
Maison >base de données >tutoriel mysql >Quels sont les avantages et les inconvénients de l'index clusterisé MySQL
Quels sont les avantages et les inconvénients de l'index clusterisé MySQL

- 王林avant
- 2023-05-27 21:43:111568parcourir
1. Qu'est-ce qu'un index clusterisé ?
Les index de base de données peuvent être divisés en différents types selon différentes perspectives, et l'index clusterisé en fait partie.
L'index clusterisé en anglais est un index clusterisé. Parfois, vous pouvez voir certaines personnes l'appeler index clusterisé, etc. L'opposé est un index non clusterisé ou un index secondaire.
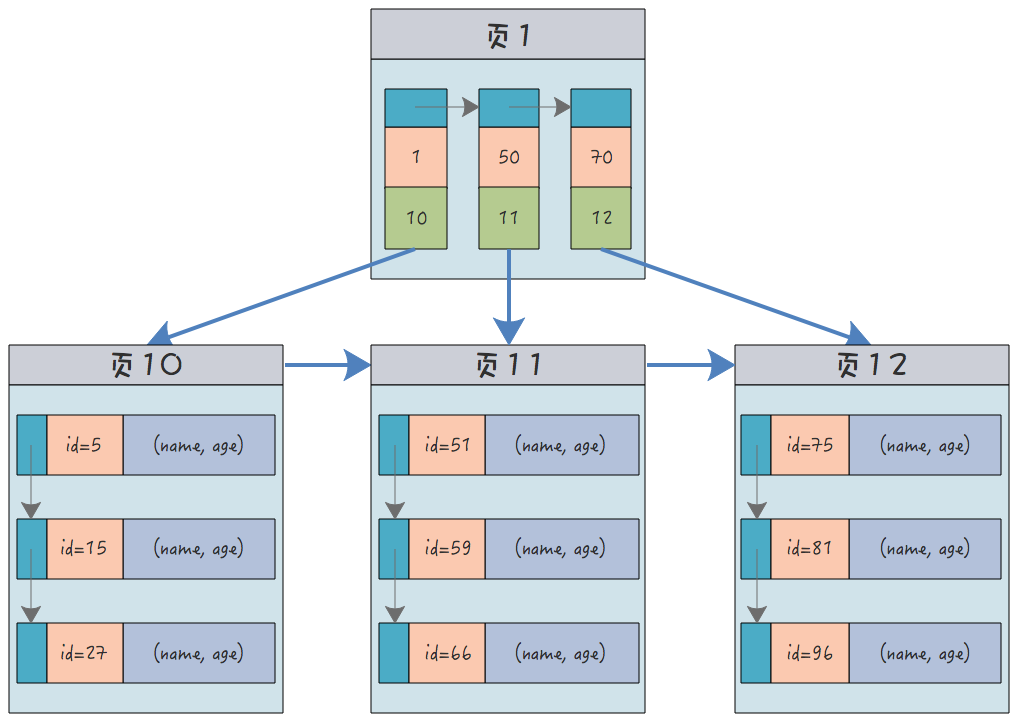
L'index clusterisé n'est pas un type d'index distinct, mais un moyen de stocker des données. Dans le moteur de stockage InnoDB de MySQL, ce que l'on appelle l'index clusterisé stocke en fait l'index et les lignes de données dans le même B+Tree : À ce stade, les données sont placées dans les nœuds feuilles, regroupés, ce qui signifie les lignes de données et les valeurs clés correspondantes. existent de manière compacte ensemble. 9 9
ShenzhenHomme| 2 | ac | 98 | Guangzhou | Homme |
|---|---|---|---|---|
| 3 | af | 88 | Beijing | Femme |
| 4 | bc | 80 | Shanghai | Femme |
| 5 | bg | 85 | Chongqing | femelle |
| 6 | bw | 95 | Tianjin | male |
| 7 | bw | 99 | Haikou | Femme |
| 8 | cc | 92 | Wuhan | Homme |
| 9 | ck | 90 | Shenzhen | Homme |
| 10 | cx | 93 | Shenzhen | Homme |
|
Ensuite, son index clusterisé ressemble probablement à ceci :
Ensuite, vous pouvez voir qu'il y a les deux valeurs de clé primaire (index) sur les feuilles) et il y a des lignes de données, et il n'y a que des valeurs de clé primaire (index) sur les nœuds. Pensez-y les amis, les données de la table MySQL ne peuvent être enregistrées qu'en une seule copie sur le disque, et il est impossible d'en enregistrer deux copies. Par conséquent, dans une table, il ne peut y en avoir qu'une seule. un index clusterisé, non Il peut y en avoir plusieurs. 2. Index clusterisé et clé primaireCertains amis sont confus quant à la relation entre les deux et assimilent même les deux. Dans certaines bases de données, les développeurs sont autorisés à choisir librement quel index utiliser comme index clusterisé, mais cette fonctionnalité n'est pas prise en charge dans MySQL. Dans MySQL, si la table elle-même a un jeu de clés primaires, alors la clé primaire est l'index clusterisé ; si la table elle-même ne définit pas de clé primaire, un index unique et non vide dans le La table sera sélectionnée comme index clusterisé ; s’il n’y a pas d’index unique non vide dans la table, la clé primaire implicite de la table sera automatiquement sélectionnée comme index clusterisé. Brother Song vous présentera la clé primaire implicite des tables MySQL dans les prochains articles.
Selon l'introduction ci-dessus, nous pouvons résumer la relation entre l'index clusterisé et l'index de clé primaire dans MySQL comme suit :
Jetons un coup d'œil aux inconvénients :
|
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!