
Maison >Périphériques technologiques >IA >Que faire si les connaissances sur les grands modèles sont épuisées ? L'équipe de l'Université du Zhejiang explore des méthodes de mise à jour des paramètres des grands modèles : l'édition de modèles
Que faire si les connaissances sur les grands modèles sont épuisées ? L'équipe de l'Université du Zhejiang explore des méthodes de mise à jour des paramètres des grands modèles : l'édition de modèles

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-30 22:11:091466parcourir
Xi Xiaoyao Science and Technology Talk Auteur original | Xiaoxi, Python
Il y a une question intuitive derrière la taille énorme des grands modèles : « Comment les grands modèles doivent-ils être mis à jour ?
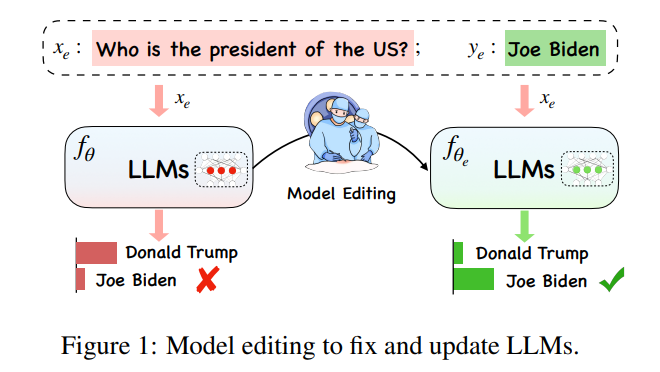
Sous la charge de calcul extrêmement énorme des grands modèles, les grands modèles modèles La mise à jour des connaissances sur les modèles n'est pas une simple « tâche d'apprentissage ». Idéalement, avec les changements complexes dans diverses situations dans le monde, les grands modèles devraient suivre le temps à tout moment et en tout lieu, mais le calcul de la formation d'un nouveau grand modèle est une charge. ne permet pas les mises à jour en temps réel des grands modèles. Par conséquent, un nouveau concept « d'édition de modèles » a vu le jour pour apporter des modifications efficaces aux données du modèle dans des domaines spécifiques sans affecter les autres entrées, le résultat étant des effets indésirables.

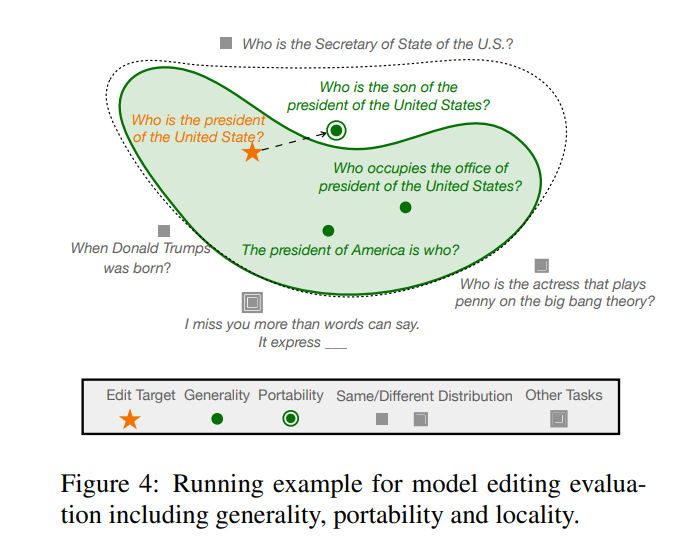
Parmi eux, représente le « voisin effectif » de , qui représente la zone au-delà du champ d'application de . Un modèle édité doit répondre aux trois points suivants, à savoir la fiabilité, l'universalité et la localité. La fiabilité signifie que le modèle édité doit être capable de générer correctement des exemples d'erreurs dans le modèle pré-édité, qui peuvent être déterminées par la précision moyenne du modèle édité. Dans certains cas, l'universalité signifie que le modèle doit être capable de fournir un résultat correct pour les « voisins effectifs » de Le modèle doit toujours conserver la précision de pré-édition dans les exemples au-delà de la plage d'édition. La localité peut être caractérisée en mesurant séparément la moyenne. précision avant et après l'édition, comme le montre la figure ci-dessous, au poste d'édition "Trump" , certaines autres caractéristiques publiques ne doivent pas être modifiées. Dans le même temps, d'autres entités, comme le « Secrétaire d'État », bien qu'ayant des caractéristiques similaires à celles du « Président », ne devraient pas être affectées.
L'article de l'Université du Zhejiang présenté aujourd'hui est du point de vue d'un grand modèle. Il décrit en détail les problèmes, les méthodes et l'avenir de l'édition de modèles à l'ère des grands modèles, et construit de nouveaux ensembles de données et. les indicateurs d'évaluation aident à évaluer les technologies existantes de manière plus complète et fournissent à la communauté des suggestions de prise de décision significatives et des informations sur la sélection des méthodes :
Titre de l'article : Édition de modèles de langage étendus : problèmes, méthodes et opportunités
Lien de l'article : https://arxiv .org/pdf/2305.13172.pdf
Méthodes grand public
Les méthodes actuelles d'édition de modèles pour les modèles de langage à grande échelle (LLM) sont principalement divisées en deux types de paradigmes, comme le montre la figure ci-dessous, à savoir comme le montre la figure (un ) ci-dessous, des paramètres supplémentaires sont utilisés tout en gardant les paramètres du modèle d'origine inchangés, et les paramètres internes du modèle sont modifiés comme le montre la figure (b) ci-dessous.
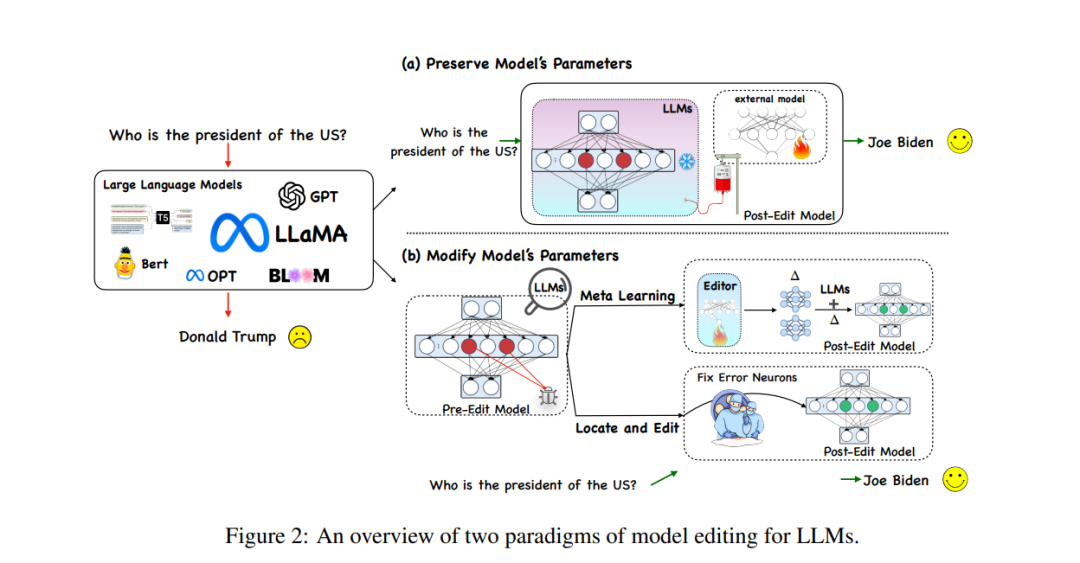
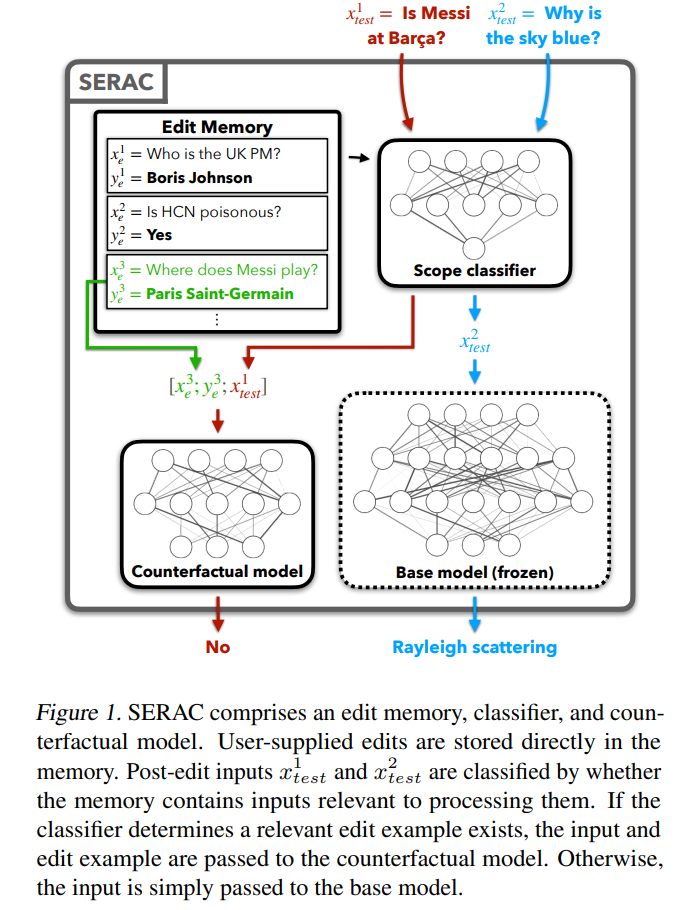
Examinons d'abord la méthode relativement simple d'ajout de paramètres supplémentaires. Cette méthode est également appelée méthode d'édition de modèle en mémoire ou basée sur la mémoire. La méthode représentative SERAC est apparue pour la première fois dans l'article de Mitchell proposant « l'édition de modèle ». L'idée principale est de conserver les paramètres d'origine du modèle inchangés et de retraiter les faits modifiés via un ensemble de paramètres indépendant. Plus précisément, ce type de méthode ajoute généralement d'abord un « classificateur de plage » pour déterminer si la nouvelle entrée se trouve dans la « réédition ». Dans la plage de faits, si elle appartient, l'entrée est traitée à l'aide d'un ensemble de paramètres indépendant, donnant une probabilité de sélection plus élevée à la « bonne réponse » dans le cache. Basés sur SERAC, T-Patcher et CaliNET introduisent des paramètres supplémentaires pouvant être entraînés dans le module feedforward des PLM (au lieu de brancher un modèle supplémentaire). Ces paramètres sont entraînés sur l'ensemble de données de faits modifiés pour obtenir l'effet d'édition du modèle.
L'autre grande catégorie de méthodes, la méthode de modification des paramètres dans le modèle d'origine, utilise principalement une matrice Δ pour mettre à jour certains paramètres du modèle. Plus précisément, la méthode de modification des paramètres peut être divisée en « Localiser-Puis-Modifier ». et méta-apprentissage Il existe deux types de méthodes, comme son nom l'indique. La méthode Locate-Then-Edit localise d'abord les principaux paramètres d'influence dans le modèle, puis modifie les paramètres du modèle localisés pour implémenter l'édition du modèle. La méthode est la méthode Knowledge Neuron (KN). Les principaux paramètres d'influence sont déterminés en identifiant les « neurones de la connaissance » dans le modèle, et le modèle est mis à jour en mettant à jour ces neurones. Une autre méthode appelée ROME a une idée similaire à KN et localise. la zone d'édition via une analyse intermédiaire causale. De plus, une méthode MEMIT peut être utilisée pour mettre à jour une série de descriptions d'édition. Le plus gros problème de ce type de méthode est qu’elle repose généralement sur une hypothèse de localité des connaissances factuelles, mais cette hypothèse n’a pas été largement vérifiée, et la modification de nombreux paramètres peut conduire à des résultats inattendus.
La méthode de méta-apprentissage est différente de la méthode Locate-Then-Edit. La méthode de méta-apprentissage utilise la méthode hyper-réseau et utilise un hyper-réseau pour générer des poids pour un autre réseau. Plus précisément, dans la méthode Knowledge Editor, l'auteur. utilise un Le LSTM bidirectionnel prédit les mises à jour que chaque point de données apporte au poids du modèle, réalisant ainsi une optimisation contrainte des connaissances cibles d'édition. Ce type de méthode d'édition des connaissances est difficile à appliquer aux LLM en raison de la grande quantité de paramètres dans les LLM. Par conséquent, Mitchell et al. ont proposé MEND (Model Editor Networks with Gradient Decomposition) afin qu'une seule description d'édition puisse mettre à jour efficacement les LLM. update La méthode utilise principalement la décomposition des gradients de bas rang pour affiner les gradients des grands modèles, permettant ainsi des mises à jour minimales des ressources des LLM. Contrairement à la méthode Locate-Then-Edit, les méthodes de méta-apprentissage prennent généralement plus de temps et consomment plus de mémoire.
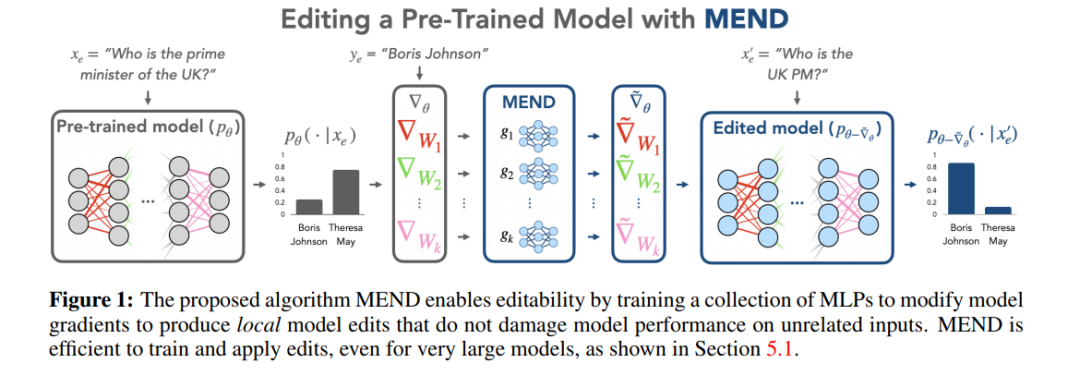
Évaluation des méthodes
Ces différentes méthodes sont utilisées dans les deux ensembles de données principaux de l'édition de modèle ZsRE (ensemble de données de questions et réponses, utilisant des questions générées par rétro-traduction pour les réécrire en tant que champs valides) et COUNTERFACT (ensemble de données contrefactuelles , entités sujet remplacées par des entités synonymes comme champs valides), l'expérience a été menée comme le montre la figure ci-dessous. L'expérience s'est principalement concentrée sur deux LLM à relativement grande échelle T5-XL (3B) et GPT-J (6B) comme base. modèle et une édition efficace du modèle. Le processeur doit trouver un équilibre entre les performances du modèle, la vitesse d'inférence et l'espace de stockage.
En comparant les résultats du réglage fin (FT) dans la première colonne, on constate que SERAC et ROME fonctionnent bien sur les ensembles de données ZsRE et COUNTERFACT, en particulier SERAC, qui obtient plus de 90 % de résultats sur plusieurs indicateurs d'évaluation, bien que MEMIT La polyvalence n'est pas aussi bonne que SERAC et ROME, mais il fonctionne bien en termes de fiabilité et de localité. La méthode T-Patcher est extrêmement instable. Elle a une bonne fiabilité et une bonne localité dans l'ensemble de données COUNTERFACT, mais manque de généralité. Dans GPT-J, elle a une excellente fiabilité et une bonne généralité, mais de mauvaises performances en localité. Il est à noter que les performances de KE, CaliNET et KN sont médiocres. Par rapport aux bonnes performances obtenues par ces modèles dans les « petits modèles », les expérimentations peuvent prouver que ces méthodes ne sont pas bien adaptées à l'environnement des grands modèles.
