
Maison >Périphériques technologiques >IA >La pratique de l'algorithme graphique dans le système de contrôle des risques d'Alibaba
La pratique de l'algorithme graphique dans le système de contrôle des risques d'Alibaba

- 王林avant
- 2023-05-29 19:28:041519parcourir

1. Introduction aux algorithmes graphiques dans les scénarios de contrôle des risques du commerce électronique
# 🎜 🎜#Tout d’abord, décrivons brièvement les caractéristiques de risque du commerce électronique d’Alibaba, ainsi que l’historique des applications et la situation actuelle des algorithmes graphiques.
1. Caractéristiques de risque du commerce électronique Ali
Ali e-commerce Les principales caractéristiques du risque : complexité conflictuelle et permutationnelle.
Les risques doivent être conflictuels, et les risques du commerce électronique d'Alibaba sont également complexes en termes de permutations et de combinaisons. L'identification des risques utilise principalement X (données) pour prédire Y (risque) : P(Y|X). Dans le commerce électronique Alibaba – Taobao, Xianyu, Tmall, 1688, Lazada, etc., les caractéristiques de risque des différents marchés sont différentes ; les scénarios commerciaux – comptes, produits, promotions, etc., et de nouveaux risques apparaîtront avec l'itération et innovation de l'entreprise ; Divers terminaux d'application - PC, H5, APP, etc., chaque terminal doit être prévenu et contrôlé #🎜🎜 ; #④ Des sources de données diverses nécessitent la capacité de traiter et d'intégrer des données provenant de différentes modalités.
En même temps, Y est également très compliqué, Cela se reflète principalement dans trois aspects. Le premier est qu'il existe de nombreux types de risques de contenu courants et les risques comportementaux ne sont qu'une goutte dans l'océan de nombreux risques. tels que la fraude du vendeur, l'enregistrement, le vol et le contenu du produit ; troisièmement, les risques seront transférés lorsqu'un type de risque est mieux évité et que le coût de la commission d'un crime devient plus élevé, il sera transféré à d'autres risques ou en créera de nouveaux. risques.
L'ensemble de la prévention et du contrôle des risques est donc très compliqué, avec la complexité des permutations et des combinaisons.
2. L'importance des algorithmes graphiques
Les algorithmes graphiques peuvent Améliorer la capacité de confrontation des modèles d’identification des risques. La plupart des « mauvaises choses » sur la plateforme ne sont faites que par quelques personnes. Les « méchants » ont de nombreux gilets. Nous pouvons découvrir les indices grâce aux « relations » et les identifier et les traiter à l'avance. Par exemple, le point jaune dans l'image ci-dessous, en supposant qu'il s'agit d'un utilisateur au comportement anormal, il est difficile de juger qu'il s'agit d'un utilisateur frauduleux sur la base de son seul comportement, mais il peut être analysé en analysant les trois autres utilisateurs frauduleux. qui lui est associé (points noirs) pour déterminer qu'il s'agit d'un utilisateur frauduleux. Dans le même temps, nous avons trouvé tous les comptes étroitement liés à ces quatre comptes et avons constaté qu'ils constituaient un groupe. Traiter ces comptes par lots à l'avance peut augmenter le coût de la commission du mal. De plus, des graphiques hétérogènes peuvent Intégrez naturellement et globalement les données de chaque modalité et de chaque objet à risque, calculez la représentation de chaque objet différent, puis identifiez différents risques pour faire face à la complexité des permutations et combinaisons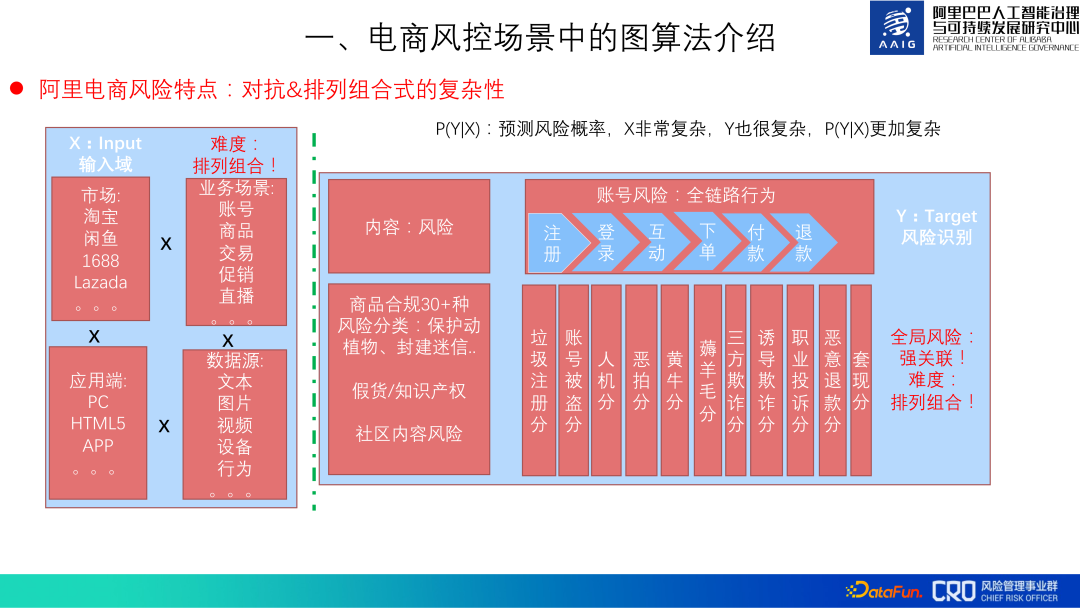 #🎜 🎜#
#🎜 🎜#
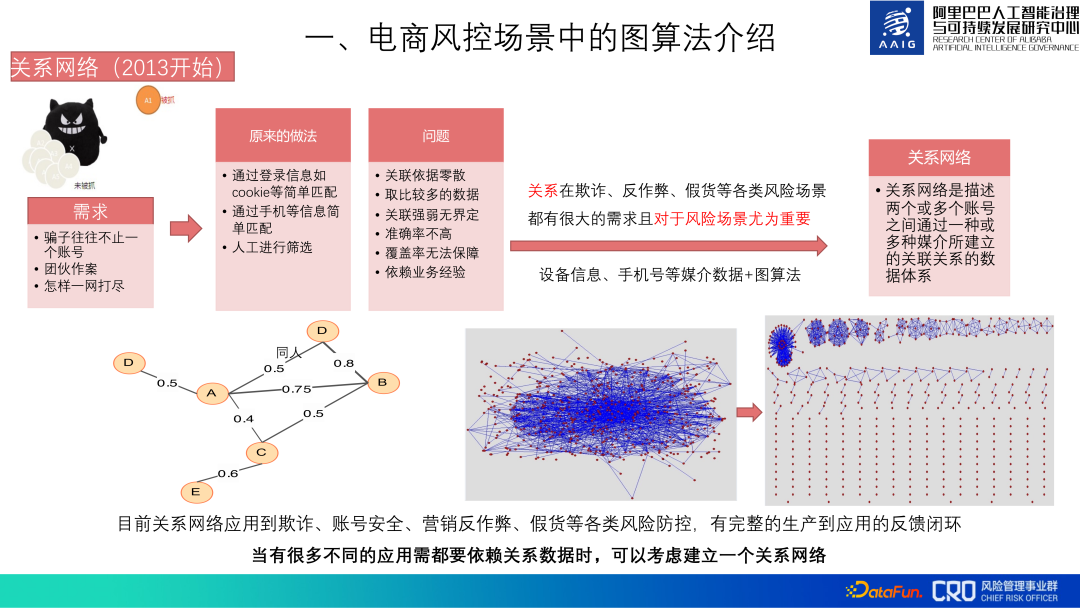
Basé sur l'importance des algorithmes graphiques, le contrôle des risques du commerce électronique d'Alibaba est en place depuis 2013 Utiliser des algorithmes graphiques.
Initialement, des algorithmes graphiques étaient utilisés pour construire le réseau relationnel de l'ensemble de la bibliothèque de comptes. Ces données relationnelles constituent les données de base nécessaires à tous les scénarios de prévention et de contrôle des risques tels que la fraude, la sécurité des comptes, la lutte contre la triche et les produits contrefaits. Les principales données utilisées comprennent les données multimédias telles que les informations sur les appareils et les numéros de téléphone mobile. Il décrit principalement la corrélation entre les comptes, les types de relations, l'identification du groupe, etc. Un canal de rétroaction en boucle fermée, de la production à l'application, a été établi pour ce réseau relationnel.
Il existe de nombreuses données relationnelles sous-jacentes. Le coût global de l'agrégation, du nettoyage, du calcul graphique et du stockage des données relationnelles est très élevé, et elles doivent être continuellement mises à jour ultérieurement, donc le coût de construction d'un réseau relationnel est très élevé. Mais comme bon nombre de nos modèles et stratégies de risque reposent sur ce réseau relationnel, cela en vaut toujours la peine.
Quant aux réseaux de neurones graphes, nous avons commencé à explorer des applications en 2016. A cette époque, nous nous appelions encore GGL (Geometric Graph Learning, apprentissage de graphes géométriques). pas de réseau de neurones graphiques directement disponible. Nous avons donc implémenté un cadre d'algorithme GGL en C++. En 2018, il a été déplacé vers Graph learn fourni par Alibaba Computing Platform. Ce framework est également open source. Nous avons également contribué au code de l'algorithme graphique.
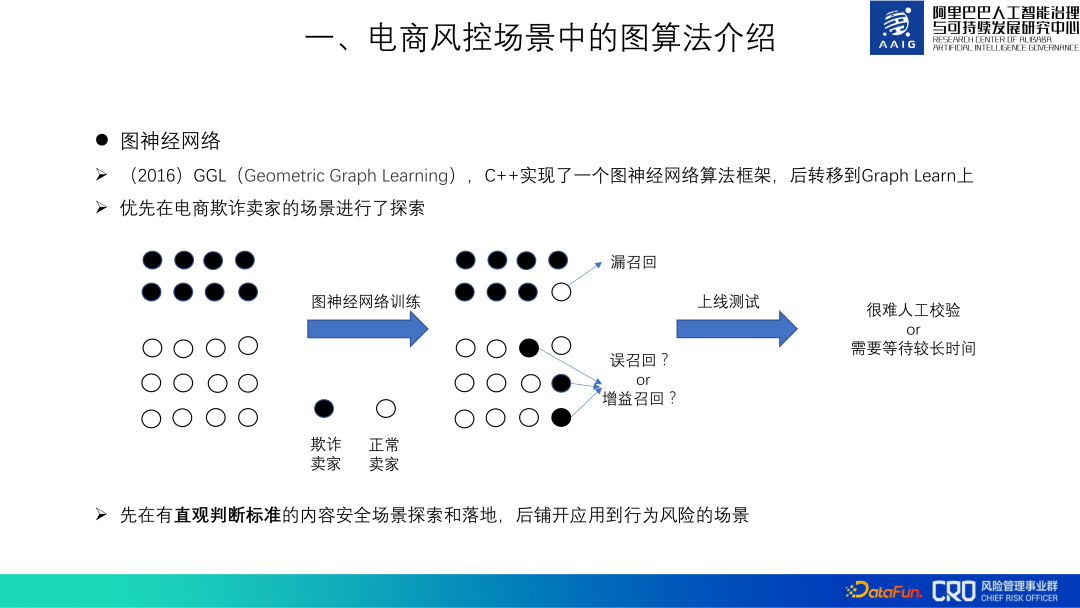
Il existe de nombreux scénarios de contrôle des risques du e-commerce, et il est particulièrement important de choisir le scénario approprié lors de l'étape de vérification de l'algorithme graphique. Les « critères de jugement » pour les risques comportementaux, qui représentent une grande partie des scénarios de risque, ne sont pas intuitifs. Dans les scénarios industriels, les échantillons blancs de risques comportementaux sont mélangés à de nombreux échantillons noirs non découverts lorsque l'algorithme graphique juge les échantillons blancs comme étant noirs. échantillons, il est difficile de juger s'il s'agit d'échantillons noirs ou non. Qu'il s'agisse d'un faux rappel ou d'un rappel de gain, cela affectera le réglage du modèle et le jugement de l'effet en ligne. Au contraire, les scénarios de sécurité des contenus, tels que le spam et les insultes, sont des scénarios avec des « critères de jugement intuitifs » et sont plus adaptés pour vérifier l'efficacité des algorithmes graphiques. Par conséquent, nous explorons d’abord l’algorithme dans des scénarios de sécurité du contenu, vérifions son efficacité et accumulons les meilleures pratiques, puis l’appliquons à des scénarios de risque comportemental.
Jusqu'à présent, les algorithmes graphiques sont utilisés dans diverses activités à risque du commerce électronique d'Alibaba. L'ensemble du cadre d'application de l'algorithme graphique est présenté ci-dessous. Premièrement, une couche de données relationnelles est conservée en bas pour collecter et nettoyer diverses données relationnelles afin de faciliter l'application de la couche supérieure. Au-dessus de la couche de données, les algorithmes graphiques couramment utilisés sont. précipité ; la couche suivante utilise la couche de données relationnelles et la couche d'algorithmes pour construire un réseau de relations de compte, qui prend en charge horizontalement la prévention et le contrôle de divers scénarios de risque dans la couche commerciale supérieure, combinés avec les caractéristiques de risques spécifiques ; , nous utilisons ces algorithmes graphiques et ces données relationnelles pour créer un modèle graphique permettant d'identifier divers risques commerciaux.
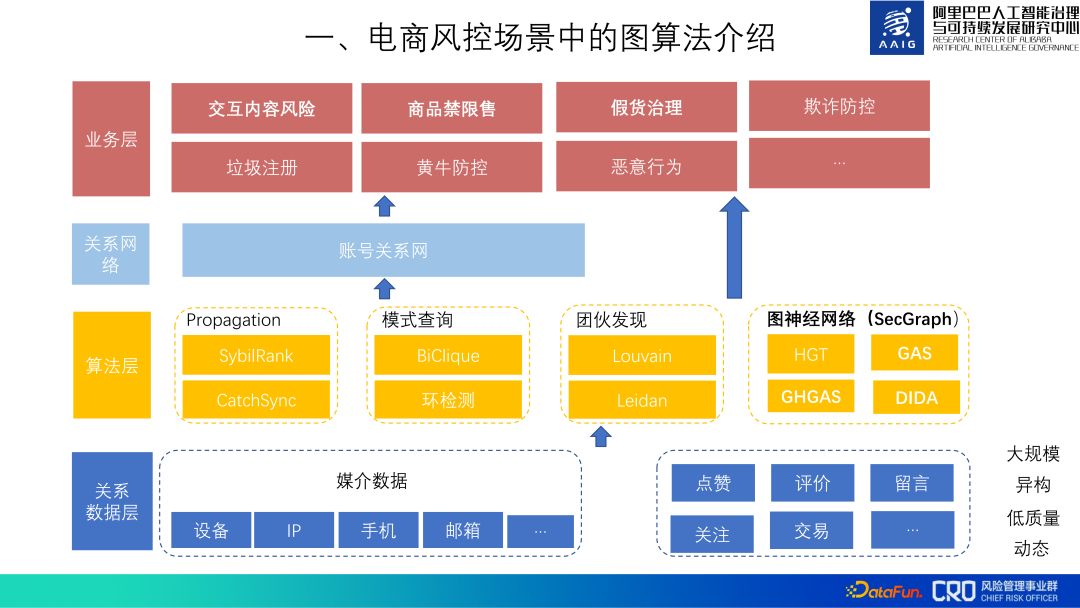
Le partage suivant présentera principalement quelques algorithmes graphiques pour les trois types d'applications à risque : "risque de contenu interactif", "interdiction et restriction de vente de produits de base" et "gestion des produits contrefaits".
2. Algorithme graphique pour le contrôle interactif des risques de contenu
La plate-forme de commerce électronique Alibaba propose de riches scénarios de contenu interactif, tels que l'évaluation des produits, les commentaires, les questions à tout le monde, ainsi que les achats mobiles Taobao, la communauté Xianyu, etc. Ce qui suit utilise l'identification des publicités de spam dans les messages Xianyu comme exemple pour présenter l'algorithme du graphique de contrôle des risques de contenu.
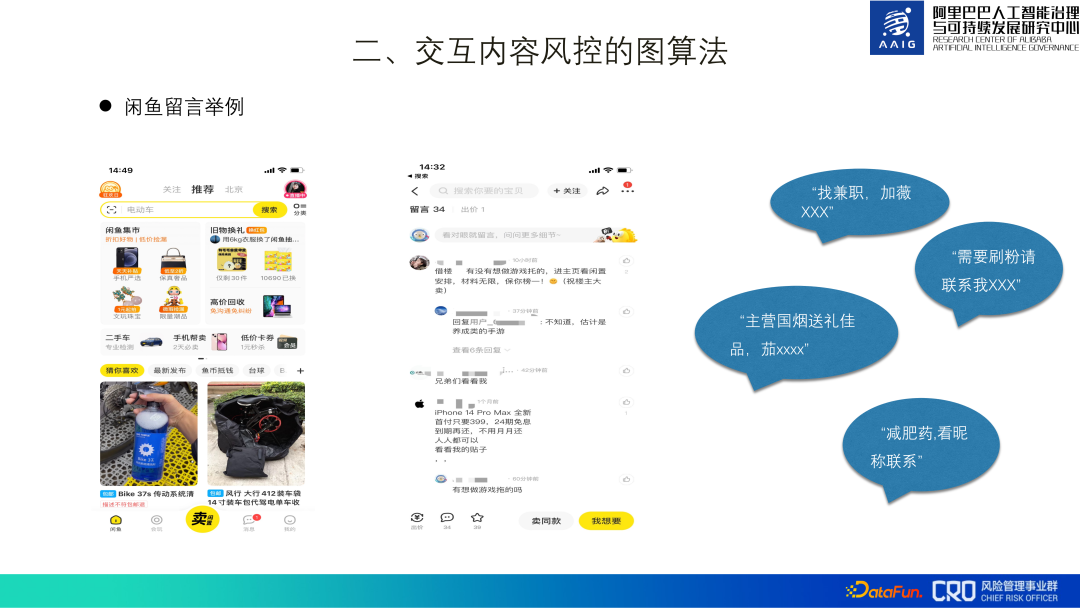
Il est facile de voir les risques de contenu tels que les « publicités spam » dans les commentaires sur les produits dans l'application Xianyu, tels que les emplois à temps partiel, les fausses commandes, la vente de pilules amaigrissantes, etc. , et ils sont très conflictuels. Par exemple, dans la capture d'écran ci-dessus de « Frère, regarde-moi », la véritable publicité n'est pas dans le texte lui-même, mais sur la page d'accueil de l'utilisateur.
L'identification des publicités spam dans les messages Xianyu est le premier scénario d'application de notre algorithme de réseau neuronal graphique. Nous appelons ce modèle d'identification GAS en abrégé. L'ensemble du modèle se compose d'un graphe hétérogène et d'un graphe homogène. Le graphe hétérogène apprend la représentation locale de chaque nœud, y compris les produits, les commentaires et les utilisateurs. Le graphe homogène est un graphe de commentaires qui apprend la représentation globale de différents commentaires. Enfin, ces quatre représentations sont fusionnées pour la formation du modèle de classification binaire.
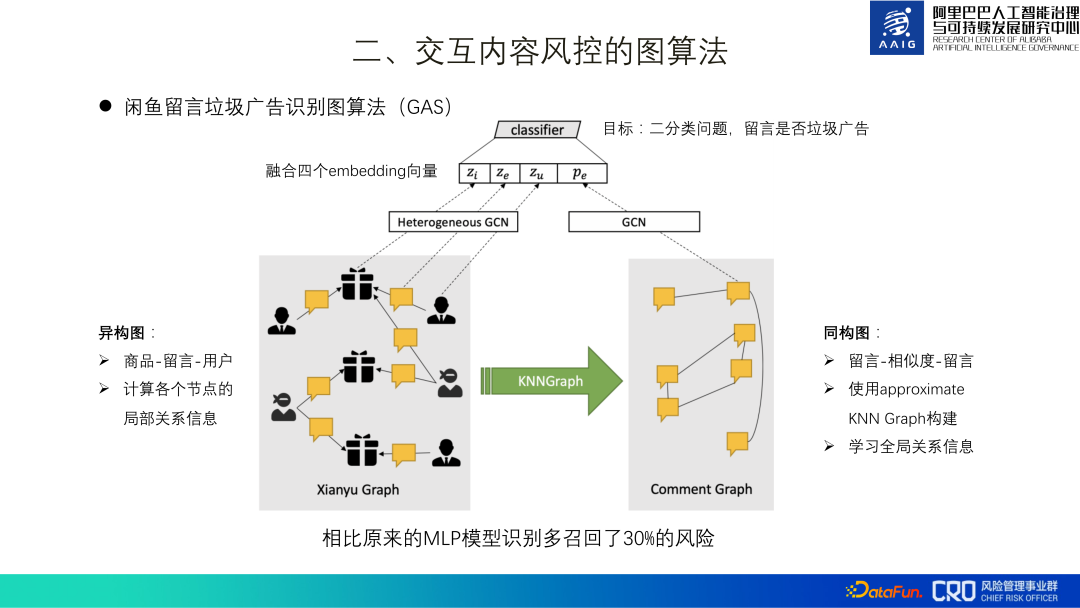
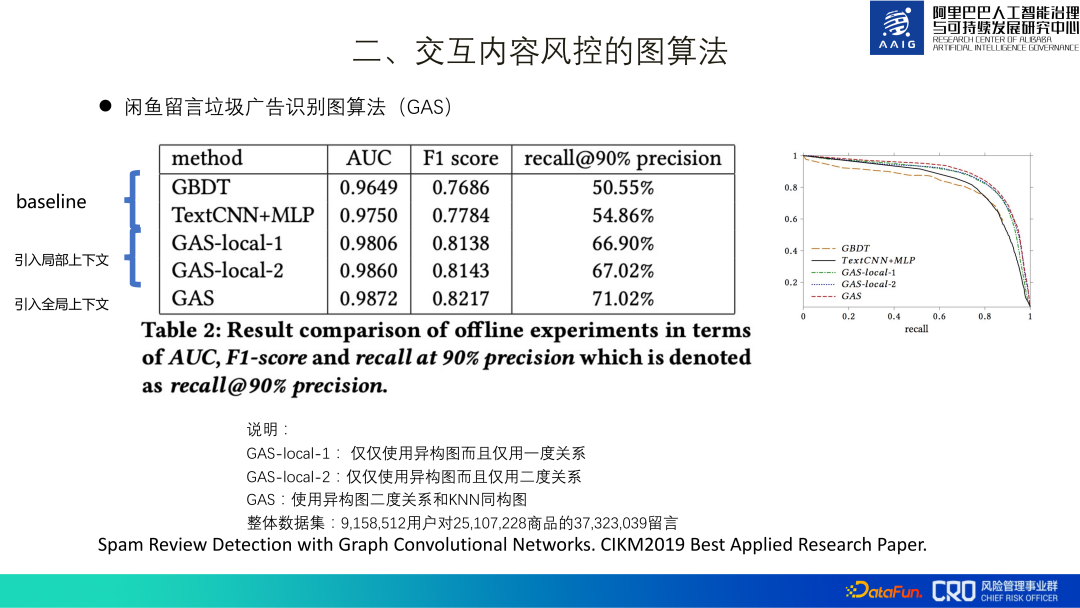
L'ensemble global de données de formation comprend plus de 3 kW de commentaires, plus de 2 kW de produits et plus de 9 millions d'utilisateurs. Après sa mise en ligne, il a rappelé 30 % de risques en plus que le modèle MLP d'origine. En outre, des expériences d'ablation ont également confirmé que l'ajout d'informations globales est également considérablement amélioré. Cela est dû aux caractéristiques de la publicité spam elle-même : elle nécessite un grand nombre de transferts pour obtenir de meilleurs avantages. Ce travail a finalement été compilé et publié dans un article[1], et a remporté le prix du meilleur article de recherche appliquée du CIKM2019.
3. 🎜🎜#
Ici, nous introduisons principalement deux types d'algorithmes graphiques pour le contrôle des risques du contenu des produits : l'un est l'apprentissage de la structure des graphiques de produits et l'autre est la structure des graphiques de produits et les professionnels. fusion de graphes de connaissances.

La gestion des risques sur matières premières consiste principalement à maîtriser les risques de « ventes interdites et ventes restreintes", de nombreux types de marchandises ne peuvent pas être vendus conformément aux lois et réglementations nationales, telles que les animaux et les plantes protégés au niveau national, la tricherie et la contrefaçon, les dispositifs médicaux contrôlés, etc.
La gestion et le contrôle des produits sont très compliqués. Les données sur les produits sont multi-flux de données, multi-canaux et multimodaux. : # 🎜🎜#
① Flux de données multiples : Titre, description, image principale, sous-image, images détaillées, SKU ; Le son, la forme et la signification de l'image, le RVB de l'image 🎜#Texte, images, méta-informations (prix, volume des ventes).
Dans le même temps, les risques liés au contenu des produits sont également complexes, diversifiés et farouchement contestés. il semble vendre des perles, mais en fait il vend de l'ivoire. Il existe deux principaux types d'algorithmes de carte de contrôle des risques liés au contenu des produits : l'un est un modèle de fusion multimodal, qui utilise une analyse approfondie modèle pour construire un Le réseau neuronal des biens effectue un apprentissage multitâche par fusion multimodale, qui est l'apprentissage des informations locales sur les biens ; l'autre consiste à améliorer le rappel des risques, en utilisant des graphiques hétérogènes pour établir des biens et des biens ; et les vendeurs, et les vendeurs et la relation entre les vendeurs, et mener un apprentissage par fusion d'informations globales.
1. Apprentissage de la structure graphique des images de produits GCN's L'essence est le lissage des caractéristiques qui fusionne les caractéristiques voisines. Par conséquent, l'apprentissage des réseaux de neurones graphiques a certaines exigences sur la qualité de la structure du graphe. Un bon graphe de réseau est dense et a un taux d'homogénéité élevé. Cependant, le graphique des produits de risque est clairsemé et le taux d'homogénéité est relativement faible (0,15, et les statistiques sur les ensembles de données publiques ont montré que 0,6 ou plus est meilleur), nous devons donc apprendre la structure du graphique.
Il existe trois types de bords dans l'image du produit, qui forment trois types d'images, comme indiqué ci-dessous Comme indiqué dans l'image du cadre à droite : la première catégorie est la même image du vendeur où les deux produits sont vendus par le même vendeur, la deuxième catégorie est la même image de navigation où les deux produits ont été vu par le même consommateur, et la troisième catégorie est les vendeurs des deux produits ont de nombreuses similitudes graphique vendeur associé fortement. L'essence de l'apprentissage de la structure du graphe de produit est le processus d'ajout et de suppression d'arêtes : utilisez d'abord KNN Graph pour construire un graphe KNN basé sur l'intégration du produit, puis combinez les quatre types d'arêtes ci-dessus avec le produit. Assemblez l'intégration dans HGT pour apprendre la nouvelle intégration du produit et supprimez les arêtes avec des valeurs d'attention inférieures en tant que bruit. L'intégration du nouveau produit peut être utilisée pour mettre à jour le graphique KNN, et itérer d'avant en arrière jusqu'à ce que la perte converge. La pratique sur des données réelles montre que ce cadre d'apprentissage de la structure des graphes permet d'obtenir des résultats SOTA par rapport aux graphiques homogènes/graphiques hétérogènes.
2. Intégration du calcul graphique et du graphe de connaissance des risques
L'algorithme d'amélioration de l'algorithme du graphe de produit est la fusion du calcul graphique et du graphe de connaissance des risques. Certains risques liés aux matières premières sont difficiles à évaluer avec le bon sens et nécessitent une combinaison de certaines connaissances professionnelles. Par conséquent, des graphiques de connaissances spécifiques ont été construits pour ces points de connaissance spécifiques du domaine de risque afin de faciliter l'identification du modèle et l'examen manuel.
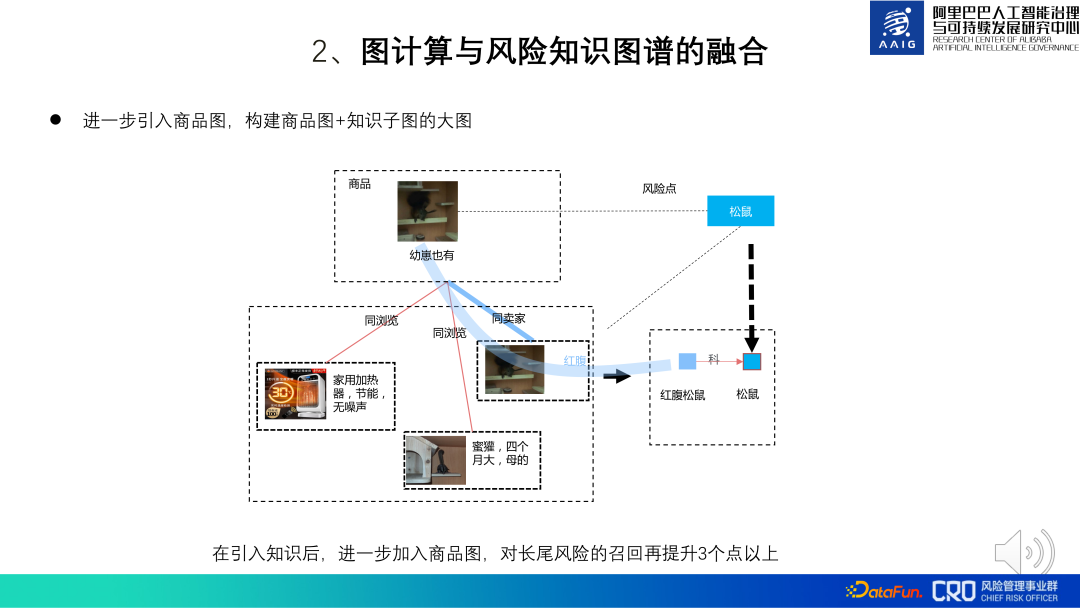
Par exemple, les deux produits présentés sur le côté gauche de l'image ci-dessous semblent vendre des accessoires simples, mais en fait ils vendent des cornes d'antilope tibétaine. L'antilope tibétaine est un animal protégé au niveau national. et ses produits associés sont interdits à la vente, nous pouvons identifier le risque de ce produit en le faisant correspondre aux connaissances liées à l'antilope tibétaine. Le cadre de l'algorithme de fusion est présenté sur le côté droit de la figure ci-dessous : l'objectif du modèle est de déterminer si les produits candidats et les points de connaissance des risques correspondent. L'élément p est la représentation graphique du produit et le point de risque R est la représentation du point de connaissance. Grâce à la reconnaissance d'entité, à la liaison d'entités et à l'extraction de relations, le sous-graphe du produit et le point de connaissance sont obtenus, puis GNN est utilisé. pour calculer la représentation du sous-graphe, et enfin la représentation est utilisée. Effectuer la classification et l'identification des risques. Parmi eux, le CPR est une fusion de la représentation du produit et de la représentation des points de connaissance. Il est principalement utilisé pour guider la représentation graphique afin d'apprendre certaines informations globales. La pratique montre que par rapport à la reconnaissance multimodale des produits, la mémorisation des risques à longue traîne est améliorée de plus de 10 points grâce à l'ajout de graphiques de connaissance des risques.
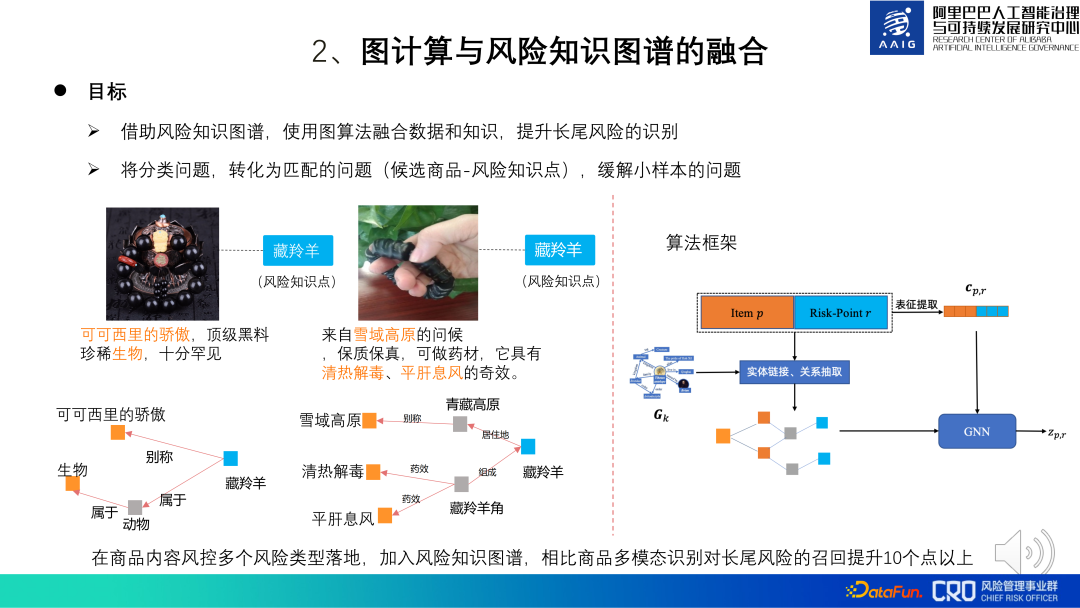
Sur cette base, nous avons également essayé d'introduire une cartographie globale des produits. Lorsque le contenu du produit est directement lié à la carte des connaissances et que le risque ne peut pas être identifié, vous pouvez introduire davantage l'association entre le produit et le produit pour aider au jugement. Par exemple, dans l'image ci-dessous, un produit marqué « Il existe également ». "Les petits" et "l'écureuil à ventre rouge" n'ont pas de connaissances approfondies. Il existe une relation de correspondance, mais ce produit correspond aux connaissances du vendeur sur un autre produit "à ventre rouge" et "écureuil à ventre rouge", on peut donc en déduire que le le produit vend effectivement des écureuils à ventre rouge (animaux protégés secondairement, interdits à la vente). La pratique a montré que l'introduction de l'intégralité du grand graphique de produits lors d'un raisonnement fondé sur les connaissances peut augmenter le rappel des risques à longue traîne de plus de 3 %.
4. Pratique de contrôle des risques des graphes hétérogènes dynamiques
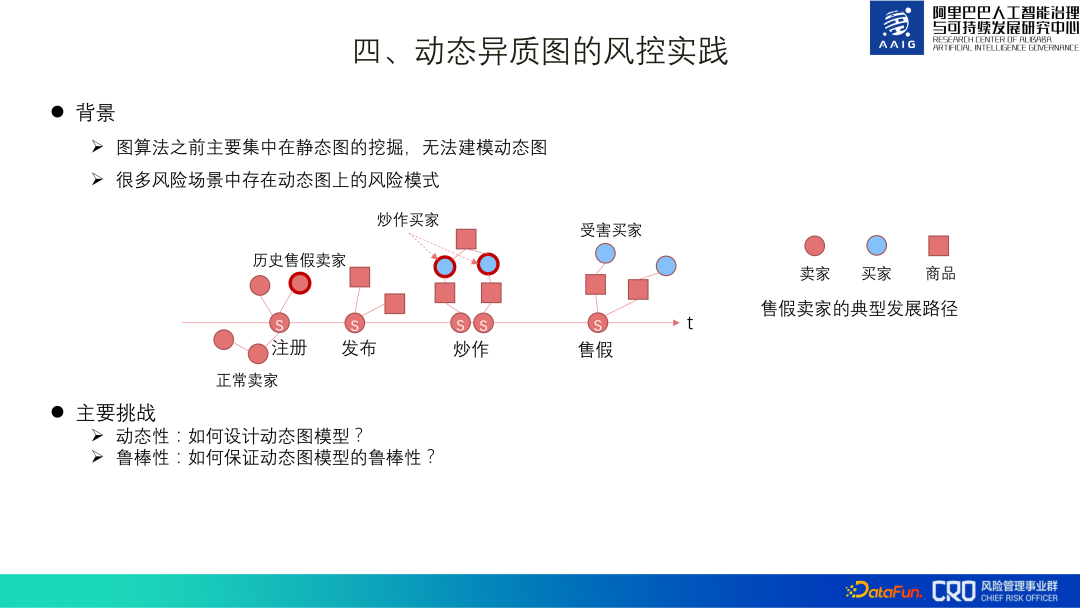
Les algorithmes de graphes introduits précédemment sont principalement des applications d'exploration de graphes statiques, mais de nombreux scénarios de risque ont le modèle de risque des graphes dynamiques.
Par exemple, un commerçant vendant des produits contrefaits s'enregistre d'abord, puis commercialise un grand nombre de produits par lots, les met en avant pour attirer du trafic, puis vend rapidement des produits contrefaits. Dans cette série d'actions, les changements se produisent. La structure graphique de la dimension temporelle est très importante pour notre identification des risques. Les graphiques dynamiques constituent donc également une direction clé pour l'exploration et l'application d'algorithmes graphiques.
Le plus grand défi des graphiques dynamiques est de savoir comment concevoir et rechercher une bonne structure graphique. D'une part, les graphiques dynamiques introduisent la dimension temporelle basée sur le graphique hétérogène d'origine. Par exemple, s'il y a 30 moments, alors les paramètres (quantité d'informations) du graphique dynamique sont 30 fois ceux du graphique hétérogène, ce qui apporte beaucoup. pression sur l'apprentissage D'un autre côté, en raison de la nature contradictoire des risques, les graphiques dynamiques doivent être très robustes.
1. Apprentissage automatique de graphiques dynamiques
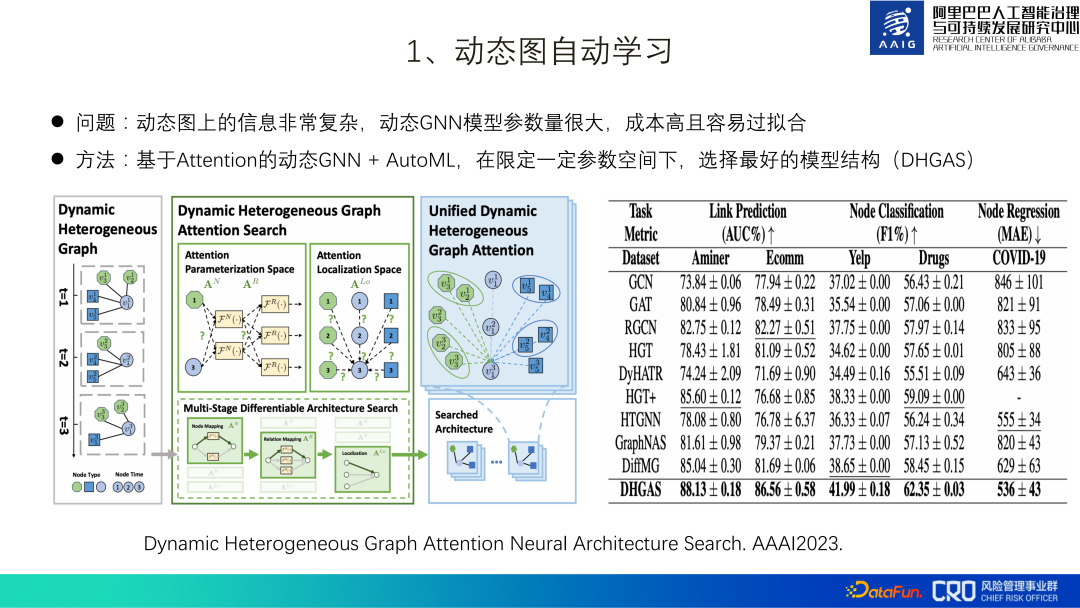
Selon cela, nous proposons un GNN + AutoML dynamique basé sur Attention, et sélectionnons la meilleure structure de modèle (DHGAS) sous un certain espace de paramètres. Le cœur de ce modèle est d'optimiser la structure du modèle grâce à l'apprentissage automatique, comme le montre la figure ci-dessous : il est d'abord préférable de décomposer le graphe dynamique en graphiques hétérogènes à différents moments, et de définir différents espaces de fonctions à différents moments et différents nœuds pour représentent les changements dans la représentation du produit (types N*T, N : type de nœud ; T : espace temporel), différents espaces de fonctions sont également configurés pour différents moments et différents types d'arêtes pour représenter l'espace de chemin de propagation de l'information (R*T). types, R : type de bord ; T : temps et espace), et enfin il existe des méthodes d'agrégation R*T*T lorsque les nœuds et les voisins sont agrégés (les deux T sont les horodatages des nœuds aux deux extrémités du bord.
Évidemment, l'ensemble de l'espace de recherche est énorme. Nous essayons de limiter l'espace des paramètres et d'utiliser la technologie d'apprentissage automatique pour créer un supernet afin que le modèle puisse rechercher automatiquement l'architecture réseau optimale. Méthode spécifique : limiter le nombre d'espaces fonctionnels de N*T à K_N, les données de l'espace fonctionnel de R*T à K_R et la longueur du module de R*T*T à K_Lo. Par exemple, N=6, T=30. , la théorie est un espace fonctionnel N*T=180, la limite réelle est K_N=10.
Cet algorithme a actuellement été mis en œuvre dans des scénarios tels que « l'identification de vendeurs contrefaits » et « l'identification de commerçants malveillants avec des ventes de marchandises restreintes », et par rapport aux algorithmes traditionnels de l'industrie, il a obtenu des résultats SOTA. Pour plus de détails, veuillez. reportez-vous au document [2].
2. Apprentissage robuste des graphiques dynamiques
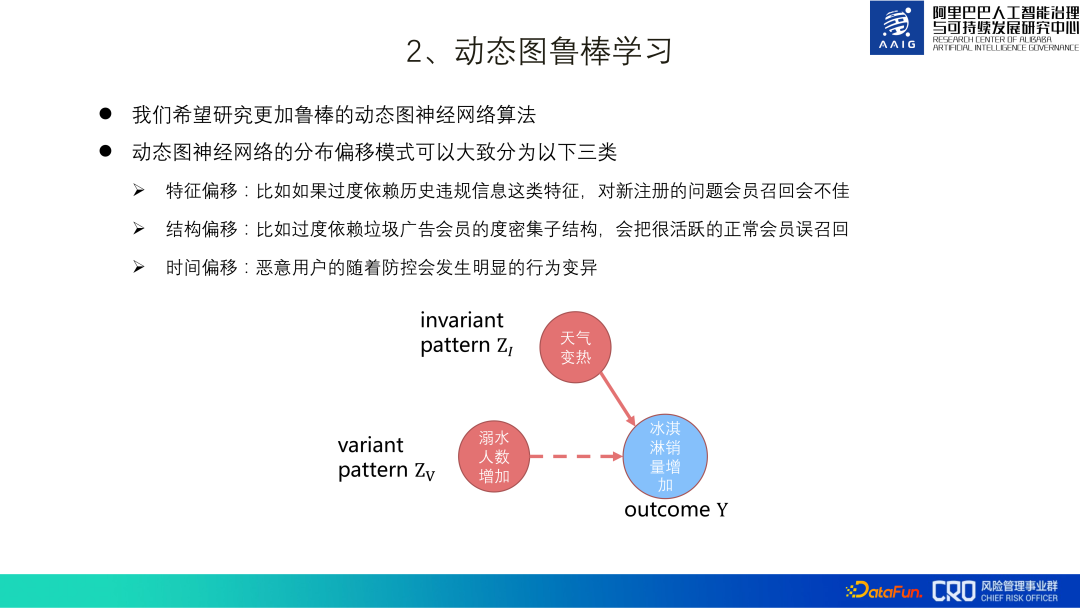
En raison de la nature conflictuelle des risques, les graphiques dynamiques doivent avoir une forte robustesse. L'essentiel est que J'espère que les graphiques dynamiques pourront apprendre certaines choses essentielles. pattern, par exemple, le modèle essentiel du sous-graphique d'exemple dans la figure ci-dessous est que l'augmentation des ventes de glaces est due au temps plus chaud, et non à l'augmentation du nombre de noyades.
Nous espérons qu'un apprentissage robuste pourra résoudre certains problèmes de changement de distribution des graphiques dynamiques de contrôle des risques du commerce électronique :
(1) Changement de fonctionnalité : Par exemple, si vous comptez trop sur les informations de violations historiques Ce type de fonctionnalité ne sera pas utile pour rappeler les membres problématiques nouvellement enregistrés
(2) Compensation structurelle : Par exemple, une dépendance excessive à l'égard de la sous-structure de degré-densité de la publicité spammée ; les membres entraîneront le rappel par erreur de membres normaux très actifs
(3) Décalage horaire : Les utilisateurs malveillants subiront des changements de comportement évidents avec prévention et contrôle.
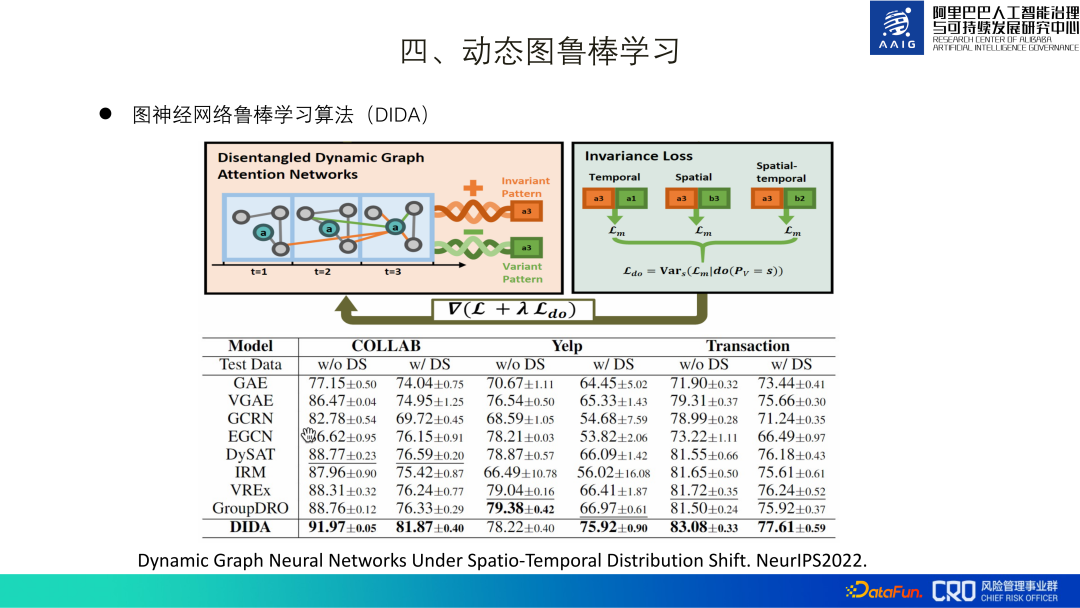
À cet égard, nous avons proposé un algorithme DIDA. L'idée de base est la suivante : lors de l'apprentissage des graphiques dynamiques, apprenez deux modèles - le modèle essentiel représenté par l'orange et le modèle non essentiel représenté. par vert. Utilisez simplement La perte (L) du modèle essentiel + la variance de perte (Ldo) de la combinaison de motifs non essentiels est utilisée comme perte finale apprise par le modèle. L'idée de conception de la variance de perte (Ldo) de la combinaison de motifs non essentiels est la suivante : supposer que le a3 vert sur l'image est un motif non essentiel, puis remplacer ce a3 vert par d'autres motifs non essentiels tels que b3, c3, etc. devraient améliorer la perte (discrimination) de la capacité du modèle) a peu d'impact. Par conséquent, nous pouvons ajouter la variance de perte des modèles non essentiels à l'apprentissage du modèle, et dans l'étape de prédiction finale, seuls les modèles essentiels sont utilisés pour la classification. À l'heure actuelle, cet algorithme a été mis en œuvre dans des scénarios de contrôle des risques liés au contenu des produits, et un article[3] a également été rédigé.
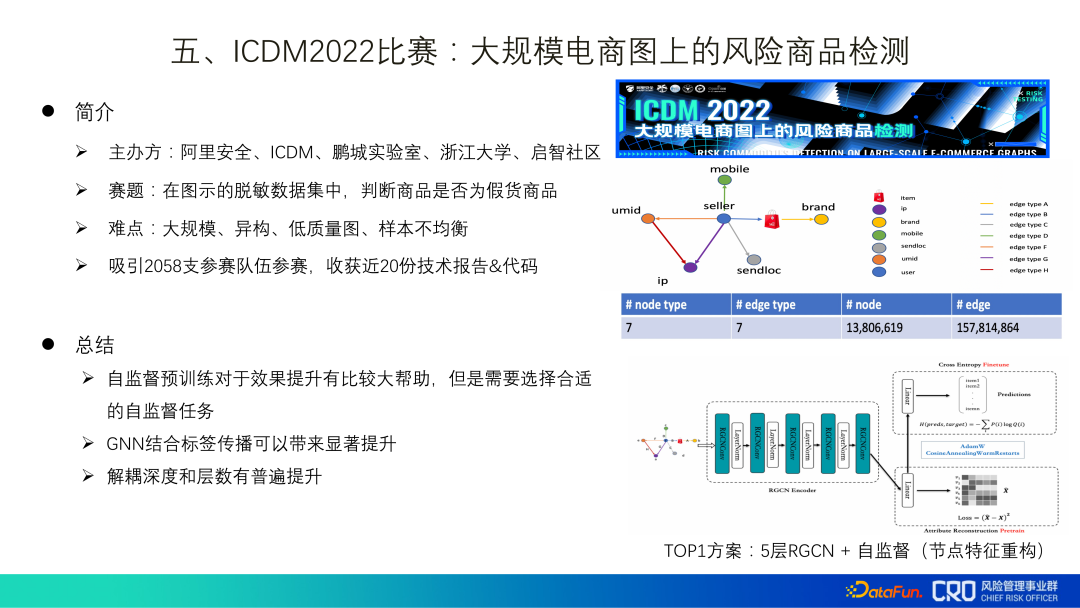
"Concours ICDM2022 : Détection de produits à risque sur des graphiques de commerce électronique à grande échelle" est un concours d'algorithmes que nous hébergé cette année, les données fournies sont des données désensibilisées de scènes réelles. Au final, je me suis également inspiré des codes techniques et des rapports soumis :
(1) Le pré-entraînement auto-supervisé est d'une grande aide pour améliorer l'effet, mais il est nécessaire de choisir l'auto-entraînement approprié -tâche supervisée ;
(2) GNN combiné à la propagation d'étiquettes peut apporter des améliorations significatives dans les applications d'algorithmes graphiques précédentes, cette partie des données a été rejetée en raison de problèmes de fuite d'étiquettes, mais après pratique sur des données réelles, il s'est avéré que ce n'était pas évident. La raison est supposée que le réseau de graphes actuel n'a réalisé que la fusion d'informations, mais n'a pas encore atteint le raisonnement ou a de faibles capacités de raisonnement
(3) La profondeur du découplage et le nombre de couches se sont généralement améliorés ; il peut être transmis une fois et agrégé plusieurs fois en même temps. 6. Résumé et perspectives des méthodes d'implémentation d'algorithmes graphiques : devrait Il existe un cadre d'algorithme graphique qui accumule la technologie et les meilleures pratiques pour améliorer la réutilisabilité de la technologie.
(2) Modélisation semi-automatique : afin d'améliorer l'efficacité de la modélisation, au niveau des données, nous ferions mieux de nettoyer et de résumer les données médiatiques relationnelles sous-jacentes, et au niveau de la modélisation, nous pouvons fournir certains composants (composant de sélection MetaPath/ MetaGraph, composant d'échantillonnage de graphiques, composant de récupération de vecteurs, etc.) pour améliorer l'efficacité de la modélisation.
(3) Appel automatisé : il peut appeler automatiquement des algorithmes graphiques ou des modèles graphiques qui reposent uniquement sur des échantillons d'entrée. Il n'est pas nécessaire de comprendre les modèles graphiques, ce qui est pratique pour les autres étudiants en contrôle des risques qui ne sont pas familiers avec. algorithmes graphiques pour optimiser l'utilisation de modèles, tels que l'identification des gangs, la récupération des produits, la récupération des utilisateurs à risque, etc.
(4) Représentation graphique de production (auto-supervisée) : utilisée comme entrée modale distincte dans le modèle, sans affecter la méthode de modélisation d'origine, améliorant considérablement les scénarios d'application des graphiques.
Perspectives de travaux de suivi :
(1) Apprentissage auto-supervisé des représentations de graphes à grande échelle. Nous disposons de milliers de modèles de risque, dont beaucoup n'appliquent pas l'algorithme graphique ci-dessus. Notre prochaine étape consiste donc à créer une représentation graphique auto-supervisée à grande échelle pour élargir le champ d'application des fonctionnalités graphiques et contribuer à améliorer les résultats commerciaux. Ce travail présente un double défi en ingénierie et en algorithmique : Premièrement, en termes d’ingénierie, nous disposons d’au moins des milliards de nœuds et de dizaines de milliards d’arêtes pour un apprentissage à grande échelle. Deuxièmement, en termes d’algorithmes, la représentation graphique ne doit pas couvrir uniquement les sujets communs. utilisé des représentations de relations, vous devez également apprendre les caractéristiques des structures graphiques d'ordre supérieur, qui sont très polyvalentes et peuvent être appliquées à divers scénarios.(2) Explorez les capacités de raisonnement des graphiques dans des scénarios de contrôle des risques spécifiques. À l'heure actuelle, les algorithmes graphiques concernent davantage la fusion des connaissances, et les capacités de raisonnement sont relativement faibles et ne peuvent pas faire face à la forte confrontation des risques. . Objectivement, nous avons besoin que notre modèle ait une forte intelligence, la capacité de raisonnement des graphiques est donc très importante. À l'heure actuelle, il est prévu de s'appuyer sur les riches scénarios interactifs et le contenu de la communauté Xianyu pour explorer l'algorithme.

(3) Plus d'exploration et de mise en œuvre dans la recherche dans le domaine fréquentiel et l'interprétabilité des graphiques hétérogènes dynamiques. Le but de la recherche dans le domaine fréquentiel est d’apprendre plus de détails sur les changements de structure des graphiques dans les graphiques dynamiques. L'interprétabilité nous aide à comprendre si l'algorithme a réellement appris les caractéristiques essentielles, d'une part, elle nous aide à améliorer l'algorithme, et d'autre part, elle peut également être mieux fournie aux étudiants en commerce pour la mise en œuvre de l'application.
Nous recherchons également une coopération académique dans les directions d'exploration ci-dessus, notamment dans le sens du raisonnement graphique. En parallèle, nous recrutons également des étudiants pour les algorithmes de graphes. Les étudiants intéressés peuvent me contacter.
7. Référence
1. Détection de l'examen du spam avec les réseaux convolutionnels graphiques CIKM2019 Meilleur document de recherche appliquée.

2. .
3. Réseaux de neurones à graphiques dynamiques sous changement de distribution spatio-temporelle NeurIPS2022.
8. Session de questions-réponses
Q1 : Quels sont les défis particuliers de la représentation graphique des scénarios de contrôle des risques, par rapport à la représentation graphique dans d'autres domaines ?
A1 : Les trois principaux défis : d'une part, la structure du graphe est mauvaise et le taux d'homogénéité est faible, d'autre part, la robustesse du graphe, en ; notre scène, en particulier le graphique dynamique, sa dérive de distribution est toujours très grave. Il y a un autre problème. La concentration de risque des échantillons noirs est très faible, pas 1:10 ou 1:20. Dans notre graphique, la concentration de certains risques dans le graphique est très faible. L'algorithme est supérieur à 1: 1w +, nos échantillons sont donc extrêmement déséquilibrés, c'est ce que nous devons résoudre.
Q2 : Quel est le modèle d'algorithme actuel d'apprentissage fédéré par graphes ? Existe-t-il une solution mature dans l'industrie ? Avez-vous des applications ou des considérations concernant l’apprentissage fédéré par graphes ?
A2 : Nous l'utilisons toujours principalement dans nos scénarios de commerce électronique. Bien sûr, nous avons également des entreprises non liées au commerce électronique, mais ces données. sont les nôtres Nous pouvons toujours utiliser nos propres données directement pour le contrôle des risques, nous n'avons donc pas encore utilisé l'apprentissage fédéré, mais il sera toujours nécessaire d'utiliser l'apprentissage fédéré par graphes plus tard, car nous effectuons maintenant la segmentation et l'isolation des données pour la sécurité des informations, et les données dans différents domaines ne peuvent pas être utilisées via une connexion, l'apprentissage fédéré par graphes devrait donc devenir une direction d'application à explorer à l'avenir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI