
Maison >base de données >tutoriel mysql >Comment résoudre le problème de pagination profonde des requêtes SQL dans le réglage MySQL
Comment résoudre le problème de pagination profonde des requêtes SQL dans le réglage MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-27 09:58:371830parcourir
1. Introduction du problème
Par exemple, il existe actuellement une table test_user, puis insérez 3 millions de données dans cette table :
CREATE TABLE `test_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `user_id` varchar(36) NOT NULL COMMENT '用户id', `user_name` varchar(30) NOT NULL COMMENT '用户名称', `phone` varchar(20) NOT NULL COMMENT '手机号码', `lan_id` int(9) NOT NULL COMMENT '本地网', `region_id` int(9) NOT NULL COMMENT '区域', `create_time` datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`) ) ENGINE=InnoDB AUTO_INCREMENT;
Dans le processus de développement de bases de données, nous utilisons souvent la pagination. Début limite, compte L'instruction de pagination lit les données.
Regardons le temps d'exécution de la pagination à partir de 0, 10 000, 100 000, 500 000, 1000 000 et 1800 000 (100 éléments par page).
SELECT * FROM test_user LIMIT 0,100; # 0.031 SELECT * FROM test_user LIMIT 10000,100; # 0.047 SELECT * FROM test_user LIMIT 100000,100; # 0.109 SELECT * FROM test_user LIMIT 500000,100; # 0.219 SELECT * FROM test_user LIMIT 1000000,100; # 0.547s SELECT * FROM test_user LIMIT 1800000,100; # 1.625s
Nous avons vu qu'à mesure que le record de départ augmente, le temps augmente également. Après avoir modifié l'enregistrement de départ à 2,9 millions, nous pouvons voir qu'il existe une grande corrélation entre la limite et le numéro de page de départ dans l'instruction de pagination
SELECT * FROM test_user LIMIT 2900000,100; # 3.062s
Nous avons été surpris de constater que MySQL a un point de départ de pagination plus grand lorsque la quantité de les données sont volumineuses et la requête est plus lente !
Alors pourquoi la situation ci-dessus se produit-elle ?
Réponse : Parce que la syntaxe de limit 2900000,100 signifie en fait que MySQL analyse les 2900100 premiers éléments de données puis supprime les 3000000 premières lignes. Cette étape est en fait un gaspillage.
Nous pouvons également en conclure les deux choses suivantes :
Le temps d'interrogation de l'instruction limite est directement proportionnel à la position de l'enregistrement de départ.
L'instruction de limite de MySQL est très pratique, mais elle ne convient pas à une utilisation directe sur des tables comportant de nombreux enregistrements.
2. Utilisation de la limite dans MySQL
La clause limit peut être utilisée pour forcer l'instruction select à renvoyer un nombre spécifié d'enregistrements. Son format de syntaxe est le suivant :
SELECT * FROM 表名 limit m,n; SELECT * FROM table LIMIT [offset,] rows;
limit accepte un ou deux paramètres numériques, et le. Le paramètre doit être une constante entière, si deux paramètres sont donnés :
Le premier paramètre spécifie le décalage de la première ligne d'enregistrement renvoyée
Le deuxième paramètre spécifie le nombre maximum de lignes d'enregistrement renvoyées
2,1 m représente m+1 enregistrements. la ligne commence à être récupérée et n représente la récupération de n éléments de données. (m peut être défini sur 0)
SELECT * FROM 表名 limit 6,5;
Le SQL ci-dessus indique qu'à partir de la 7ème ligne d'enregistrement, 5 éléments de données sont supprimés
2.2 Il convient de noter que n peut être défini sur -1, lorsque n est -1 , indiquant que la récupération commence à partir de la ligne m+1 jusqu'à ce que les dernières données soient récupérées
SELECT * FROM 表名 limit 6,-1;
Le SQL ci-dessus indique que toutes les données après la 6ème ligne d'enregistrement sont récupérées
2.3 Si seulement m est donné, il signifie commencer à partir de la 1ère rangée d'enregistrement Commencez à compter et supprimez m rangées au total
SELECT * FROM 表名 limit 6;
2.4 Retirez les 3 premières rangées dans l'ordre inverse de l'âge
select * from student order by age desc limit 3;
2.5 Sautez les 3 premières rangées puis prenez les 2 suivantes rows
select * from student order by age desc limit 3,2;
3. Stratégie d'optimisation de pagination approfondie
Méthode 1 : Optimiser avec un identifiant de clé primaire ou un index unique
Trouvez d'abord l'identifiant maximum de la dernière pagination, puis utilisez l'index sur l'identifiant pour interroger :
SELECT * FROM test_user WHERE id>1000000 LIMIT 100; # 0.047秒
L'utilisation de ce SQL optimisé est déjà 11 fois plus rapide que la requête précédente. En plus d'utiliser l'ID de clé primaire, vous pouvez également utiliser un index unique pour localiser rapidement des données spécifiques, évitant ainsi une analyse complète de la table. Voici le code d'optimisation SQL correspondant pour lire les données avec des clés uniques (pk) comprises entre 1000 et 1019 :
SELECT * FROM 表名称 WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20
Raison : l'analyse de l'index sera très rapide.
Scénarios applicables : si la requête de données est triée par pk ou id et que toutes les données ne manquent pas, vous pouvez l'optimiser de cette manière, sinon l'opération de pagination entraînera une fuite de données.
Méthode 2 : Utiliser l'optimisation de la couverture d'index
Nous savons tous que si l'instruction qui utilise une requête d'index ne contient que cette colonne d'index (c'est-à-dire couverture d'index), alors la requête sera très rapide.
Pourquoi la requête de couverture d'index est-elle si rapide ?
Réponse : Comme il existe un algorithme d'optimisation pour la recherche d'index et que les données se trouvent sur l'index de requête, il n'est pas nécessaire de trouver l'adresse des données pertinente, ce qui permet de gagner beaucoup de temps. Lorsque le niveau de concurrence est élevé, Mysql fournit également un cache associé à l'index. Utiliser pleinement ce cache peut obtenir de meilleurs résultats.
Étant donné que le champ id est la clé primaire dans notre table de test test_user, l'index de clé primaire est inclus par défaut. Voyons maintenant comment fonctionne la requête utilisant l'index de couverture.
Cette fois, nous interrogeons les données des lignes 1000001 à 1000100 (en utilisant un index de couverture, incluant uniquement la colonne id) :
SELECT id FROM test_user LIMIT 1000000,100; # 0.843秒
À partir de ce résultat, nous avons constaté que la vitesse de requête est plus lente que l'analyse complète de la table (bien sûr, après avoir exécuté ce SQL à plusieurs reprises, après plusieurs requêtes, la vitesse est devenue beaucoup plus rapide, près de la moitié du temps est économisé, cela est dû à la mise en cache), puis utilisez la commande expliquer pour afficher le plan d'exécution du SQL et constatez que l'ordinaire index utilisé pour l'exécution SQL idx_user_id :
EXPLAIN SELECT id FROM test_user LIMIT 1000000,100;
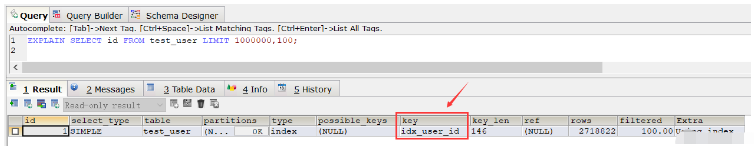
Si nous supprimons l'index normal, l'index de clé primaire sera utilisé lors de l'exécution du SQL ci-dessus. Si nous ne supprimons pas l'index ordinaire, dans ce cas, si nous voulons que le SQL ci-dessus utilise l'index de clé primaire, nous pouvons utiliser l'instruction order by :
SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100; # 0.250秒
Ensuite, si nous voulons également interroger toutes les colonnes, il y en a deux méthodes, l'une est id>=, l'autre consiste à utiliser join.
La première façon d'écrire :
SELECT * FROM test_user WHERE ID >= (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,1) LIMIT 100;
Le temps de requête SQL ci-dessus est de 0,281 seconde
La deuxième façon d'écrire :
SELECT * FROM (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100) a LEFT JOIN test_user b ON a.id = b.id;
Le temps de requête SQL ci-dessus est de 0,252 secondes
Méthode 3 : Réorganisation basée sur l'index
où pageNum représente le numéro de page, sa valeur commence à 0 ; pageSize indique le nombre de données par page.
SELECT * FROM 表名称 WHERE id_pk > (pageNum*pageSize) ORDER BY id_pk ASC LIMIT pageSize;
适应场景:
适用于数据量多的情况
最好ORDER BY后的列对象是主键或唯一索引
id数据没有缺失,可以作为序号使用
使用ORDER BY操作能利用索引被消除,但结果集是稳定的
原因:
索引扫描,速度会很快
但MySQL的排序操作,只有ASC没有DESC。在MySQL中,索引的存储顺序是升序ASC,没有降序DESC的索引。这就是为什么默认情况下,order by 是按照升序排序的原因
方法四:基于索引使用prepare
PREPARE预编译一个SQL语句,并为其分配一个名称 stmt_name,以便以后引用该语句,预编译好的语句用EXECUTE执行。
PREPARE stmt_name FROM 'SELECT * FROM test_user WHERE id > ? ORDER BY id ASC LIMIT ?'; SET @a = 1000000; SET @b = 100; EXECUTE stmt_name USING @a, @b;;

上述SQL查询时间为0.047秒。
对于定义好的PREPARE预编译语句,我们可以使用下述命令来释放该预编译语句:
DEALLOCATE PREPARE stmt_name;
原因:
索引扫描,速度会很快.
prepare语句又比一般的查询语句快一点。
方法五:利用"子查询+索引"快速定位数据
其中page表示页码,其取值从0开始;pagesize表示指的是每页多少条数据。
SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id DESC LIMIT ($page-1)*$pagesize ORDER BY id DESC LIMIT $pagesize);
方法六:利用复合索引进行优化
假设数据表 collect ( id, title ,info ,vtype) 就这4个字段,其中id是主键自增,title用定长,info用text, vtype是tinyint,vtype是一个普通索引。
现在往里面填充数据,填充10万条记录,数据库表占用硬1.6G。
select id,title from collect limit 1000,10;
执行上述SQL速度很快,基本上0.01秒就OK。
select id,title from collect limit 90000,10;
然后再执行上述SQL,就发现非常慢,基本上平均8~9秒完成。
这个时候如果我们执行下述,我们会发现速度又变的很快,0.04秒就OK。
select id from collect order by id limit 90000,10;
那么这个现象的原因是什么?
答案:因为用了id主键做索引, 这里实现了索引覆盖,当然快。
所以如果想一起查询其它列的话,可以按照索引覆盖进行优化,具体如下:
select id,title from collect where id >= (select id from collect order by id limit 90000,1) limit 10;
再看下面的语句,带上where 条件:
select id from collect where vtype=1 order by id limit 90000,10;
可以发现这个速度上也是很慢的,用了8~9秒!
这里有一个疑惑:vtype 做了索引了啊?怎么会慢呢?
vtype做了索引是不错,如果直接对vtype进行过滤:
select id from collect where vtype=1 limit 1000,10;
可以看到速度还是很快的,基本上0.05秒,如果从9万开始,那就是0.05*90=4.5秒的速度了。
其实加了 order by id 就不走索引,这样做还是全表扫描,解决的办法是:复合索引!
因此针对下述SQL深度分页优化时可以加一个search_index(vtype,id)复合索引:
select id from collect where vtype=1 order by id limit 90000,10;
综上:
在进行SQL查询深度分页优化时,如果对于有where条件,又想走索引用limit的,必须设计一个索引,将where放第一位,limit用到的主键放第二位,而且只能select 主键。
最后根据查询出的主键走一级索引找到对应的数据。
按这样的逻辑,百万级的limit 在0.0x秒就可以分完,完美解决了分页问题。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!