
Maison >base de données >Redis >Quel est le concept de pénétration du cache Redis et d'avalanche de cache
Quel est le concept de pénétration du cache Redis et d'avalanche de cache

- 王林avant
- 2023-05-27 16:35:20882parcourir
1. Pénétration du cache
1. Concept
Le concept de pénétration du cache est très simple. Pour interroger une donnée, il a été constaté que la base de données mémoire Redis n'existait pas, c'est-à-dire que le cache n'a pas fonctionné, la requête a donc été adressée à la base de données de la couche de persistance. Il s’est avéré qu’il n’y en avait pas, cette requête a donc échoué. Lorsqu'il y a de nombreux utilisateurs, le cache ne fonctionne pas, ils demandent donc tous la base de données de la couche de persistance. En cas de pénétration du cache, la base de données de la couche de persistance supportera un énorme fardeau.
Vous devez faire attention à la différence entre la panne de cache et la panne de cache. La panne de cache fait référence à une clé qui est très chaude et qui transporte constamment une grande concurrence se concentre sur ce point. . Accès, lorsque la clé expire, la grande concurrence continue traverse le cache et demande directement la base de données, tout comme percer un trou dans une barrière.
Il existe en réalité de nombreuses solutions pour éviter la pénétration du cache. Plusieurs sont présentés ci-dessous.
2. Solution
(1) Filtre Bloom
#🎜🎜 #Selon Selon les statistiques, le nombre total de sites Web de spam et de sites Web normaux dans le monde atteint des milliards. Le filtre Bloom est une structure de données qui peut être appliquée à cette échelle de données. L'utilisation des filtres Bloom évite à la police d'Internet d'avoir à comparer un par un les sites Web de spam dans la base de données. Supposons que nous stockions 100 millions d’adresses de sites Web de spam. Vous pouvez commencer avec 100 millions de bits binaires, puis la police d'Internet utilise huit générateurs de nombres aléatoires différents (F1, F2, …, F8) pour générer huit empreintes digitales d'informations (f1, f2, …, f8 ). Ensuite, un générateur de nombres aléatoires G est utilisé pour mapper ces huit empreintes digitales d'informations sur huit nombres naturels g1, g2,…, g8 de 1 à 100 millions. Enfin, définissez toutes les valeurs binaires de ces huit positions sur un. Le processus est le suivant :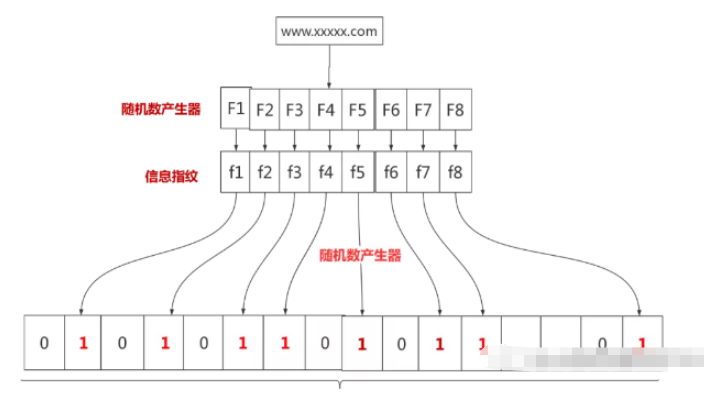
2. Cachez les objets vides
Lorsque la couche de stockage manque, même l'objet vide renvoyé sera mis en cache et sera défini. , après quoi les données seront accessibles à partir du cache, protégeant la source de données back-end- Étant donné que les valeurs nulles peuvent occuper de nombreuses positions clés dans le cache, le cache nécessite plus d'espace pour stocker plus de paires clé-valeur
- #🎜🎜 #Même si le délai d'expiration est défini pour la valeur nulle, il y aura toujours une fenêtre d'incohérence entre les données de la couche de cache et la couche de stockage, ce qui est important pour ceux qui ont besoin de maintenir cohérence. Il y aura un impact sur les entreprises.
- 2. Avalanche de cache
2. Solution
(1) redis haute disponibilité
La signification de cette idée est que puisque redis peut raccrocher, alors j'ajouterai quelques redis supplémentaires pour que les autres puissent continuer à travailler après que l'un d'entre eux ait raccroché. en fait, c'est un cluster construit.
(2) Déclassement de limitation actuelle
L'idée de cette solution est d'utiliser des méthodes de verrouillage ou de file d'attente pour contrôler la lecture de la base de données après l'expiration du cache Et le nombre de threads écrivant dans le cache. Par exemple, un seul thread est autorisé à interroger des données et à écrire dans le cache pour exploiter une certaine clé, et les threads restants doivent attendre.
(3) Préchauffage des données
La signification du chauffage des données est qu'avant le déploiement formel, j'accède d'abord aux données possibles à l'avance, donc la partie des données accessible en grande quantité sera chargée dans le cache. Déclenchez manuellement le chargement du cache de différentes clés et définissez différents délais d'expiration pour tenter d'équilibrer le temps d'invalidation du cache et empêcher un grand nombre d'accès de se produire en même temps.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!