
Maison >base de données >Redis >Comment utiliser la structure de données SDS de Redis
Comment utiliser la structure de données SDS de Redis

- PHPzavant
- 2023-05-28 18:07:331414parcourir
序言
Redis的几种基本数据结构有字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set),这些是最常见的,也能在官网上查看到。
字符串
前面也提到过字符串是设计了简单动态字符串SDS(Simple Dynamic String)结构来表示字符串。这种数据结构可以提升字符串的操作效率,并可以保存二进制数据。
先思考一个问题:
Redis是用C语言实现的,那么为什么没有复用C语言的字符串实现方法,而选用了SDS呢?
char*字符串数组
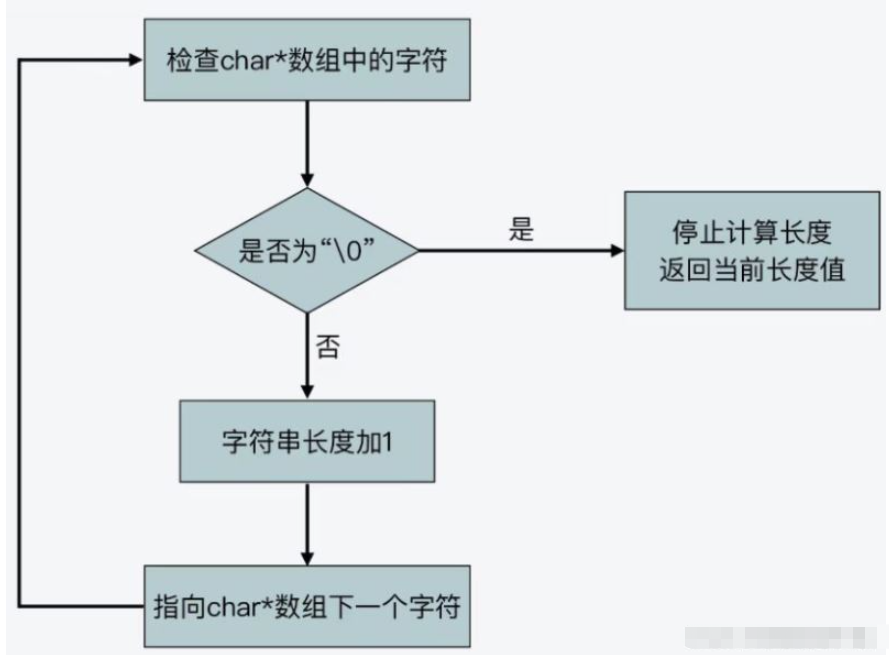
C语言实现字符串使用的是char*字符串数组,它是一块连续的内存空间,一次存放了字符串的每一个字符,并且最后一个字符是“\0”,用来标识字符串的结尾位置,如下图,

如果没有分隔符将连续的内存空间中的字符串区分开来,计算机将无法识别它们之间的位置。C语言标准库中,字符串操作函数根据在字符串数组中是否存在“\0”来判断字符串是否结束。例如字符串操作函数strlen函数,它就是在遍历字符串数组中的每一个字符,并进行计数,直到检查到“\0”,它的时间复杂度是O(n)。流程如下,
简单动态字符串SDS
SDS的数据结构里包含:字符串实际长度,字符串分配空间长度,SDS类型,字符数组,其中字符数组buf[]用来保存实际数据,如下图

再来看看类似的字符操作函数sdslen函数的源码(在sds.h文件中),直接根据SDS类型返回对应的字符串现有长度,避免了对字符串的遍历,时间复杂度变成了O(1),当然也会付出一点代价增加了空间复杂度。这都是设计人员让数据操作更加高效。源码如下,
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}再来看一下字符串的拷贝源码,操作都使用了字符串的现有长度,拷贝后进行更新。
sds sdscpylen(sds s, const char *t, size_t len) {
// 判断字符串数组分配的空间长度是不是小于字符串数组当前长度
if (sdsalloc(s) < len) {
// 根据要追加的长度len-sdslen(s)和现有长度,判断是否增加新的空间
s = sdsMakeRoomFor(s,len-sdslen(s));
if (s == NULL) return NULL;
}
// 将源字符串t中len长度的数据拷贝到目标字符串结尾
memcpy(s, t, len);
// 拷贝完后,在目标字符串结尾加上\0
s[len] = '\0';
// 设置字符串数组最新当前长度
sdssetlen(s, len);
return s;
}SDS把目标字符串的空间检查和扩容封装在了sdsMakeRoomFor函数中,追加、打印、复制等操作都会调用该函数。可以看到该函数根据sds的信息进行动态扩容,源码如下,
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
// 获取sds可用空间
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
// 如果可用空间大于等于要增加的空间,则直接返回
if (avail >= addlen) return s;
// sds长度
len = sdslen(s);
// sds指针
sh = (char*)s-sdsHdrSize(oldtype);
// 新字符串长度
newlen = (len+addlen);
// 如果新长度小于最大预分配长度,则进行两倍扩容
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
// SDS类型5转换为类型8
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}可以看到sdsMakeRoomFor函数中sdshdr5类型不再使用直接转换成了sdshdr8类型,它们是SDS设计的5种类型,分别表示sdshdr5、sdshdr8、sdshdr16、sdshdr32和sdshdr64,下面就看一下这几种类型的结构源码,如下图,
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};sdshdr5已不再使用,所以在函数中做了处理,把sdshdr5类型转换为sdshdr8类型。前面也提到过SDS是紧凑型字符串数据结构,以sdshdr8为例,它是用的是uint8_t即8位无符号整型,会占用1字节的内存空间。SDS之所以设计不同的结构是为了能灵活保存不同大小的字符串,从而有效节省内存空间。
另外,__attribute__ ((__packed__))标志可以告诉编译器在编译以上数据结构时,不实用字节对齐的方式(不满8字节的整数倍,则会自动补齐),而是采用紧凑的方式分配内存。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!