
Maison >base de données >Redis >Quelle est la formule de l'algorithme pour la taille du filtre Redis Bloom ?
Quelle est la formule de l'algorithme pour la taille du filtre Redis Bloom ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-31 20:17:571096parcourir
1. Introduction
Client : Cette clé existe-t-elle ?
Serveur : n'existe pas/je ne sais pas
Le filtre Bloom est une structure de données probabiliste relativement intelligente, et son essence est une structure de données. Il propose une insertion et des requêtes efficaces. Mais lorsque l'on veut vérifier si une clé existe dans une certaine structure, en utilisant un filtre Bloom, on peut rapidement apprendre que « cette clé ne doit pas exister ou peut exister ». Comparé aux structures de données traditionnelles telles que List, Set et Map, il est plus efficace et prend moins de place, mais les résultats qu'il renvoie sont probabilistes et inexacts.
Les filtres Bloom ne servent qu'à tester l'appartenance à une collection. L'exemple classique du filtre Bloom consiste à améliorer l'efficacité en réduisant les recherches coûteuses sur le disque (ou le réseau) pour des clés inexistantes. Comme nous pouvons le voir, un filtre Bloom peut rechercher une clé en temps constant O(k), où k est le nombre de fonctions de hachage, et tester la non-existence d'une clé sera très rapide.
2. Scénarios d'application
2.1 Pénétration du cache
Afin d'améliorer l'efficacité de l'accès, nous mettrons certaines données dans le cache Redis. Lors de l'exécution d'une requête de données, vous pouvez d'abord obtenir les données du cache sans lire la base de données. Cela peut améliorer efficacement les performances.
Lors de l'interrogation de données, vous devez d'abord déterminer s'il y a des données dans le cache. S'il y a des données, récupérez les données directement du cache.
Mais s'il n'y a pas de données, vous devez récupérer les données de la base de données et les mettre dans le cache. Si un grand nombre d'accès échouent dans le cache, cela exercera une forte pression sur la base de données, provoquant un crash de la base de données. Grâce aux filtres Bloom, lorsque vous accédez à un cache inexistant, vous pouvez revenir rapidement pour éviter un crash du cache ou de la base de données.
2.2 Déterminer si une certaine donnée existe dans les données massives
Une très grande quantité de données est stockée dans HBase Pour déterminer si un certain ROWKEYS ou une certaine colonne existe, utilisez un filtre Bloom pour obtenir rapidement si une certaine donnée existe. . Mais il existe un certain taux d’erreurs d’appréciation. Mais si une clé n’existe pas, elle doit être exacte.
3. Problèmes avec HashMap
Pour déterminer si un élément existe, il est très efficace d'utiliser HashMap. HashMap peut atteindre une complexité temporelle constante O(1) en mappant les valeurs sur les clés HashMap.
Cependant, si la quantité de données stockées est très importante (par exemple : des centaines de millions de données), HashMap consommera une très grande quantité de mémoire. Et il est tout simplement impossible de lire simultanément des quantités massives de données en mémoire.
4. Comprendre le schéma de principe de fonctionnement du filtre Bloom
:
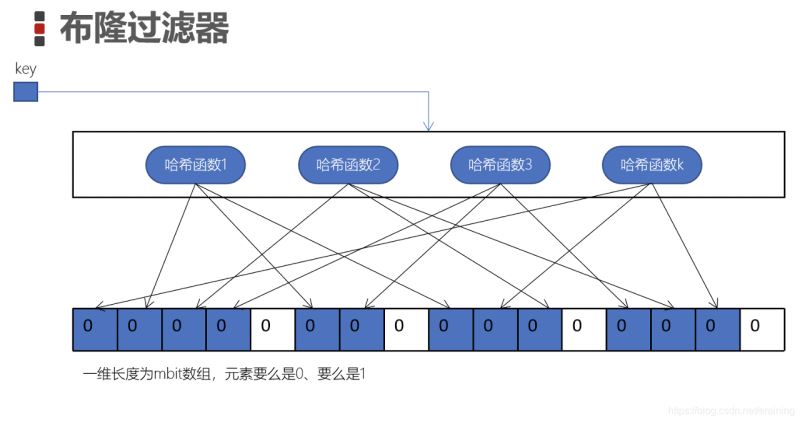
Le filtre Bloom est un tableau de bits ou un vecteur binaire de bits
Les éléments de ce tableau sont soit 0, soit 1
Les fonctions de hachage k sont indépendants les uns des autres, et le résultat calculé de chaque fonction de hachage est modulo la longueur m du tableau, et le bit de chacune est mis à 1 (cellule bleue)
Nous définissons chaque clé Toutes les cellules sont configurées de cette manière, ce qui est le "filtre Bloom"
5. Requérez des éléments selon le filtre Bloom
Supposons que vous saisissiez une clé, nous utilisons les fonctions de hachage k précédentes pour trouver le hachage et obtenir des valeurs k
Déterminer si les valeurs k sont toutes bleu. Si l'un d'eux n'est pas bleu, alors la clé ne doit pas exister.
S'ils sont tous bleus, alors la clé peut exister (le filtre Bloom provoquera une erreur de jugement)
Parce que s'il y a beaucoup d'objets d'entrée et que la collection est relativement. petite, la plupart des positions de la collection seront dessinées en bleu. Ensuite, lorsqu'une certaine clé est cochée comme étant bleue, une certaine position se trouve être définie en bleu. À ce moment, une erreur se produit. l'ensemble
Exemple :
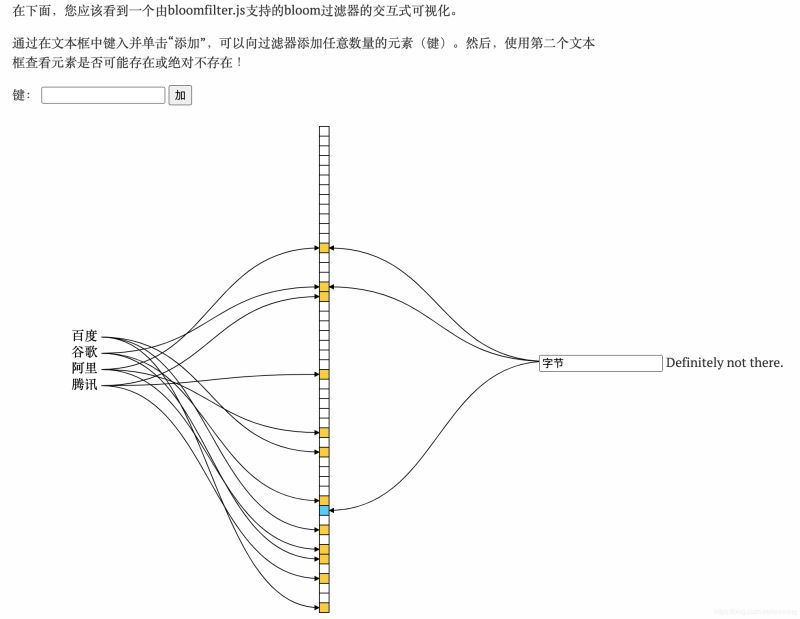
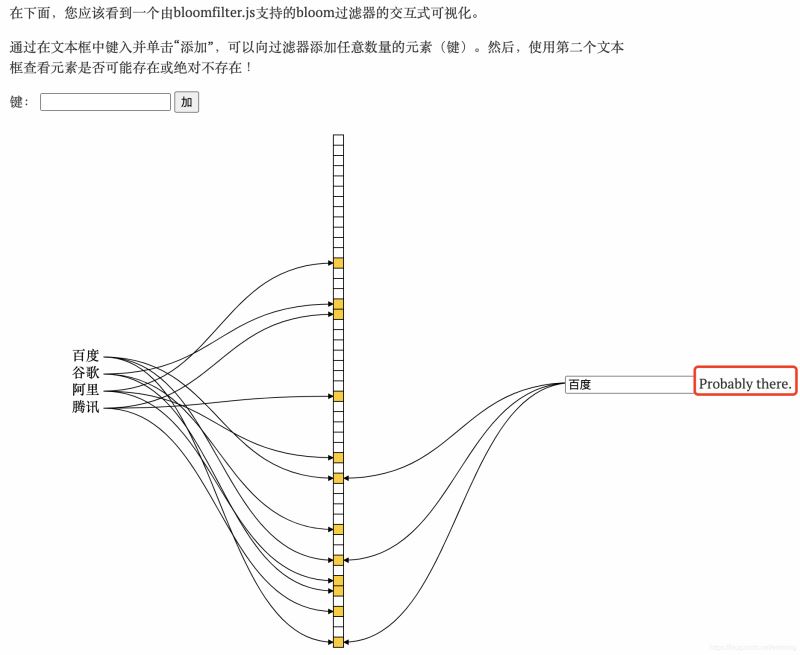
6. Peut-il être supprimé
Les filtres Bloom traditionnels ne prennent pas en charge les opérations de suppression. Cependant, une variante appelée filtre Counting Bloom peut être utilisée pour tester si le nombre d'éléments est absolument inférieur à un certain seuil, et elle prend en charge la suppression d'éléments. Le principe et la mise en œuvre de l'article Counting Bloom Filter sont écrits de manière très détaillée et vous pouvez le lire en détail.
7. Comment choisir le nombre de fonctions de hachage et la longueur du filtre Bloom
Évidemment, si le filtre Bloom est trop petit, tous les bits seront bientôt 1, alors l'interrogation de n'importe quelle valeur renverra "peut exister". Cela va à l’encontre de l’objectif du filtrage. À mesure que la longueur d’un filtre Bloom augmente, son taux de faux positifs diminue.
De plus, le nombre de fonctions de hachage doit également être pondéré. Plus le nombre est élevé, plus la position du bit du filtre Bloom est réglée rapidement sur 1, et plus l'efficacité du filtre Bloom est faible, mais s'il y en a trop peu, alors nous Le taux de fausses alarmes deviendra plus élevé.
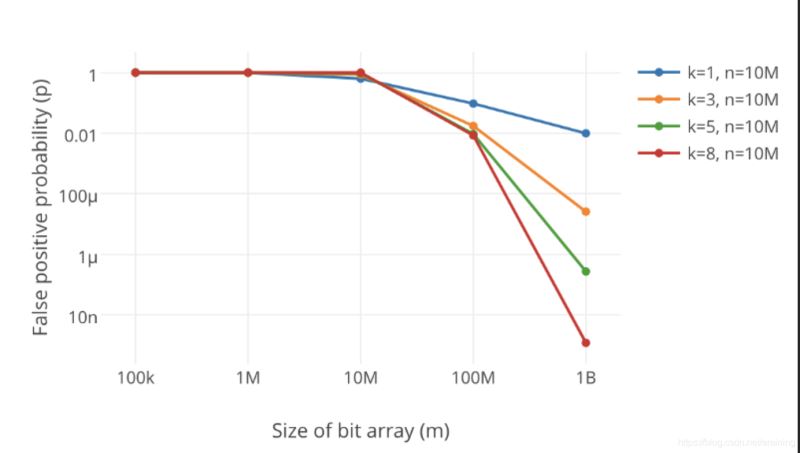
Comme le montre la figure ci-dessus, augmenter le nombre de fonctions de hachage k réduira considérablement le taux d'erreur p.
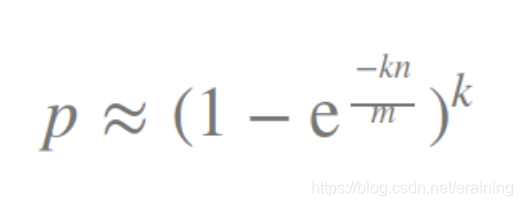
Ne vous inquiétez pas, nous devons en fait confirmer les valeurs de m et k. Eh bien, si l'on précise la tolérance aux pannes p et le nombre d'éléments n, ces paramètres peuvent être calculés à l'aide de la formule suivante :
Nous pouvons calculer les faux positifs en fonction de la taille du filtre m, du nombre de fonctions de hachage k et du nombre d'éléments insérés n Le taux p, la formule est la suivante : Sur la base de ce qui précède, comment choisir les valeurs k et m adaptées à l'entreprise ?
Formule :
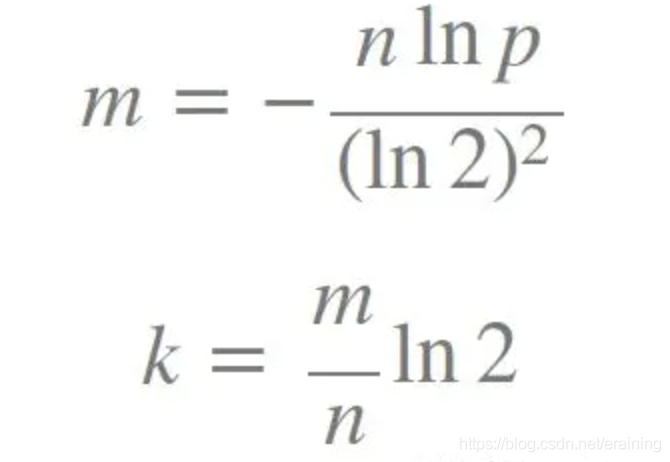
k est le nombre de fonctions de hachage, m est la longueur du filtre Bloom, n est le nombre d'éléments insérés et p est le taux de faux positifs.
Quant à la façon de dériver cette formule, j'ai publié un article sur Zhihu à ce sujet. Si vous êtes intéressé, vous pouvez le lire. Si vous n'êtes pas intéressé, rappelez-vous simplement la formule ci-dessus.
Je voudrais également mentionner ici un autre point important. Puisque le seul objectif de l’utilisation d’un filtre Bloom est d’effectuer une recherche plus rapide, nous ne pouvons pas utiliser une fonction de hachage lente, n’est-ce pas ? Les fonctions de hachage cryptographique (par exemple Sha-1, MD5) ne sont pas un bon choix pour les filtres Bloom car elles sont un peu lentes. Ainsi, les meilleurs choix parmi les implémentations plus rapides de fonctions de hachage sont murmur, le hachage de la famille fnv, le hachage Jenkins et HashMix.
Plus de scénarios d'application
Dans l'exemple donné, vous avez vu que nous pouvons utiliser cela pour avertir l'utilisateur d'avoir saisi un mot de passe faible.
Vous pouvez utiliser des filtres Bloom pour empêcher les utilisateurs de visiter des sites Web malveillants.
Au lieu d'interroger une base de données SQL pour vérifier si un utilisateur avec une adresse e-mail spécifique existe, vous pouvez d'abord utiliser le filtre Bloom pour effectuer une vérification de recherche bon marché. Si l'e-mail n'existe pas, tant mieux ! S'il existe, vous devrez peut-être effectuer des requêtes supplémentaires dans la base de données. Vous pouvez également faire la même chose pour rechercher « nom d’utilisateur déjà pris ».
Vous pouvez conserver un filtre Bloom basé sur l'adresse IP des visiteurs de votre site Web pour vérifier si les utilisateurs de votre site Web sont des « utilisateurs connus » ou des « nouveaux utilisateurs ». Quelques faux positifs provenant d’« utilisateurs connus » ne peuvent pas vous faire de mal, n’est-ce pas ?
Vous pouvez également effectuer une vérification orthographique en suivant les mots du dictionnaire à l'aide des filtres Bloom.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!