
Maison >base de données >tutoriel mysql >Quel est le rôle de l'index MySQL
Quel est le rôle de l'index MySQL

- 王林avant
- 2023-05-27 23:52:391927parcourir
Créez d'abord une table de base de données :
create table single_table(
id int not auto_increment,
key1 varchar(100),
key2 int,
key3 varchar(100),
key_part1 varchar(100),
key_part2 varchar(100),
key_part3 varchar(100),
common_field varchar(100),
primary key(id), # 聚簇索引
key idx_key1(key1), # 二级索引
unique key uk_key2(key2), # 二级索引,而且该索引是唯一二级索引
key idx_key3(key3), # 二级索引
key idx_key_part(key_part1,key_part2,key_part3) # 二级索引,也是联合索引
)Engine=InnoDB CHARSET=utf8;1 Les index sont utilisés pour réduire le nombre d'enregistrements à analyser
Le plan d'exécution de requête le plus élémentaire consiste à analyser tous les enregistrements de la table et à les vérifier. si chaque enregistrement de recherche correspond aux critères de recherche. S'il correspond, envoyez-le au client, sinon ignorez l'enregistrement. Ce schéma d'exécution est appelé analyse complète de la table.
Pour le moteur de stockage InnoDB, une analyse complète de la table signifie commencer à partir du premier enregistrement du premier nœud feuille de l'index clusterisé et analyser en arrière le long de la liste chaînée unidirectionnelle où se trouve l'enregistrement jusqu'à Pour le dernier enregistrement du dernier nœud feuille, si vous pouvez utiliser l'arborescence B+ pour rechercher des enregistrements dont la valeur de la colonne d'index est égale à une certaine valeur, vous pouvez réduire le nombre d'enregistrements à analyser. InnoDB存储引擎来说,全表扫描意味着从聚簇索引第一个叶子节点的第一条记录开始,沿着记录所在的单向链表向后扫描,直到最后一个叶子节点的最后一条记录,如果可以利用B+树查找索引列值等于某个值的记录,这样就可以减少需要扫描的记录的数量。
由于B+树叶子节点中的记录是按照索引列值有小到大的顺序排序的,所以只需要扫描某个区间或者某些区间中的记录也可以明显减少需要扫描的记录的数量。
对于查询语句:
select * from single_table where id>=2 and id<=100;
这个语句其实就是想查找id值在[2,100]区间中的所有聚簇索引记录,我们可以通过聚簇索引对应的B+树快速的找到id=2的那条聚簇索引记录,然后沿着记录所在的单向链表向后扫描,直到某条聚簇索引记录的id值不在[2,100]区间中为止,与扫描全部的聚簇索引记录相比,这种方式大大减少了需要扫描的记录数量,所以提升了查询效率。
其实,对于B+树来说,只要索引列和常数使用=、、in、not in、is null、is not null、>、=、操作符连接起来,就可以产生扫描区间,从而提高查询效率。
2、索引用于排序
我们在编写查询语句时,经常需要使用order by子句对查询出来的记录按照某种规则进行排序。在一般情况下,我们只能把记录加载到内存中,然后再用一些排序算法在内存中对这些记录进行排序。有时查询的结果集可能太大以至于在内存中无法进行排序,此时就需要暂时借助磁盘的空间来存放中间结果,在排序操作完成后再把排序的结果返回给客户端。
在MySQL中,这种在内存中或者磁盘中进行排序的方式称为文件排序,但是如果order by子句中使用了索引列,就有可能省去在内存或磁盘中排序的步骤。
1、分析下面的查询语句:
select * form single_table order by key_part1,key_part2,key_part3 limit 10;
这个查询语句的结果集需要先按照key_part1值排序,如果记录的key_part1值相同,再按照key_part2值排序,如果key_part1值和key_part2值都相同,再按照key_part3排序。而我们建立的联合索引idx_key_part就是按照上面的规则排序的,如下为idx_key_part索引的简化示意图:
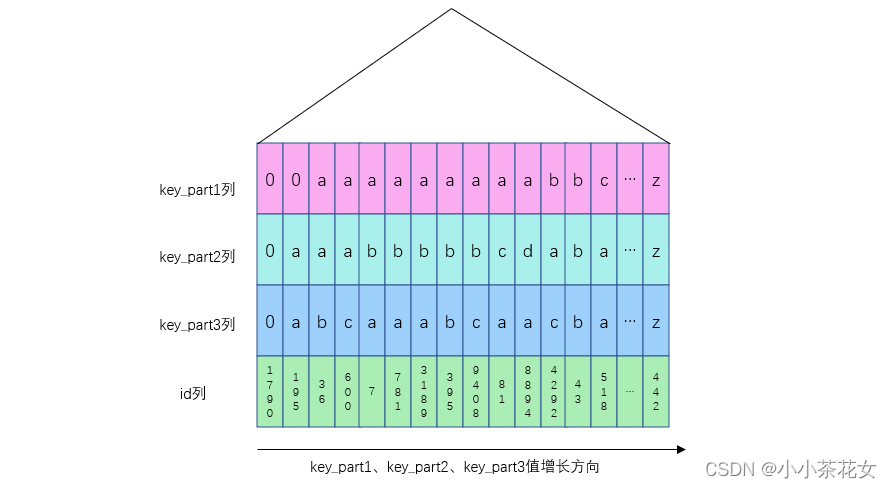
所以我们可以从第一条idx_key_part二级索引记录开始,沿着记录所在的单向链表向后扫描,取10条二级索引记录即可。由于我们的查询列表是*,也就是需要读取完整的用户记录,所以针对获取到的每一条二级索引记录都执行一次回表操作,将完整的用户记录发送给客户端。这样就省去了给10000条记录排序的时间。
这里我们在执行查询语句时加了limit语句,如果不限制需要获取的记录数量,会导致为大量二级索引记录执行回表操作,这样会影响整体的性能。
2、使用联合索引进行排序时的注意事项
在使用联合索引时,需要注意:order by子句后面的列的顺序也必须按照索引列的顺序给出;如果给出order by key_part3,key_part2,key_part1的顺序,则无法使用B+树索引。
之所以颠倒排序列顺序就不能使用索引,原因还是联合索引中页面和记录的排序规则是规定的,即先按照key_part1值排序,如果记录的key_part1值相同,再按照key_part2值排序,如果记录的key_part1值和key_part2值都相同,再按照key_part3值排序。如果order by子句的内容是order by key_part3,key_part2,key_part1,那就要求先按照key_part3值排序,如果记录的key_part3值相同,再按照key_part2值排序,如果记录的key_part3值和key_part2值都相同,再按照key_part1
select * from single_table order by key1,,key2 limit 10;🎜Cette instruction veut en fait trouver tous les enregistrements d'index cluster dont la valeur
id est dans la plage [2,100]. clustering L'arborescence B+ correspondant à l'index de cluster trouve rapidement l'enregistrement d'index cluster avec id=2, puis parcourt en arrière le long de la liste chaînée unidirectionnelle où se trouve l'enregistrement jusqu'au d'un enregistrement d'index clusterisé Jusqu'à ce que la valeur >id ne soit pas dans l'intervalle [2,100], par rapport à l'analyse de tous les enregistrements d'index clusterisés, cette méthode réduit considérablement le nombre d'enregistrements qui doivent être analysés, cela améliore donc l’efficacité des requêtes. 🎜🎜En fait, pour les arbres B+, tant que les colonnes d'index et les constantes utilisent =, , in, not in, est nul, n'est pas nul, >, = Les opérateurs , < ;=, between, != ou like sont connectés pour générer un intervalle d'analyse, améliorant ainsi l'efficacité des requêtes. 🎜🎜2. Les index sont utilisés pour le tri🎜🎜Lorsque nous écrivons des instructions de requête, nous devons souvent utiliser la clause order by pour trier les enregistrements interrogés selon certaines règles. Dans des circonstances normales, nous ne pouvons charger que des enregistrements en mémoire, puis utiliser certains algorithmes de tri pour trier ces enregistrements en mémoire. Parfois, le jeu de résultats de la requête peut être trop volumineux pour être trié en mémoire. Dans ce cas, il est nécessaire d'utiliser temporairement de l'espace disque pour stocker les résultats intermédiaires, puis de renvoyer les résultats triés au client une fois l'opération de tri terminée. 🎜🎜Dans MySQL, cette méthode de tri en mémoire ou sur disque est appelée tri de fichiers, mais si une colonne d'index est utilisée dans la clause order by, il est possible d'éviter le tri en mémoire ou disque. Étapes de tri sur le disque. 🎜1. Analysez l'instruction de requête suivante :
select key_part1,key_part2,key_part3,count(*) fron single_table group by key_part1,key_part2,key_part3;🎜L'ensemble de résultats de cette instruction de requête doit être trié en fonction de la valeur
key_part1 si le key_part1 valeur Si les valeurs sont les mêmes, triez selon la valeur <code>key_part2 si la valeur key_part1 et la valeur key_part2 sont. la même chose, puis trier par la valeur key_part3. L'index conjoint idx_key_part que nous avons établi est trié selon les règles ci-dessus. Voici un schéma simplifié de l'index idx_key_part : 🎜🎜 🎜🎜Nous pouvons donc commencer par le premier
🎜🎜Nous pouvons donc commencer par le premier idx_key_part index secondaire Lorsque l'enregistrement commence, parcourez en arrière le long de la liste chaînée unidirectionnelle où se trouve l'enregistrement et obtenez 10 enregistrements d'index secondaire. Puisque notre liste de requêtes est *, c'est-à-dire que nous devons lire l'enregistrement utilisateur complet, nous effectuons donc une opération de retour de table pour chaque enregistrement d'index secondaire obtenu et envoyons l'enregistrement utilisateur complet au client. Cela permet d'économiser le temps de trier 10 000 enregistrements. 🎜🎜Ici, nous ajoutons une instruction de limite lors de l'exécution de l'instruction de requête. Si nous ne limitons pas le nombre d'enregistrements à obtenir, un grand nombre d'enregistrements d'index secondaire seront renvoyés à la table, ce qui affectera les performances globales. . 🎜2. Choses à noter lors de l'utilisation d'un index conjoint pour le tri
🎜Lors de l'utilisation d'un index conjoint, vous devez faire attention : à l'ordre des colonnes après la clauseorder by doit également être conforme à la colonne d'index L'ordre est donné ; si l'ordre de order by key_part3, key_part2, key_part1 est donné, l'index de l'arbre B+ ne peut pas être utilisé. 🎜🎜La raison pour laquelle l'index ne peut pas être utilisé lorsque l'ordre des colonnes de tri est inversé est que les règles de tri des pages et des enregistrements dans l'index conjoint sont stipulées, c'est-à-dire qu'il faut d'abord trier en fonction de la valeur key_part1 . Si les valeurs key_part1 de l'enregistrement sont les mêmes, puis triez en fonction de la valeur <code>key_part2 si les valeurs key_part1 enregistrées et. Les valeurs key_part2 sont les mêmes, puis triez selon le tri key_part3 Value. Si le contenu de la clause order by est order by key_part3,key_part2,key_part1, alors il est nécessaire de trier d'abord en fonction de la valeur key_part3 . Si le key_part3 est la même, puis triée en fonction de la valeur de key_part2 Si la valeur enregistrée de key_part3 et. la valeur de key_part2 est la même, puis triez en fonction de la valeur de key_part2 les valeurs de key_part1 sont triées, ce qui est évidemment un conflit. . 🎜3、不可以使用索引进行排序的情况:
(1) ASC、DESC混用;
对于使用联合索引进行排序的场景,我们要求各个排序列的排序规则是一致的,也就是要么各个列都是按照升序规则排序,要么都是按照降序规则排序。
(2) 排序列包含非一个索引的列;
有时用来排序的多个列不是同一个索引中的,这种情况也不能使用索引进行排序,比如下面的查询语句:
select * from single_table order by key1,,key2 limit 10;
对于idx_key1的二级索引记录来说,只按照key1列的值进行排序,而且在key1列相同的情况下是不按照
key2列的值进行排序的,所以不能使用idx_key1索引执行上述查询。
(3) 排序列是某个联合索引的索引列,但是这些排序列在联合索引中并不连续;
(4) 排序列不是以单独列名的形式出现在order by子句中;
3、索引用于分组
有时为了方便统计表中的一些信息,会把表中的记录按照某些列进行分组。比如下面的分组查询语句:
select key_part1,key_part2,key_part3,count(*) fron single_table group by key_part1,key_part2,key_part3;
这个查询语句相当于执行了3次分组操作:
先按照
key_part1值把记录进行分组,key_part1值相同的所有记录划分为一组;将
key_part1值相同的每个分组中的记录再按照key_part2的值进行分组,将key_part2值相同的记录放到一个小分组中,看起来像是在一个大分组中又细分了好多小分组。再将上一步中产生的小分组按照
key_part3的值分成更小的分组。所以整体上看起来就像是先把记录分成一个大分组,然后再把大分组分成若干个小分组,最后把若干个小分组再细分为更多的小分组。
上面这个查询语句就是统计每个小小分组包含的记录条数。
如果没有idx_key_part索引,就得建立一个用于统计的临时表,在扫描聚簇索引的记录时将统计的中间结果填入这个临时表。当扫描完记录后,再把临时表中的结果作为结果集发送给客户端。
如果有了idx_key_part索引,恰巧这个分组顺序又与idx_key_part的索引列的顺序一致,因此可以直接使用idx_key_part的二级索引进行分组,而不用建立临时表了。
与使用B+树索引进行排序差不多,分组列的顺序页需要与索引列的顺序一致,也可以值使用索引列中左边连续的列进行分组。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!