
Maison >Périphériques technologiques >IA >Pratique d'optimisation du cache pour la formation en deep learning à grande échelle
Pratique d'optimisation du cache pour la formation en deep learning à grande échelle

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-27 20:49:041376parcourir

1. Contexte du projet et stratégie de mise en cache
Tout d'abord, partageons le contexte pertinent.
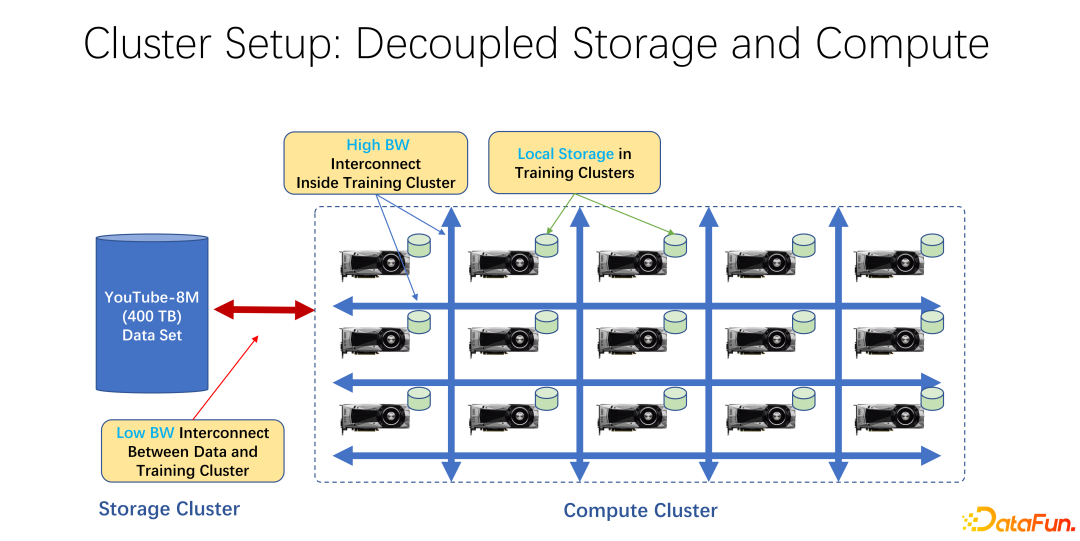
Ces dernières années, les applications de formation à l'IA sont devenues de plus en plus répandues. Du point de vue de l'infrastructure, qu'il s'agisse de clusters de big data ou de formation à l'IA, la plupart d'entre eux utilisent une architecture qui sépare le stockage et l'informatique. Par exemple, de nombreuses baies de GPU sont placées dans un grand cluster informatique, et l'autre cluster est le stockage. Il peut également utiliser du stockage cloud, tel que Azure de Microsoft ou S3 d'Amazon.
Les caractéristiques d'une telle infrastructure sont que, tout d'abord, il existe de nombreux GPU très coûteux dans le cluster informatique, et chaque GPU dispose souvent d'une certaine quantité de stockage local, comme des dizaines de To de stockage comme SSD. Dans une telle gamme de machines, un réseau haut débit est souvent utilisé pour se connecter à l'extrémité distante. Par exemple, des données de formation à très grande échelle telles que Coco, image net et YouTube 8M sont connectées via le réseau.
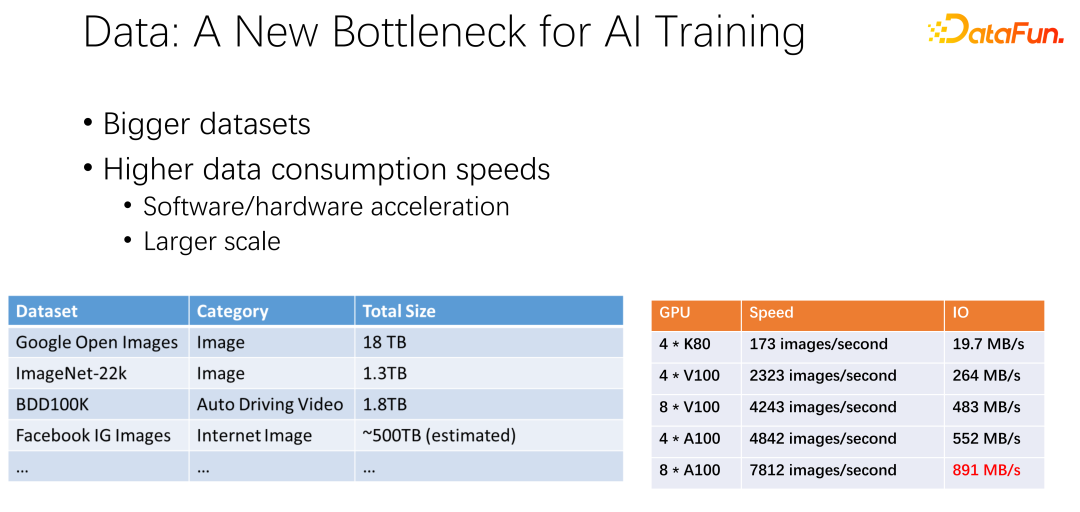
Comme le montre la figure ci-dessus, les données pourraient devenir le goulot d'étranglement de la prochaine formation en IA. Nous avons observé que les ensembles de données sont de plus en plus volumineux et qu’à mesure que l’IA est plus largement utilisée, davantage de données de formation sont accumulées. Dans le même temps, la piste GPU est très volumineuse. Par exemple, des fabricants tels qu'AMD et TPU ont consacré beaucoup d'énergie à optimiser le matériel et les logiciels pour rendre les accélérateurs, tels que les GPU et les TPU, de plus en plus rapides. Les accélérateurs étant largement utilisés au sein de l’entreprise, les déploiements de clusters sont de plus en plus importants. Les deux tableaux présentés ici présentent certaines variations selon les ensembles de données et les vitesses du GPU. Du précédent K80 aux V100, P100 et A100, la vitesse est très rapide. Cependant, à mesure qu’ils deviennent plus rapides, les GPU deviennent de plus en plus chers. Que nos données, telles que la vitesse des E/S, puissent suivre la vitesse du GPU est un grand défi.