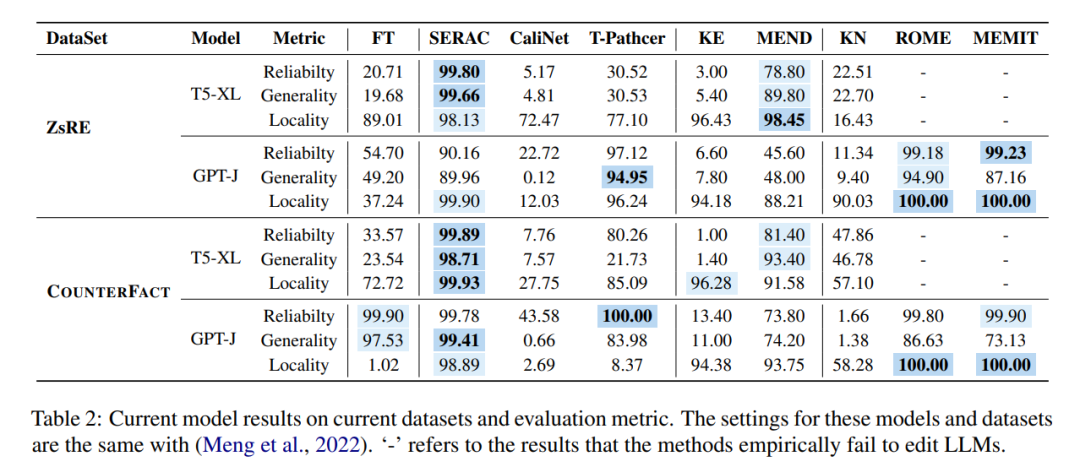
D'un point de vue temporel, une fois le réseau formé, KE et MEND fonctionnent très bien, tandis que des méthodes telles que T-Patcher prennent trop de temps :
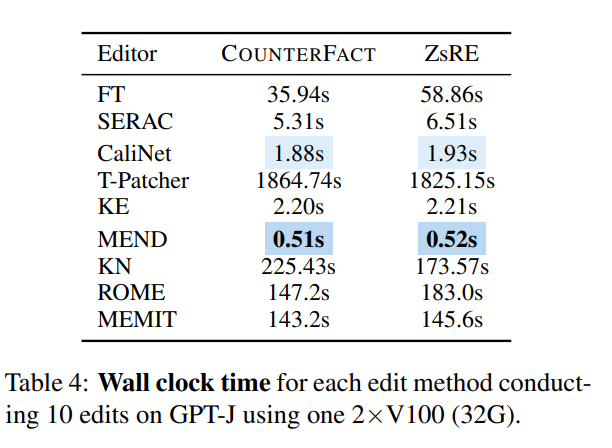
En regardant la consommation de mémoire, la plupart des méthodes consomment de la mémoire du même ordre de grandeur, mais les méthodes qui introduisent des paramètres supplémentaires entraîneront une surcharge de mémoire supplémentaire :
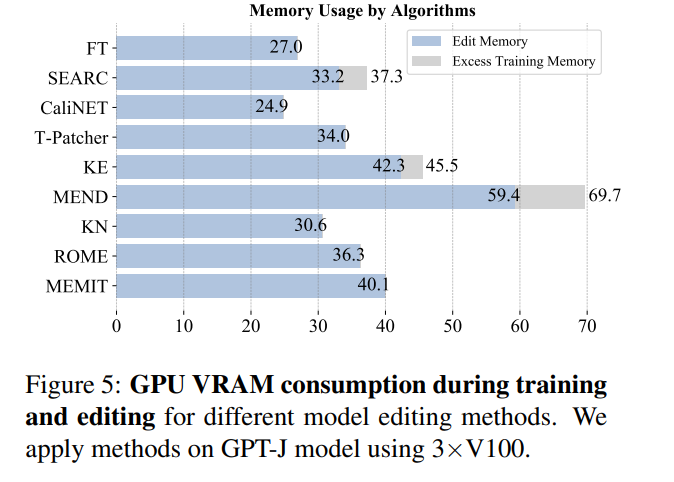
Dans le même temps, les opérations d'édition de modèle doivent généralement également prendre en compte les informations d'édition par lots et les informations d'édition séquentielles, c'est-à-dire. , mettant à jour plusieurs informations de fait en même temps et mettant à jour plusieurs informations de fait de manière séquentielle. L'effet global du modèle des informations de modification par lots est illustré dans la figure ci-dessous. Vous pouvez voir que MEMIT peut prendre en charge la modification de plus de 10 000 informations en même temps. et peut également garantir deux métriques. La performance des deux indicateurs reste stable, tandis que les performances du MEND et du SERAC sont médiocres :
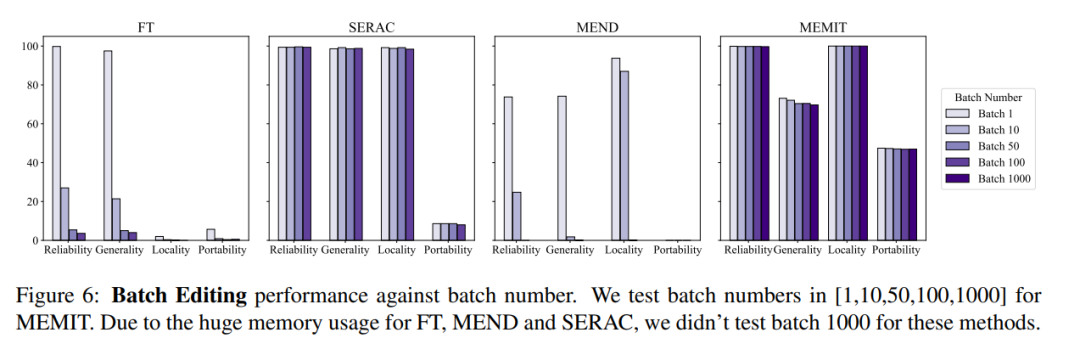
En termes de saisie séquentielle, SERAC et T-Patcher ont fonctionné correctement et de manière stable. ROME, MEMIT et MEND ont tous connu une baisse rapide des performances du modèle après un certain nombre de saisies :
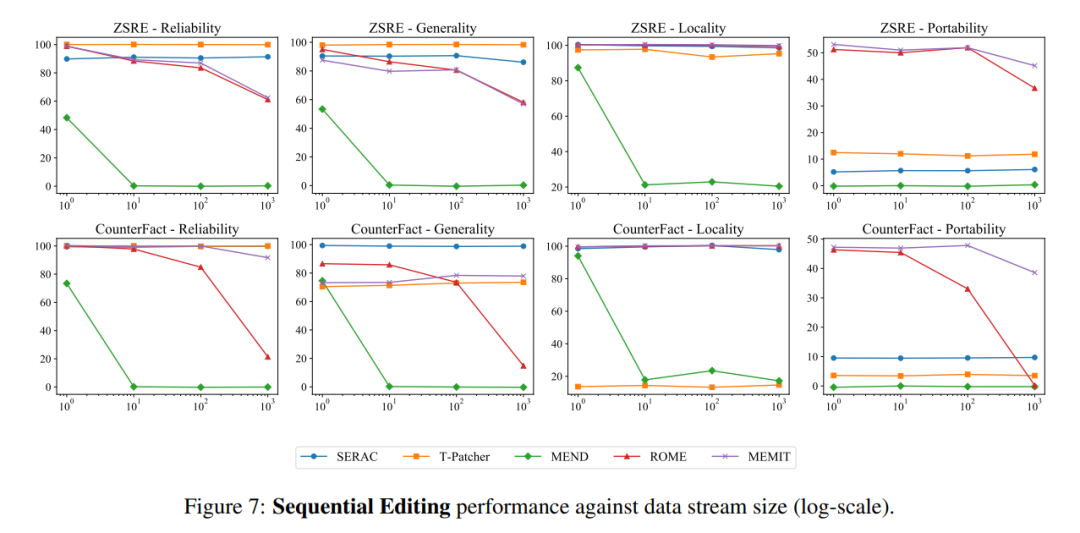
Enfin, l'auteur. L'étude a révélé que les indicateurs actuels de construction et d'évaluation de ces ensembles de données se concentrent en grande partie uniquement sur les changements dans la formulation des phrases, mais n'entrent pas dans les modifications apportées par les éditeurs de modèles à de nombreux faits logiques pertinents, par exemple si "Watts Humphrey a fréquenté quelle université". " "La réponse est changée du Trinity College à l'Université du Michigan. Évidemment, si nous demandons au modèle "Dans quelle ville Watts Humphrey a-t-il vécu à l'université ?", le modèle idéal devrait répondre Ann Arbor au lieu de Hartford, selon l'auteur de l'article. vient en premier. Sur la base des trois indicateurs d'évaluation, l'indicateur « portabilité » est introduit pour mesurer l'efficacité du modèle édité en matière de transfert de connaissances.
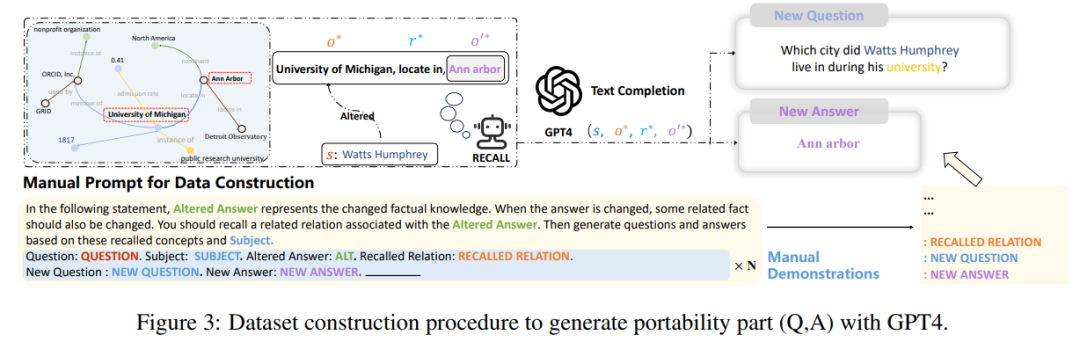
À cette fin, l'auteur a utilisé GPT-4 pour construire un nouvel ensemble de données, en modifiant la réponse à la question d'origine de Input , si le modèle peut produire correctement, cela prouve que le modèle édité a une "portabilité" . Selon cette méthode, l'article a testé les scores de portabilité de plusieurs méthodes existantes, comme le montre la figure ci-dessous :
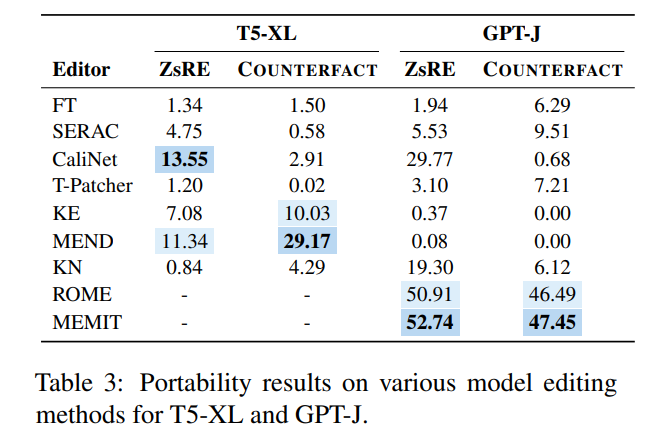
Vous pouvez voir que presque la plupart des méthodes d'édition de modèles ne sont pas idéales en termes de portabilité. la précision de la portabilité de SERAC, qui fonctionnait autrefois bien, est inférieure à 10 %, et les meilleurs ROME et MEMIT ne sont qu'environ 50 % au mieux, ce qui montre que la méthode d'édition de modèle actuelle est presque difficile à réaliser une expansion et une promotion des éditions connaissances, et l'édition de modèles a encore un long chemin à parcourir.
Discussion et avenir
Dans tous les sens, le problème des préréglages d'édition de modèles a un grand potentiel dans ce que l'on appelle « l'ère des grands modèles » à l'avenir. Le problème de l'édition de modèles doit être mieux exploré, comme « comment ». la connaissance du modèle est stockée « Parmi quels paramètres ? » et « Comment les opérations d'édition du modèle peuvent-elles ne pas affecter la sortie des autres modules ? » et une série de questions très difficiles. D'autre part, pour résoudre le problème du modèle « obsolète », en plus de laisser le modèle être « édité », une autre idée est de laisser le modèle « apprendre tout au long de la vie » et « oublier » les connaissances sensibles, qu'il s'agisse de l'édition du modèle ou modéliser l'apprentissage tout au long de la vie. De telles recherches apporteront des contributions significatives aux problèmes de sécurité et de confidentialité des LLM.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI