
Maison >base de données >tutoriel mysql >Comment utiliser l'index clusterisé, l'index auxiliaire, l'index de couverture et l'index conjoint dans MySQL
Comment utiliser l'index clusterisé, l'index auxiliaire, l'index de couverture et l'index conjoint dans MySQL

- 王林avant
- 2023-05-27 12:25:572075parcourir
Index clusterisé
Un index clusterisé construit un arbre B+ basé sur la clé primaire de chaque table, et les données d'enregistrement de ligne de la table entière sont stockées dans les nœuds feuilles.
Par exemple, ressentons intuitivement l'index clusterisé.
Créez la table t et autorisez artificiellement chaque page à stocker seulement deux enregistrements de ligne (je ne sais pas comment contrôler artificiellement seulement deux enregistrements de ligne par page) :
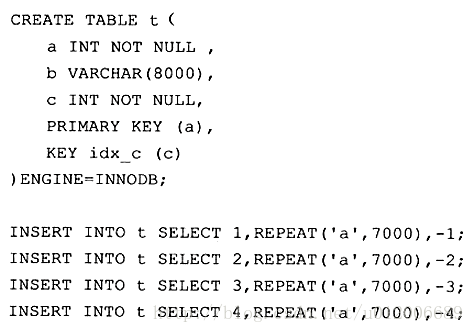
Enfin, "MySQL Technology Insider" L'auteur a obtenu la structure approximative de cet arbre d'index clusterisé à l'aide des outils d'analyse suivants :
Les nœuds feuilles d'un index clusterisé sont appelés pages de données, dont chacune est liée par une liste doublement chaînée, et les pages de données sont organisées dans l'ordre des clés primaires.
Comme le montre la figure, chaque page de données stocke un enregistrement de ligne complet, tandis que dans la page d'index de la page sans données, seules la valeur clé et le décalage pointant vers la page de données sont stockés, plutôt qu'un enregistrement de ligne complet. .
Si une clé primaire est définie, InnoDB utilisera automatiquement la clé primaire pour créer un index clusterisé. Lorsqu'aucune clé primaire n'est définie, InnoDB choisira un index unique et non vide pour servir de clé primaire. InnoDB définira implicitement une clé primaire comme un index clusterisé s'il n'y a pas d'index unique non nul.
Index secondaire
Index auxiliaire, également appelé index non clusterisé. Par rapport à l'index clusterisé, les nœuds feuilles ne contiennent pas toutes les données de l'enregistrement de ligne. En plus de la valeur clé, la ligne d'index du nœud feuille contient également un signet (signet), qui est utilisé pour indiquer à InnoDB où trouver les données de ligne correspondant à l'index.
Utilisons l'exemple de "MySQL Technology Insider" pour ressentir intuitivement à quoi ressemble l'index auxiliaire.
Toujours en prenant comme exemple le tableau t ci-dessus, créez un index non clusterisé sur la colonne c :
Ensuite l'auteur a obtenu le diagramme de relation entre l'index auxiliaire et l'index clusterisé grâce à un travail d'analyse :
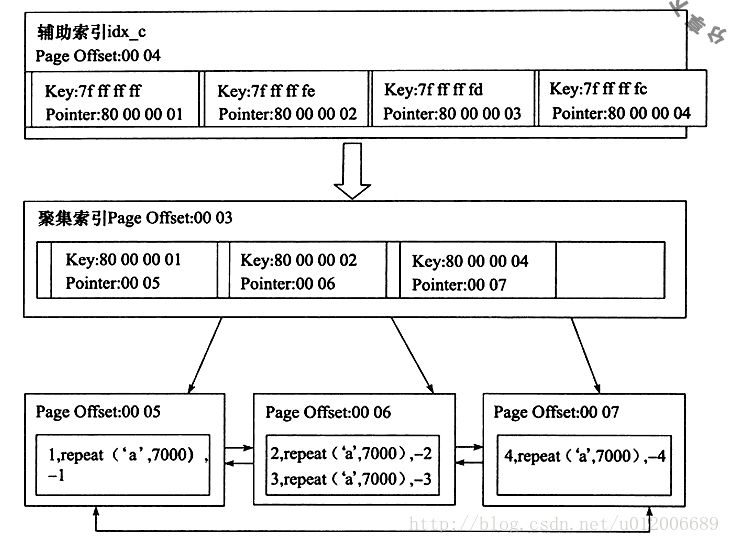
Vous pouvez voir l'index auxiliaire. Le nœud feuille de idx_c contient la valeur de la colonne c et la valeur de la clé primaire.
Par exemple, supposons que la valeur de Key soit 0x7ffffffff, où la représentation binaire de 7 est 0111 et 0 est un nombre négatif. La valeur entière réelle doit être inversée plus 1, donc le résultat est -1, et c'est la valeur dans la colonne c. La valeur de la clé primaire est un nombre positif 1, représenté par la valeur du pointeur 80000001, où 8 bits représentent le nombre binaire 1000.
Index de couverture
En utilisant le moteur de stockage InnoDB, vous pouvez couvrir l'index via l'index auxiliaire et obtenir les enregistrements de requête directement sans interroger les enregistrements dans l'index clusterisé.
Quels sont les avantages de l'utilisation de l'indice couvrant ?
peut réduire de nombreuses opérations d'E/S
Dans l'image ci-dessus, nous savons que si vous souhaitez interroger des champs qui ne sont pas inclus dans l'index auxiliaire, vous devez d'abord parcourir l'index auxiliaire, puis parcourir l'index clusterisé .Si la valeur du champ à interroger est déjà sur l'index auxiliaire, il n'est donc pas nécessaire de vérifier l'index clusterisé, ce qui réduira évidemment les opérations d'E/S.
Par exemple, dans l'image ci-dessus, le SQL suivant peut utiliser directement l'index auxiliaire,
select a from where c = -2;
est utile pour les statistiques
Supposons que la table suivante existe :
CREATE TABLE `student` ( `id` bigint(20) NOT NULL, `name` varchar(255) NOT NULL, `age` varchar(255) NOT NULL, `school` varchar(255) NOT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`), KEY `idx_school_age` (`school`,`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Si elle est exécutée sur cette table :
select count(*) from student
Qu'arrivera-t-il à l'optimiseur ?
L'optimiseur choisira l'index auxiliaire pour les statistiques, car bien que des résultats puissent être obtenus en parcourant à la fois l'index clusterisé et l'index auxiliaire, la taille de l'index auxiliaire est beaucoup plus petite que l'index clusterisé. Exécutez la commande expliquer :

key et Extra montrent que l'index auxiliaire idx_name est utilisé.
Supposons également que le SQL suivant soit exécuté :
select * from student where age > 10 and age < 15
Étant donné que l'ordre des champs de l'index conjoint idx_school_age est d'abord school puis age, une requête conditionnelle est effectuée en fonction de l'âge, généralement sans utiliser l'index :

Cependant, si les conditions restent inchangées, interrogez tous les champs au lieu d'interroger le nombre d'entrées :
select count(*) from student where age > 10 and age < 15
L'optimiseur choisira cet index conjoint :

Index conjoint
L'index conjoint fait référence à l'indexation de plusieurs colonnes sur la table.
Voici un exemple de création d'un index conjoint idx_a_b :

La structure interne de l'index conjoint :
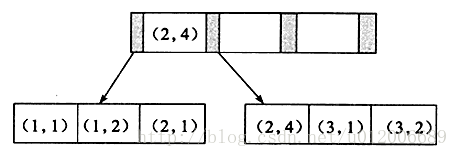
联合索引也是一棵B+树,其键值数量大于等于2。键值都是排序的,通过叶子节点可以逻辑上顺序的读出所有数据。数据(1,1)(1,2)(2,1)(2,4)(3,1)(3,2)是按照(a,b)先比较a再比较b的顺序排列。
基于上面的结构,对于以下查询显然是可以使用(a,b)这个联合索引的:
select * from table where a=xxx and b=xxx ; select * from table where a=xxx;
但是对于下面的sql是不能使用这个联合索引的,因为叶子节点的b值,1,2,1,4,1,2显然不是排序的。
select * from table where b=xxx
联合索引的第二个好处是对第二个键值已经做了排序。举个例子:
create table buy_log(
userid int not null,
buy_date DATE
)ENGINE=InnoDB;
insert into buy_log values(1, '2009-01-01');
insert into buy_log values(2, '2009-02-01');
alter table buy_log add key(userid);
alter table buy_log add key(userid, buy_date);当执行
select * from buy_log where user_id = 2;
时,优化器会选择key(userid);但是当执行以下sql:
select * from buy_log where user_id = 2 order by buy_date desc;
时,优化器会选择key(userid, buy_date),因为buy_date是在userid排序的基础上做的排序。
如果把key(userid,buy_date)删除掉,再执行:
select * from buy_log where user_id = 2 order by buy_date desc;
优化器会选择key(userid),但是对查询出来的结果会进行一次filesort,即按照buy_date重新排下序。所以联合索引的好处在于可以避免filesort排序。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!