Comme le montre l'image ci-dessus, dans de nombreuses applications de grandes entreprises, nous avons observé un tel phénomène : lors de la lecture de données distantes, le GPU est inactif. Étant donné que le GPU attend que les données distantes soient lues, cela signifie que les E/S deviennent un goulot d'étranglement, entraînant un gaspillage de GPU coûteux. De nombreux travaux d'optimisation sont en cours pour atténuer ce goulot d'étranglement, et la mise en cache est l'une des directions d'optimisation les plus importantes. Voici deux façons.

La première est que dans de nombreux scénarios d'application, en particulier dans les architectures de formation de base en IA telles que K8 et Docker, de nombreux disques locaux sont utilisés. Comme mentionné précédemment, la machine GPU dispose d'un certain stockage local. Vous pouvez d'abord utiliser le disque local pour effectuer une mise en cache et mettre les données en cache.
Après avoir démarré un GPU Docker, au lieu de démarrer immédiatement la formation GPU AI, vous téléchargez d'abord les données et téléchargez les données de l'extrémité distante vers Docker, ou vous pouvez les monter. Commencez la formation après l'avoir téléchargée sur Docker. De cette manière, la lecture ultérieure des données d'entraînement peut être transformée autant que possible en lecture de données locales. Les performances des IO locales sont actuellement suffisantes pour prendre en charge la formation GPU. Sur VLDB 2020, il existe un article, CoorDL, basé sur DALI pour la mise en cache des données.
Cette méthode pose également de nombreux problèmes. Tout d'abord, l'espace local est limité, ce qui signifie que les données mises en cache sont également limitées. Lorsque l'ensemble de données devient de plus en plus grand, il est difficile de mettre en cache toutes les données. En outre, une grande différence entre les scénarios d’IA et les scénarios de Big Data réside dans le fait que les ensembles de données des scénarios d’IA sont relativement limités. Contrairement aux scénarios Big Data dans lesquels il existe de nombreuses tables et diverses entreprises, l'écart de contenu entre les tables de données de chaque entreprise est très important. Dans les scénarios d’IA, la taille et le nombre d’ensembles de données sont bien inférieurs à ceux des scénarios de Big Data. Par conséquent, on constate souvent que de nombreuses tâches soumises dans l’entreprise lisent les mêmes données. Si tout le monde télécharge les données sur sa propre machine locale, elles ne peuvent pas être partagées et de nombreuses copies des données seront stockées à plusieurs reprises sur la machine locale. Cette approche pose évidemment de nombreux problèmes et n’est pas assez efficace.
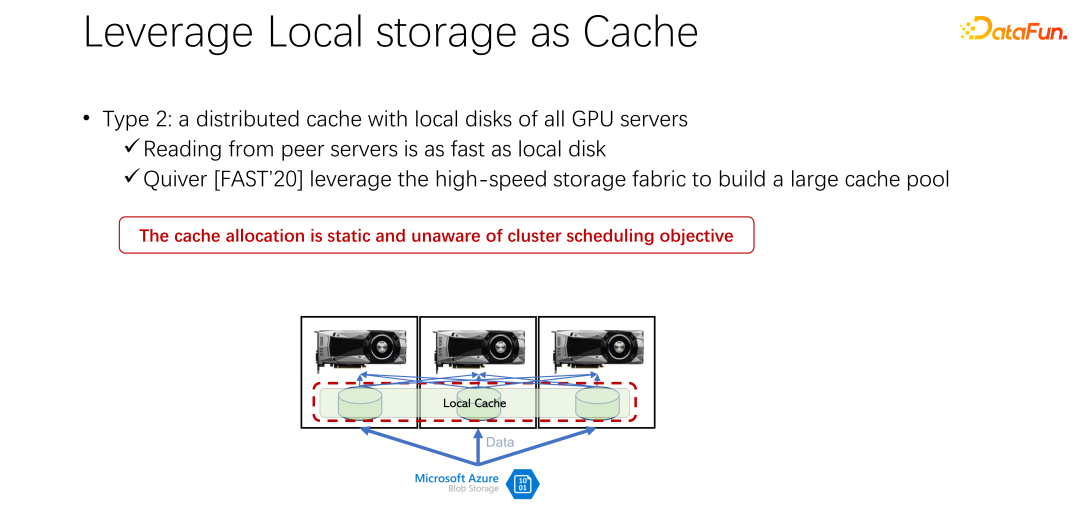
La deuxième méthode est présentée ensuite. Étant donné que le stockage local n'est pas très bon, pouvons-nous utiliser un cache distribué comme Alluxio pour atténuer le problème pour le moment ? Le cache distribué a une très grande capacité de chargement de données. De plus, Alluxio, en tant que cache distribué, est facile à partager. Les données sont téléchargées sur Alluxio et d'autres clients peuvent également lire ces données depuis le cache. Il semble que l'utilisation d'Alluxio puisse facilement résoudre les problèmes mentionnés ci-dessus et améliorer considérablement les performances de formation de l'IA. Un article intitulé Quiver publié par Microsoft India Research lors de FAST2020 mentionnait cette solution. Cependant, notre analyse a révélé qu’un tel plan d’allocation apparemment parfait reste relativement statique et peu efficace. Dans le même temps, quel type d’algorithme d’élimination du cache doit être utilisé est également une question digne de discussion.
