
Maison >base de données >tutoriel mysql >Comment indexer les champs de chaîne dans MySQL
Comment indexer les champs de chaîne dans MySQL

- 王林avant
- 2023-05-28 14:38:522542parcourir
Supposons que vous mainteniez actuellement un système prenant en charge la connexion par courrier électronique. La table des utilisateurs est définie comme suit :
create table SUser( ID bigint unsigned primary key, email varchar(64), ... )engine=innodb;
Puisque vous devez utiliser le courrier électronique pour vous connecter, il y aura certainement des déclarations similaires à celle-ci dans le code d'entreprise :
select f1, f2 from SUser where email='xxx';
Si le champ e-mail est Sans index, cette instruction ne peut effectuer qu'une analyse complète de la table.
1) Puis-je créer un index sur le champ de l'adresse email ?
MySQL prend en charge l'index de préfixe, vous pouvez définir une partie de la chaîne comme index
2) Que se passe-t-il si l'instruction qui crée l'index ne spécifie pas la longueur du préfixe ?
L'index contiendra la chaîne entière
3) Pouvez-vous donner un exemple pour illustrer ?
alter table SUser add index index1(email); 或 alter table SUser add index index2(email(6));
index1 contient la chaîne entière de chaque enregistrement
index2 l'index ne prend que les 6 premiers octets de chaque enregistrement
4) Ces deux-là Quelles sont les différences entre les différentes définitions dans la structure des données et stockage?
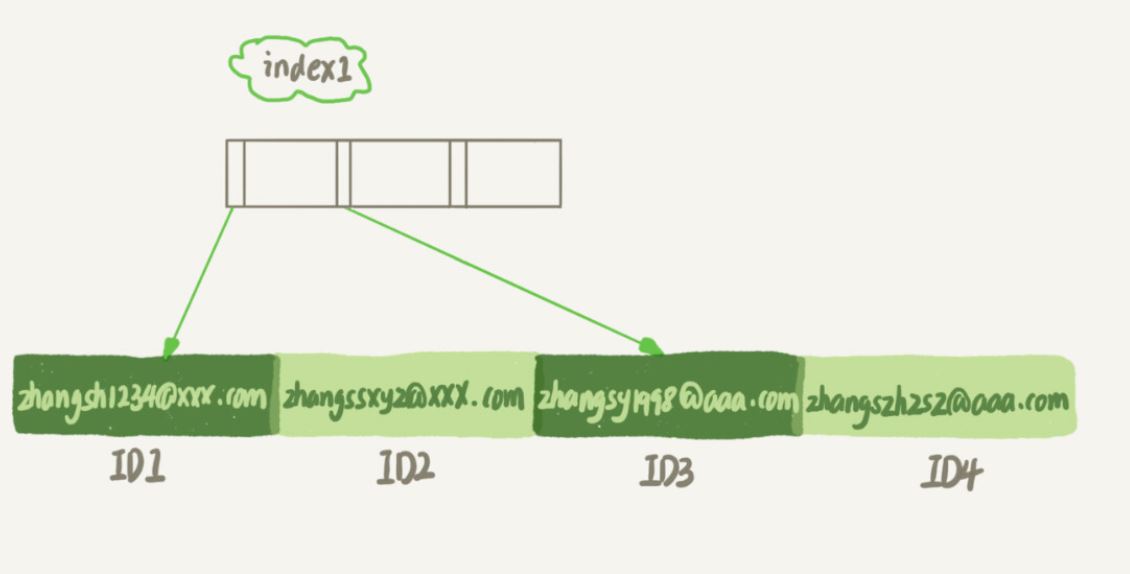
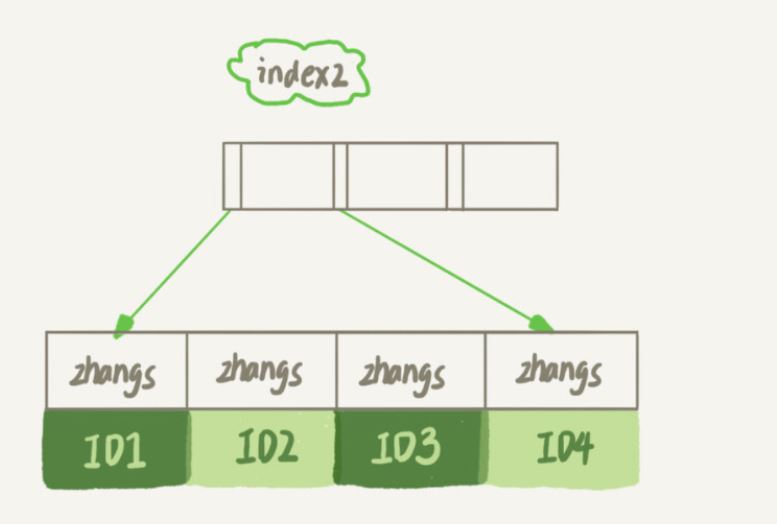
Il est évident que la structure d'index email(6) prendra moins de place
5) Y a-t-il des lacunes dans la structure d'index email(6) ?
peut augmenter le nombre d'analyses d'enregistrements supplémentaires
6) Comment l'instruction suivante est-elle exécutée sous ces deux définitions d'index ?
select id,name,email from SUser where email='zhangssxyz@xxx.com';
index1 (c'est-à-dire la structure d'index de la chaîne entière de l'e-mail), la séquence d'exécution
-
trouve l'enregistrement qui satisfait la valeur d'index de ’zhangssxyz@xxx.com’ et obtient la valeur de ID2 ;
-
Retournez au tableau et trouvez la ligne dont la valeur de clé primaire est ID2, jugez que la valeur de email est correcte et ajoutez cette ligne d'enregistrements à l'ensemble de résultats ;
Continuez jusqu'à l'enregistrement suivant dans l'arborescence d'index et constatez que l'e-mail n'est plus satisfait à la condition ='zhangssxyz@xxx.com’, la boucle se termine. - Dans ce processus, vous n'avez besoin de récupérer les données qu'une seule fois à partir de l'index de clé primaire, le système pense donc qu'une seule ligne a été analysée.
- Obtenez la suivante ; enregistrement de l'emplacement qui vient d'être trouvé sur l'index2, et constatez qu'il s'agit toujours de « zhangs », retirez ID2, puis récupérez la ligne entière sur l'index ID et jugez, cette fois la valeur est correcte, ajoutez cette ligne d'enregistrements à l'emplacement jeu de résultats ;
- Répétez l'étape précédente jusqu'à ce que la valeur obtenue sur idxe2 ne soit pas Lorsque ’zhangs», le cycle se termine.
- Dans ce processus, l'index de clé primaire doit être récupéré 4 fois, c'est-à-dire que 4 lignes sont analysées.
7) Quelles conclusions peut-on tirer de la comparaison ci-dessus ?
- 8) Les index de préfixes sont-ils vraiment inutiles ?
- 9) Alors quelles sont les précautions à prendre pour utiliser l'index de préfixe ?
- 10) Lors de la création d'un index de préfixe pour une chaîne, comment puis-je savoir quelle doit être la longueur de l'index de préfixe ?
- 11) Comment compter combien de valeurs différentes il y a sur l'index ?
select count(distinct email) as L from SUser;
12) Que devons-nous faire ensuite après avoir obtenu combien de valeurs différentes correspondant à l'indice ?
Sélectionnez tour à tour des préfixes de différentes longueurs pour voir la valeur
select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7, from SUser;Ensuite, dans L4~L7, trouvez la première valeur qui n'est pas inférieure à L * 95%, indiquant que des centaines de valeurs peuvent On retrouvera grâce à cet indice des données avec un score supérieur à 95%.
- 13) Quel est l'impact de l'indice de préfixe sur l'indice de couverture ?
- L'instruction SQL suivante :
select id,email from SUser where email='zhangssxyz@xxx.com';Par rapport à l'instruction SQL
select id,name,email from SUser where email='zhangssxyz@xxx.com';dans l'exemple précédent, la première instruction nécessite uniquement le retour des champs id et email. Si vous utilisez index1 (c'est-à-dire la structure d'index de toute la chaîne d'e-mail), vous pouvez obtenir l'ID en vérifiant l'e-mail. Il n'est alors pas nécessaire de renvoyer la table.
用 index2(即 email(6) 索引结构)的话,就不得不回到 ID 索引再去判断 email 字段的值。
14)那我把index2 的定义修改为 email(18) 的前缀索引不就行了?
这个18是你自己定义的,系统不知道18这个长度是否已经大于我的email长度,所以它还是会回表去查一下验证。
总而言之:使用前缀索引就用不上覆盖索引对查询性能的优化了
针对类似于邮箱这样的字段,使用前缀索引可能会产生不错的效果。但是,遇到身份证这种前缀的区分度不够好的情况时,我们要怎么办呢?
索引选取的要更长一些。
但是所以越长的话,占的磁盘空间更大,相同的一页能放下的索引值就变少了,反而会影响查询效率。
16)如果我们能够确定业务需求里面只有按照身份证进行等值查询的需求,还有没有别的处理方法呢?
-
既然正过来相同的多,那我就把它倒过来存。查询时候这样查
select field_list from t where id_card = reverse('input_id_card_string');
使用 的时候用count(distinct) 方法去做个验证
-
使用 hash 字段。在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
alter table t add id_card_crc int unsigned, add index(id_card_crc);
新记录插入时必须使用 crc32() 函数生成校验码,并填入新字段中。由于校验码可能存在冲突,也就是说两个不同的身份证号通过 crc32() 函数得到的结果可能是相同的,所以你的查询语句 where 部分要判断 id_card 的值是否精确相同。
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
这样,索引的长度变成了 4 个字节(int类型),比原来小了很多
17)使用倒序存储和使用 hash 字段这两种方法有什么异同点?
相同点:都不支持范围查询
倒序存储的字段上创建的索引是按照倒序字符串的方式排序的,已经没有办法利用索引方式查出身份证号码在[ID_X, ID_Y]的所有市民了。同样地,hash 字段的方式也只能支持等值查询。
区别
从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,而 hash 字段方法需要增加一个字段。当然,倒序存储方式使用 4 个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个 hash 字段也差不多抵消了。
在 CPU 消耗方面,倒序方式每次写和读的时候,都需要额外调用一次 reverse 函数,而 hash 字段的方式需要额外调用一次 crc32() 函数。以仅考虑这两个函数的计算复杂度为前提,reverse 函数对 CPU 资源的额外消耗将较少。
就查询性能而言,采用哈希字段方式的查询更具可靠性。虽然crc32算法不可避免地存在冲突的风险,但这种风险极其微小,因此我们可以认为查询时平均扫描行数接近于1。使用倒序存储方式仍然需要使用前缀索引来进行扫描,因此会增加扫描的行数。
案例:如果你在维护一个学校的学生信息数据库,学生登录名的统一格式是”学号 @gmail.com", 而学号的规则是:十五位的数字,其中前三位是所在城市编号、第四到第六位是学校编号、第七位到第十位是入学年份、最后五位是顺序编号。
学生必须输入正确的登录名和密码,方可继续使用系统。如果只考虑登录验证这个行为,你会如何为登录名设计索引?
如果一个学校每年预计2万新生,50年才100万记录,如果直接使用全字段索引,可以节省多少存储空间?。除非遇到超大规模数据,否则不需要使用后两种方法,从而避免了开发转换和限制风险
在实际操作中,只需对所有字段进行索引,一个学校的数据库数据量和查询负担不会变得很大。 如果单从优化数据表的角度: \1. 后缀@gmail可以单独一个字段来存,或者用业务代码来保证, \2. 城市编号和学校编号估计也不会变,也可以用业务代码来配置 \3. 然后直接存年份和顺序编号就行了,这个字段可以全字段索引
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!