
Maison >développement back-end >Tutoriel Python >Quelles sont les méthodes de visualisation de données Python rapides et faciles à utiliser ?
Quelles sont les méthodes de visualisation de données Python rapides et faciles à utiliser ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-29 17:34:161275parcourir
La visualisation des données est une partie très importante des projets de science des données ou d'apprentissage automatique. En règle générale, vous devez effectuer une analyse exploratoire des données (EDA) au début d'un projet pour acquérir une certaine compréhension des données, et la création de visualisations peut vraiment rendre la tâche d'analyse plus claire et plus facile à comprendre, en particulier pour les données à grande échelle et de grande dimension. . ensemble. À l'approche de la fin d'un projet, il est également important de présenter le résultat final d'une manière claire, concise et convaincante que votre public (qui est souvent des clients non techniques) puisse comprendre.
Heat Map
Une méthode d'utilisation de la couleur pour représenter la valeur de chaque élément dans une matrice de données est appelée Heat Map. Grâce à l'indexation matricielle, deux éléments ou caractéristiques qui doivent être comparés sont associés et différentes couleurs sont utilisées pour représenter leurs différentes valeurs. Les cartes thermiques conviennent pour afficher les relations entre plusieurs variables de caractéristiques, car la couleur peut refléter directement la taille de l'élément de la matrice à cette position. Vous pouvez comparer chaque relation à d’autres relations dans l’ensemble de données via d’autres points de la carte thermique. En raison de la nature intuitive de la couleur, elle nous offre un moyen simple et facile à comprendre d’interpréter les données.
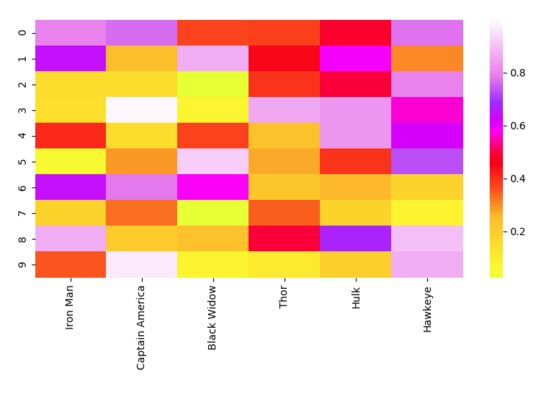
Jetons maintenant un œil au code d'implémentation. Par rapport à "matplotlib", "seaborn" peut être utilisé pour dessiner des graphiques plus avancés, qui nécessitent généralement plus de composants, tels que plusieurs couleurs, graphiques ou variables. « matplotlib » peut être utilisé pour afficher des graphiques, « NumPy » peut être utilisé pour générer des données et « pandas » peut être utilisé pour traiter des données ! Le dessin n'est qu'une simple fonction de "seaborn".
# Importing libs import seaborn as sns import pandas as pd import numpy as np import matplotlib.pyplot as plt # Create a random dataset data = pd.DataFrame(np.random.random((10,6)), columns=["Iron Man","Captain America","Black Widow","Thor","Hulk", "Hawkeye"]) print(data) # Plot the heatmap heatmap_plot = sns.heatmap(data, center=0, cmap='gist_ncar') plt.show()
Tracé de densité bidimensionnel
Le tracé de densité bidimensionnel (2D Density Plot) est une extension intuitive de la version unidimensionnelle du tracé de densité. Par rapport à la version unidimensionnelle, son avantage est qu'il peut. voir la distribution de probabilité de deux variables. Le tracé d'échelle de droite utilise la couleur pour représenter la probabilité de chaque point dans le tracé de densité 2D ci-dessous. L'endroit où nos données ont la plus forte probabilité d'occurrence (c'est-à-dire là où les points de données sont les plus concentrés) semble se situer autour de la taille = 0,5 et de la vitesse = 1,4. Comme vous le savez maintenant, les tracés de densité 2D sont très utiles pour trouver rapidement les zones où nos données sont les plus concentrées avec deux variables, par opposition à une seule variable comme un tracé de densité 1D. L'observation des données avec un tracé de densité bidimensionnel est utile lorsque vous disposez de deux variables importantes pour la sortie et que vous souhaitez comprendre comment elles fonctionnent ensemble pour contribuer à la distribution de la sortie.
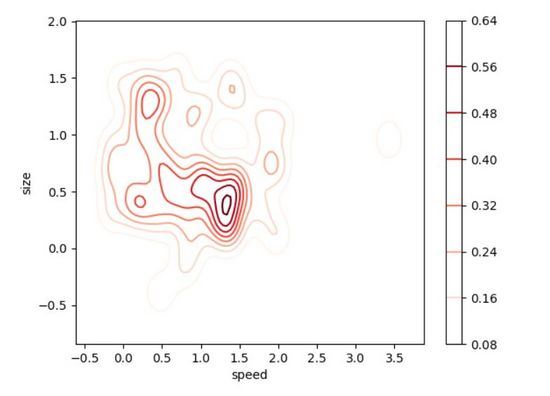
Les faits ont une fois de plus prouvé qu'utiliser "seaborn" pour écrire du code est très pratique ! Cette fois, nous allons créer une distribution asymétrique pour rendre la visualisation des données plus intéressante. Vous pouvez ajuster la plupart des paramètres facultatifs pour rendre la visualisation plus claire.
# Importing libs import seaborn as sns import matplotlib.pyplot as plt from scipy.stats import skewnorm # Create the data speed = skewnorm.rvs(4, size=50) size = skewnorm.rvs(4, size=50) # Create and shor the 2D Density plot ax = sns.kdeplot(speed, size, cmap="Reds", shade=False, bw=.15, cbar=True) ax.set(xlabel='speed', ylabel='size') plt.show()
Spider plots
Spider plots sont l'un des meilleurs moyens d'afficher des relations un-à-plusieurs. En d'autres termes, vous pouvez tracer et afficher les valeurs de plusieurs variables par rapport à une variable ou une catégorie spécifique. Dans un diagramme en toile d'araignée, l'importance d'une variable par rapport à une autre est claire et évidente car la zone couverte et la longueur à partir du centre deviennent plus grandes dans une direction particulière. Vous pouvez tracer côte à côte les différentes catégories d'objets décrites par ces variables pour voir les différences entre elles. Dans le tableau ci-dessous, il est facile de comparer les différents attributs des Avengers et de voir où ils excellent chacun ! (Veuillez noter que ces données sont définies de manière aléatoire et que je n'ai aucun parti pris contre les membres des Avengers.)
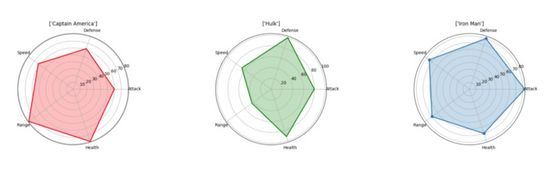
Nous pouvons utiliser "matplotlib" pour générer des résultats de visualisation sans utiliser "seaborn". Nous devons avoir chaque attribut également espacé autour de la circonférence. Il y aura des étiquettes sur chaque coin et nous tracerons les valeurs comme un point dont la distance du centre est proportionnelle à sa valeur/taille. Pour le montrer plus clairement, nous allons remplir la zone formée par les lignes reliant les points de propriété avec une couleur semi-transparente.
# Import libs
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Get the data
df=pd.read_csv("avengers_data.csv")
print(df)
"""
# Name Attack Defense Speed Range Health
0 1 Iron Man 83 80 75 70 70
1 2 Captain America 60 62 63 80 80
2 3 Thor 80 82 83 100 100
3 3 Hulk 80 100 67 44 92
4 4 Black Widow 52 43 60 50 65
5 5 Hawkeye 58 64 58 80 65
"""
# Get the data for Iron Man
labels=np.array(["Attack","Defense","Speed","Range","Health"])
stats=df.loc[0,labels].values
# Make some calculations for the plot
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,[stats[0]]))
angles=np.concatenate((angles,[angles[0]]))
# Plot stuff
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
ax.set_thetagrids(angles * 180/np.pi, labels)
ax.set_title([df.loc[0,"Name"]])
ax.grid(True)
plt.show()Treemap
Nous avons appris à utiliser les treemaps depuis l'école primaire. Parce que les diagrammes arborescents sont naturellement intuitifs, ils sont faciles à comprendre. Les nœuds directement connectés sont étroitement liés, tandis que les nœuds avec plusieurs connexions sont moins similaires. Dans la visualisation ci-dessous, j'ai tracé un dendrogramme d'un petit sous-ensemble de l'ensemble de données du jeu Pokémon basé sur les statistiques de Kaggle (santé, attaque, défense, attaque spéciale, défense spéciale, vitesse).
因此,统计意义上最匹配的口袋妖怪将被紧密地连接在一起。例如,在图的顶部,阿柏怪 和尖嘴鸟是直接连接的,如果我们查看数据,阿柏怪的总分为 438,尖嘴鸟则为 442,二者非常接近!但是如果我们看看拉达,我们可以看到其总得分为 413,这和阿柏怪、尖嘴鸟就具有较大差别了,所以它们在树状图中是被分开的!当我们沿着树往上移动时,绿色组的口袋妖怪彼此之间比它们和红色组中的任何口袋妖怪都更相似,即使这里并没有直接的绿色的连接。
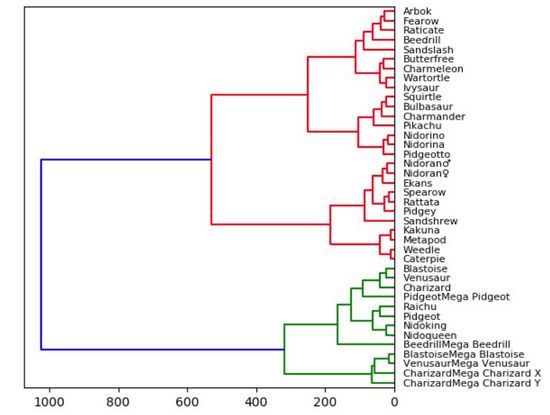
实际上,我们需要使用「Scipy」来绘制树状图。一旦读取了数据集中的数据,我们就会删除字符串列。这么做只是为了使可视化结果更加直观、便于理解,但在实践中,将这些字符串转换为分类变量会得到更好的结果和对比效果。我们还创建了数据帧的索引,以方便在每个节点上正确引用它的列。告诉大家的最后一件事是:在“Scipy”中,计算和绘制树状图只需一行简单代码。
# Import libs import pandas as pd from matplotlib import pyplot as plt from scipy.cluster import hierarchy import numpy as np # Read in the dataset # Drop any fields that are strings # Only get the first 40 because this dataset is big df = pd.read_csv('Pokemon.csv') df = df.set_index('Name') del df.index.name df = df.drop(["Type 1", "Type 2", "Legendary"], axis=1) df = df.head(n=40) # Calculate the distance between each sample Z = hierarchy.linkage(df, 'ward') # Orientation our tree hierarchy.dendrogram(Z, orientation="left", labels=df.index) plt.show()
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!