
Maison >base de données >Redis >Quelle est la méthode de conception de l'architecture Pika du système de stockage Redis ?
Quelle est la méthode de conception de l'architecture Pika du système de stockage Redis ?

- 王林avant
- 2023-05-29 20:07:171664parcourir
Pika est un produit de base de données NoSQL open source efficace, stable, simple et fiable développé conjointement par l'équipe d'infrastructure 360 et l'équipe DBA. Il est entièrement compatible avec le protocole Redis et prend en charge 5 structures de données (chaîne, hachage, liste, ensemble, zset). Par rapport à la méthode de stockage en mémoire Redis, cela peut réduire considérablement l'occupation des ressources du serveur et. améliorer la sécurité des données. Il peut être déployé selon deux modes : autonome et cluster. Le projet Pika a été lancé en 2015 et a ensuite été open source sur Github. Il compte actuellement 3 700 étoiles et 35 contributeurs. La communauté compte un grand nombre d'entreprises en ligne utilisant Pika.
Comparez Redis
Capacité de stockage : Redis stocke en mémoire, a un coût matériel élevé et un délai de récupération élevé ; Pika emprunte RocksDB pour stocker sur disque, et la quantité de données hébergée par un seul serveur est des dizaines de fois supérieure à celle de Redis. , et la vitesse de récupération en cas d'arrêt est rapide.
Débit : Redis QPS est plus élevé, avec un million de QPS sur un seul serveur ; Pika QPS est relativement faible, des centaines de milliers sur un seul serveur, et Redis est 3 à 5 fois supérieur à celui de Pika.
Latence d'accès : Redis devrait être inférieure à 1 ms ; la latence Pika est légèrement plus élevée, inférieure à 3 ms.
Déploiement d'exploitation et de maintenance : Redis prend en charge deux méthodes : maître-esclave autonome et cluster ; Pika prend également en charge deux méthodes de déploiement.
Scénarios applicables
Si le volume de données du scénario commercial est relativement important (> 50 Go) et que les exigences de fiabilité des données sont élevées, alors Pika peut résoudre votre problème.
Scénario 1 : Stockage des résultats intermédiaires pour les systèmes de traitement de données à grande échelle
Scénario 2 : Systèmes d'entreprise utilisant Redis/Redis Cluster pour le stockage persistant
Scénario 3 : Stockage des métadonnées pour les systèmes distribués à grande échelle
Conception de l'architecture
Pika peut choisir d'exécuter Pika en mode classique (Classic) ou en mode distribué (Sharding) en définissant l'élément de configuration du mode instance dans le fichier de configuration sur classique et sharding.
Architecture en mode classique
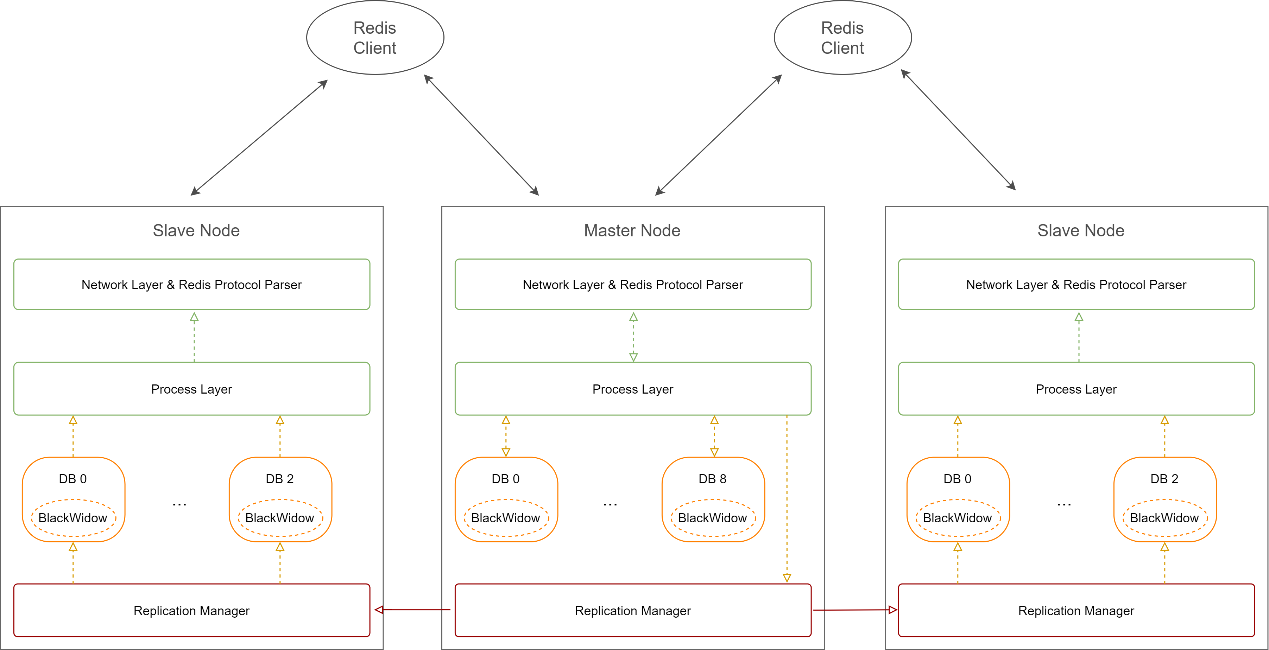
Mode classique (Classique) : c'est-à-dire 1 mode de synchronisation maître N esclave, 1 instance maître stocke toutes les données et N instances esclaves reflètent et synchronisent complètement les données du maître instance. Une instance prend en charge plusieurs bases de données. Les bases de données d'éléments de configuration de Pika vous permettent de définir le nombre maximum de bases de données pouvant être créées, en commençant par 0 par défaut. La forme physique de DB sur Pika est un répertoire de fichiers.
