
Maison >base de données >tutoriel mysql >Quel est le processus de requête d'index secondaire MySQL ?
Quel est le processus de requête d'index secondaire MySQL ?

- PHPzavant
- 2023-05-27 12:16:131419parcourir
Préface
L'index clusterisé est la structure d'index basée sur la clé primaire créée par innodb par défaut, et les données de la table sont directement placées dans l'index clusterisé en tant que page de données du nœud feuille : #🎜 🎜#
- Insérez les données complètes dans la page de données du nœud feuille de l'index clusterisé et maintenez l'index clusterisé en même temps
- Pour l'index établi pour vos autres champs, rétablissez un arbre B+
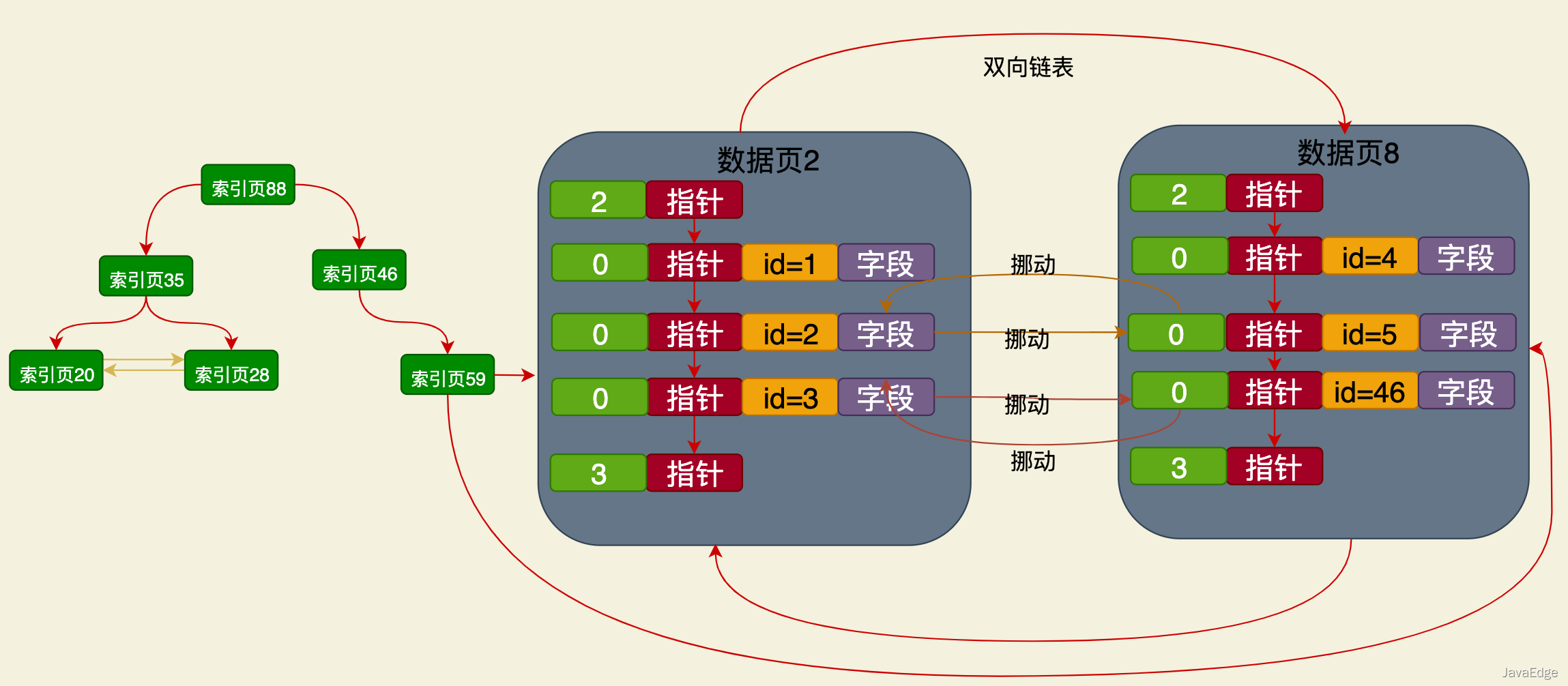
#🎜🎜 # Il s'agit d'une structure d'index basée sur l'arborescence B+ dont le champ de nom est indépendant de l'index clusterisé. Les données stockées dans ses nœuds feuilles. contient uniquement les valeurs de la clé primaire et du champ nom.
Il s'agit d'une structure d'index basée sur l'arborescence B+ dont le champ de nom est indépendant de l'index clusterisé. Les données stockées dans ses nœuds feuilles. contient uniquement les valeurs de la clé primaire et du champ nom.
Les règles de tri globales sont les mêmes que les règles de tri de l'index clusterisé selon la clé primaire, soit :
- nom dans la page de données du nœud feuille Les valeurs sont toutes triées
- La valeur du champ de nom dans la page de données suivante est > la valeur du champ de nom dans la page de données précédente
-
# 🎜🎜#
L'arbre d'index B+ du champ nom construira également une page d'index multi-niveaux. La page d'index stocke :
Numéro de page de niveau suivant# 🎜🎜#
- Valeur minimale du champ de nom, triée en fonction de la valeur du champ de nom.
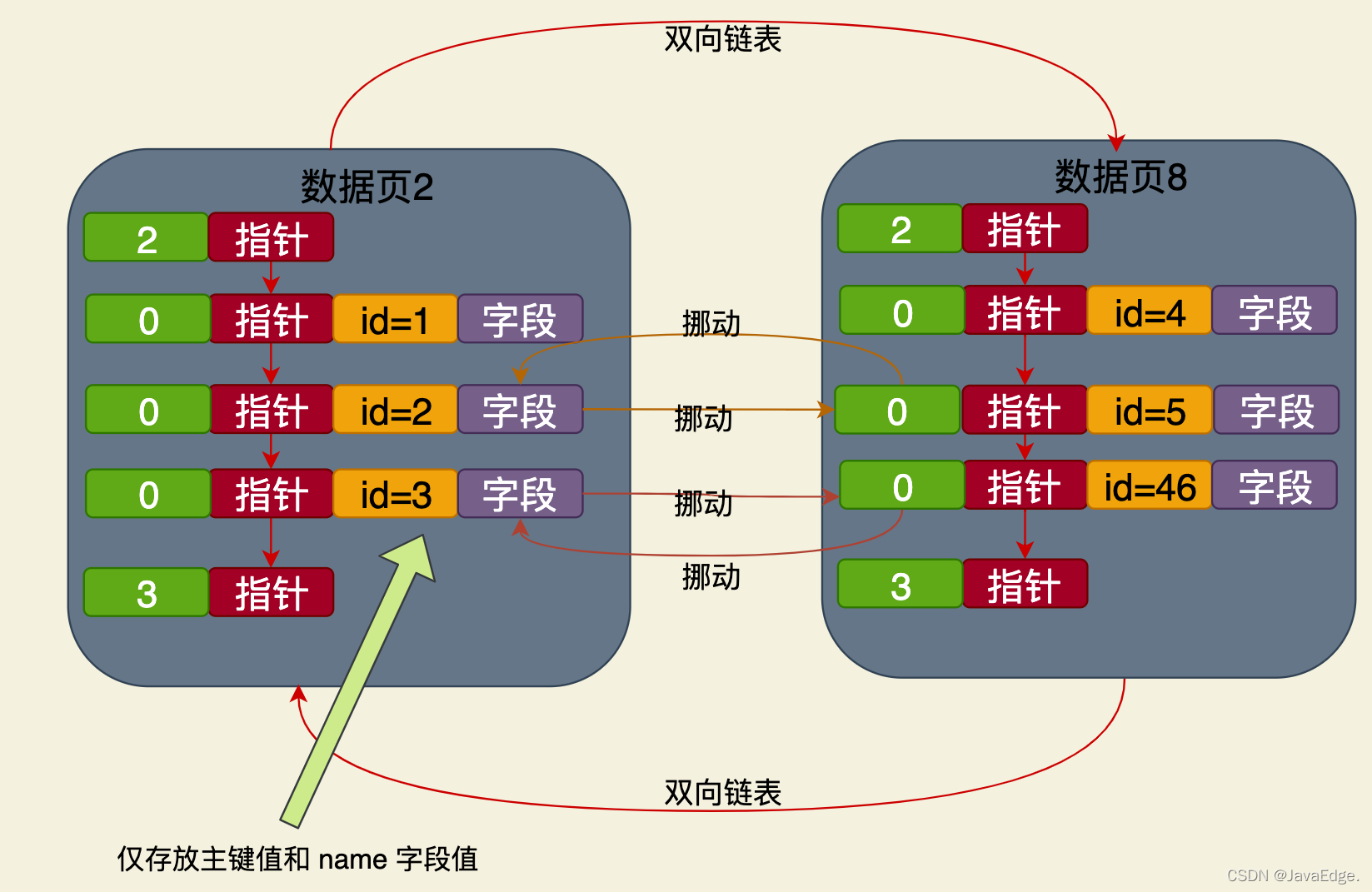
- Donc, si vous recherchez des données en fonction du champ de nom, le processus est le même. Commencez à partir du nœud racine de l'arborescence d'index de noms et effectuez une recherche couche par couche. jusqu'à ce que vous trouviez le nœud feuille. Sur la page de données, localisez la valeur de clé primaire correspondant à la valeur du champ de nom. Ensuite, pour des instructions telles que
select * from t where name='xx', recherchez d'abord dans l'arborescence d'index de noms en fonction de la valeur du nom et recherchez le nœud feuille. Seule la valeur de clé primaire correspondante peut être trouvée. , mais ne peut pas être trouvé dans tous les champs de cette ligne de données. Nous devons donc encore renvoyer la table : nous devons accéder à l'index clusterisé à partir du nœud racine en fonction de la valeur de la clé primaire, trouver la page de données du nœud feuille et localiser le fichier complet ligne de données correspondant à la valeur de la clé primaire. Ce n'est qu'à ce stade que toutes les valeurs de champ
peuvent être supprimées.
Joint Index
Par exemple, nom+âge, le processus en cours est le même et un arbre B+ indépendant est établi après que la page de données du nœud feuille stocke l'identifiant. +nom+âge, la valeur par défaut est Trier par nom, le même nom est trié par âge, il en va de même pour le tri des valeurs nom+âge entre différentes pages de données. select *
- La valeur minimale du nom+âge
- Ainsi, lorsque vous effectuez une recherche en fonction du nom+âge, le nom sera utilisé + l'arborescence d'index conjointe âge, recherchera la clé primaire, puis recherchera dans l'index clusterisé en fonction de la clé primaire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!