
Maison >développement back-end >Tutoriel Python >Comment implémenter un algorithme de classification d'arbre de décision en python
Comment implémenter un algorithme de classification d'arbre de décision en python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-26 19:43:461362parcourir
Pré-information
1. Arbre de décision
Phrase réécrite : Dans l'apprentissage supervisé, un algorithme de classification couramment utilisé est l'arbre de décision, qui est basé sur un lot d'échantillons, chaque échantillon contient un ensemble d'attributs et les résultats de classification correspondants. En utilisant ces échantillons à des fins d'apprentissage, l'algorithme peut générer un arbre de décision capable de classer correctement les nouvelles données
2. Exemples de données
Supposons qu'il y ait 14 utilisateurs existants, leurs attributs personnels et leurs données sur l'achat ou non d'un certain produit. Comme suit :
| Numéro | Âge | Fourchette de revenus | Nature de l'emploi | Note de crédit | Décision d'achat | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 01 | Élevé | Instable | Pauvre Non | InstablePauvre | |||||||||
| 04 | >40 | Moyen | Instable | Pauvre | |||||||||
| 05 | &g t;40 | Faible | Stable | pire | |||||||||
| 06 | >40 | Faible | Stable | Bonne | |||||||||
| 07 | 30-40 | Faible | Stable | Bien | |||||||||
| 08 | Moyen | Instable | Faible | ||||||||||
| Pauvre | Oui | 10 | >40 | Modéré | |||||||||
| Faible | Oui | 11 | Moyen | ||||||||||
| Bon | Oui | 12 | 30-40 | Moyen | |||||||||
| Bon | Oui | 13 | 30-40 | Élevé | |||||||||
| Faible | Oui | 14 | >40 | Moyen | |||||||||
| Bon | Non |
| Âge | Gamme de revenus | Nature du travail | Note de crédit |
|---|---|---|---|
| faible | stable | bonne | |
| élevée | instable | bonne |
def classify(inputtree,featlabels,testvec): firststr = list(inputtree.keys())[0] seconddict = inputtree[firststr] featindex = featlabels.index(firststr) for key in seconddict.keys(): if testvec[featindex]==key: if type(seconddict[key]).__name__=='dict': classlabel=classify(seconddict[key],featlabels,testvec) else: classlabel=seconddict[key] return classlabellabels=['age','income','job','credit'] tsvec=[0,0,1,1] print('result:',classify(Tree,labels,tsvec)) tsvec1=[0,2,0,1] print('result1:',classify(Tree,labels,tsvec1))
résultat : N
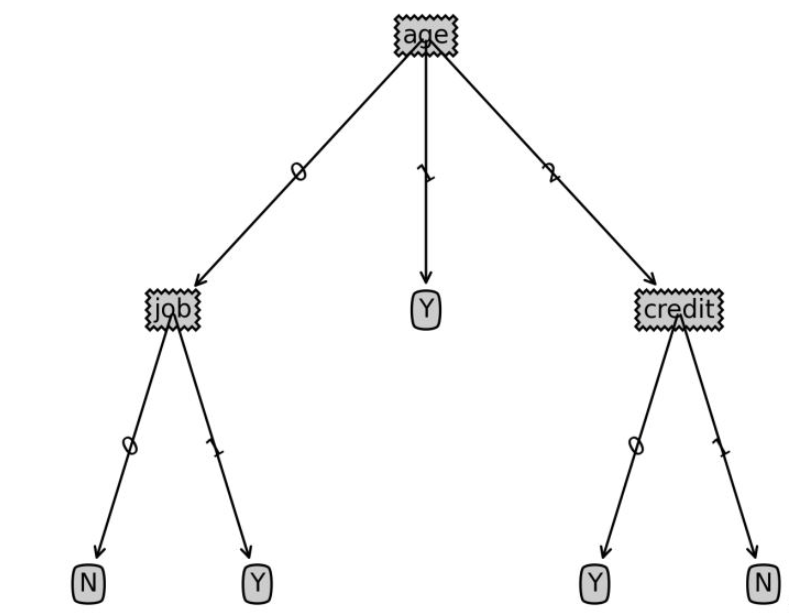
post-information : tirage des décisions Code d'arbre
Le code suivant est utilisé pour dessiner des graphiques d'arbre de décision, et non l'objectif de l'algorithme d'arbre de décision. Si vous êtes intéressé, vous pouvez vous y référer pour référence
import matplotlib.pyplot as plt
decisionNode = dict(box, fc="0.8")
leafNode = dict(box, fc="0.8")
arrow_args = dict(arrow)
#获取叶节点的数目
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#测试节点的数据是否为字典,以此判断是否为叶节点
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
#获取树的层数
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#测试节点的数据是否为字典,以此判断是否为叶节点
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
#绘制节点
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args )
#绘制连接线
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
#绘制树结构
def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #this determines the x width of this tree
depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key],cntrPt,str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#创建决策树图形
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks
#createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '')
plt.savefig('决策树.png',dpi=300,bbox_inches='tight')
plt.show().Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!