
Maison >base de données >Redis >Comment réaliser l'identification et l'échange de données chaudes et froides dans Redis
Comment réaliser l'identification et l'échange de données chaudes et froides dans Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-26 17:23:03984parcourir
Background
Le produit de stockage hybride Redis est un produit de stockage hybride développé indépendamment par Alibaba Cloud qui est entièrement compatible avec le protocole et les fonctionnalités Redis.
En stockant une partie des données froides sur le disque, cela réduit considérablement les coûts d'utilisation et dépasse la limite de mémoire sur le volume de données d'une instance unique Redis tout en garantissant que la plupart des performances d'accès ne diminuent pas.
Parmi elles, l'identification et l'échange de données chaudes et froides sont des facteurs clés dans la performance des produits de stockage hybrides.
Définition des données chaudes et froides
Dans le stockage hybride Redis, le rapport mémoire/disque est librement sélectionnable par l'utilisateur :
#🎜🎜 # 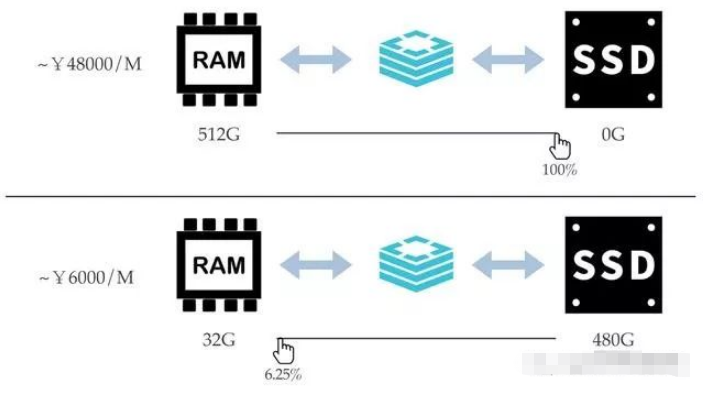
- # 🎜🎜#Key est consulté beaucoup plus fréquemment que Value.
- En tant que base de données KV, les demandes d'accès normales doivent d'abord rechercher la clé pour confirmer si la clé existe. Pour confirmer qu'une clé n'existe pas, vous devez. vérifiez toutes les clés sous une forme ou une autre. Une collection de clés. Conserver toutes les valeurs clés des structures de données en mémoire peut garantir que la vitesse de recherche est exactement la même que celle des structures de données en mémoire pure.
- Le ratio de taille de clé est très faible.
- Dans un modèle économique général, même s'il s'agit d'un type de chaîne ordinaire, sa valeur est généralement plusieurs fois supérieure à la clé. Pour les objets de collection tels que Set, List, Hash, etc., la valeur composée de tous les membres additionnés est plusieurs ordres de grandeur supérieure à la clé.
- Par conséquent, il existe deux principaux scénarios applicables pour les instances de stockage hybride Redis :
- Aucun accès aux données de manière uniforme , il y a des points chauds
- La mémoire n'est pas suffisante pour stocker toutes les données, et la valeur est grande (par rapport à la clé)
- #🎜🎜 ##🎜 🎜#
Identification des données chaudes et froides
Lorsque la mémoire est insuffisante, l'instance calculera le poids de la valeur en fonction de l'heure d'accès récente, de la fréquence d'accès, de la taille de la valeur et d'autres dimensions et attribuer le poids le plus bas. La valeur est stockée sur le disque et supprimée de la mémoire.
Le pseudo code est le suivant :
Dans le cas le plus idéal, on aimerait pouvoir calculer avec précision la valeur la plus basse actuelle. Cependant, le degré chaud et froid d'une valeur change dynamiquement en fonction de la situation d'accès, et le temps nécessaire pour recalculer les poids chauds et froids de toutes les valeurs à chaque fois est totalement inacceptable. Lorsque la mémoire est pleine, Redis lui-même éliminera les données selon la stratégie d'élimination définie par l'utilisateur, et l'écriture de données chaudes de la mémoire sur le disque peut également être considérée comme un processus « d'élimination ». Compte tenu des performances, de la précision et de la compréhension de l'utilisateur, nous utilisons des méthodes de calcul approximatives similaires à celles de Redis pour identifier les données chaudes et froides. Nous prenons en charge plusieurs stratégies et réduisons la consommation de processeur et de mémoire en échantillonnant de manière aléatoire une petite partie des données et en utilisant l'échantillonnage via le pool d'expulsion. .Informations historiques pour aider à améliorer la précision.
Lorsque la mémoire est pleine, Redis lui-même éliminera les données selon la stratégie d'élimination définie par l'utilisateur, et l'écriture de données chaudes de la mémoire sur le disque peut également être considérée comme un processus « d'élimination ». Compte tenu des performances, de la précision et de la compréhension de l'utilisateur, nous utilisons des méthodes de calcul approximatives similaires à celles de Redis pour identifier les données chaudes et froides. Nous prenons en charge plusieurs stratégies et réduisons la consommation de processeur et de mémoire en échantillonnant de manière aléatoire une petite partie des données et en utilisant l'échantillonnage via le pool d'expulsion. .Informations historiques pour aider à améliorer la précision.
Le diagramme schématique du taux de réussite de l'algorithme d'élimination approximative de Redis est présenté sous différentes versions et configurations avec différents nombres d'échantillons d'échantillonnage. Les points de données qui ont été éliminés sont en gris clair, les points de données qui n'ont pas été éliminés sont en gris et les points de données ajoutés pendant le test sont en vert.
Échange de données chaudes et froides
Le processus d'échange de données chaudes et froides de stockage mixte Redis est terminé dans le thread IO en arrière-plan.
Hot data->cold dataMéthode asynchrone :
Lorsque la mémoire est proche de la valeur maximale, le thread principal génère une série de tâches d'échange de données ;
Le thread d'arrière-plan exécute ces tâches d'échange de données et informe le thread principal après l'achèvement ; # 🎜🎜#
- Le thread principal met à jour et libère la valeur dans la mémoire, et met à jour la valeur dans le dictionnaire de données dans la mémoire en une simple méta-information ; 🎜🎜#
#🎜🎜 #
Méthode de synchronisation : - Lorsque le trafic d'écriture est trop important, la méthode asynchrone ne peut pas échanger les données dans le temps, ce qui peut amener la mémoire à dépasser la spécification maximale. Le thread principal exécutera directement la tâche d'échange de données pour atteindre l'objectif de limitation de courant déguisé.
Cold data->Hot data
Avant d'exécuter la commande, le thread principal détermine d'abord si les valeurs impliquées dans la commande sont en mémoire ;
Sinon, générez une tâche de chargement de données, suspendez la client et principal Le thread continue de traiter les autres demandes du client ;- Le thread d'arrière-plan effectue la tâche de chargement des données et informe le thread principal une fois terminé ; 🎜🎜#
- Le thread principal met à jour la valeur dans le dictionnaire de données en mémoire, réveille le client précédemment suspendu et traite sa demande.
- Méthode de synchronisation :
- Dans le script Lua, lors de la phase spécifique d'exécution de la commande, si une valeur se trouve stocké dans Sur le disque, le thread principal effectuera directement la tâche de chargement des données, garantissant que la sémantique des scripts et des commandes Lua reste inchangée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!