
Maison >Périphériques technologiques >IA >AI Morning Post | Quelle est l'expérience de la génération mutuelle de texte, d'image, d'audio, de vidéo et de 3D ?
AI Morning Post | Quelle est l'expérience de la génération mutuelle de texte, d'image, d'audio, de vidéo et de 3D ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-26 14:29:081665parcourir

Le 9 mai, heure locale, Meta a annoncé l'open source d'un nouveau modèle d'IA ImageBind qui peut couvrir 6 modalités différentes, notamment la vision (formes d'image et vidéo), la température (image infrarouge), le texte, l'audio et la profondeur. Informations, mouvement lectures (produites par une centrale inertielle ou IMU). Actuellement, le code source correspondant est hébergé sur GitHub.
Que signifie couvrir 6 modes ?
ImageBind prend la vision comme élément central et peut librement comprendre et convertir entre 6 modes. Meta a montré certains cas, comme entendre un chien aboyer et dessiner un chien, et donner en même temps la carte de profondeur correspondante et la description textuelle, comme saisir une image d'un oiseau + le bruit des vagues de l'océan et obtenir une image de ; un oiseau sur la plage.
Comparé aux générateurs d'images comme Midjourney, Stable Diffusion et DALL-E 2 qui associent du texte à des images, ImageBind ressemble davantage à un large réseau et peut connecter du texte, des images/vidéos, de l'audio, des mesures 3D (profondeur), des données de température (chaleur ) et les données de mouvement (de l'IMU), et il prédit directement les connexions entre les données sans formation préalable à chaque possibilité, de la même manière que les humains perçoivent ou imaginent leur environnement.

Les chercheurs affirment qu'ImageBind peut être initialisé à l'aide de modèles de langage visuel à grande échelle (tels que CLIP), exploitant ainsi les riches représentations d'images et de texte de ces modèles. Par conséquent, ImageBind peut être adapté à différentes modalités et tâches avec très peu de formation.
ImageBind fait partie de l'engagement de Meta à créer des systèmes d'IA multimodaux qui apprennent de tous les types de données pertinents. À mesure que le nombre de modalités augmente, ImageBind ouvre les vannes aux chercheurs pour tenter de développer de nouveaux systèmes holistiques, tels que la combinaison de capteurs 3D et IMU pour concevoir ou expérimenter des mondes virtuels immersifs. Il offre également un moyen riche d'explorer votre mémoire en utilisant une combinaison de texte, de vidéo et d'images pour rechercher des images, des vidéos, des fichiers audio ou des informations textuelles.
Ce modèle n'est actuellement qu'un projet de recherche et n'a pas d'application directe ni d'application pratique, mais il montre comment l'IA générative peut générer du contenu immersif et multisensoriel à l'avenir, et montre également que Meta travaille avec OpenAI, Google Wait pour que les concurrents adoptent des méthodes différentes et trouvent une voie qui appartient au grand modèle open source.
En fin de compte, Meta estime que la technologie ImageBind finira par transcender les six « sens » actuels, déclarant sur son blog : « Bien que nous ayons exploré six modes dans nos recherches actuelles, nous croyons en l'introduction d'une technologie qui connecte autant de sens que possible. – tels que le toucher, la parole, l’odorat et les signaux IRMf cérébraux – permettront des modèles d’IA plus riches centrés sur l’humain
.Objectif d'ImageBind
Si ChatGPT peut servir de moteur de recherche et de communauté de questions-réponses, et que Midjourney peut être utilisé comme outil de dessin, que pouvez-vous faire avec ImageBind ?
Selon la démo officielle, il peut générer de l'audio directement à partir d'images :
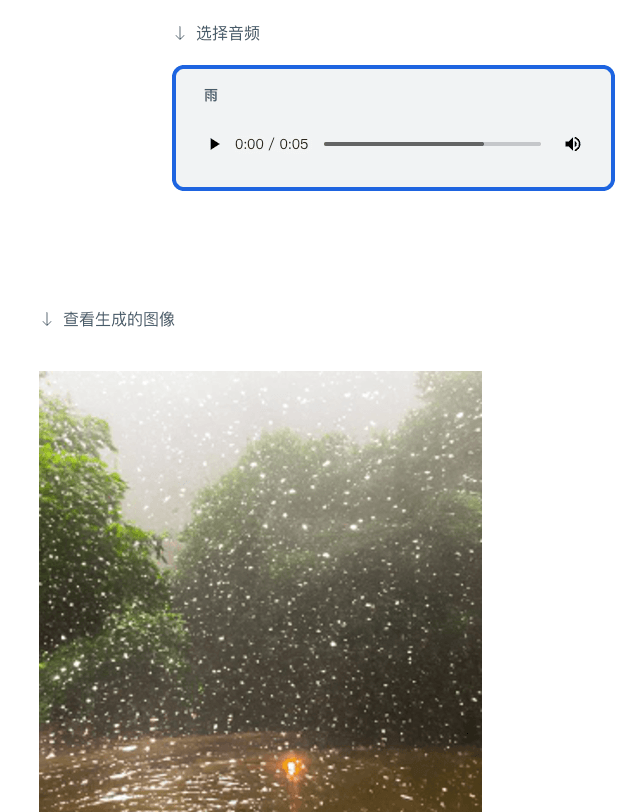
Vous pouvez également générer des images à partir de l'audio :
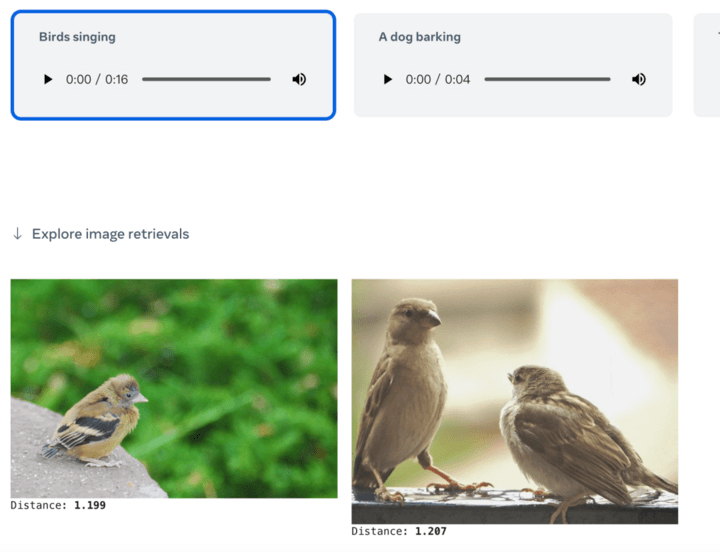
Ou donnez simplement un texte pour récupérer des images ou du contenu audio associé :
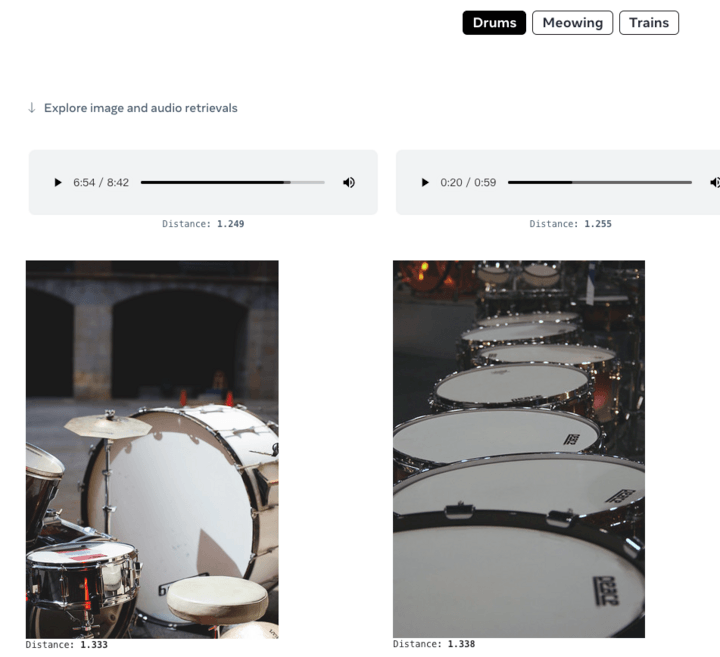
Vous pouvez également donner de l'audio et générer des images correspondantes :
Comme mentionné ci-dessus, ImageBind permet aux futurs systèmes d'IA générative d'être présentés sous plusieurs modalités, et en même temps, combinés avec la réalité virtuelle interne de Meta, la réalité mixte, le métaverse et d'autres technologies et scénarios. L'utilisation d'outils comme ImageBind ouvrira de nouvelles portes dans les espaces accessibles, par exemple en générant des descriptions multimédias en temps réel pour aider les personnes malvoyantes ou malentendantes à mieux percevoir leur environnement immédiat.
Il reste encore beaucoup à découvrir sur l’apprentissage multimodal. Actuellement, le domaine de l’intelligence artificielle n’a pas quantifié efficacement les comportements de mise à l’échelle qui n’apparaissent que dans des modèles plus grands ni compris leurs applications. ImageBind est une étape vers l'évaluation et la démonstration de nouvelles applications pour la génération et la récupération d'images de manière rigoureuse.
Auteur : Ballade
Source : Premier Réseau Électrique (www.d1ev.com)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI