
Maison >Opération et maintenance >exploitation et maintenance Linux >Que signifie le numéro de nœud Linux i-node ?
Que signifie le numéro de nœud Linux i-node ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-29 17:19:412192parcourir
Le numéro d'inode est le numéro d'identification utilisé pour distinguer les différents fichiers du système Linux. Linux utilise en interne les numéros d'inodes pour identifier les fichiers, plutôt que les noms de fichiers. Pour le système, les noms de fichiers sont un autre nom pour les numéros d'inodes, ce qui permet aux utilisateurs d'identifier les fichiers. Il existe une correspondance biunivoque entre les noms de fichiers et les inodes. numéros, et chaque numéro d'inode correspond à un nom de fichier.
1. i node sous Linux
Sous Linux, i node fait référence au nœud inode.
Sous Linux, la recherche de fichiers ne se fait pas par nom de fichier. En fait, la recherche et le positionnement des fichiers se font via i nœuds. Nous pouvons visualiser le nœud i comme un pointeur fip. Lorsqu'un fichier est stocké sur le disque, le fichier sera certainement stocké dans un emplacement du disque. Vous pouvez imaginer que puisque les données du fichier sont stockées sur le disque, si nous connaissons l'adresse des données du fichier, quand nous voulons lire et lire. écrire le fichier À ce stade, pouvons-nous simplement utiliser cette adresse pour trouver le fichier ?
Oui, sous Linux, l'i-node peut en fait être considéré comme ceci. L'i-node est considéré comme une adresse pointant vers la zone de stockage de fichiers sur le disque. Normalement, nous ne pouvons pas utiliser cette adresse directement, mais devons l'utiliser indirectement via le nom du fichier. En fait, en plus de l'adresse de la zone de stockage des données du fichier, le nœud i contient également une grande quantité d'autres informations, telles que la taille du fichier, les informations sur le fichier, etc. Mais le nœud i n'enregistre pas le nom du fichier. Le nom du fichier est enregistré dans une entrée du répertoire. Chaque entrée du répertoire contient le nom du fichier et l'i-node.
Nous pouvons utiliser un diagramme pour voir la relation entre les éléments du répertoire, les nœuds i et les données du fichier.
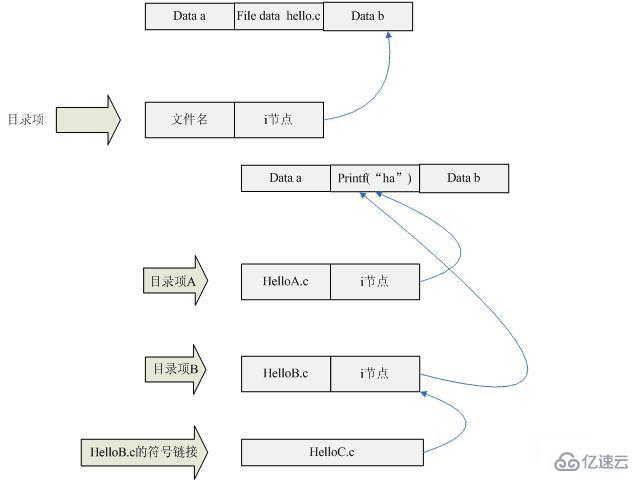
Comme vous pouvez le voir sur l'image ci-dessus, l'entrée du répertoire contient le nom du fichier et le nœud i.
En même temps, vous constaterez que dans la figure ci-dessus, les i nœuds de l'élément de répertoire A et de l'élément de répertoire B pointent vers la même zone de stockage, et cette zone de stockage stocke les données de printf ("ha").
Cela signifie que le contenu de helloA.c et helloB.c est le même.
i Numéro de nœud
Chaque inode a un numéro (c'est-à-dire un numéro d'inode) et le système d'exploitation utilise le numéro d'inode pour identifier différents fichiers.
————Linux utilise en interne les numéros d'inode pour identifier les fichiers, pas les noms de fichiers. Pour le système, les noms de fichiers sont un autre nom pour les numéros d'inode, ce qui permet aux utilisateurs d'identifier les fichiers. entre les noms de fichiers et les numéros d'inode, chaque numéro d'inode correspond à un nom de fichier.
Le numéro d'inode est le seul code reconnu par le système, et le nom de fichier sert uniquement à l'identification de l'utilisateur. La table inode (nœud d'index) contient une liste de tous les fichiers du système de fichiers. entrée de table contenant des informations sur les fichiers associés (métadonnées).
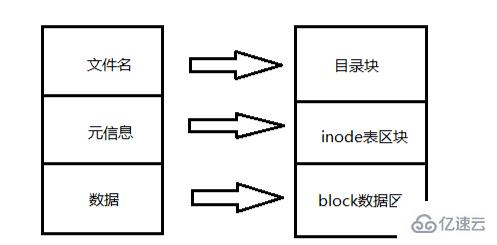
La structure du disque dur après le partitionnement :
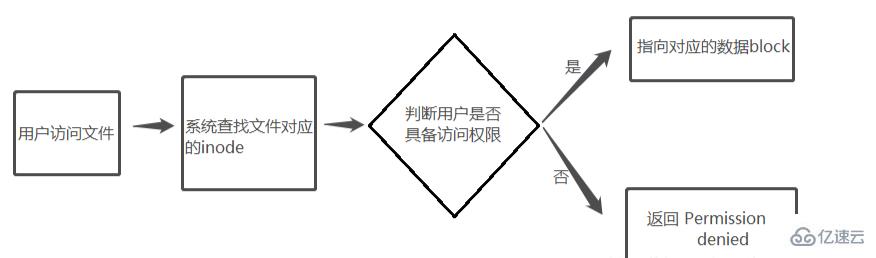
Lorsqu'un utilisateur tente d'accéder à un fichier dans le système Linux, le système recherchera d'abord son numéro d'inode correspondant en fonction du nom du fichier pour obtenir l'inode ; informations via le numéro d'inode ; basé sur les informations d'inode pour voir si l'utilisateur est autorisé à accéder à ce fichier ; si c'est le cas, pointez vers le bloc de données correspondant et lisez les données, sinon, il reviendra ;
Processus simple pour accéder aux fichiers :
2. Stockage de fichiers Linux
2.1 Limite du nombre d'inodes
Les inodes consommeront également de l'espace sur le disque dur, donc lors du formatage, le système d'exploitation Divisez automatiquement le disque dur en deux zones : l'une est la zone de données, qui stocke les données du fichier ; l'autre est la zone d'inode, qui stocke les informations contenues dans l'inode. La taille de chaque inode est généralement de 128 octets ou 256 octets.
Normalement, vous n'avez pas besoin de prêter attention à la taille d'un seul inode, mais vous devez vous concentrer sur le nombre total d'inodes. Le nombre total d'inodes a été déterminé lors du formatage
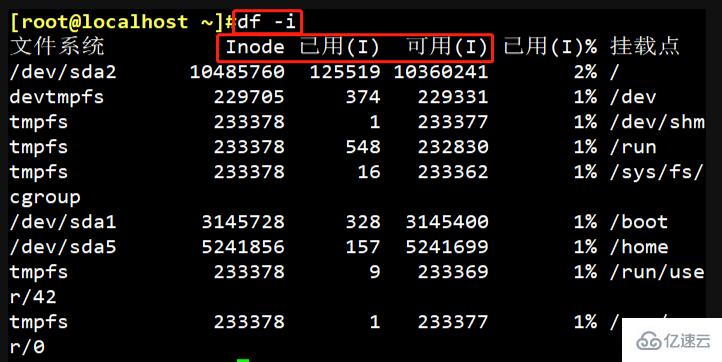
——Pourquoi. faut-il se concentrer sur le nombre total d'inodes ? Parce queLorsque les inodes sont épuisés À ce stade, de nouveaux fichiers ne peuvent pas être créés même s'il y a encore de l'espace sur le disque, car lors de la création d'un fichier, un numéro d'inode doit correspondre et de nouveaux fichiers ne peuvent pas être créés sans inode. Exécutez la commande "
df-i" pour afficher le nombre total d'inodes correspondant à chaque partition du disque dur et le nombre d'inodes utilisés.
2.2 Le contenu de l'inode
inode contient les méta-informations du fichier, notamment le contenu suivant :- Le nombre d'octets du fichier
- Le propriétaire de l'ID utilisateur du fichier
- L'ID de groupe du fichier
- Les autorisations de lecture, d'écriture et d'exécution du fichier
- Le nombre de liens, c'est-à-dire le nombre de fichiers pointant vers cet inode
- L'horodatage du fichier
- Deux façons d'afficher les informations d'inode d'un fichier
Première méthode : stat [nom du fichier]
Exemple : stat aa.txt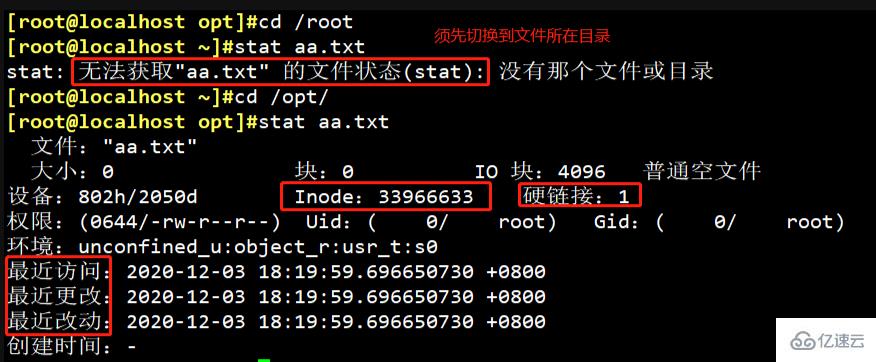
Avantages : Vous pouvez afficher les informations détaillées de l'inode du fichier
Méthode 2 : ls -i [nom du fichier]

Seul le numéro de l'inode peut être affiché
2.3 Trois fichiers système Linux Les principaux attributs temporels
Les trois principaux attributs temporels des fichiers système Linux (c'est-à-dire l'horodatage dans l'inode)
ctime (heure de changement)
fait référence au dernier change fichier ou répertoire ( attribut) L'heureatime (heure d'accès)
fait référence à la dernière fois accédé au fichier ou répertoiremtime (heure de modification)
fait référence à la dernière modification fichier ou répertoire (contenu ) time
3. Le rôle particulier de l'inode
En raison de la séparation du numéro d'inode et du nom de fichier, certains systèmes Unix/Linux ont le phénomène suivant :
Lorsque le nom du fichier contient caractères spéciaux, il peut être impossible de supprimer le fichier normalement, de supprimer l'inode directement ou de supprimer le fichier
Lors du déplacement ou du renommage d'un fichier, seul le nom du fichier est modifié et le numéro d'inode n'est pas affecté
Après en ouvrant un fichier, le système identifie le fichier par le numéro d'inode, ne prend plus en compte le nom du fichier
-
Une fois les données du fichier modifiées et enregistrées, un nouveau numéro d'inode sera généré (le numéro d'inode d'origine sera libéré)
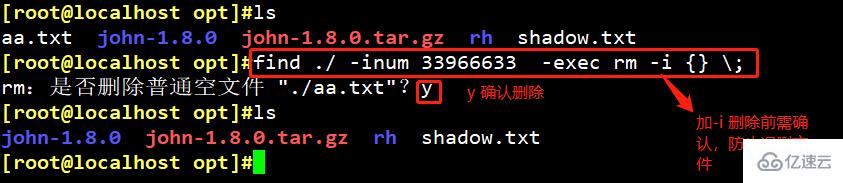
Comment supprimer un fichier en supprimant le numéro d'inode :
méthode 1 (les informations doivent être confirmées avant la suppression) : find ./ -inum [numéro d'inode] -exec rm -i {} ;
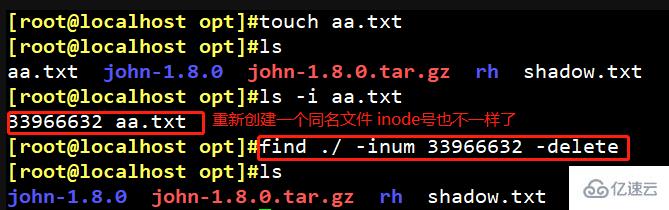
Deuxième méthode (suppression directe) : find ./ -inum [numéro d'inode] -delete
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Apprenez à installer le serveur Nginx sous Linux
- Introduction détaillée à la commande wget de Linux
- Explication détaillée d'exemples d'utilisation de yum pour installer Nginx sous Linux
- Explication détaillée des problèmes de connexions des travailleurs dans Nginx
- Explication détaillée du processus d'installation de python3 sous Linux