
Maison >base de données >tutoriel mysql >Comment utiliser Python pour lire des dizaines de millions de données et les écrire automatiquement dans une base de données MySQL
Comment utiliser Python pour lire des dizaines de millions de données et les écrire automatiquement dans une base de données MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-30 11:55:281612parcourir
Scénario 1 : Les données n'ont pas besoin d'être écrites fréquemment sur MySQL
Utilisez la fonction d'assistant d'importation de l'outil Navicat. Ce logiciel peut prendre en charge une variété de formats de fichiers et peut créer automatiquement des tableaux basés sur des champs de fichiers ou insérer des données dans des tableaux existants, ce qui est très rapide et pratique.
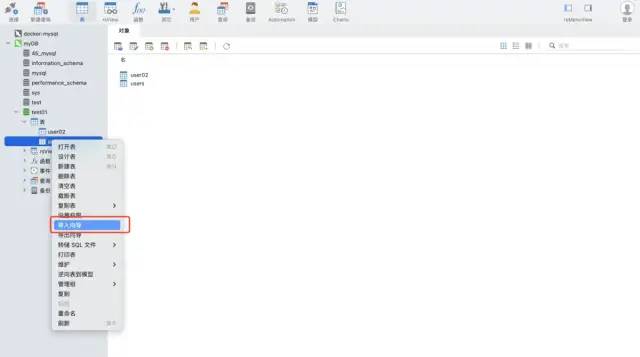
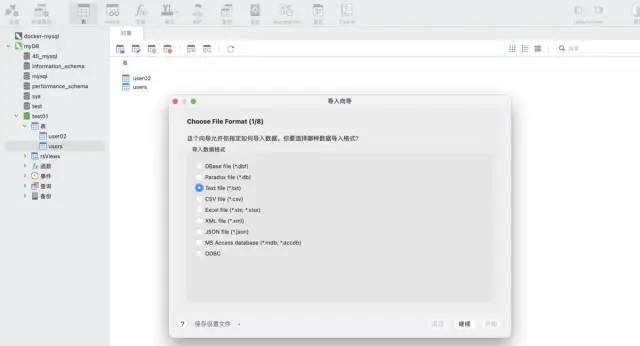
Scénario 2 : Les données sont incrémentielles et doivent être automatisées et fréquemment écrites dans MySQL
Données de test : format csv, environ 12 millions de lignes
import pandas as pd data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv') data.shape
Résultats d'impression :

Méthode 1 : python ➕ Bibliothèque pymysql
Installer la commande pymysql :
pip install pymysql
Implémentation du code :
import pymysql
# 数据库连接信息
conn = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='wangyuqing',
db='test01',
port = 3306,
charset="utf8")
# 分块处理
big_size = 100000
# 分块遍历写入到 mysql
with pd.read_csv('./tianchi_mobile_recommend_train_user.csv',chunksize=big_size) as reader:
for df in reader:
datas = []
print('处理:',len(df))
# print(df)
for i ,j in df.iterrows():
data = (j['user_id'],j['item_id'],j['behavior_type'],
j['item_category'],j['time'])
datas.append(data)
_values = ",".join(['%s', ] * 5)
sql = """insert into users(user_id,item_id,behavior_type
,item_category,time) values(%s)""" % _values
cursor = conn.cursor()
cursor.executemany(sql,datas)
conn.commit()
# 关闭服务
conn.close()
cursor.close()
print('存入成功!')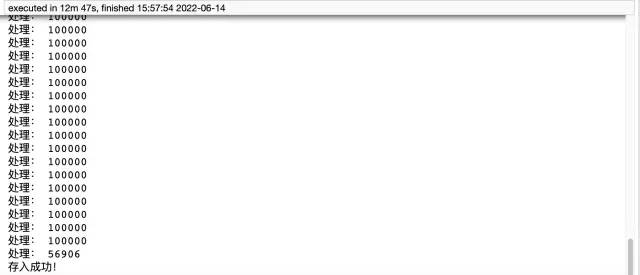
Méthode 2 : pandas ➕ sqlalchem y : les pandas doivent introduire sqlalchemy pour prendre en charge SQL, avec le support de sqlalchemy, il peut implémenter des requêtes, des mises à jour et d'autres opérations sur tous les types de bases de données courants.
Implémentation du code : la méthode
from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:wangyuqing@localhost:3306/test01') data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv') data.to_sql('user02',engine,chunksize=100000,index=None) print('存入成功!')
Summary
pymysql prend 12 minutes et 47 secondes, ce qui est encore relativement long et comporte une grande quantité de code. Cependant, les pandas n'ont besoin que de cinq lignes de code pour répondre à cette exigence, ce qui est nécessaire. ne prend que 4 minutes environ. Enfin, je voudrais ajouter que la première méthode nécessite de créer un tableau à l'avance, mais pas la deuxième méthode. Il est donc recommandé d’utiliser la deuxième méthode, à la fois pratique et efficace. Si vous sentez toujours que la vitesse est lente, vous pouvez envisager d'ajouter du multi-processus et du multi-thread.
Les trois méthodes les plus complètes pour stocker des données dans une base de données MySQL :
Stockage direct, à l'aide de la fonction d'assistant d'importation de Navicat
Python pymysql
Pandas sqlalchemy
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!