
Maison >base de données >tutoriel mysql >Que sont les curseurs et les variables de liaison dans MySQL
Que sont les curseurs et les variables de liaison dans MySQL

- PHPzavant
- 2023-05-27 13:30:191508parcourir
1. Introduction aux curseurs MySQL
MySQL fournit des curseurs unidirectionnels en lecture seule côté serveur et ne peuvent être utilisés que dans des procédures stockées ou des API client de niveau inférieur.
Le curseur MySQL est en lecture seule car l'objet vers lequel il pointe est stocké dans une table temporaire au lieu des données réellement interrogées. Il peut pointer vers les résultats de la requête ligne par ligne, puis laisser le programme poursuivre le traitement. Dans une procédure stockée, les curseurs peuvent être utilisés plusieurs fois et peuvent être « imbriqués » dans des structures de boucles.
La conception du curseur de MySQL « prépare » également des pièges pour les imprudents. Parce qu’il est implémenté à l’aide de tables temporaires, il donne aux développeurs une illusion d’efficacité. La nécessité d’exécuter l’intégralité de la requête lors de l’ouverture d’un curseur est la chose la plus importante à noter.
Considérez la procédure stockée suivante :
CREATE PROCEDURE bad_cursor() BEGIN DECLARE film_id INT; DECLARE f CURSOR FOR SELECT film_id FROM sakila.film; OPEN f; FETCH f INTO film_id; CLOSE f; END
Cet exemple montre qu'un curseur peut être fermé immédiatement lors du traitement de données inachevées. Les utilisateurs utilisant Oracle ou SQL Server ne penseront pas qu'il y a de problème avec cette procédure stockée, mais dans MySQL, cela entraînera de nombreuses opérations supplémentaires inutiles. Utilisez SHOW STATUS pour diagnostiquer cette procédure stockée. Vous pouvez voir qu'elle doit lire 1 000 pages d'index et effectuer 1 000 écritures. Dans la cinquième ligne de l'action d'ouverture du curseur, 1 000 opérations de lecture et d'écriture ont eu lieu car il y avait 1 000 enregistrements dans la table sakila.film.
Ce cas nous indique que si vous analysez seulement une petite partie d'un grand ensemble de résultats lors de la fermeture du curseur, la procédure stockée peut non seulement échouer à réduire la surcharge, mais apporter à la place beaucoup de ressources supplémentaires. aérien. À ce stade, vous devez envisager d'utiliser LIMIT pour limiter le jeu de résultats renvoyé.
L'utilisation de curseurs peut amener MySQL à effectuer des opérations d'E/S supplémentaires inefficaces. Étant donné que les tables de mémoire temporaire ne prennent pas en charge les types BLOB et TEXT, si les résultats renvoyés par le curseur contiennent de telles colonnes, MySQL doit créer une table de disque temporaire pour les stocker, ce qui peut entraîner de mauvaises performances. Même sans cette colonne, MySQL créera toujours une table temporaire sur le disque lorsque la table temporaire dépassera tmp_table_size.
Bien que MySQL ne prenne pas en charge les curseurs côté client, les curseurs peuvent être simulés en mettant en cache tous les résultats de requête via l'API client. Ce n'est pas différent de conserver les résultats directement dans une matrice mémoire.
2. Variables de liaison
À partir de la version MySQL 4.1, les variables de liaison côté serveur (instruction préparée) sont prises en charge, ce qui améliore considérablement la transmission de données côté client et côté serveur . efficacité. Si vous utilisez un client prenant en charge le nouveau protocole, tel que MySQL CAPI, vous pouvez utiliser la fonctionnalité de variable de liaison. De plus, Java et .NET peuvent également utiliser leurs clients respectifs Connector/J et Connector/NET pour utiliser des variables de liaison.
Enfin, il existe une interface SQL pour prendre en charge les variables de liaison, dont nous parlerons plus tard (cela peut facilement prêter à confusion ici).
Le client envoie un modèle de l'instruction SQL au serveur pour créer un SQL qui lie les variables. Après avoir reçu la trame d'instruction SQL, le serveur analyse et stocke le plan d'exécution partiel de l'instruction SQL et renvoie un handle de traitement d'instruction SQL au client. Chaque fois que ce type de requête est exécuté à l'avenir, le client spécifie l'utilisation de ce handle.
Pour les variables de liaison SQL, des points d'interrogation sont utilisés pour marquer les emplacements où les paramètres peuvent être reçus. Lorsque des requêtes spécifiques sont réellement nécessaires, des valeurs spécifiques sont utilisées pour remplacer ces points d'interrogation. Par exemple, ce qui suit est une instruction SQL qui lie des variables :
INSERT INTO tbl(col1, col2, col3) VALUES (?, ?, ?);
Envoyez le handle SQL et chaque valeur de paramètre de point d'interrogation au serveur pour exécuter une requête spécifique. L'exécution répétée de requêtes spécifiques de cette manière constitue l'avantage des variables de liaison. La méthode spécifique d'envoi des paramètres de valeur et des handles SQL dépend du langage de programmation de chaque client. Utiliser le connecteur MySQL pour Java et .NET est une solution. De nombreux clients utilisant la bibliothèque de liens du langage MySQL C peuvent fournir des interfaces similaires. Vous devez comprendre comment utiliser les variables de liaison selon la documentation du langage de programmation utilisé.
Pour les raisons suivantes, MySQL peut exécuter un grand nombre d'instructions répétées plus efficacement lors de l'utilisation de variables de liaison :
1 Dans le serveur. il suffit d'analyser l'instruction SQL une seule fois.
2. Certains travaux d'optimisation côté serveur ne doivent être exécutés qu'une seule fois car ils mettent en cache une partie du plan d'exécution.
Seul l'envoi de paramètres et de handles en binaire est plus efficace que l'envoi de texte ASCII à chaque fois. Un champ de date binaire ne nécessite que trois octets, mais s'il s'agit de code ASCII, dix. des octets sont nécessaires. En utilisant la forme de variables de liaison, les champs BLOB et TEXT peuvent être transmis en morceaux, réalisant ainsi des économies maximales. Cela élimine le besoin d’un transfert unique. Les protocoles binaires peuvent également économiser beaucoup de mémoire côté client, réduire la surcharge du réseau et également économiser la surcharge liée à la conversion des données du format de stockage d'origine vers un format texte.
4. Seuls les paramètres - et non l'intégralité de l'instruction de requête - doivent être envoyés au serveur, la surcharge du réseau sera donc réduite.
5. Lorsque MySQL stocke les paramètres, il les stocke directement dans le cache, éliminant ainsi le besoin de les copier plusieurs fois en mémoire.
Les variables liées sont relativement plus sûres. Ne pas avoir à gérer l'échappement dans l'application rend les choses beaucoup plus simples tout en réduisant considérablement le risque d'injection SQL et d'attaques. (Ne faites jamais confiance aux entrées de l'utilisateur à aucun moment, même lorsque vous utilisez des variables de liaison.)
可以只在使用绑定变量的时候才使用二进制传输协议。如果使用常规的mysql_query()接口,则无法使用二进制传输协议。还有一些客户端让你使用绑定变量,先发送带参数的绑定SQL,然后发送变量值,但是实际上,这些客户端只是模拟了绑定变量的接口,最后还是会直接用具体值代替参数后,再使用mysql_query()发送整个查询语句。
2.1 绑定变量的优化
对使用绑定变量的SQL,MySQL能够缓存其部分执行计划,如果某些执行计划需要根据传入的参数来计算时,MySQL就无法缓存这部分的执行计划。根据优化器什么时候工作,可以将优化分为三类。
在本书编写的时候,下面的三点是适用的。
1.在准备阶段
服务器解析SQL语句,移除不可能的条件,并且重写子查询。
2.在第一次执行的时候
如果可能的话,服务器先简化嵌套循环的关联,并将外关联转化成内关联。
3.在每次SQL语句执行时
服务器做如下事情:
1)过滤分区。
2)如果可能的话,尽量移除COUNT()、MIN()和MAX()。
3)移除常数表达式。
4)检测常量表。
5)做必要的等值传播。
6)分析和优化ref、range和索引优化等访问数据的方法。
7)优化关联顺序。
2.2 SQL接口的绑定变量
MySQL支持了SQL接口的绑定变量。不使用二进制传输协议也可以直接以SQL的方式使用绑定变量。下面案例展示了如何使用SQL接口的绑定变量:
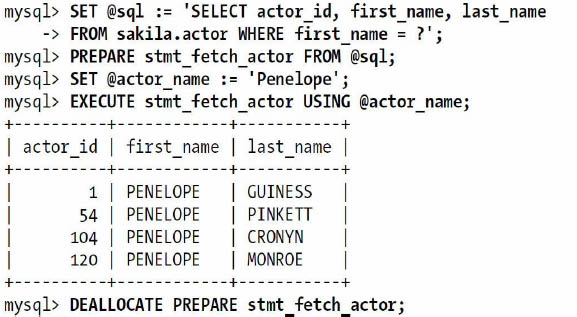
当服务器收到这些SQL语句后,先会像一般客户端的链接库一样将其翻译成对应的操作。
这意味着你无须使用二进制协议也可以使用绑定变量。
正如你看到的,比起直接编写的SQL语句,这里的语法看起来有一些怪怪的。
那么,这种写法实现的绑定变量到底有什么优势呢?
最主要的用途就是在存储过程中使用。在MySQL 5.0版本中,就可以在存储过程中使用绑定变量,其语法和前面介绍的SQL接口的绑定变量类似。意思是在存储过程中可以创建和运行基于动态SQL语句的代码
“动态”是指可以通过灵活地拼接字符串等参数构建SQL语句。举个例子,下面这个存储过程可以在特定的数据库中执行OPTIMIZE TABLE操作:
DROP PROCEDURE IF EXISTS optimize_tables;
DELIMITER //
CREATE PROCEDURE optimize_tables(db_name VARCHAR(64))
BEGIN
DECLARE t VARCHAR(64);
DECLARE done INT DEFAULT 0;
DECLARE c CURSOR FOR
SELECT table_name FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = db_name AND TABLE_TYPE = 'BASE TABLE';
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
OPEN c;
tables_loop: LOOP
FETCH c INTO t;
IF done THEN
LEAVE tables_loop;
END IF;
SET @stmt_text := CONCAT("OPTIMIZE TABLE ", db_name, ".", t);
PREPARE stmt FROM @stmt_text;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END LOOP;
CLOSE c;
END//
DELIMITER ;可以这样调用这个存储过程:
mysql> CALL optimize_tables('sakila')
另一种实现存储过程中循环的办法是:
REPEAT
FETCH c INTO t;
IF NOT done THEN
SET @stmt_text := CONCAT("OPTIMIZE TABLE ", db_name, ".", t);
PREPARE stmt FROM @stmt_text;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END IF;
UNTIL done END REPEAT;REPEAT和其他循环结构最大的不同是,它在每次循环中都会检查两次循环条件。在这个例子中,因为循环条件检查的是一个整数判断,并不会有什么性能问题,如果循环的判断条件非常复杂的话,则需要注意这两者的区别。
像这样使用SQL接口的绑定变量拼接表名和库名是很常见的,这样的好处是无须使用任何参数就能完成SQL语句。由于库名和表名都是关键字,因此在绑定变量的二进制协议中无法将这两个参数化。LIMIT子句是另一个经常需要动态设置的,因为在二进制协议中无法将其参数化。
另外,编写存储过程时,SQL接口的绑定变量通常可以很大程度地帮助我们调试绑定变量,如果不是在存储过程中,SQL接口的绑定变量就不是那么有用了。因为SQL接口的绑定变量,它既没有使用二进制传输协议,也没有能够节省带宽,相反还总是需要增加至少一次额外网络传输才能完成一次查询。所有只有在某些特殊的场景下SQL接口的绑定变量才有用,比如当SQL语句非常非常长,并且需要多次执行的时候。
2.3 绑定变量的限制
关于绑定变量的一些限制和注意事项如下:
1.绑定变量是会话级别的,所以连接之间不能共用绑定变量句柄。同样地,一旦连接断开,则原来的句柄也不能再使用了。(连接池和持久化连接可以在一定程度上缓解这个问题。)
2.在MySQL 5.1版本之前,绑定变量的SQL是不能使用查询缓存的。
3.并不是所有的时候使用绑定变量都能获得更好的性能。如果只是执行一次SQL,那么使用绑定变量方式无疑比直接执行多了一次额外的准备阶段消耗,而且还需要一次额外的网络开销。(要正确地使用绑定变量,还需要在使用完成后,释放相关的资源。)
4. Dans la version actuelle, les variables de liaison ne peuvent pas être utilisées dans les fonctions stockées (mais elles peuvent être utilisées dans les procédures stockées).
Si les ressources liées aux variables ne sont pas libérées, des fuites de ressources peuvent facilement se produire côté serveur. Étant donné que la limite du nombre total de variables SQL de liaison est une limite globale, une erreur à un endroit peut affecter tous les autres threads.
6. Certaines opérations, telles que BEGIN, ne peuvent pas être effectuées dans les variables de liaison.
Cependant, le plus gros obstacle à l'utilisation des variables de liaison peut être :
Comment c'est implémenté et quel est le principe, ces deux points prêtent facilement à confusion. Parfois, il est difficile d'expliquer quelle est la différence entre les trois types de variables de liaison suivants :
1. Variables de liaison simulées côté client
Le pilote client reçoit un code SQL avec des paramètres, puis ajoute la valeur spécifiée dans et enfin envoyer la requête complète côté serveur.
2. Lier les variables côté serveur
Le client utilise un protocole binaire spécial pour envoyer la chaîne avec les paramètres au serveur, puis utilise le protocole binaire pour envoyer la valeur du paramètre spécifique au serveur et l'exécuter. il.
3. Lier les variables de l'interface SQL
Le client envoie d'abord une chaîne avec des paramètres au serveur, ce qui est similaire à l'instruction SQL utilisant PREPARE, puis envoie le SQL pour définir les paramètres, et enfin utilise EXÉCUTER Exécute SQL. Tout cela utilise des protocoles de transfert de texte ordinaires.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!