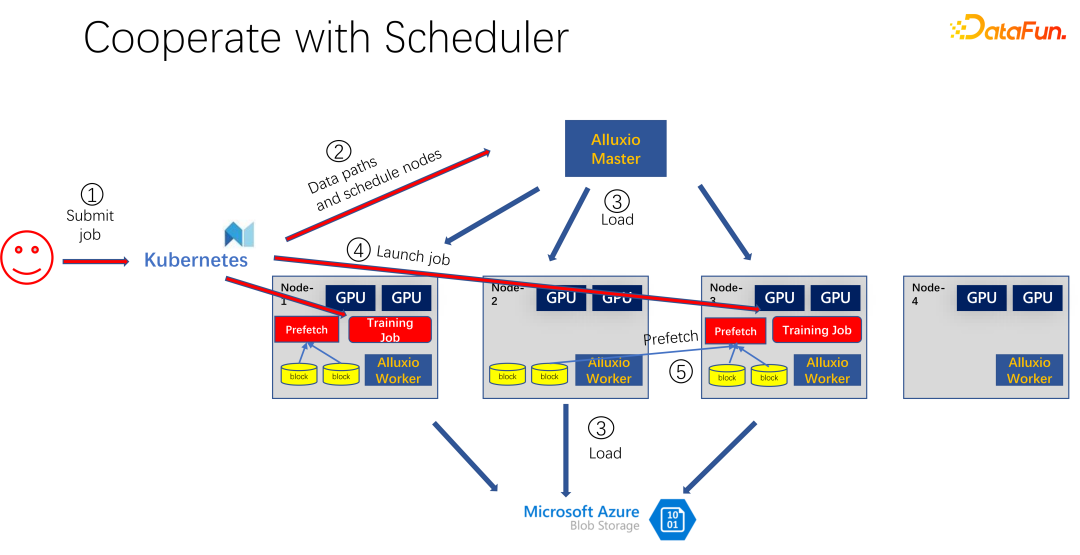
Comme le montre l'image ci-dessus , oui Une application utilisant Alluxio comme cache pour la formation en IA. Utilisez les K8 pour planifier l'intégralité de la tâche du cluster et gérer les ressources telles que le GPU, le CPU et la mémoire. Lorsqu'un utilisateur soumet une tâche à K8, K8 créera d'abord un plug-in et informera le maître Alluxio de télécharger cette partie des données. C'est-à-dire, faites d'abord un échauffement et essayez de mettre en cache certaines tâches qui peuvent être nécessaires pour le travail. Bien sûr, il n’est pas nécessaire de le mettre complètement en cache, car Alluxio utilise autant de données qu’il en possède. Le reste, s'il n'a pas encore été mis en cache, est lu depuis l'extrémité distante. De plus, une fois que le maître Alluxio a reçu une telle commande, il peut demander à son travailleur de se rendre à l'extrémité distante. Il peut s'agir d'un stockage cloud ou d'un cluster Hadoop téléchargeant les données. À ce stade, les K8 planifieront également le travail sur le cluster GPU. Par exemple, dans la figure ci-dessus, dans un tel cluster, il sélectionne le premier nœud et le troisième nœud pour démarrer la tâche de formation. Après avoir démarré la tâche de formation, les données doivent être lues. Dans les frameworks grand public actuels tels que PyTorch et Tensorflow, Prefetch est également intégré, ce qui signifie une pré-lecture des données. Il lit les données mises en cache dans Alluxio qui ont été mises en cache à l'avance pour fournir une prise en charge des données d'entraînement IO. Bien entendu, s’il s’avère que certaines données n’ont pas été lues, Alluxio peut également les lire à distance. Alluxio est une excellente interface unifiée. Dans le même temps, il peut également partager des données entre les tâches.
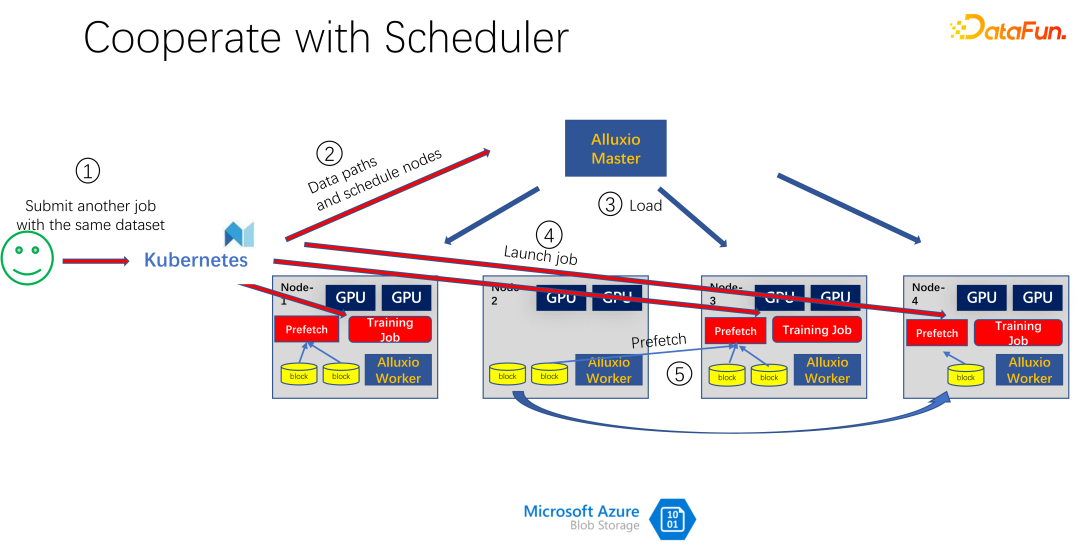
Comme le montre l'image ci-dessus, par exemple, une autre personne a soumis le mêmes données. Un autre travail consomme le même ensemble de données. À ce moment-là, lors de la soumission du travail à K8s, Alluxio sait que cette partie des données existe déjà. Si Alluxio veut faire mieux, il peut même savoir sur quelle machine les données seront planifiées. Par exemple, il est planifié pour le moment sur le nœud 1, le nœud 3 et le nœud 4. Vous pouvez même faire des copies des données du nœud 4. De cette manière, toutes les données, même au sein d'Alluxio, n'ont pas besoin d'être lues sur plusieurs machines, mais sont lues localement. Il semble donc qu'Alluxio ait considérablement atténué et optimisé le problème des E/S dans la formation à l'IA. Mais si vous regardez attentivement, vous découvrirez deux problèmes.

Le premier problème est que l'algorithme d'élimination du cache est très inefficace, car dans les scénarios d'IA, le mode d'accès aux données est très différent du passé. Le deuxième problème est que le cache, en tant que ressource, a une relation antagoniste avec la bande passante (c'est-à-dire la vitesse de lecture du stockage distant). Si le cache est volumineux, il y a moins de chances de lire les données depuis l'extrémité distante. Si le cache est petit, de nombreuses données doivent être lues depuis l'extrémité distante. Comment bien planifier et allouer ces ressources est également une question à considérer.
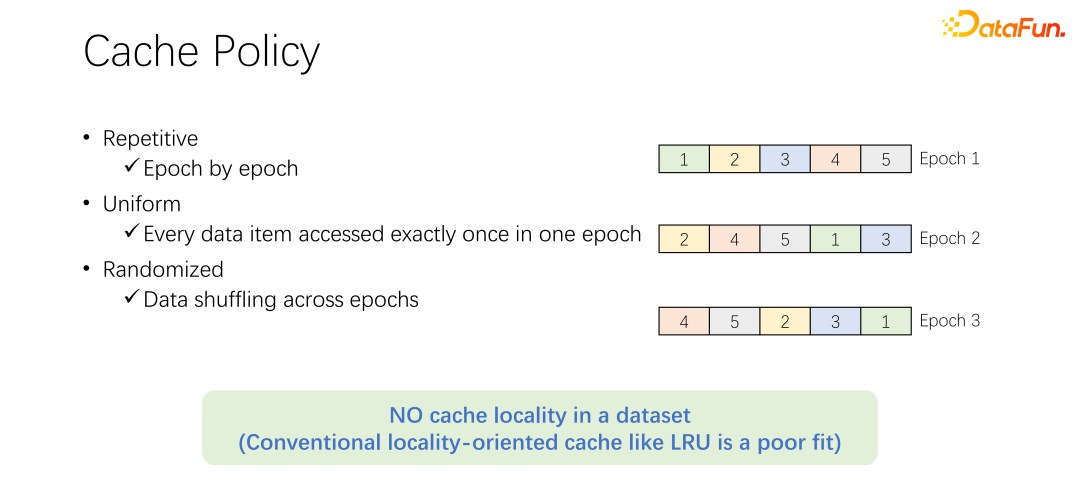 Avant de discuter de l'algorithme d'élimination du cache, jetons d'abord un coup d'œil au processus d'accès aux données dans la formation à l'IA. Dans la formation en IA, elle sera divisée en plusieurs époques et entraînée de manière itérative. À chaque époque de formation, chaque élément de données sera lu et lu une seule fois. Afin d'éviter un ajustement excessif de l'entraînement, après la fin de chaque époque, à l'époque suivante, l'ordre de lecture changera et une lecture aléatoire sera effectuée. C’est-à-dire que toutes les données seront lues une fois par époque, mais l’ordre est différent.
Avant de discuter de l'algorithme d'élimination du cache, jetons d'abord un coup d'œil au processus d'accès aux données dans la formation à l'IA. Dans la formation en IA, elle sera divisée en plusieurs époques et entraînée de manière itérative. À chaque époque de formation, chaque élément de données sera lu et lu une seule fois. Afin d'éviter un ajustement excessif de l'entraînement, après la fin de chaque époque, à l'époque suivante, l'ordre de lecture changera et une lecture aléatoire sera effectuée. C’est-à-dire que toutes les données seront lues une fois par époque, mais l’ordre est différent.
L'algorithme d'élimination LRU par défaut dans Alluxio ne peut évidemment pas être bien appliqué aux scénarios de formation d'IA. Parce que LRU profite de la localité du cache. La localité est divisée en deux aspects. Le premier est la localité temporelle, c'est-à-dire que les données consultées maintenant pourront être consultées bientôt. Cela n’existe pas dans la formation en IA. Parce que les données consultées maintenant ne le seront qu'au prochain tour, et le seront au prochain tour. Il n’y a aucune probabilité particulière que les données soient plus accessibles que d’autres données. De l’autre côté se trouve la localité des données, mais aussi la localité spatiale. En d'autres termes, la raison pour laquelle Alluxio utilise des blocs relativement volumineux pour mettre en cache les données est due au fait que lorsqu'une certaine donnée est lue, les données environnantes peuvent également être lues. Par exemple, dans les scénarios Big Data, les applications OLA
P analysent souvent les tables, ce qui signifie que les données environnantes seront accessibles immédiatement. Mais cela ne peut pas être appliqué dans des scénarios de formation à l’IA. Parce qu'il est mélangé à chaque fois, l'ordre de lecture est différent à chaque fois. Par conséquent, l’algorithme d’élimination LRU n’est pas adapté aux scénarios de formation de l’IA.

Non seulement LRU, mais aussi les algorithmes d'élimination traditionnels comme LFU ont un tel problème. Parce que l’ensemble de la formation en IA a un accès très égal aux données. Par conséquent, vous pouvez utiliser l’algorithme de mise en cache le plus simple, qui n’a besoin de mettre en cache qu’une partie des données et n’a jamais besoin d’y toucher. Après une tâche, seule une partie des données est toujours mise en cache. Ne l’éliminez jamais. Aucun algorithme d'élimination n'est requis. C’est probablement le meilleur mécanisme d’élimination qui existe.
Comme l'exemple dans l'image ci-dessus. Ci-dessus se trouve l’algorithme LRU et ci-dessous la méthode d’égalisation. Au début, seules deux données peuvent être mises en cache. Simplifions le problème. Il n'a que deux éléments de capacité, le cache D et B, et le milieu est la séquence d'accès. Par exemple, le premier accès est B. S'il s'agit de LRU, B est atteint dans le cache. L'accès suivant est C. C n'est pas dans le cache de D et B. Par conséquent, sur la base de la politique LRU, D sera remplacé et C sera conservé. Autrement dit, les caches sont actuellement C et B. Le prochain visité est A, qui n'est pas non plus dans C et B. B sera donc éliminé et remplacé par C et A. Le suivant est D, et D n'est pas dans le cache, il est donc remplacé par D et A. Par analogie, vous constaterez que tous les accès ultérieurs n’atteindront pas le cache. La raison en est que lorsque la mise en cache LRU est effectuée, elle est remplacée, mais en fait elle n'a été consultée qu'une seule fois au cours d'une époque, et elle ne sera plus jamais consultée à cette époque. LRU le met en cache à la place. Non seulement LRU n'aide pas, mais cela aggrave la situation. Il est préférable d'utiliser un uniforme, comme la méthode suivante.
La méthode uniforme suivante met toujours en cache D et B dans le cache et n'effectue jamais de remplacement. Dans ce cas, vous trouverez au moins un taux de réussite de 50 %. Vous pouvez donc voir que l'algorithme de mise en cache n'a pas besoin d'être compliqué. Utilisez simplement uniform. N'utilisez pas d'algorithmes tels que LRU et LFU.
Concernant la deuxième question, qui concerne la relation entre le cache et la bande passante distante. La lecture anticipée des données est désormais intégrée à tous les frameworks d'IA traditionnels pour empêcher le GPU d'attendre les données. Ainsi, lorsque le GPU s'entraîne, il déclenche en fait le CPU pour qu'il pré-prépare les données qui pourront être utilisées lors du tour suivant. Cela permet d'exploiter pleinement la puissance de calcul du GPU. Mais lorsque les E/S du stockage distant deviennent un goulot d'étranglement, cela signifie que le GPU doit attendre le CPU. Par conséquent, le GPU aura beaucoup de temps d’inactivité, ce qui entraînera un gaspillage de ressources. J'espère qu'il pourra y avoir une meilleure méthode de gestion de la planification pour atténuer les problèmes d'E/S.

Le cache et les E/S distantes ont un grand impact sur le débit de l'ensemble travail de. Ainsi, en plus du GPU, du CPU et de la mémoire, le cache et le réseau doivent également être planifiés. Dans le passé, le processus de développement du Big Data, tel que Hadoop, Yarn, My Source, K8, etc., était principalement programmé pour le processeur, la mémoire et le GPU. Le contrôle sur le réseau, notamment le cache, n'est pas très bon. Par conséquent, nous pensons que dans les scénarios d’IA, ils doivent être bien planifiés et alloués pour parvenir à l’optimisation de l’ensemble du cluster.
2. Framework SiloD

#🎜 🎜# a publié un tel article à EuroSys 2023, qui est un cadre unifié pour planifier les ressources informatiques et les ressources de stockage.
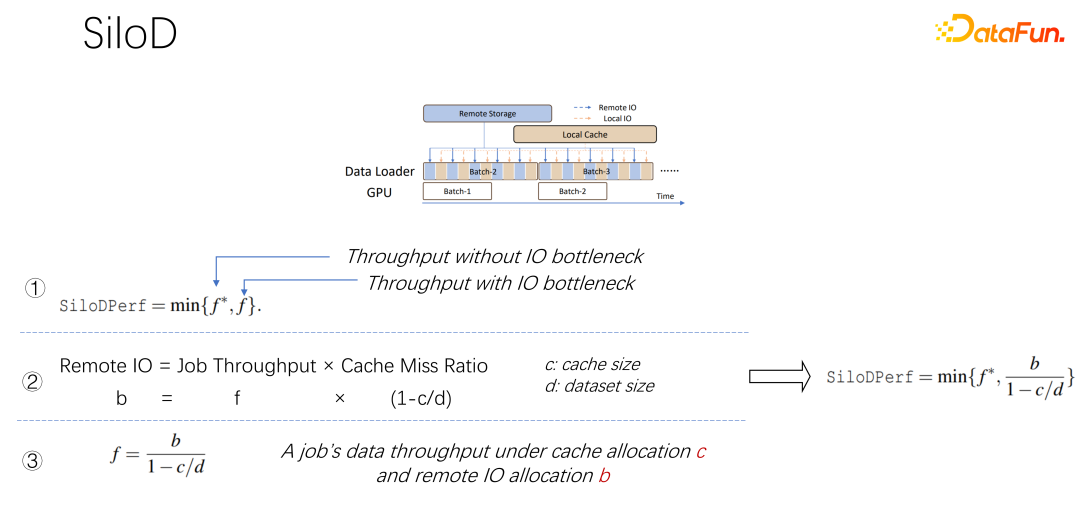
Comme le montre la figure ci-dessus, quel type de débit un travail peut-il atteindre et les performances sont déterminées par la valeur minimale du GPU et des E/S. Combien d’E/S distantes sont utilisées, quelle quantité de réseau distant est utilisée. La vitesse d'accès peut être calculée grâce à une telle formule. La vitesse de la tâche est multipliée par le taux d'échec du cache, qui est de (1-c/d). Où c est la taille du cache et d est l'ensemble de données. Cela signifie que lorsque les données ne prennent en compte que les E/S et peuvent devenir un goulot d'étranglement, le débit approximatif est égal à (b/(1-c/d)), où b est la bande passante distante. En combinant les trois formules ci-dessus, nous pouvons déduire la formule de droite, qui correspond au type de performances qu'un travail souhaite finalement atteindre. Vous pouvez utiliser la formule pour calculer les performances lorsqu'il n'y a pas de goulot d'étranglement d'E/S et les performances lorsqu'il y en a. Goulot d’étranglement IO. Prenez celui entre les deux valeurs minimales. Après avoir obtenu la formule ci-dessus, en la différenciant, vous pouvez obtenir l'efficacité du cache, ou l'efficacité du cache. Autrement dit, même s'il existe de nombreux travaux, ils ne peuvent pas être traités de la même manière lors de l'allocation du cache. Chaque tâche, basée sur différents ensembles de données et vitesses, est très particulière quant à la quantité de cache allouée. Voici un exemple, en prenant cette formule comme exemple. Si vous trouvez un travail qui est très rapide et qui s'entraîne très rapidement, et que l'ensemble de données est petit, cela signifie allouer un cache plus grand et les avantages seront plus importants.
Sur la base des observations ci-dessus, SiloD peut être utilisé pour l'allocation de cache et de réseau. De plus, la taille du cache est allouée en fonction de la vitesse de chaque tâche et de la taille totale de l'ensemble de données. Il en va de même pour le Web. L'ensemble de l'architecture est donc comme ceci : en plus de la planification des tâches traditionnelle comme celle des K8, il y a aussi la gestion des données. Sur le côté gauche de la figure, par exemple, la gestion du cache nécessite des statistiques ou une surveillance de la taille du cache alloué à l'ensemble du cluster, de la taille de chaque cache de tâches et de la taille des E/S distantes utilisées par chaque tâche. Les opérations suivantes sont très similaires à la méthode Alluxio, et toutes deux peuvent utiliser des API pour la formation des données. Utilisez le cache sur chaque travailleur pour fournir une prise en charge de la mise en cache pour les tâches locales. Bien entendu, il peut également s’étendre sur les nœuds d’un cluster et peut également être partagé.
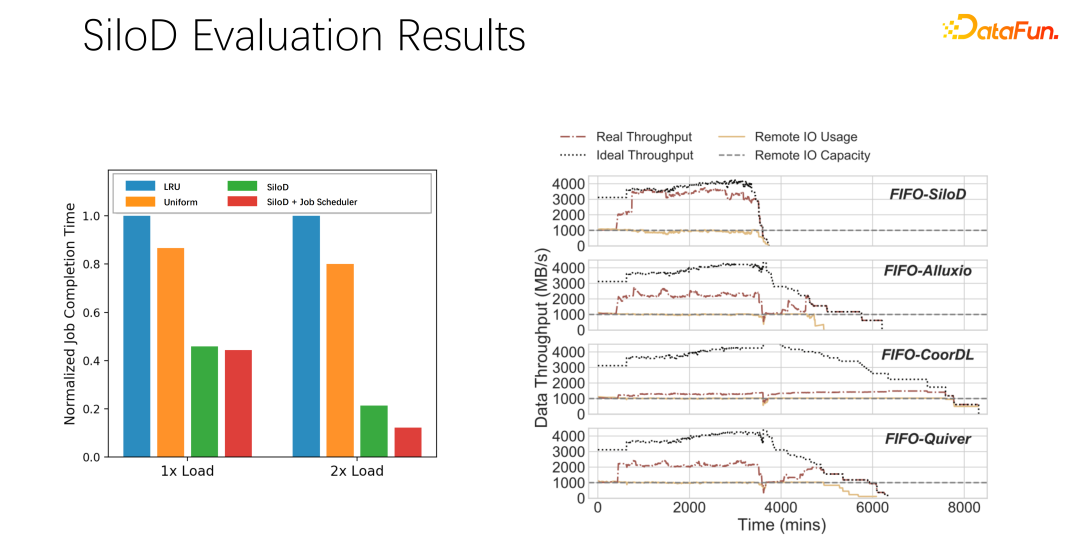
Après des tests et des expériences préliminaires, il a été constaté qu'une telle méthode d'allocation peut améliorer considérablement l'utilisation et le débit de l'ensemble du cluster, jusqu'à 8 fois l'amélioration des performances. Cela peut évidemment atténuer le statut d’attente de travail et l’inactivité du GPU.

Résumons l'introduction ci-dessus :
Tout d'abord, Dans les scénarios de formation en IA ou en apprentissage profond, les stratégies de mise en cache traditionnelles telles que LRU et LFU ne conviennent pas, elles Il est préférable d'utiliser l'uniforme directement.
Deuxièmement, la mise en cache et la bande passante distante sont une paire de partenaires qui jouent un très grand rôle dans les performances globales.
Troisièmement, Les principaux cadres de planification tels que les K8 et le fil peuvent être facilement hérités de SiloD.
Enfin, Nous avons réalisé quelques expériences dans le journal. Différentes stratégies de planification peuvent apporter des améliorations évidentes du débit.
3. Stratégie de mise en cache distribuée et gestion des copies
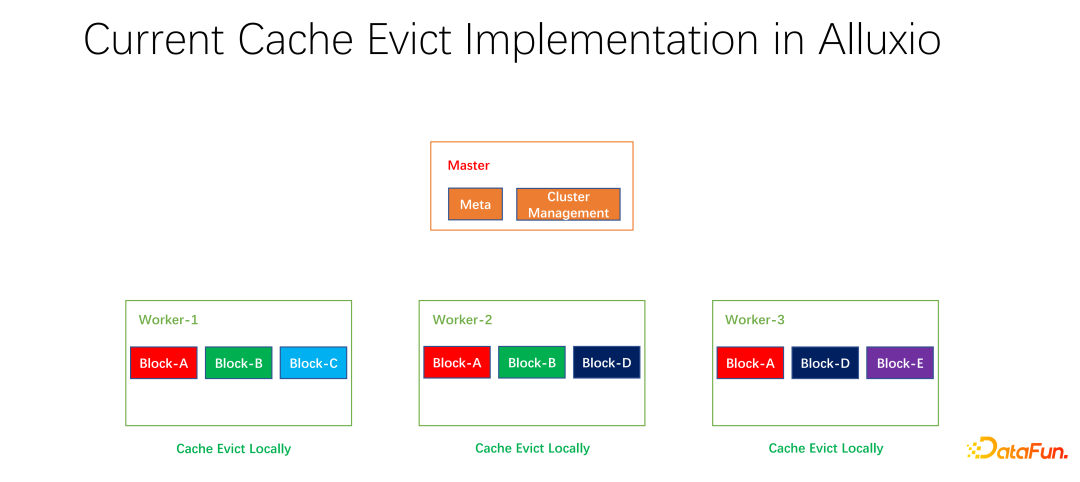
Nous avons également effectué du travail open source. Ce travail sur la stratégie de mise en cache distribuée et la gestion des répliques a été soumis à la communauté et est maintenant en phase de PR. Alluxio master est principalement responsable de la gestion de Meta et de la gestion de l'ensemble du cluster de travail. C'est le travailleur qui met réellement en cache les données. Il existe de nombreux blocs en unités de blocs pour mettre en cache les données. Un problème est que les stratégies de mise en cache actuelles s'appliquent à un seul travailleur. Lors du calcul de l'élimination ou non de chaque donnée au sein du travailleur, elles ne doivent être calculées que sur un seul travailleur et sont localisées.
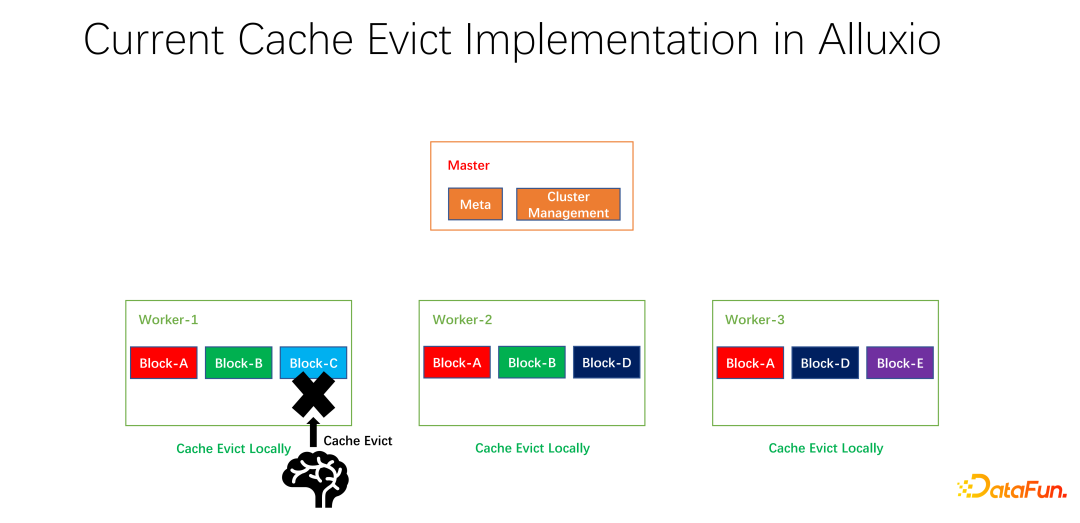
Comme le montre l'exemple ci-dessus, s'il y a le bloc A, le bloc B et le bloc C sur le travailleur 1, il est calculé en fonction du LRU que le bloc C n'a pas été utilisé depuis le plus longtemps , et le bloc sera supprimé. C est éliminé. Si vous regardez la situation globale, vous constaterez que ce n’est pas bon. Parce que le bloc C n'a qu'une seule copie dans l'ensemble du cluster. Une fois éliminé, si quelqu'un d'autre souhaite accéder au bloc C, il ne peut extraire les données que de l'extrémité distante, ce qui entraînera des pertes de performances et de coûts. Nous proposons une stratégie d’élimination globale. Dans ce cas, le bloc C ne doit pas être éliminé, mais celui qui contient le plus de copies doit être éliminé. Dans cet exemple, le bloc A doit être éliminé car il possède encore deux copies sur d'autres nœuds, ce qui est meilleur en termes de coût et de performances.
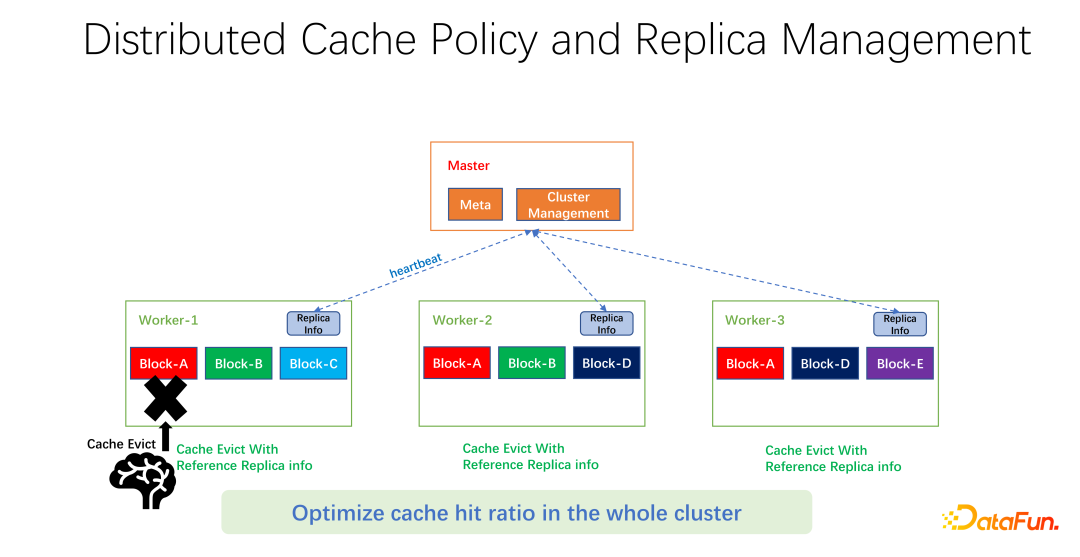
Comme le montre la figure ci-dessus, ce que nous faisons est de conserver des informations de réplique sur chaque travailleur. Lorsqu'un travailleur, par exemple, ajoute une copie ou supprime une copie, il fera d'abord rapport au maître, et le maître utilisera ces informations comme valeur de retour de battement de cœur et les renverra aux autres travailleurs associés. Les autres travailleurs peuvent connaître les modifications en temps réel de l'intégralité de la copie globale. En même temps, les informations de copie sont mises à jour. Par conséquent, lors de l’élimination des travailleurs internes, vous pouvez connaître le nombre d’exemplaires de chaque travailleur dans le monde entier et concevoir des pondérations. Par exemple, LRU est toujours utilisé, mais le poids du nombre de répliques est ajouté pour déterminer de manière exhaustive les données à éliminer et à remplacer.
Après nos tests préliminaires, il peut apporter de grandes améliorations dans de nombreux domaines, qu'il s'agisse du big data ou de la formation en IA. Il ne s’agit donc pas seulement d’optimiser les accès au cache pour un travailleur sur une machine. Notre objectif est d'améliorer le taux de réussite du cache de l'ensemble du cluster.

la plupart# Après 🎜🎜#, résumons le texte intégral. Tout d'abord, dans les scénarios de formation à l'IA, l'algorithme d'élimination uniforme du cache est meilleur que les LRU et LFU traditionnels. Deuxièmement, le cache et la mise en réseau à distance sont également des ressources qui doivent être allouées et planifiées. Troisièmement, lors de l'optimisation du cache, ne le limitez pas à une seule tâche ou à un seul travailleur. Vous devez prendre en compte l'ensemble des paramètres globaux de bout en bout, afin que l'efficacité et les performances de l'ensemble du cluster puissent être mieux améliorées.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI