
Maison >Périphériques technologiques >IA >Tout le monde comprend ChatGPT Chapitre 1 : ChatGPT et traitement du langage naturel
Tout le monde comprend ChatGPT Chapitre 1 : ChatGPT et traitement du langage naturel

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-29 15:54:591407parcourir

ChatGPT (Chat Generative Pre-training Transformer) est un modèle d'IA qui appartient au domaine du traitement du langage naturel (NLP) qui est une branche de l'intelligence artificielle. La langue dite naturelle fait référence à l'anglais, au chinois, à l'allemand, etc. avec lesquels les gens entrent en contact et utilisent dans leur vie quotidienne. Le traitement du langage naturel consiste à permettre aux ordinateurs de comprendre et d'utiliser correctement le langage naturel pour accomplir des tâches spécifiées par les humains. Les tâches courantes en PNL incluent l'extraction de mots-clés à partir du texte, la classification de texte, la traduction automatique, etc.
Il existe une autre tâche très difficile en PNL : le système de dialogue, qui peut aussi être généralement appelé chatbot, et c'est exactement ce qu'accomplit ChatGPT.
ChatGPT et Turing Test
Depuis l'avènement des ordinateurs dans les années 1950, les gens ont commencé à étudier comment les ordinateurs peuvent aider les humains à comprendre et à traiter le langage naturel. C'est aussi l'objectif de développement du domaine de la PNL le plus célèbre. est le test de Turing.
En 1950, Alan Turing, le père des ordinateurs, a introduit un test pour vérifier si une machine peut penser comme un humain. Ce test s'appelle le test de Turing. Sa méthode de test spécifique est exactement la même que la méthode ChatGPT actuelle, c'est-à-dire la construction d'un système de dialogue informatique, dans lequel une personne et le modèle testé se parlent si la personne ne peut pas distinguer si l'autre partie est un modèle de machine ou. une autre personne, cela signifie que le modèle a réussi. Après avoir réussi le test de Turing, l'ordinateur est intelligent.Pendant longtemps, le test de Turing a été considéré par les milieux académiques comme un sommet insaisissable. Pour cette raison, la PNL est également connue comme le joyau de l’intelligence artificielle. Le travail que ChatGPT peut effectuer va bien au-delà de la portée des robots de discussion. Il peut rédiger des articles selon les instructions de l'utilisateur, répondre à des questions techniques, résoudre des problèmes mathématiques, effectuer des traductions en langues étrangères, jouer à des jeux de mots, etc. Ainsi, d’une certaine manière, ChatGPT s’est emparé du joyau de la couronne.
Formulaire de modélisation de ChatGPT
Le formulaire de travail de ChatGPT est très simple. Si l'utilisateur pose une question à ChatGPT, le modèle y répondra.
 Parmi eux, l'entrée de l'utilisateur et la sortie du modèle se présentent toutes deux sous la forme de
Parmi eux, l'entrée de l'utilisateur et la sortie du modèle se présentent toutes deux sous la forme de
. Une entrée utilisateur et une sortie correspondante du modèle sont appelées une conversation. Nous pouvons résumer le modèle ChatGPT dans le processus suivant :
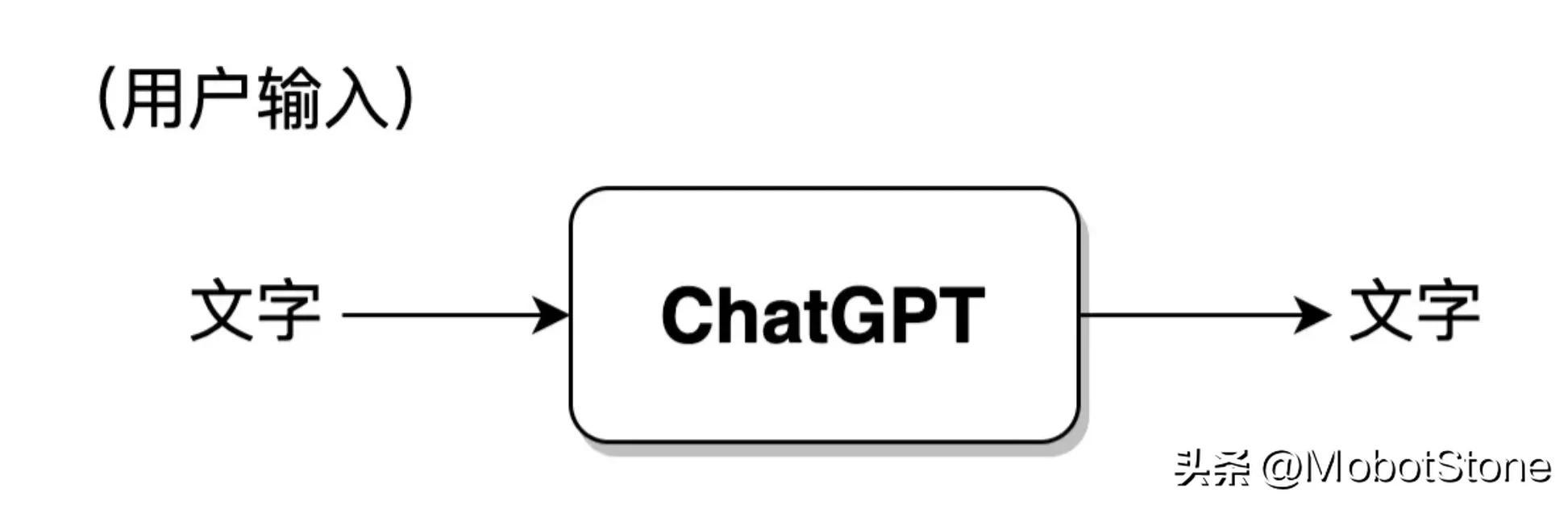 De plus, ChatGPT peut également répondre aux questions continues des utilisateurs, c'est-à-dire plusieurs cycles de dialogue, et il existe une corrélation d'informations entre plusieurs cycles de dialogue. Sa forme spécifique est également très simple. Lorsque l'utilisateur entre pour la deuxième fois, le système fusionnera par défaut les informations d'entrée et de sortie de la première fois pour que ChatGPT fasse référence aux informations de la dernière conversation.
De plus, ChatGPT peut également répondre aux questions continues des utilisateurs, c'est-à-dire plusieurs cycles de dialogue, et il existe une corrélation d'informations entre plusieurs cycles de dialogue. Sa forme spécifique est également très simple. Lorsque l'utilisateur entre pour la deuxième fois, le système fusionnera par défaut les informations d'entrée et de sortie de la première fois pour que ChatGPT fasse référence aux informations de la dernière conversation.
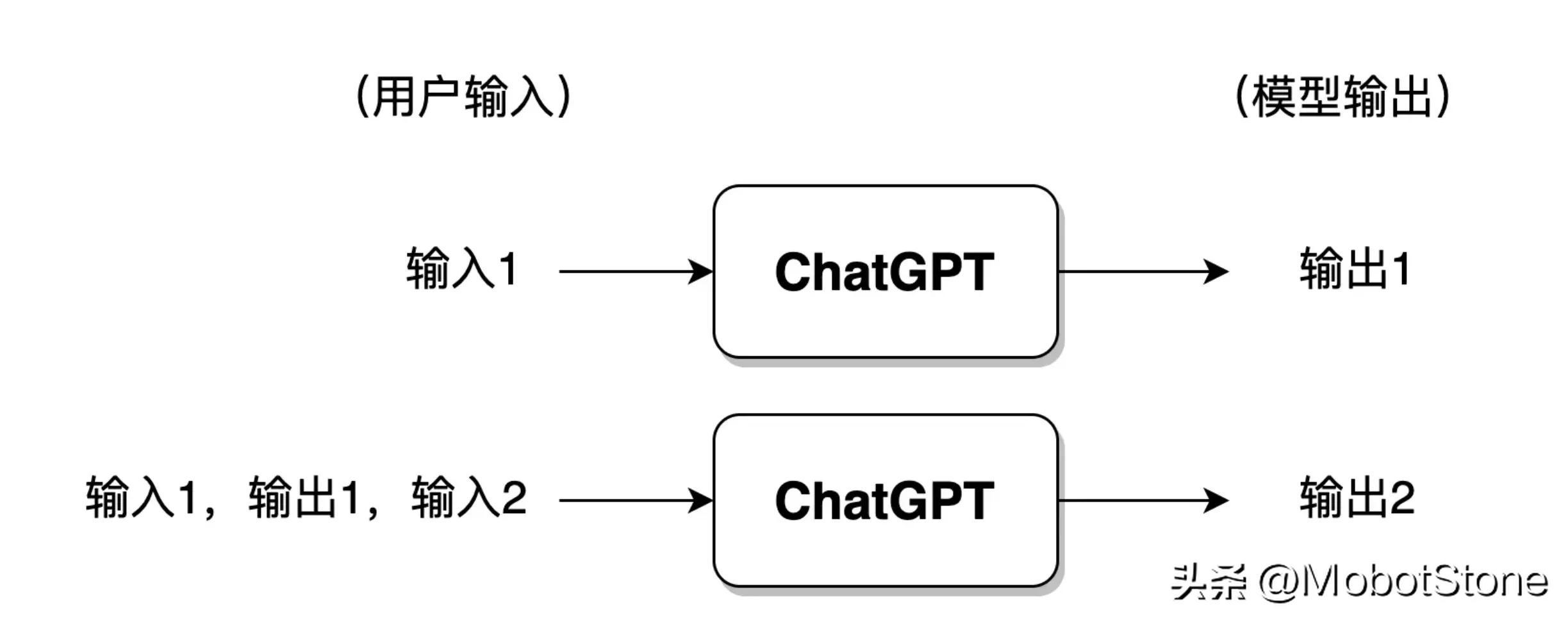 Si l'utilisateur a eu trop de conversations avec ChatGPT, de manière générale, le modèle ne conservera que les informations des séries de conversations les plus récentes et les informations des conversations précédentes seront oubliées.
Si l'utilisateur a eu trop de conversations avec ChatGPT, de manière générale, le modèle ne conservera que les informations des séries de conversations les plus récentes et les informations des conversations précédentes seront oubliées.
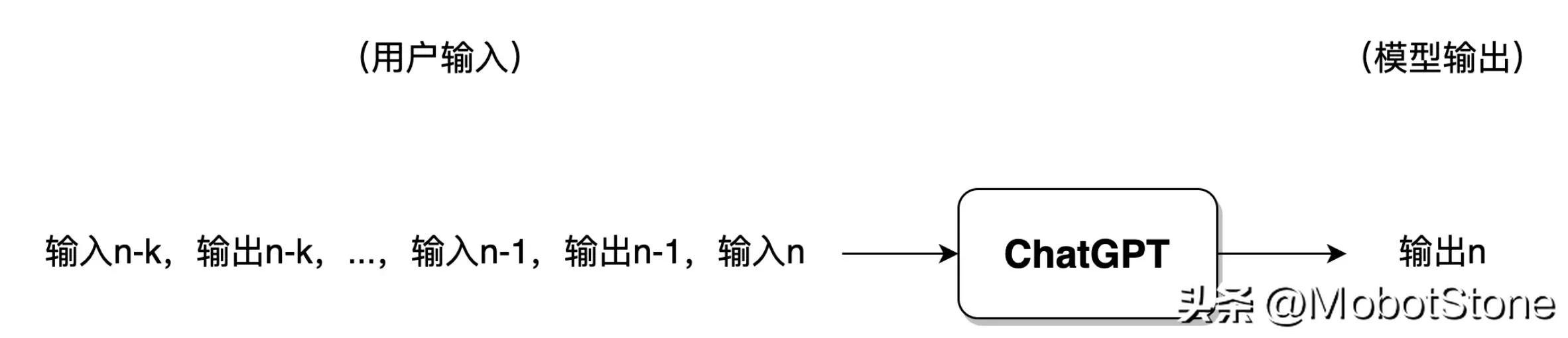 Une fois que ChatGPT a reçu la question de l'utilisateur, le texte de sortie n'est pas directement généré en un seul souffle, mais généré mot par mot. Cette génération mot par mot est
Une fois que ChatGPT a reçu la question de l'utilisateur, le texte de sortie n'est pas directement généré en un seul souffle, mais généré mot par mot. Cette génération mot par mot est
. Comme indiqué ci-dessous.
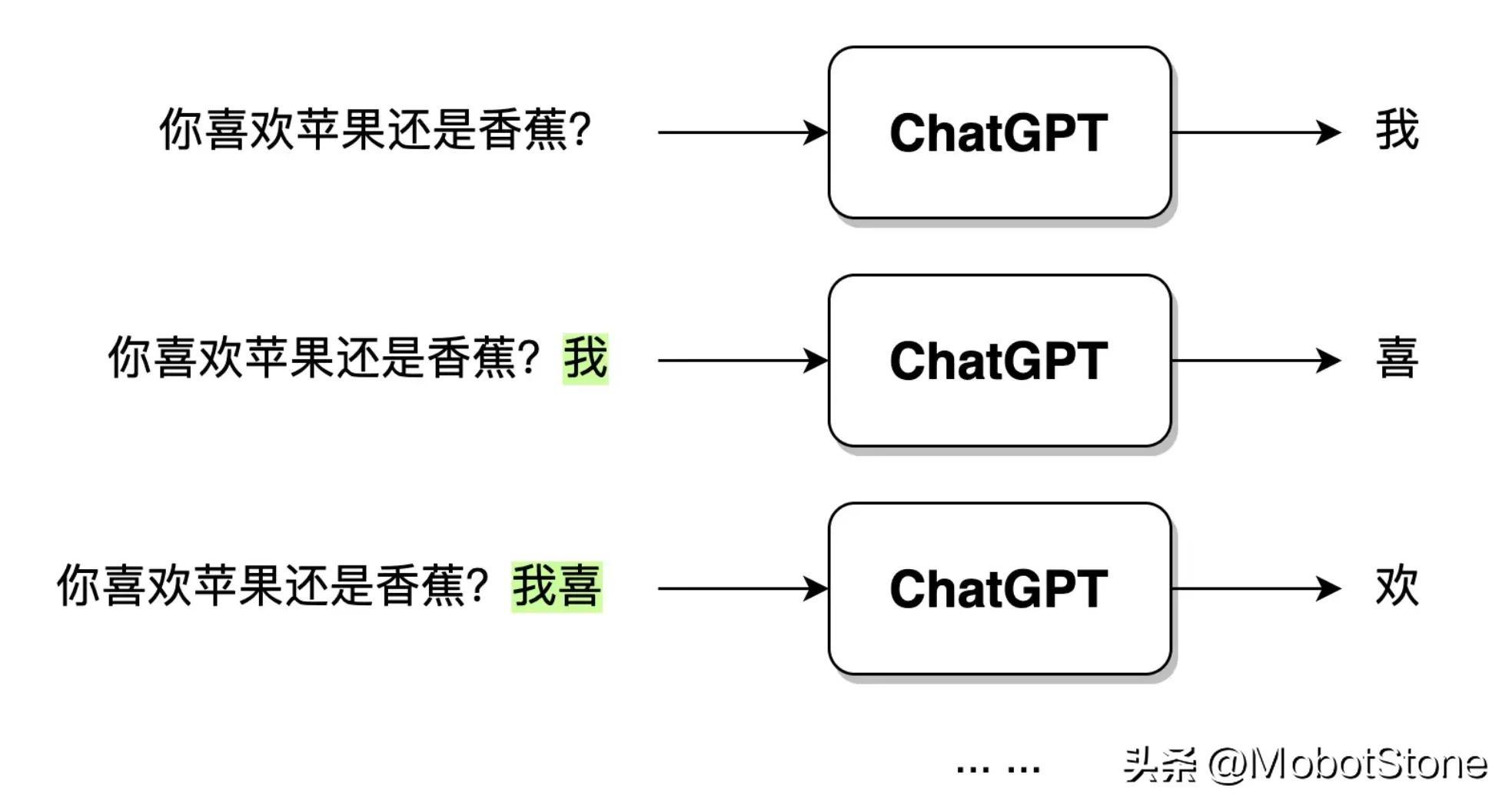 Lorsque l'utilisateur saisit une question : "Aimez-vous les pommes ou les bananes ?", après que ChatGPT ait reçu les données, il générera d'abord le mot "Je", puis le modèle combinera la question de l'utilisateur et le généré Mot "je", continuez à générer le mot suivant "salut". Et ainsi de suite jusqu'à ce qu'une phrase complète « J'aime les pommes » soit générée.
Lorsque l'utilisateur saisit une question : "Aimez-vous les pommes ou les bananes ?", après que ChatGPT ait reçu les données, il générera d'abord le mot "Je", puis le modèle combinera la question de l'utilisateur et le généré Mot "je", continuez à générer le mot suivant "salut". Et ainsi de suite jusqu'à ce qu'une phrase complète « J'aime les pommes » soit générée.
L'historique du développement de ChatGPT et du NLP
La forme de modélisation de ChatGPT a été introduite plus tôt. Imaginez, si on vous demandait d'implémenter un modèle ChatGPT, quelles idées et méthodes auriez-vous ? En fait, il existe environ deux stratégies, la PNL basée sur des règles et la PNL basée sur des statistiques. Depuis les débuts de ChatGPT, le domaine de la PNL est entré dans l'ère du Reinforcement Learning, c'est-à-dire de la PNL basée sur l'apprentissage par renforcement.
PNL basée sur des règles
La PNL basée sur des règles fait référence à l'utilisation de règles écrites manuellement pour traiter le langage naturel. Ces règles sont généralement basées sur des connaissances en grammaire, sémantique et pragmatique et peuvent être utilisées pour analyser et générer du langage naturel. Par exemple, nous pouvons concevoir un système de dialogue basé sur les règles suivantes :
Règle 1 : Lorsque le modèle reçoit la question de l'utilisateur, supprimez le mot "?" dans la question et remplacez "."
Règle 2 : Remplacez « vous » par « je » et remplacez le mot « je » par « vous »
À partir de là, nous pouvons créer un modèle de dialogue basé sur ces règles et démarrer le mode dialogue.
Utilisateur : Bonjour. Modèle : Bonjour. Utilisateur : Êtes-vous ChatGPT ? Modèle : Oui, je m'appelle ChatGPT. Utilisateur : Aimez-vous la communauté Nuggets ? Modèle : J'adore la communauté Nuggets. Utilisateur : Avez-vous déjà utilisé la boîte à outils jionlp ? Modèle : j'ai utilisé la boîte à outils jionlp.
Ce qui précède est un exemple très grossier d'un système de dialogue basé sur des règles. Je pense que les lecteurs peuvent facilement découvrir les problèmes qui existent. Et si le problème de l'utilisateur est trop complexe ? Que faire s'il n'y a pas de point d'interrogation dans la question ? Nous devons constamment rédiger diverses règles pour couvrir les situations particulières ci-dessus. Cela montre qu'il existe plusieurs lacunes évidentes basées sur les règles :
- En langage naturel, aucune règle ne peut couvrir complètement les exigences, elle n'est donc pas efficace lorsqu'il s'agit de tâches complexes en langage naturel
- Les règles sont infinies et reposent sur l'humain ; le pouvoir de terminer Cela représentera une quantité de travail énorme ;
- Essentiellement, la tâche de traitement du langage naturel n'est pas confiée aux ordinateurs, elle est toujours dominée par les humains.
C'est ainsi que la PNL a été développée à ses débuts : construire un système modèle basé sur des règles. Au début, on l’appelait aussi généralement symbolisme.
PNL basée sur les statistiques
La PNL basée sur les statistiques utilise des algorithmes d'apprentissage automatique pour apprendre les caractéristiques régulières du langage naturel à partir d'un grand nombre de corpus. Au début, on l'appelait également connexionnisme. Cette méthode ne nécessite pas d'écriture manuelle de règles. Les règles sont principalement implicites dans le modèle par l'apprentissage des caractéristiques statistiques du langage. En d’autres termes, dans la méthode basée sur des règles, les règles sont explicites et écrites manuellement ; dans la méthode statistique, les règles sont invisibles, implicites dans les paramètres du modèle et sont entraînées par le modèle basé sur les données.
Ces modèles se sont développés rapidement ces dernières années, et ChatGPT en fait partie. De plus, il existe une grande variété de modèles avec des formes et des structures différentes, mais leurs principes de base sont les mêmes. Leurs méthodes de traitement sont principalement les suivantes :
Modèle de formation => Utiliser le modèle formé pour travailler
Dans ChatGPT, la technologie de pré-formation (Pré-formation) est principalement utilisée pour compléter l'apprentissage du modèle PNL basé sur les statistiques. Au plus tôt, la pré-formation dans le domaine du PNL a été introduite pour la première fois par le modèle ELMO (Embedding from Language Models), et cette méthode a été largement adoptée par divers modèles de réseaux neuronaux profonds tels que ChatGPT.
L'objectif est d'apprendre un modèle de langage basé sur un corpus original à grande échelle, et ce modèle n'apprend pas directement comment résoudre une tâche spécifique, mais apprend des informations allant de la grammaire, de la morphologie, de la pragmatique au bon sens, aux connaissances, etc. Intégrez-les dans le modèle de langage. Intuitivement, il s’agit davantage d’une mémoire de connaissances que d’une application des connaissances pour résoudre des problèmes pratiques.
La pré-formation présente de nombreux avantages, et elle est devenue une étape nécessaire pour presque toutes les formations de modèles PNL. Nous développerons cela dans les chapitres suivants.
Les méthodes basées sur les statistiques sont beaucoup plus populaires que les méthodes basées sur des règles. Cependant, leur plus grand inconvénient est l'incertitude de la boîte noire, c'est-à-dire que les règles sont invisibles et implicites dans les paramètres. Par exemple, ChatGPT donnera également des résultats ambigus et incompréhensibles. Nous n'avons aucun moyen de juger à partir des résultats pourquoi le modèle a donné une telle réponse.

PNL basée sur l'apprentissage par renforcement
Le modèle ChatGPT est basé sur des statistiques, mais il utilise également une nouvelle méthode, l'apprentissage par renforcement avec feedback humain (RLHF), pour obtenir d'excellents résultats, amenant le développement de la PNL dans une nouvelle étape.
Il y a quelques années, Alpha GO battait Ke Jie. Cela peut presque prouver que si l'apprentissage par renforcement se déroule dans des conditions appropriées, il peut complètement vaincre les humains et approcher la limite de la perfection. Actuellement, nous sommes encore à l’ère d’une intelligence artificielle faible, mais limité au domaine du Go, Alpha GO est une intelligence artificielle forte, et son cœur réside dans l’apprentissage par renforcement.
L'apprentissage par renforcement est une méthode d'apprentissage automatique qui vise à permettre à l'agent (agent, en PNL fait principalement référence au modèle de réseau neuronal profond, qui est le modèle ChatGPT) d'apprendre à prendre des décisions optimales grâce à l'interaction avec l'environnement. .
Cette méthode revient à entraîner un chien (agent) à écouter un sifflet (environnement) et à manger (objectif d'apprentissage).
Un chiot sera récompensé par de la nourriture lorsqu'il entendra son propriétaire siffler, mais lorsque le propriétaire ne sifflera pas, le chiot ne pourra que mourir de faim. En mangeant et en mourant de faim à plusieurs reprises, le chiot peut établir les réflexes conditionnés correspondants, ce qui complète en réalité un apprentissage par renforcement.
Dans le domaine de la PNL, l'environnement est ici beaucoup plus complexe. L’environnement du modèle NLP n’est pas un véritable environnement linguistique humain, mais un modèle d’environnement linguistique construit artificiellement. Par conséquent, l’accent est mis ici sur l’apprentissage par renforcement avec rétroaction artificielle.

Basé sur des statistiques, le modèle peut s'adapter à l'ensemble de données d'entraînement avec le plus grand degré de liberté ; tandis que l'apprentissage par renforcement donne au modèle un plus grand degré de liberté, lui permettant d'apprendre de manière indépendante et de dépasser les limites de l'établi. ensemble de données. Le modèle ChatGPT intègre des méthodes d'apprentissage statistique et des méthodes d'apprentissage par renforcement. Son processus de formation modèle est présenté dans la figure ci-dessous :
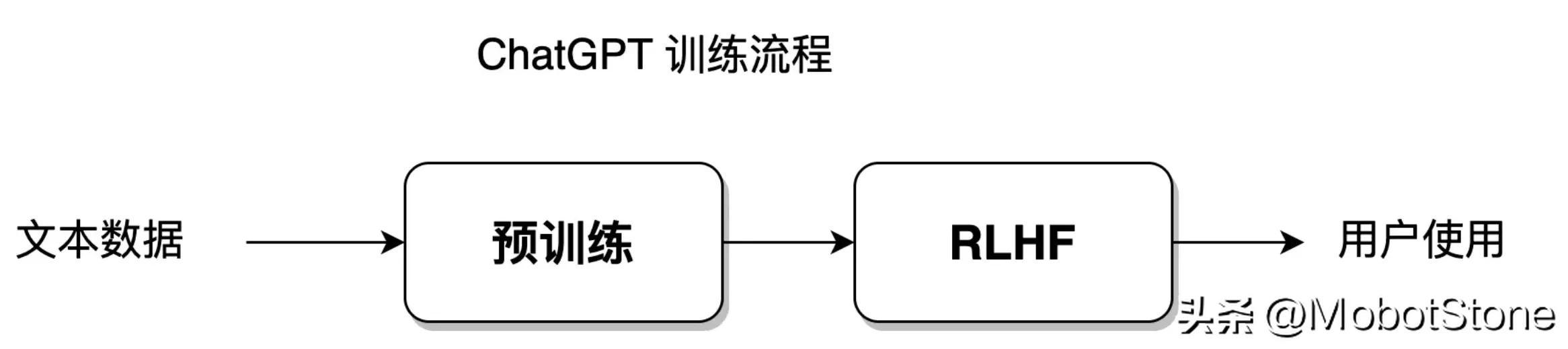
Cette partie du processus de formation sera abordée dans les sections 8 à 11.
La tendance au développement de la technologie PNL
En fait, les trois méthodes basées sur des règles, basées sur des statistiques et basées sur l'apprentissage par renforcement ne sont pas seulement un moyen de traiter le langage naturel, mais une idée. Un modèle d’algorithme qui résout un certain problème est souvent le produit d’une fusion de ces trois solutions.
Si un ordinateur est comparé à un enfant, le traitement du langage naturel est comme un être humain apprenant à l'enfant à grandir.
L'approche basée sur des règles est comme un parent contrôlant un enfant à 100%, lui demandant d'agir conformément à ses propres instructions et règles, comme fixer des heures d'étude par jour et enseigner à l'enfant toutes les questions. Tout au long du processus, l'accent est mis sur l'enseignement pratique, l'initiative et l'accent étant mis sur les parents. Pour la PNL, l’initiative et l’orientation de l’ensemble du processus appartiennent aux programmeurs et aux chercheurs qui écrivent les règles du langage.
La méthode basée sur les statistiques, c'est comme si les parents disaient seulement à leurs enfants comment apprendre, mais n'enseignaient pas chaque question spécifique. L'accent est mis sur la semi-orientation. Pour la PNL, l’apprentissage se concentre sur les modèles de réseaux neuronaux, mais l’initiative est toujours contrôlée par les ingénieurs algorithmiques.
Basé sur la méthode d'apprentissage par renforcement, c'est comme si les parents fixaient uniquement des objectifs éducatifs à leurs enfants. Par exemple, ils exigent que leurs enfants atteignent 90 points à l'examen, mais ils ne se soucient pas de la façon dont les enfants apprennent. sur l'auto-apprentissage. Les enfants ont une liberté et une initiative extrêmement grandes. Les parents ne récompensent ou ne punissent que les résultats finaux et ne participent pas à l'ensemble du processus éducatif. Pour la PNL, l’accent et l’initiative de l’ensemble du processus résident dans le modèle lui-même.
Le développement de la PNL s'est progressivement rapproché des méthodes basées sur les statistiques, et finalement la méthode basée sur l'apprentissage par renforcement a obtenu une victoire complète. Le symbole de la victoire est l'avènement de ChatGPT ; La méthode a progressivement décliné, réduite à une méthode de traitement auxiliaire. Depuis le début, le développement du modèle ChatGPT a progressé sans relâche dans le sens de laisser le modèle apprendre par lui-même.
Transformateur de structure de réseau neuronal de ChatGPT
Dans l'introduction précédente, afin de faciliter la compréhension des lecteurs, la structure interne spécifique du modèle ChatGPT n'a pas été mentionnée.
ChatGPT est un grand réseau neuronal. Sa structure interne est composée de plusieurs couches de Transformer. Depuis 2018, il est devenu une structure de modèle standard courante dans le domaine de la PNL, et Transformer peut être trouvé dans presque tous les modèles de PNL.
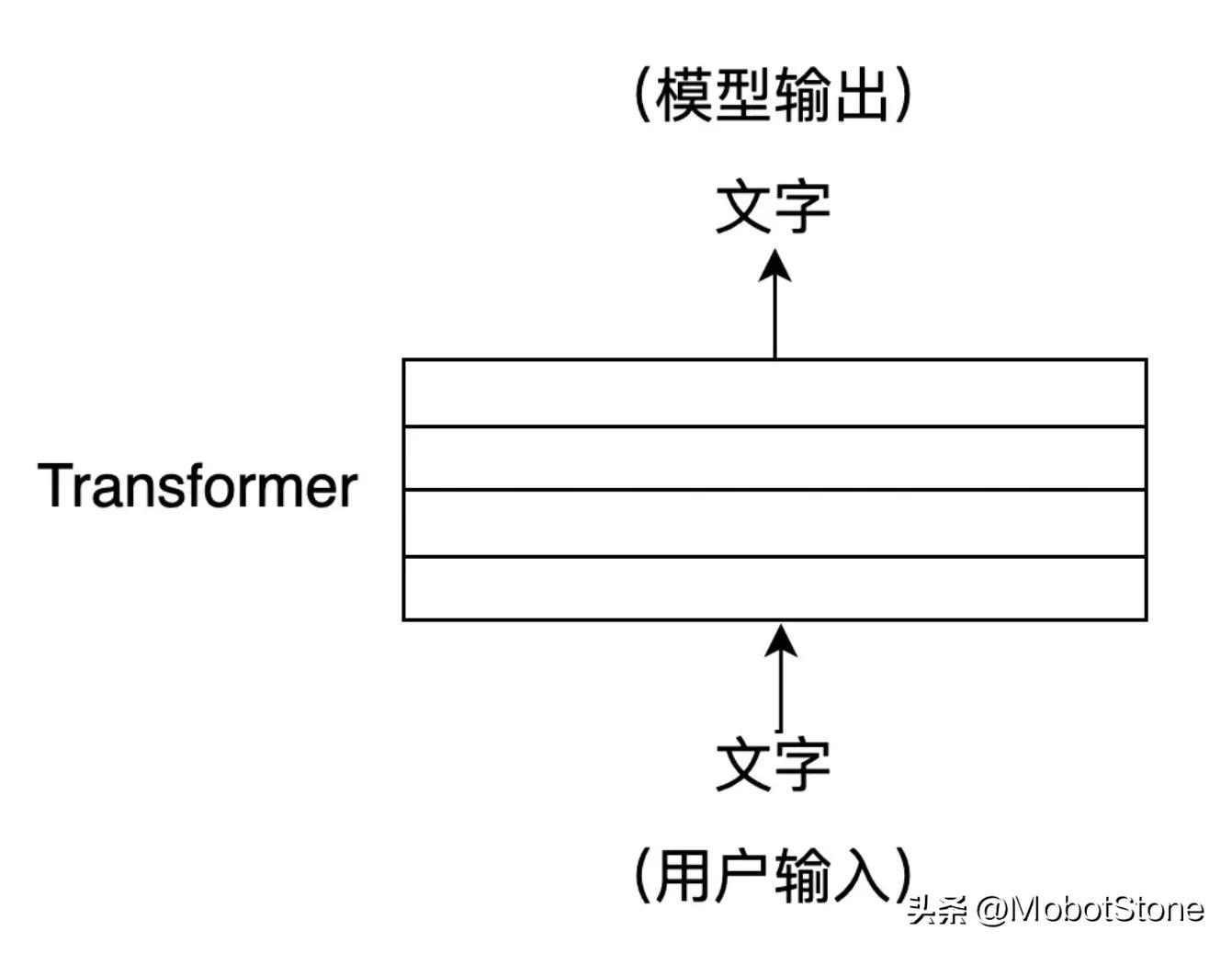
Si ChatGPT est une maison, alors Transformer est la brique qui construit ChatGPT. Le cœur de
Transformer est le mécanisme d'auto-attention, qui peut aider le modèle à prêter automatiquement attention aux autres caractères de position liés au caractère de position actuel lors du traitement de la séquence de texte d'entrée. Le mécanisme d'auto-attention peut représenter chaque position dans la séquence d'entrée sous forme de vecteur, et ces vecteurs peuvent participer aux calculs en même temps, réalisant ainsi un calcul parallèle efficace. Donnez un exemple :
Dans la traduction automatique, lors de la traduction de la phrase anglaise "Je suis un bon élève" en chinois, le modèle de traduction automatique traditionnel peut la traduire par "Je suis un bon élève", mais cette traduction Les résultats peuvent ne pas être assez précis. L'article « a » en anglais doit être déterminé en fonction du contexte lorsqu'il est traduit en chinois.
Lorsque vous utilisez le modèle Transformer pour la traduction, vous pouvez obtenir des résultats de traduction plus précis, tels que « Je suis un bon élève ».
En effet, Transformer peut mieux capturer la relation entre les mots sur de longues distances dans les phrases anglaises et résoudre les longues dépendances au contexte du texte. Le mécanisme d'auto-attention sera présenté dans la section 5-6, et la structure détaillée de Transformer sera présentée dans la section 6-7.
Résumé
- Le développement du domaine de la PNL est progressivement passé de l'écriture manuelle de règles et du contrôle logique des programmes informatiques à l'abandon complet du modèle de réseau pour s'adapter à l'environnement linguistique.
- ChatGPT est actuellement le modèle PNL le plus proche de réussir le test de Turing, et GPT4 et GPT5 le seront encore plus à l'avenir. Le flux de travail de
- ChatGPT est un système de dialogue génératif. Le processus de formation de
- ChatGPT comprend une pré-formation sur le modèle linguistique et un apprentissage par renforcement RLHF avec retour manuel. La structure du modèle de
- ChatGPT adopte Transformer avec un mécanisme d'auto-attention comme noyau.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI