
Maison >base de données >tutoriel mysql >Comment implémenter la fonction de transmission de données incrémentielle en temps réel MySQL basée sur Docker et Canal
Comment implémenter la fonction de transmission de données incrémentielle en temps réel MySQL basée sur Docker et Canal

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-26 20:28:311706parcourir
Introduction à canal
L'origine historique de canal
Au début, Alibaba a déployé des instances de base de données dans les salles informatiques de Hangzhou et des États-Unis. Cependant, en raison des besoins commerciaux de synchronisation des données entre les salles informatiques, Il était difficile de concevoir et de créer Canal, principalement basé sur la méthode de déclenchement (déclencheur) pour obtenir des changements progressifs. À partir de 2010, Alibaba a commencé à essayer progressivement l'analyse des journaux de base de données pour obtenir des données progressivement modifiées à des fins de synchronisation, ce qui a entraîné une augmentation des abonnements et de la consommation.
Les versions actuelles de la source de données MySQL prises en charge par canal incluent : 5.1.x, 5.5.x, 5.6.x, 5.7.x, 8.0.x.
Scénarios d'application de canal
Actuellement, les entreprises basées sur l'abonnement et la consommation incrémentielles de journaux comprennent principalement :
Basé sur l'analyse incrémentielle des journaux de base de données, fournissant un abonnement et une consommation de données incrémentielles
Base de données miroir de base de données Sauvegarde en temps réel
Construction d'index et maintenance en temps réel (index hétérogène divisé, index inversé, etc.)
Actualisation du cache métier
Traitement incrémentiel des données avec logique métier
Comment fonctionne le canal
Avant d'introduire le principe de canal, comprenons d'abord le principe de la réplication maître-esclave mysql.
Principe de réplication maître-esclave de MySQL
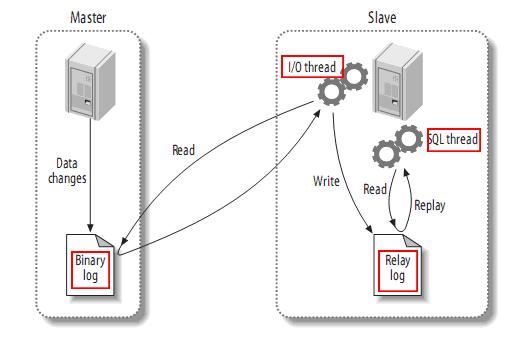
mysql master écrit les opérations de modification de données dans le journal binaire. Le contenu enregistré est appelé événements de journal binaire, qui peuvent être effectués via la commande show binlog events View
. l'esclave mysql copiera les événements du journal binaire dans le journal binaire du maître dans son journal de relais
l'esclave mysql relit et exécute les événements dans le journal de relais, mappant les modifications de données sur les siennes Dans la table de base de données
En comprenant le principe de fonctionnement de MySQL, nous pouvons à peu près deviner que Canal devrait également utiliser une logique similaire pour implémenter la fonction d'abonnement incrémentiel aux données, puis regardons comment fonctionne réellement Canal ?
principe de fonctionnement du canal
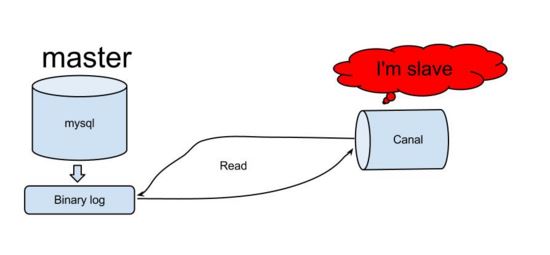
canal simule le protocole d'interaction de l'esclave mysql, se déguise en esclave mysql et envoie le protocole de vidage au maître mysql
le maître mysql reçoit la demande de vidage et commence à pousser le binaire log to Slave (également connu sous le nom de canal)
canal analyse les objets de journal binaire (les données sont un flux d'octets)
Basé sur ce principe et cette méthode, il peut compléter l'acquisition et l'analyse des journaux incrémentiels de la base de données et fournir des abonnement et consommation de données, réaliser la fonction de transmission de données incrémentielle en temps réel mysql.
Puisque canal est un tel framework et est écrit en langage Java pur, nous commencerons alors à apprendre à l'utiliser et à l'appliquer à notre travail réel.
Préparation de l'environnement Docker de Canal
En raison de la popularité actuelle de la technologie de conteneurisation, cet article utilise Docker pour créer rapidement un environnement de développement. Quant à la méthode traditionnelle de création d'environnement, après avoir appris à créer un environnement de conteneur Docker, nous pouvons également nous y fier nous-mêmes. La louche peinte en gourde a été construite avec succès. Étant donné que cet article explique principalement le canal, il ne couvrira pas grand-chose de Docker. Il présentera principalement les concepts de base et l'utilisation des commandes de Docker. Si vous souhaitez communiquer avec davantage d'experts en technologie de conteneurs, vous pouvez m'ajouter sur WeChat liyingjiese et remarquer « Ajouter un groupe ». Le groupe présente chaque semaine les meilleures pratiques des grandes entreprises du monde entier et les dernières tendances du secteur.
Qu'est-ce que Docker
Je crois que la plupart des gens ont utilisé la machine virtuelle VMware Lorsque vous utilisez VMware pour créer l'environnement, il vous suffit de fournir une image système ordinaire et de l'installer avec succès, ainsi que l'environnement logiciel et les applications restants. La configuration est toujours effectuée dans la machine virtuelle comme nous le faisons sur la machine locale, et VMware occupe beaucoup de ressources de l'hôte, ce qui peut facilement provoquer le gel de l'hôte, et l'image système elle-même prend également trop de place.
Afin de permettre à tout le monde de comprendre rapidement Docker, comparons-le avec VMware pour l'introduction. Docker fournit une plate-forme pour démarrer, empaqueter et exécuter des applications, qui isole l'application (application) de l'infrastructure sous-jacente (infrastructure). . Les deux concepts les plus importants dans Docker sont les images (similaires aux images système dans VMware) et les conteneurs (similaires aux systèmes installés dans VMware).
Qu'est-ce qu'une image (miroir)
Une collection de fichiers et de métadonnées (système de fichiers racine)
-
Elle est superposée et chaque couche peut ajouter, modifier et supprimer des fichiers pour devenir une nouvelle image
Différentes images peuvent partager le même calque
L'image elle-même est en lecture seule

Qu'est-ce qu'un conteneur ?
Créé (copie) par image
Établissez une couche conteneur (lisible et inscriptible) au-dessus de la couche image
Analogie orientée objet : classes et instances
image est responsable du stockage et de la distribution de l'application, et le conteneur est responsable du fonctionnement de l'application
Présentation du réseau Docker
Docker a trois types de réseau :
bridge : réseau de ponts. Par défaut, les conteneurs Docker ont commencé à utiliser Bridge, un réseau de ponts créé lors de l'installation du Docker. Chaque fois que le conteneur Docker est redémarré, l'adresse IP correspondante sera obtenue dans l'ordre. Cela entraînera une modification de l'adresse IP du Docker après le redémarrage.
aucun : Aucun réseau spécifié. En utilisant --network=none, le conteneur Docker n'attribuera pas d'adresse IP LAN.
host : Réseau hôte. Si --network=host est utilisé, le conteneur Docker partagera le réseau avec l'hôte et les deux pourront communiquer entre eux. Lors de l'exécution d'un service Web écoutant sur le port 8080 dans un conteneur, le conteneur est automatiquement mappé au port 8080 de l'hôte.
Créer un réseau personnalisé : (définir une adresse IP fixe)
docker network create --subnet=172.18.0.0/16 mynetwork
Afficher le réseau docker de type réseau existant ls :

Créer un environnement de canal
L'adresse de téléchargement et d'installation du docker est ci-jointe ==> ; téléchargement du menu fixe.
Télécharger l'image du canal docker pull canal/canal-server : docker pull canal/canal-server:
下载mysql镜像docker pull mysql,下载过的则如下图:

查看已经下载好的镜像docker images:

接下来通过镜像生成mysql容器与canal-server容器:
##生成mysql容器 docker run -d --name mysql --net mynetwork --ip 172.18.0.6 -p 3306:3306 -e mysql_root_password=root mysql ##生成canal-server容器 docker run -d --name canal-server --net mynetwork --ip 172.18.0.4 -p 11111:11111 canal/canal-server ## 命令介绍 --net mynetwork #使用自定义网络 --ip #指定分配ip
查看docker中运行的容器docker ps:

mysql的配置修改
以上只是初步准备好了基础的环境,但是怎么让canal伪装成salve并正确获取mysql中的binary log呢?
对于自建mysql,需要先开启binlog写入功能,配置binlog-format为row模式,通过修改mysql配置文件来开启bin_log,使用find / -name my.cnf查找my.cnf,修改文件内容如下:
[mysqld] log-bin=mysql-bin # 开启binlog binlog-format=row # 选择row模式 server_id=1 # 配置mysql replaction需要定义,不要和canal的slaveid重复
进入mysql容器docker exec -it mysql bash。
创建链接mysql的账号canal并授予作为mysql slave的权限,如果已有账户可直接grant:
mysql -uroot -proot # 创建账号 create user canal identified by 'canal'; # 授予权限 grant select, replication slave, replication client on *.* to 'canal'@'%'; -- grant all privileges on *.* to 'canal'@'%' ; # 刷新并应用 flush privileges;
数据库重启后,简单测试 my.cnf 配置是否生效:
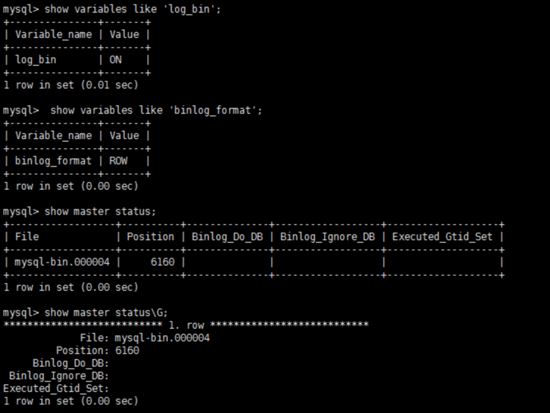
show variables like 'log_bin'; show variables like 'log_bin'; show master status;
canal-server的配置修改
进入canal-server容器docker exec -it canal-server bash。
编辑canal-server的配置vi canal-server/conf/example/instance.properties:

更多配置请参考==>canal配置说明 。
重启canal-server容器docker restart canal-server

 Téléchargez l'image mysql
Téléchargez l'image mysql docker pull mysql, celle téléchargée est comme indiqué ci-dessous :
Voir les images téléchargées du Docker miroir :
Ensuite, générez le conteneur mysql et le conteneur canal-server via le miroir :
docker exec -it canal-server bash tail -100f canal-server/logs/example/example.log
Affichez le conteneur exécuté dans docker docker ps : 

mysql modification de la configuration
Ce qui précède n'est qu'une préparation préliminaire de l'environnement de base, mais comment faire en sorte que le canal se déguise en baume et obtenir correctement le journal binaire dans MySQL ? Pour MySQL auto-construit, vous devez d'abord activer la fonction d'écriture binlog, configurerbinlog-format en mode ligne, activer bin_log en modifiant le fichier de configuration mysql et utiliser find / - nommez my.cnf Trouvez my.cnf et modifiez le contenu du fichier comme suit : # 下载对镜像 docker pull elasticsearch:7.1.1 docker pull mobz/elasticsearch-head:5-alpine # 创建容器并运行 docker run -d --name elasticsearch --net mynetwork --ip 172.18.0.2 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.1.1 docker run -d --name elasticsearch-head --net mynetwork --ip 172.18.0.5 -p 9100:9100 mobz/elasticsearch-head:5-alpineEntrez le conteneur mysql
docker exec -it mysql bash. Créez un canal de compte lié à mysql et accordez la permission d'être un esclave mysql. Si vous avez déjà un compte, vous pouvez directement accorder : 🎜package com.example.canal.study.pojo;
import lombok.data;
import java.io.serializable;
// @data 用户生产getter、setter方法
@data
public class student implements serializable {
private string id;
private string name;
private int age;
private string sex;
private string city;
}🎜Après le redémarrage de la base de données, testez simplement si le my. La configuration cnf prend effet : 🎜🎜🎜package com.example.canal.study.common;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.client.canalconnectors;
import org.apache.http.httphost;
import org.elasticsearch.client.restclient;
import org.elasticsearch.client.resthighlevelclient;
import org.springframework.beans.factory.annotation.value;
import org.springframework.context.annotation.bean;
import org.springframework.context.annotation.configuration;
import java.net.inetsocketaddress;
/**
* @author haha
*/
@configuration
public class canalconfig {
// @value 获取 application.properties配置中端内容
@value("${canal.server.ip}")
private string canalip;
@value("${canal.server.port}")
private integer canalport;
@value("${canal.destination}")
private string destination;
@value("${elasticsearch.server.ip}")
private string elasticsearchip;
@value("${elasticsearch.server.port}")
private integer elasticsearchport;
@value("${zookeeper.server.ip}")
private string zkserverip;
// 获取简单canal-server连接
@bean
public canalconnector canalsimpleconnector() {
canalconnector canalconnector = canalconnectors.newsingleconnector(new inetsocketaddress(canalip, canalport), destination, "", "");
return canalconnector;
}
// 通过连接zookeeper获取canal-server连接
@bean
public canalconnector canalhaconnector() {
canalconnector canalconnector = canalconnectors.newclusterconnector(zkserverip, destination, "", "");
return canalconnector;
}
// elasticsearch 7.x客户端
@bean
public resthighlevelclient resthighlevelclient() {
resthighlevelclient client = new resthighlevelclient(
restclient.builder(new httphost(elasticsearchip, elasticsearchport))
);
return client;
}
}🎜🎜canal- Modifier la configuration du serveur 🎜🎜🎜 dans le conteneur canal-server docker exec -it canal-server bash. 🎜🎜Modifier la configuration canal-server vi canal-server/conf/example/instance.properties : 🎜🎜 🎜🎜Pour plus de configuration, veuillez vous référer aux instructions de configuration ==>canal
🎜🎜Pour plus de configuration, veuillez vous référer aux instructions de configuration ==>canal. 🎜🎜Redémarrez le conteneur canal-server docker restart canal-server Entrez dans le conteneur pour afficher le journal de démarrage : 🎜public static class twotuple<a, b> {
public final a eventtype;
public final b columnmap;
public twotuple(a a, b b) {
eventtype = a;
columnmap = b;
}
}
public static list<twotuple<eventtype, map>> printentry(list<entry> entrys) {
list<twotuple<eventtype, map>> rows = new arraylist<>();
for (entry entry : entrys) {
// binlog event的事件事件
long executetime = entry.getheader().getexecutetime();
// 当前应用获取到该binlog锁延迟的时间
long delaytime = system.currenttimemillis() - executetime;
date date = new date(entry.getheader().getexecutetime());
simpledateformat simpledateformat = new simpledateformat("yyyy-mm-dd hh:mm:ss");
// 当前的entry(binary log event)的条目类型属于事务
if (entry.getentrytype() == entrytype.transactionbegin || entry.getentrytype() == entrytype.transactionend) {
if (entry.getentrytype() == entrytype.transactionbegin) {
transactionbegin begin = null;
try {
begin = transactionbegin.parsefrom(entry.getstorevalue());
} catch (invalidprotocolbufferexception e) {
throw new runtimeexception("parse event has an error , data:" + entry.tostring(), e);
}
// 打印事务头信息,执行的线程id,事务耗时
logger.info(transaction_format,
new object[]{entry.getheader().getlogfilename(),
string.valueof(entry.getheader().getlogfileoffset()),
string.valueof(entry.getheader().getexecutetime()),
simpledateformat.format(date),
entry.getheader().getgtid(),
string.valueof(delaytime)});
logger.info(" begin ----> thread id: {}", begin.getthreadid());
printxainfo(begin.getpropslist());
} else if (entry.getentrytype() == entrytype.transactionend) {
transactionend end = null;
try {
end = transactionend.parsefrom(entry.getstorevalue());
} catch (invalidprotocolbufferexception e) {
throw new runtimeexception("parse event has an error , data:" + entry.tostring(), e);
}
// 打印事务提交信息,事务id
logger.info("----------------\n");
logger.info(" end ----> transaction id: {}", end.gettransactionid());
printxainfo(end.getpropslist());
logger.info(transaction_format,
new object[]{entry.getheader().getlogfilename(),
string.valueof(entry.getheader().getlogfileoffset()),
string.valueof(entry.getheader().getexecutetime()), simpledateformat.format(date),
entry.getheader().getgtid(), string.valueof(delaytime)});
}
continue;
}
// 当前entry(binary log event)的条目类型属于原始数据
if (entry.getentrytype() == entrytype.rowdata) {
rowchange rowchage = null;
try {
// 获取储存的内容
rowchage = rowchange.parsefrom(entry.getstorevalue());
} catch (exception e) {
throw new runtimeexception("parse event has an error , data:" + entry.tostring(), e);
}
// 获取当前内容的事件类型
eventtype eventtype = rowchage.geteventtype();
logger.info(row_format,
new object[]{entry.getheader().getlogfilename(),
string.valueof(entry.getheader().getlogfileoffset()), entry.getheader().getschemaname(),
entry.getheader().gettablename(), eventtype,
string.valueof(entry.getheader().getexecutetime()), simpledateformat.format(date),
entry.getheader().getgtid(), string.valueof(delaytime)});
// 事件类型是query或数据定义语言ddl直接打印sql语句,跳出继续下一次循环
if (eventtype == eventtype.query || rowchage.getisddl()) {
logger.info(" sql ----> " + rowchage.getsql() + sep);
continue;
}
printxainfo(rowchage.getpropslist());
// 循环当前内容条目的具体数据
for (rowdata rowdata : rowchage.getrowdataslist()) {
list<canalentry.column> columns;
// 事件类型是delete返回删除前的列内容,否则返回改变后列的内容
if (eventtype == canalentry.eventtype.delete) {
columns = rowdata.getbeforecolumnslist();
} else {
columns = rowdata.getaftercolumnslist();
}
hashmap<string, object> map = new hashmap<>(16);
// 循环把列的name与value放入map中
for (column column: columns){
map.put(column.getname(), column.getvalue());
}
rows.add(new twotuple<>(eventtype, map));
}
}
}
return rows;
}🎜🎜🎜🎜À ce stade, notre travail sur l'environnement est prêt ! 🎜🎜Récupérez les données et enregistrez-les de manière synchrone dans elasticsearch🎜🎜L'elasticsearch de cet article est également construit sur la base de l'environnement docker, afin que le lecteur puisse exécuter la commande suivante : 🎜package com.example.canal.study.common;
import com.alibaba.fastjson.json;
import com.example.canal.study.pojo.student;
import lombok.extern.slf4j.slf4j;
import org.elasticsearch.client.resthighlevelclient;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.stereotype.component;
import org.elasticsearch.action.docwriterequest;
import org.elasticsearch.action.delete.deleterequest;
import org.elasticsearch.action.delete.deleteresponse;
import org.elasticsearch.action.get.getrequest;
import org.elasticsearch.action.get.getresponse;
import org.elasticsearch.action.index.indexrequest;
import org.elasticsearch.action.index.indexresponse;
import org.elasticsearch.action.update.updaterequest;
import org.elasticsearch.action.update.updateresponse;
import org.elasticsearch.client.requestoptions;
import org.elasticsearch.common.xcontent.xcontenttype;
import java.io.ioexception;
import java.util.map;
/**
* @author haha
*/
@slf4j
@component
public class elasticutils {
@autowired
private resthighlevelclient resthighlevelclient;
/**
* 新增
* @param student
* @param index 索引
*/
public void savees(student student, string index) {
indexrequest indexrequest = new indexrequest(index)
.id(student.getid())
.source(json.tojsonstring(student), xcontenttype.json)
.optype(docwriterequest.optype.create);
try {
indexresponse response = resthighlevelclient.index(indexrequest, requestoptions.default);
log.info("保存数据至elasticsearch成功:{}", response.getid());
} catch (ioexception e) {
log.error("保存数据至elasticsearch失败: {}", e);
}
}
/**
* 查看
* @param index 索引
* @param id _id
* @throws ioexception
*/
public void getes(string index, string id) throws ioexception {
getrequest getrequest = new getrequest(index, id);
getresponse response = resthighlevelclient.get(getrequest, requestoptions.default);
map<string, object> fields = response.getsource();
for (map.entry<string, object> entry : fields.entryset()) {
system.out.println(entry.getkey() + ":" + entry.getvalue());
}
}
/**
* 更新
* @param student
* @param index 索引
* @throws ioexception
*/
public void updatees(student student, string index) throws ioexception {
updaterequest updaterequest = new updaterequest(index, student.getid());
updaterequest.upsert(json.tojsonstring(student), xcontenttype.json);
updateresponse response = resthighlevelclient.update(updaterequest, requestoptions.default);
log.info("更新数据至elasticsearch成功:{}", response.getid());
}
/**
* 根据id删除数据
* @param index 索引
* @param id _id
* @throws ioexception
*/
public void deletees(string index, string id) throws ioexception {
deleterequest deleterequest = new deleterequest(index, id);
deleteresponse response = resthighlevelclient.delete(deleterequest, requestoptions.default);
log.info("删除数据至elasticsearch成功:{}", response.getid());
}
}🎜L'environnement est prêt, nous allons maintenant commencer notre codage partie pratique, comment passer L'application obtient les données binlog analysées par canal. Tout d’abord, nous construisons une application de démonstration de canal basée sur Spring Boot. La structure est comme le montre la figure ci-dessous : 🎜🎜🎜🎜🎜student.java🎜package com.example.canal.study.action;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.protocol.canalentry;
import com.alibaba.otter.canal.protocol.message;
import com.example.canal.study.common.canaldataparser;
import com.example.canal.study.common.elasticutils;
import com.example.canal.study.pojo.student;
import lombok.extern.slf4j.slf4j;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.beans.factory.annotation.qualifier;
import org.springframework.stereotype.component;
import java.io.ioexception;
import java.util.list;
import java.util.map;
/**
* @author haha
*/
@slf4j
@component
public class binlogelasticsearch {
@autowired
private canalconnector canalsimpleconnector;
@autowired
private elasticutils elasticutils;
//@qualifier("canalhaconnector")使用名为canalhaconnector的bean
@autowired
@qualifier("canalhaconnector")
private canalconnector canalhaconnector;
public void binlogtoelasticsearch() throws ioexception {
opencanalconnector(canalhaconnector);
// 轮询拉取数据
integer batchsize = 5 * 1024;
while (true) {
message message = canalhaconnector.getwithoutack(batchsize);
// message message = canalsimpleconnector.getwithoutack(batchsize);
long id = message.getid();
int size = message.getentries().size();
log.info("当前监控到binlog消息数量{}", size);
if (id == -1 || size == 0) {
try {
// 等待2秒
thread.sleep(2000);
} catch (interruptedexception e) {
e.printstacktrace();
}
} else {
//1. 解析message对象
list<canalentry.entry> entries = message.getentries();
list<canaldataparser.twotuple<canalentry.eventtype, map>> rows = canaldataparser.printentry(entries);
for (canaldataparser.twotuple<canalentry.eventtype, map> tuple : rows) {
if(tuple.eventtype == canalentry.eventtype.insert) {
student student = createstudent(tuple);
// 2。将解析出的对象同步到elasticsearch中
elasticutils.savees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.update){
student student = createstudent(tuple);
elasticutils.updatees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.delete){
elasticutils.deletees("student_index", tuple.columnmap.get("id").tostring());
canalhaconnector.ack(id);
}
}
}
}
}
/**
* 封装数据至student
* @param tuple
* @return
*/
private student createstudent(canaldataparser.twotuple<canalentry.eventtype, map> tuple){
student student = new student();
student.setid(tuple.columnmap.get("id").tostring());
student.setage(integer.parseint(tuple.columnmap.get("age").tostring()));
student.setname(tuple.columnmap.get("name").tostring());
student.setsex(tuple.columnmap.get("sex").tostring());
student.setcity(tuple.columnmap.get("city").tostring());
return student;
}
/**
* 打开canal连接
*
* @param canalconnector
*/
private void opencanalconnector(canalconnector canalconnector) {
//连接canalserver
canalconnector.connect();
// 订阅destination
canalconnector.subscribe();
}
/**
* 关闭canal连接
*
* @param canalconnector
*/
private void closecanalconnector(canalconnector canalconnector) {
//关闭连接canalserver
canalconnector.disconnect();
// 注销订阅destination
canalconnector.unsubscribe();
}
}🎜canalconfig.java🎜package com.example.canal.study;
import com.example.canal.study.action.binlogelasticsearch;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.boot.applicationarguments;
import org.springframework.boot.applicationrunner;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
/**
* @author haha
*/
@springbootapplication
public class canaldemoapplication implements applicationrunner {
@autowired
private binlogelasticsearch binlogelasticsearch;
public static void main(string[] args) {
springapplication.run(canaldemoapplication.class, args);
}
// 程序启动则执行run方法
@override
public void run(applicationarguments args) throws exception {
binlogelasticsearch.binlogtoelasticsearch();
}
}🎜canaldataparser.java🎜🎜Comme cette classe contient beaucoup de code, les parties les plus importantes sont extraites de l'article. . D'autres parties du code peuvent être obtenues à partir de Get it on github : 🎜server.port=8081 spring.application.name = canal-demo canal.server.ip = 192.168.124.5 canal.server.port = 11111 canal.destination = example zookeeper.server.ip = 192.168.124.5:2181 zookeeper.sasl.client = false elasticsearch.server.ip = 192.168.124.5 elasticsearch.server.port = 9200🎜elasticutils.java🎜
docker pull zookeeper docker run -d --name zookeeper --net mynetwork --ip 172.18.0.3 -p 2181:2181 zookeeper docker run -d --name canal-server2 --net mynetwork --ip 172.18.0.8 -p 11113:11113 canal/canal-server🎜binlogelasticsearch.java🎜.
package com.example.canal.study.action;
import com.alibaba.otter.canal.client.canalconnector;
import com.alibaba.otter.canal.protocol.canalentry;
import com.alibaba.otter.canal.protocol.message;
import com.example.canal.study.common.canaldataparser;
import com.example.canal.study.common.elasticutils;
import com.example.canal.study.pojo.student;
import lombok.extern.slf4j.slf4j;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.beans.factory.annotation.qualifier;
import org.springframework.stereotype.component;
import java.io.ioexception;
import java.util.list;
import java.util.map;
/**
* @author haha
*/
@slf4j
@component
public class binlogelasticsearch {
@autowired
private canalconnector canalsimpleconnector;
@autowired
private elasticutils elasticutils;
//@qualifier("canalhaconnector")使用名为canalhaconnector的bean
@autowired
@qualifier("canalhaconnector")
private canalconnector canalhaconnector;
public void binlogtoelasticsearch() throws ioexception {
opencanalconnector(canalhaconnector);
// 轮询拉取数据
integer batchsize = 5 * 1024;
while (true) {
message message = canalhaconnector.getwithoutack(batchsize);
// message message = canalsimpleconnector.getwithoutack(batchsize);
long id = message.getid();
int size = message.getentries().size();
log.info("当前监控到binlog消息数量{}", size);
if (id == -1 || size == 0) {
try {
// 等待2秒
thread.sleep(2000);
} catch (interruptedexception e) {
e.printstacktrace();
}
} else {
//1. 解析message对象
list<canalentry.entry> entries = message.getentries();
list<canaldataparser.twotuple<canalentry.eventtype, map>> rows = canaldataparser.printentry(entries);
for (canaldataparser.twotuple<canalentry.eventtype, map> tuple : rows) {
if(tuple.eventtype == canalentry.eventtype.insert) {
student student = createstudent(tuple);
// 2。将解析出的对象同步到elasticsearch中
elasticutils.savees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.update){
student student = createstudent(tuple);
elasticutils.updatees(student, "student_index");
// 3.消息确认已处理
// canalsimpleconnector.ack(id);
canalhaconnector.ack(id);
}
if(tuple.eventtype == canalentry.eventtype.delete){
elasticutils.deletees("student_index", tuple.columnmap.get("id").tostring());
canalhaconnector.ack(id);
}
}
}
}
}
/**
* 封装数据至student
* @param tuple
* @return
*/
private student createstudent(canaldataparser.twotuple<canalentry.eventtype, map> tuple){
student student = new student();
student.setid(tuple.columnmap.get("id").tostring());
student.setage(integer.parseint(tuple.columnmap.get("age").tostring()));
student.setname(tuple.columnmap.get("name").tostring());
student.setsex(tuple.columnmap.get("sex").tostring());
student.setcity(tuple.columnmap.get("city").tostring());
return student;
}
/**
* 打开canal连接
*
* @param canalconnector
*/
private void opencanalconnector(canalconnector canalconnector) {
//连接canalserver
canalconnector.connect();
// 订阅destination
canalconnector.subscribe();
}
/**
* 关闭canal连接
*
* @param canalconnector
*/
private void closecanalconnector(canalconnector canalconnector) {
//关闭连接canalserver
canalconnector.disconnect();
// 注销订阅destination
canalconnector.unsubscribe();
}
}canaldemoapplication.java(spring boot启动类)
package com.example.canal.study;
import com.example.canal.study.action.binlogelasticsearch;
import org.springframework.beans.factory.annotation.autowired;
import org.springframework.boot.applicationarguments;
import org.springframework.boot.applicationrunner;
import org.springframework.boot.springapplication;
import org.springframework.boot.autoconfigure.springbootapplication;
/**
* @author haha
*/
@springbootapplication
public class canaldemoapplication implements applicationrunner {
@autowired
private binlogelasticsearch binlogelasticsearch;
public static void main(string[] args) {
springapplication.run(canaldemoapplication.class, args);
}
// 程序启动则执行run方法
@override
public void run(applicationarguments args) throws exception {
binlogelasticsearch.binlogtoelasticsearch();
}
}application.properties
server.port=8081 spring.application.name = canal-demo canal.server.ip = 192.168.124.5 canal.server.port = 11111 canal.destination = example zookeeper.server.ip = 192.168.124.5:2181 zookeeper.sasl.client = false elasticsearch.server.ip = 192.168.124.5 elasticsearch.server.port = 9200
canal集群高可用的搭建
通过上面的学习,我们知道了单机直连方式的canala应用。在当今互联网时代,单实例模式逐渐被集群高可用模式取代,那么canala的多实例集群方式如何搭建呢!
基于zookeeper获取canal实例
准备zookeeper的docker镜像与容器:
docker pull zookeeper docker run -d --name zookeeper --net mynetwork --ip 172.18.0.3 -p 2181:2181 zookeeper docker run -d --name canal-server2 --net mynetwork --ip 172.18.0.8 -p 11113:11113 canal/canal-server
1、机器准备:
运行canal的容器ip: 172.18.0.4 , 172.18.0.8
zookeeper容器ip:172.18.0.3:2181
mysql容器ip:172.18.0.6:3306
2、按照部署和配置,在单台机器上各自完成配置,演示时instance name为example。
3、修改canal.properties,加上zookeeper配置并修改canal端口:
canal.port=11113 canal.zkservers=172.18.0.3:2181 canal.instance.global.spring.xml = classpath:spring/default-instance.xml
4、创建example目录,并修改instance.properties:
canal.instance.mysql.slaveid = 1235 #之前的canal slaveid是1234,保证slaveid不重复即可 canal.instance.master.address = 172.18.0.6:3306
注意: 两台机器上的instance目录的名字需要保证完全一致,ha模式是依赖于instance name进行管理,同时必须都选择default-instance.xml配置。
启动两个不同容器的canal,启动后,可以通过tail -100f logs/example/example.log查看启动日志,只会看到一台机器上出现了启动成功的日志。
比如我这里启动成功的是 172.18.0.4:
查看一下zookeeper中的节点信息,也可以知道当前工作的节点为172.18.0.4:11111:
[zk: localhost:2181(connected) 15] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.4:11111","cid":1}客户端链接, 消费数据
可以通过指定zookeeper地址和canal的instance name,canal client会自动从zookeeper中的running节点获取当前服务的工作节点,然后与其建立链接:
[zk: localhost:2181(connected) 0] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.4:11111","cid":1}对应的客户端编码可以使用如下形式,上文中的canalconfig.java中的canalhaconnector就是一个ha连接:
canalconnector connector = canalconnectors.newclusterconnector("172.18.0.3:2181", "example", "", "");链接成功后,canal server会记录当前正在工作的canal client信息,比如客户端ip,链接的端口信息等(聪明的你,应该也可以发现,canal client也可以支持ha功能):
[zk: localhost:2181(connected) 4] get /otter/canal/destinations/example/1001/running
{"active":true,"address":"192.168.124.5:59887","clientid":1001}数据消费成功后,canal server会在zookeeper中记录下当前最后一次消费成功的binlog位点(下次你重启client时,会从这最后一个位点继续进行消费):
[zk: localhost:2181(connected) 5] get /otter/canal/destinations/example/1001/cursor
{"@type":"com.alibaba.otter.canal.protocol.position.logposition","identity":{"slaveid":-1,"sourceaddress":{"address":"mysql.mynetwork","port":3306}},"postion":{"included":false,"journalname":"binlog.000004","position":2169,"timestamp":1562672817000}}停止正在工作的172.18.0.4的canal server:
docker exec -it canal-server bash cd canal-server/bin sh stop.sh
这时172.18.0.8会立马启动example instance,提供新的数据服务:
[zk: localhost:2181(connected) 19] get /otter/canal/destinations/example/running
{"active":true,"address":"172.18.0.8:11111","cid":1}与此同时,客户端也会随着canal server的切换,通过获取zookeeper中的最新地址,与新的canal server建立链接,继续消费数据,整个过程自动完成。
异常与总结
elasticsearch-head无法访问elasticsearch
es与es-head是两个独立的进程,当es-head访问es服务时,会存在一个跨域问题。所以我们需要修改es的配置文件,增加一些配置项来解决这个问题,如下:
[root@localhost /usr/local/elasticsearch-head-master]# cd ../elasticsearch-5.5.2/config/ [root@localhost /usr/local/elasticsearch-5.5.2/config]# vim elasticsearch.yml # 文件末尾加上如下配置 http.cors.enabled: true http.cors.allow-origin: "*"
修改完配置文件后需重启es服务。
elasticsearch-head查询报406 not acceptable
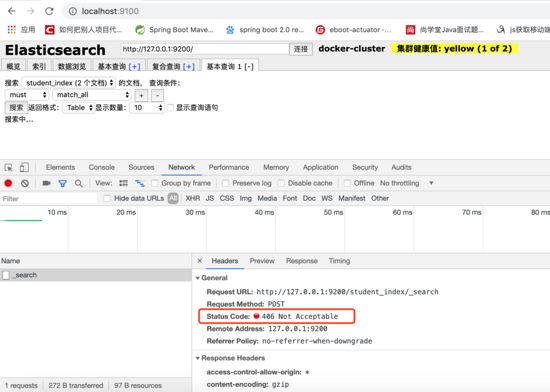
解决方法:
1、进入head安装目录;
2、cd _site/
3、编辑vendor.js 共有两处
#6886行 contenttype: "application/x-www-form-urlencoded 改成 contenttype: "application/json;charset=utf-8" #7574行 var inspectdata = s.contenttype === "application/x-www-form-urlencoded" && 改成 var inspectdata = s.contenttype === "application/json;charset=utf-8" &&
使用elasticsearch-rest-high-level-client报org.elasticsearch.action.index.indexrequest.ifseqno
#pom中除了加入依赖 <dependency> <groupid>org.elasticsearch.client</groupid> <artifactid>elasticsearch-rest-high-level-client</artifactid> <version>7.1.1</version> </dependency> #还需加入 <dependency> <groupid>org.elasticsearch</groupid> <artifactid>elasticsearch</artifactid> <version>7.1.1</version> </dependency>
相关参考: 。
为什么elasticsearch要在7.x版本不能使用type?
参考: 为什么elasticsearch要在7.x版本去掉type?
使用spring-data-elasticsearch.jar报org.elasticsearch.client.transport.nonodeavailableexception
由于本文使用的是elasticsearch7.x以上的版本,目前spring-data-elasticsearch底层采用es官方transportclient,而es官方计划放弃transportclient,工具以es官方推荐的resthighlevelclient进行调用请求。 可参考 resthighlevelclient api 。
设置docker容器开启启动
如果创建时未指定 --restart=always ,可通过update 命令 docker update --restart=always [containerid]
docker for mac network host模式不生效
host模式是为了性能,但是这却对docker的隔离性造成了破坏,导致安全性降低。 在性能场景下,可以用--netwokr host开启host模式,但需要注意的是,如果你用windows或mac本地启动容器的话,会遇到host模式失效的问题。原因是host模式只支持linux宿主机。
参见官方文档: 。
客户端连接zookeeper报authenticate using sasl(unknow error)

zookeeper.jar est incohérent avec la version de zookeeper dans dokcer
zookeeper.jar utilise une version antérieure à 3.4.6
Cette erreur signifie que zookeeper doit demander des ressources au système en tant que application externe, vous devez passer l'authentification lors de la demande de ressources, et sasl est une méthode d'authentification. Nous voulons trouver un moyen de contourner l'authentification sasl. Évitez d’attendre et améliorez l’efficacité.
Ajoutez system.setproperty("zookeeper.sasl.client", "false"); au code du projet. S'il s'agit d'un projet Spring Boot, il peut être dans application.properties Ajoutez zookeeper.sasl.client=false. system.setproperty("zookeeper.sasl.client", "false");,如果是spring boot项目可以在application.properties中加入zookeeper.sasl.client=false。
参考: increased cpu usage by unnecessary sasl checks 。
如果更换canal.client.jar中依赖的zookeeper.jar的版本
把canal的官方源码下载到本机git clone ,然后修改client模块下pom.xml文件中关于zookeeper的内容,然后重新mvn install:
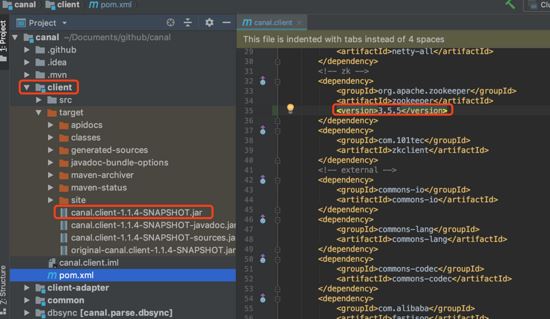
把自己项目依赖的包替换为刚刚mvn install
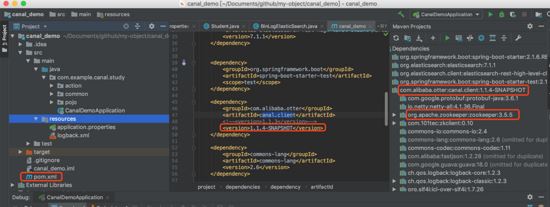 Si vous changez la version de zookeeper.jar dont dépend canal.client.jar
Si vous changez la version de zookeeper.jar dont dépend canal.client.jar
🎜🎜Remplacez le package dont dépend votre projet par le package qui vient d'être produit par mvn install : 🎜🎜🎜🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!