Architecture en mode distribué
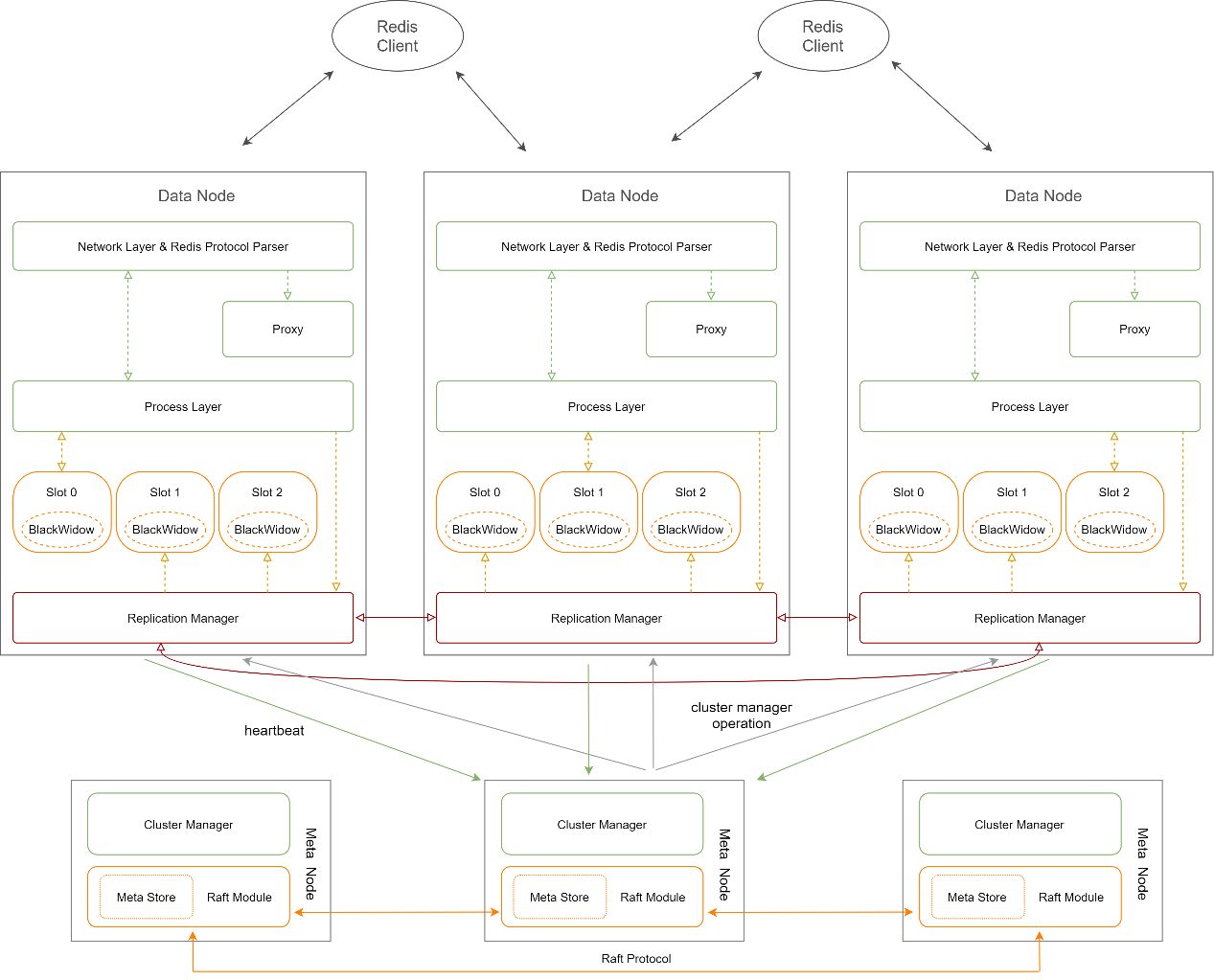
Mode distribué (Sharding) : En mode Sharding, la collection de données stockée par l'utilisateur est appelée Table, et chaque table est divisée en plusieurs fragments. Chaque fragment est appelé Slot. , et les données d'une certaine CLÉ sont calculées par un algorithme de hachage pour déterminer à quel emplacement elle appartient. Distribuez tous les Slots et leurs copies à toutes les instances Pika selon une certaine stratégie. Chaque instance Pika a une partie du Slot maître et une partie du Slot esclave. En mode Sharding, Slot est utilisé pour diviser le maître et l'esclave, et les instances Pika ne sont plus utilisées. La forme physique du slot sur Pika est un répertoire de fichiers.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!