
Maison >base de données >Redis >Quelle est la méthode utilisée dans la conception clé-valeur Redis ?
Quelle est la méthode utilisée dans la conception clé-valeur Redis ?

- PHPzavant
- 2023-05-28 16:44:46901parcourir
Irrégularité dans l'utilisation de Redis
Les noms de clés stockés dans Redis ne sont pas standardisés et sont relativement arbitraires
-
Redis est utilisé comme référentiel, il y a un risque de perte de données, et là ; il n'y a pas de plan de rechargement ;
Redis met en cache les clés sans définir le délai d'expiration. La mise en cache des données basse fréquence prend beaucoup de mémoire, ce qui provoque le crash du service
-
Redis met en cache un grand nombre de gros ; les clés, qui consomment beaucoup de bande passante réseau lorsque l'application les obtient, et leur suppression peut facilement provoquer une congestion.
Une mauvaise utilisation du client Redis, entraînant un délai d'attente pour les autres connexions client. est incorrect et le pool de connexions n'est pas utilisé. Un grand nombre de tentatives de connexion entraînent l'épuisement des ressources du port système
Utilisation inappropriée de la commande client Redis, entraînant un grand nombre de requêtes lentes, affectant d'autres services d'application ; , comme l'utilisation de touches* ou de commandes flushall pendant les périodes de pointe ;
Recommandations et suggestions de scénarios commerciaux d'utilisation de Redis
Scénarios à haute concurrence : mise en cache des données de points d'accès, cela peut améliorer la vitesse de réponse globale du système et réduire la Pression IO de la base de données ;
Scénario à durée limitée : utilisez la commande Redis expire pour définir l'expiration et le renouvellement de la session, le code de vérification du téléphone mobile, etc. ; L'utilisation de la liste de Redis et des structures de données définies peut implémenter un variété d'applications de classement complexes
Opérations de collecte de données : utilisez la liste Redis, l'ensemble, l'ensemble trié pour faciliter les calculs de données, tels que l'intersection, l'union, l'ensemble de différences, etc.
Enregistrement continu : vous pouvez utiliser redis La structure de données bitmap implémente les services liés à la connexion ;
Compteur : utilisez les commandes Redis incr et incrby pour implémenter les statistiques du numéro d'appel de l'API, la limitation du courant de l'API et d'autres scénarios
Verrouillage distribué : utilisez la fonction setnx de ; Redis pour écrire un verrou de distribution, des composants open source typiques tels que Redisson ;
Comment concevoir une clé élégante
On peut dire que lorsqu'il s'agit d'optimisation des performances en ligne de Redis, une conception de clé déraisonnable est souvent la cause première de Le problème,En substance, d'après ce que j'ai vu personnellement, la plupart des étudiants n'ont presque aucune idée de la conception des clés lorsqu'ils utilisent Redis, car le scénario utilisé par la plupart des étudiants est key/val et les données correspondantes sont structurées sous la forme d'une chaîne key/string val ;
Les étudiants qui ont une compréhension plus approfondie de Redis savent peut-être que la conception de la clé doit être aussi courte que possible lors du stockage, et qu'il est préférable d'avoir un sens de la hiérarchie au milieu. Il est préférable de procéder à : Segmentation. .
Alors comment concevoir une clé plus élégante ? Parlons-en en détail en nous basant sur l'expérience réelle et les pièges de l'éditeur :
1 Suivez les conventions de bonnes pratiques suivantes :
;
La longueur de la clé ne doit pas dépasser 44 octets ;
Ne pas inclure de caractères spéciaux
Concernant les suggestions ci-dessus, cela présente les avantages suivants :
Lisible Forte flexibilité, par exemple, lorsque nous concevons de tels une structure de clé, order:user:10, en un coup d'œil nous savons qu'il s'agit d'une clé liée aux commandes des utilisateurs ;
est pratique pour la maintenance et la gestion, différentes applications ou différentes entreprises utilisent différentes Le préfixe est très pratique pour la recherche et l'emplacement de clés dans les outils client visuels ou les lignes de commande
-
Évitez les conflits de clés et évitez les conflits de clés de cache causés par plusieurs personnes utilisant des valeurs telles que userId comme clés pendant l'utilisation
Utilisez le type de chaîne comme clé ; , et le codage sous-jacent inclut int, embstr et raw, ce qui peut réduire efficacement l'utilisation de la mémoire. L'utilisation d'embstr peut traiter des chaînes inférieures à 44 octets tout en occupant moins de mémoire, car elle utilise un espace mémoire continu. tapez les clés, il est recommandé que le nombre d'éléments soit inférieur à 1000 ; le nombre de membres dans la Clé. , par exemple :
La quantité de données dans la Clé elle-même est trop importante : une Clé de type String, sa valeur est de 5 Mo
Le nombre de membres dans la Clé ; est trop grande : une clé de type ZSET, son nombre de membres est de 10 000
La quantité de données des membres dans la clé est trop grande : une clé de type Hash n'a que 1 000 membres mais la valeur totale de ces membres est de 100 Mo ;
- 2. Dommages causés par BigKey
- Congestion du réseau
Lors de l'exécution d'une requête de lecture sur BigKey, une petite quantité de QPS peut entraîner une utilisation pleine de la bande passante, provoquant une instance Redis et même la machine physique où elle se trouve ralentit ;
Désalignement des données
L'utilisation de la mémoire de l'instance Redis où se trouve BigKey est beaucoup plus élevée que celle des autres instances, et les ressources mémoire des fragments de données ne peuvent pas être équilibré ;
- Redis blocking
-
Les opérations sur le hachage, la liste, le zset, etc. avec de nombreux éléments prendront beaucoup de temps et entraîneront le blocage du thread principal
Pression du processeur
Sérialisation des données et désérialisation de BigKey Ce sera le cas. faire monter en flèche l'utilisation du processeur, affectant l'instance Redis et d'autres applications sur la machine
3 Comment découvrir BigKey
Exécutez la commande redis-cli --bigkeys sur la machine installée
- .
Utilisation Le paramètre --bigkeys fourni par redis-cli peut parcourir et analyser toutes les clés, et renvoyer les informations statistiques globales de la clé et de la grande clé Top 1 de chaque donnée
Par scan
; écrire un programme et utiliser scan analyse toutes les clés dans Redis et utilise strlen, hlen et d'autres commandes pour déterminer la longueur de la clé (l'UTILISATION DE LA MÉMOIRE n'est pas recommandée ici
Utilisez des outils tiers
- ) ;
Utilisez des outils tiers, tels que Redis-Rdb-Tools, analyse les fichiers d'instantanés RDB et analyse de manière exhaustive l'utilisation de la mémoire
Utilisez la surveillance du réseau
Utilisez des outils personnalisés pour surveiller les données réseau entrantes et sortantes de Redis, et alerter de manière proactive lorsque la valeur d'avertissement est dépassée ;
Trois, utiliser les types de données appropriés
Comme mentionné ci-dessus, de nombreux étudiants qui utilisent Redis pour la première fois, pour de nombreux scénarios commerciaux, utilisent une structure simple de clé/val et ne réfléchissez pas profondément à la question de savoir si cela est raisonnable, ou si cela entraînera des problèmes de performances associés à l'avenir
Pour ce problème, fondamentalement parlant, nous devons avoir une compréhension et une maîtrise approfondies des types de données couramment utilisés ? redis.Sur cette base, nous pouvons concevoir des solutions pour différents scénarios commerciaux. Stockage efficace des données structurées
Réfléchissons, comment mettre en cache des données telles que la liste d'objets utilisateur ?
Option 1 : la clé est usrId, la valeur est la chaîne sérialisée de l'objet, la structure des données est similaire à la suivante

Avantages : accès facile, simple et approximatif, il suffit de faire json ; lors de l'accès, convertissez-le simplement en objet ;
Inconvénients : Couplage de données, pas assez flexible. Une fois que l'objet ajoute des champs ou supprime des champs, le coût de reconstruction du cache est très élevé
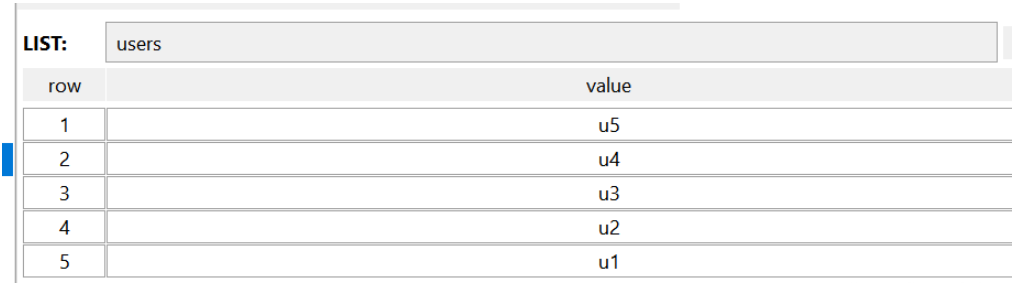
Option 2 : Utiliser une structure de liste pour ; cache Liste d'ID utilisateur, la structure des données est la suivante :
Avantages : faible utilisation de la mémoire, fonctionnement efficace
Inconvénient : après avoir obtenu val, une recherche plus approfondie dans la base de données est nécessaire pour obtenir l'objet complet ; 3 : Utilisez la structure de hachage pour mettre en cache les objets, et les données sont les suivantes :
Avantages : La couche inférieure utilise une liste zip, qui prend peu de place et peut accéder de manière flexible à tous les champs de l'objet ; Inconvénients : Le codage ; est relativement compliqué ;
Le cache Redis est actuellement utilisé Suggestions d'utilisation dans l'application
- [Recommandé] Réchauffez le cache. Avant d'accéder aux données, le cache doit être préchauffé pour éviter qu'un grand nombre de requêtes n'entrent directement dans la couche de stockage de données ; les données chaudes et froides appropriées doivent être divisées en fonction des conditions commerciales, et les données chaudes doivent être préchauffées. Tels que les informations de licence, l'apikey, etc. ;
- [Recommandé] Utilisez le cache local ensemble. Dans une architecture distribuée, bien que la mise en cache locale puisse améliorer la stabilité et la vitesse d'accès aux données, elle doit être utilisée avec prudence pour éviter d'introduire des nœuds de serveur avec état. Évitez que les caches locaux n'occupent excessivement les ressources du serveur d'applications, provoquant des pannes de nœuds d'application
- [Recommandé] Stratégie de changement de cache, mettez d'abord à jour la base de données, puis mettez à jour le cache
- [Recommandé] Un appel professionnel nécessite plusieurs visites sur le serveur Redis peut utiliser un pipeline ou d'autres méthodes d'opération par lots
- [Recommandé] Grande liste, ensemble, hachage, énorme quantité de stockage. Lors de la récupération d'un grand nombre d'éléments, un retard important se produira, bloquant l'exécution d'autres commandes. Il est recommandé de le diviser en plusieurs petites listes, ensembles ou tables de hachage
- Utiliser les spécifications métier
Qu'il s'agisse de Redis ou d'un autre middleware utilisé dans le développement, lorsqu'il s'agit de développement et d'utilisation, il est préférable de développer un ensemble de spécifications raisonnables à l'avance. Cette spécification devrait être reconnue par la plupart des développeurs et testée dans la pratique, et peut effectivement éviter certains problèmes. Une fois désignée comme spécification, elle devrait devenir une règle quotidienne pour guider les développeurs internes. Voici un guide. sont les suivants :
- Redis doit être positionné comme des données de cache et ne peut pas être utilisé pour stocker des données à grande échelle (il ne peut pas remplacer la base de données)
- Redis convient aux scénarios avec plus de lectures et moins d'écritures, tels que ; comme scénarios d'écriture à haute fréquence et de requêtes à basse fréquence, il n'est pas recommandé de l'utiliser
- Lorsque vous n'êtes pas sûr de la durée de survie de la clé, il est préférable de définir le délai d'expiration pour contrôler le cycle de vie ; de la clé;
Vous devriez envisager de séparer les données chaudes et froides. Pour les requêtes, utilisez Redis pour les requêtes professionnelles à haute fréquence et envisagez d'utiliser la base de données pour les requêtes à basse fréquence.
Lorsque le programme traite les données, vous devriez envisager le risque de perte de données dans Redis, vous devez donc implémenter les données de la base de données. Charger et mettre automatiquement en cache les données perdues dans Redis
Utilisez les commandes O(N) avec prudence, telles que list, set, hash lors de l'utilisation des données. les structures, hgetall, lrange, smembers, zrange, etc. ne sont pas inutilisables en utilisant hscan et sscan , zscan à la place.

 Avantages : La couche inférieure utilise une liste zip, qui prend peu de place et peut accéder de manière flexible à tous les champs de l'objet ;
Avantages : La couche inférieure utilise une liste zip, qui prend peu de place et peut accéder de manière flexible à tous les champs de l'objet ; Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!