
Maison >Périphériques technologiques >IA >Google DeepMind, OpenAI et d'autres ont publié conjointement un article : Comment évaluer les risques extrêmes des grands modèles d'IA ?
Google DeepMind, OpenAI et d'autres ont publié conjointement un article : Comment évaluer les risques extrêmes des grands modèles d'IA ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-31 12:59:151368parcourir
Actuellement, les méthodes de construction de systèmes généraux d'intelligence artificielle (AGI), tout en aidant les gens à mieux résoudre des problèmes réels, comportent également des risques inattendus.
Par conséquent, À l'avenir, le développement ultérieur de l'intelligence artificielle pourrait conduire à de nombreux risques extrêmes , tels que des capacités de réseau offensives ou de puissantes compétences de manipulation, etc.
Aujourd'hui, Google DeepMind, en collaboration avec des universités telles que l'Université de Cambridge et l'Université d'Oxford, des entreprises telles que OpenAI et Anthropic, ainsi que des institutions telles que l'Alignement Research Center, a publié un article intitulé « Évaluation de modèles pour les situations extrêmes. risques" sur le site Web de prépublication arXiv. propose un cadre pour un modèle commun pour l'évaluation des nouvelles menaces et explique pourquoi l'évaluation du modèle est essentielle pour faire face aux risques extrêmes.
Ils pensent que les développeurs doivent avoir la capacité d'identifier les dangers (par le biais d'une "évaluation des capacités de danger"), et la propension du modèle à appliquer ses capacités pour causer des dommages (via "évaluation de l'alignement"). Ces évaluations seront essentielles pour tenir les décideurs politiques et autres parties prenantes informés et prendre des décisions responsables concernant la formation, le déploiement et la sécurité des modèles.

Academic Headlines (ID : SciTouTiao) a réalisé une compilation simple sans changer l'idée principale du texte original. Le contenu est le suivant :
Pour promouvoir de manière responsable le développement de la recherche de pointe sur l'IA, nous devons identifier le plus tôt possible les nouvelles capacités et les risques des systèmes d'IA.
Les chercheurs en IA ont utilisé une série de critères d'évaluation pour identifier les comportements indésirables dans les systèmes d'IA, tels que les systèmes d'IA faisant des déclarations trompeuses, des décisions biaisées ou la duplication de contenu protégé par le droit d'auteur. Aujourd'hui, alors que la communauté de l'IA construit et déploie une IA de plus en plus puissante, nous devons élargir notre évaluation pour inclure les conséquences potentielles des modèles généraux d'IA ayant la capacité de manipuler, de tromper, de cyber-attaquer ou d'être autrement dangereux. Considérations.
En collaboration avec l'Université de Cambridge, l'Université d'Oxford, l'Université de Toronto, l'Université de Montréal, OpenAI, Anthropic, l'Alignement Research Center, le Centre pour la résilience à long terme et le Centre pour la gouvernance de AI, nous introduisons un cadre pour évaluer ces nouvelles menaces .
L'évaluation de la sécurité des modèles, y compris l'évaluation des risques extrêmes, deviendra un élément important du développement et du déploiement sûrs de l'IA.
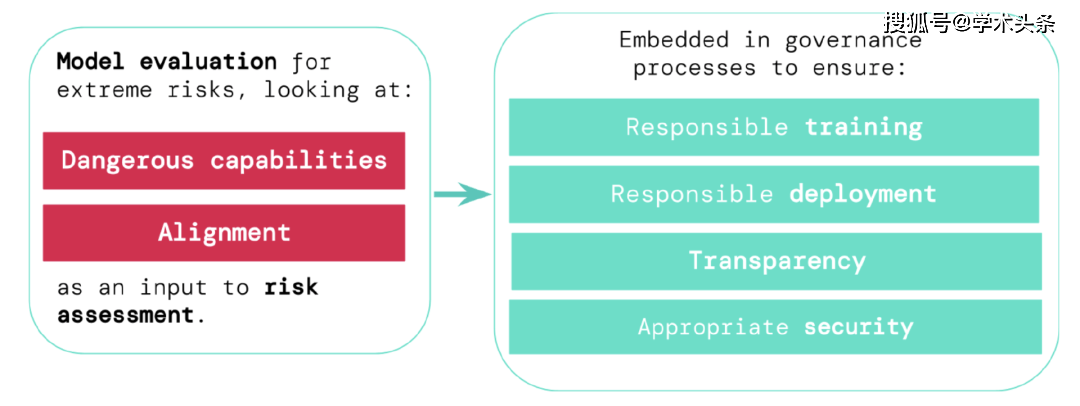
Pour évaluer les risques extrêmes des nouveaux systèmes généraux d'intelligence artificielle, les développeurs doivent évaluer leurs capacités dangereuses et leurs niveaux d'alignement. L’identification précoce des risques peut conduire à une plus grande responsabilité dans la formation de nouveaux systèmes d’IA, le déploiement de ces systèmes d’IA, la description transparente de leurs risques et l’application de normes de cybersécurité appropriées.
Évaluer les risques extrêmes
Les modèles universels apprennent généralement leurs capacités et leurs comportements pendant la formation. Cependant, les méthodes existantes pour guider le processus d’apprentissage sont imparfaites. Des recherches antérieures de Google DeepMind, par exemple, ont exploré comment les systèmes d’IA peuvent apprendre à poursuivre des objectifs que les gens ne veulent pas, même lorsque nous les récompensons correctement pour leur bon comportement.
Les développeurs d'IA responsables doivent aller plus loin et anticiper les éventuelles évolutions futures et les nouveaux risques. À mesure que les progrès se poursuivent, les futurs modèles polyvalents pourraient apprendre par défaut diverses capacités dangereuses. Par exemple, les futurs systèmes d'intelligence artificielle seront capables de mener des activités de réseau offensives, de tromper intelligemment les humains dans les conversations, de manipuler les humains pour qu'ils adoptent des comportements nocifs, de concevoir ou d'acquérir des armes (telles que des armes biologiques et chimiques), et d'affiner et de fonctionner sur le cloud computing. D’autres systèmes d’IA à enjeux élevés, ou aidant les humains dans l’une de ces tâches, sont possibles (bien que pas certains).
Les personnes mal intentionnées peuvent abuser des capacités de ces modèles. Ces modèles d’IA peuvent être nuisibles en raison des différences de valeurs et de morale par rapport aux humains, même si personne n’avait l’intention de le faire.
L'évaluation du modèle nous aide à identifier ces risques à l'avance. Dans notre cadre, les développeurs d'IA utiliseront l'évaluation du modèle pour découvrir :
- La mesure dans laquelle un modèle possède certaines « capacités dangereuses » qui menacent la sécurité, exercent une influence ou échappent à la supervision.
- La mesure dans laquelle un modèle est enclin à utiliser ses capacités pour causer des dégâts (c'est-à-dire le niveau d'alignement du modèle). Il est nécessaire de confirmer que le modèle se comporte comme prévu, même dans un très large éventail de circonstances, et, si possible, le fonctionnement interne du modèle doit être examiné.
Grâce aux résultats de ces évaluations, les développeurs d'IA peuvent comprendre s'il existe des facteurs pouvant conduire à des risques extrêmes. Les situations les plus risquées impliqueront une combinaison de capacités dangereuses. Comme indiqué ci-dessous :
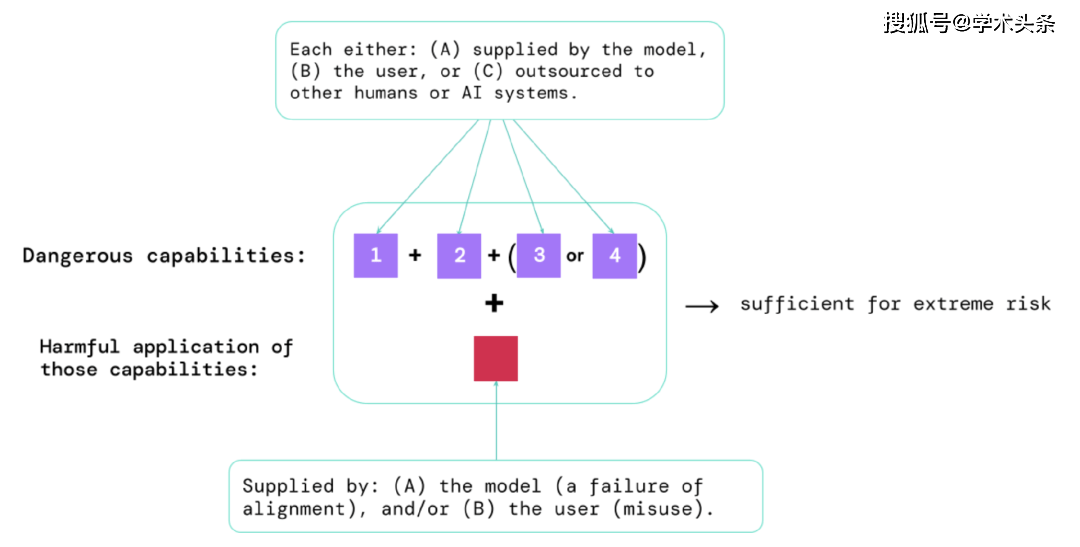
图|Éléments qui présentent des risques extrêmes : Parfois, des capacités spécifiques peuvent être sous-traitées, soit à des humains (tels que des utilisateurs ou des travailleurs de foule), soit à d'autres systèmes d'IA. Ces capacités doivent être utilisées pour infliger des dégâts, que ce soit par abus ou par échec d’alignement.
Une règle empirique : Si un système d'IA possède des caractéristiques capables de causer des dommages extrêmes, en supposant qu'il soit abusé ou mal aligné, alors la communauté de l'IA devrait le considérer comme « très dangereux ». Pour déployer de tels systèmes dans le monde réel, les développeurs d'IA doivent démontrer des normes de sécurité exceptionnellement élevées.
L'évaluation des modèles est une infrastructure de gouvernance essentielle
Si nous disposons de meilleurs outils pour identifier les modèles risqués, les entreprises et les régulateurs pourront mieux garantir :
- Formation responsable : décidez de manière responsable si et comment former un nouveau modèle qui montre les premiers signes de risque.
- Déploiement responsable : prenez des décisions responsables quant à savoir si, quand et comment déployer des modèles potentiellement risqués.
- Transparence : communiquer des informations utiles et exploitables aux parties prenantes pour les aider à faire face ou à réduire les risques potentiels.
- Sécurité appropriée : des contrôles et des systèmes de sécurité des informations solides sont appropriés pour les modèles qui peuvent présenter des risques extrêmes.
Nous avons élaboré un plan expliquant comment l'évaluation des modèles pour les risques extrêmes devrait soutenir les décisions importantes concernant la formation et le déploiement de modèles puissants à usage général. Les développeurs effectuent des évaluations tout au long du processus et accordent un accès structuré au modèle aux chercheurs en sécurité externes et aux réviseurs de modèles afin qu'ils puissent effectuer des évaluations supplémentaires. Les résultats de l'évaluation peuvent fournir une référence pour l'évaluation des risques avant la formation et le déploiement du modèle.
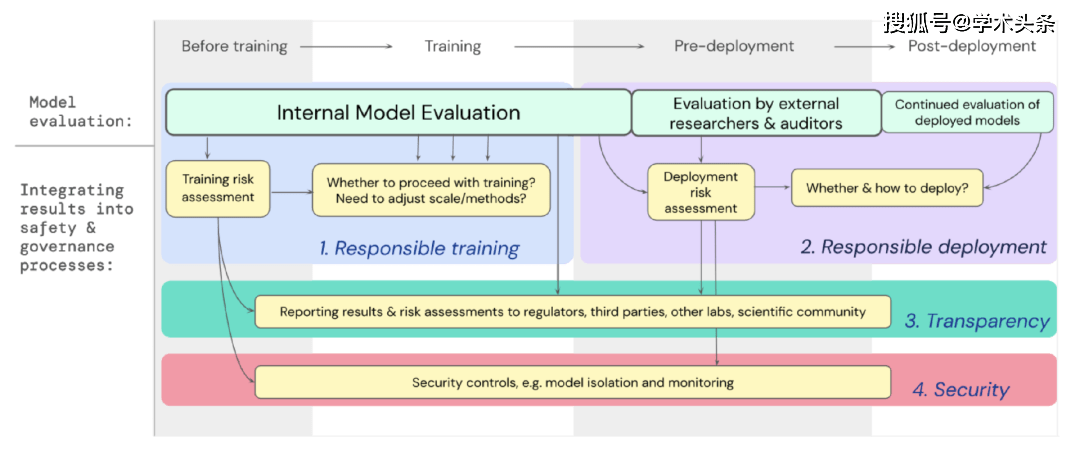
Picture | Intégrez l'évaluation du modèle pour les risques extrêmes dans le processus décisionnel important de l'ensemble de la formation et du déploiement du modèle.
Regard vers l'avenir
Chez Google DeepMind et ailleurs, d'importants travaux préliminaires sur l'évaluation des modèles pour les risques extrêmes ont commencé. Mais pour construire un processus d’évaluation qui capture tous les risques possibles et contribue à se protéger contre les défis émergents à l’avenir, nous avons besoin de davantage d’efforts techniques et institutionnels. L'évaluation du modèle n'est pas une panacée ; parfois, certains risques peuvent échapper à notre évaluation car ils reposent trop sur des facteurs externes au modèle, tels que les forces sociales, politiques et économiques complexes de la société. Il est nécessaire d'intégrer les évaluations des modèles aux préoccupations plus larges de l'industrie, du gouvernement et du public concernant la sécurité et d'autres outils d'évaluation des risques.
Google a récemment mentionné dans son blog sur l'IA responsable que « les pratiques individuelles, les normes industrielles partagées et les politiques gouvernementales judicieuses sont essentielles à la bonne utilisation de l'IA ». Nous espérons que les nombreuses industries travaillant dans le domaine de l’IA et affectées par cette technologie pourront travailler ensemble pour développer conjointement des méthodes et des normes pour le développement et le déploiement sûrs de l’IA au bénéfice de tous.
Nous pensons que disposer de procédures en place pour suivre les attributs de risque qui apparaissent dans les modèles et répondre de manière adéquate aux résultats associés est un élément essentiel du travail en tant que développeur responsable à l'avant-garde de la recherche en IA.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI