
Maison >Java >javaDidacticiel >Quels sont le cadre de collecte et les algorithmes courants de la structure des données Java ?
Quels sont le cadre de collecte et les algorithmes courants de la structure des données Java ?

- 王林avant
- 2023-05-26 13:39:441184parcourir
1 Collection Framework
1.1 Collection Framework Concept
Java Collection FrameworkJava Collection Framework, également connu sous le nom de conteneur, il s'agit d'un ensemble d'interfaces et de ses classes d'implémentation définies dans le package java.util.
Sa principale performance est de placer plusieurs éléments dans une seule unité, qui est utilisée pour stocker, récupérer et gérer rapidement et facilement ces éléments, ce que nous appelons habituellement l'ajout, la suppression et la modification. .
Aperçu des classes et des interfaces :
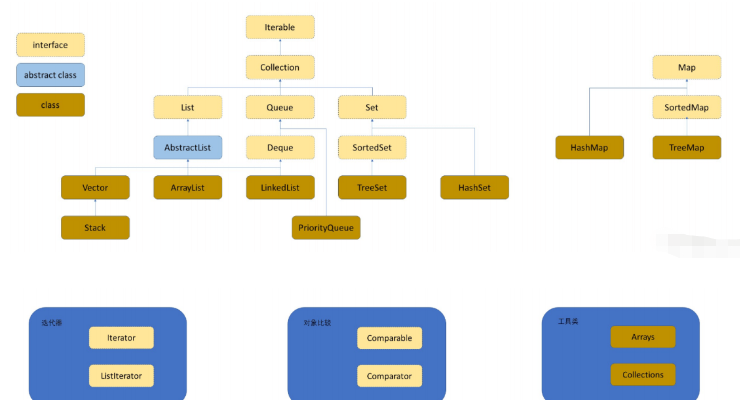
1.2 Structures de données impliquées dans le conteneur
Collection : Oui Une interface qui contient certaines méthodes couramment utilisées par la plupart des conteneurs
List : C'est une interface qui standardise les méthodes à implémenter dans ArrayList et LinkedList
- #🎜 🎜#ArrayList : implémente l'interface List, la couche inférieure est une liste de séquences de type dynamique
- LinkedList : implémente l'interface List, la couche inférieure est doublement liée list
#🎜 🎜#Deque : C'est une interface
Set : Set, c'est une interface, et le modèle K est placé à l'intérieur #🎜🎜 #
HashSet : La couche inférieure est le bucket Ha Hi, la complexité temporelle de la requête est O(1)- TreeSet : La couche inférieure est un arbre rouge-noir, la complexité temporelle de la requête est O(), à propos de la clé Séquentielle
- Map : cartographie, qui stocke le paires clé-valeur du modèle K-V
- #🎜 🎜#
TreeMap : La couche inférieure est un arbre rouge-noir et la complexité du temps de requête est O(), à propos de la clé ordonnée
- #🎜🎜 #2 Algorithme2.1 Concept d'algorithme
// 请计算一下func1基本操作执行了多少次?
void func1(int N){
int count = 0;
for (int i = 0; i < N ; i++) {
for (int j = 0; j < N ; j++) {
count++;
}
}
for (int k = 0; k < 2 * N ; k++) {
count++;
}
int M = 10;
while ((M--) > 0) {
count++;
}
System.out.println(count);
}
Func1 Le nombre d'opérations de base effectuées : F(N)=N^2+2*N+10# 🎜 🎜#
N = 10 F(N) = 130
- N = 100 F(N) = 10210
- # 🎜 🎜#N = 1000 F(N) = 1002010
- En fait, quand on calcule la complexité temporelle, on n'est pas forcément à calculons le nombre exact d'exécutions, mais seul le nombre approximatif d'exécutions est nécessaire, alors nous utilisons ici la représentation asymptotique du grand O.
- Notation Big O : C'est un symbole mathématique utilisé pour décrire le comportement asymptotique d'une fonction3.3 Dérivation de la méthode du Big O-order #🎜🎜 ## 🎜🎜#
- Si le terme d'ordre le plus élevé existe et n'est pas 1, supprimez la constante multipliée par ce terme. Le résultat est l’ordre Big O.
- Après avoir utilisé la représentation asymptotique de Big O, la complexité temporelle de Func1 est : O(n^2)
- N = 10 F(N) = 100
- N = 1000 F(N) = 1000000
- À travers le contenu ci-dessus, nous pouvons voir que l'exclusion de la notation asymptotique Big O a peu d'impact sur le éléments de résultats, exprimant ainsi de manière concise et claire le nombre d’exécutions. De plus, il existe le meilleur, la moyenne et le pire des cas pour la complexité temporelle de certains algorithmes : Pire des cas : le nombre maximum d'exécutions (limite supérieure) pour n'importe quelle taille d'entrée #🎜🎜 #Cas moyen : le nombre d'exécutions attendu pour n'importe quelle taille d'entrée
Meilleur cas : le nombre minimum d'exécutions (limite inférieure) pour n'importe quelle taille d'entrée
Par exemple : recherchez une donnée dans un tableau de longueur N x
Meilleur cas : 1 fois trouvé
Pire cas : N fois trouvé
平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)
4 空间复杂度
对于一个算法而言,空间复杂度表示它在执行期间所需的临时存储空间大小。空间复杂度的计算方式并非程序所占用的字节数量,因为这并没有太大的意义;实际上,空间复杂度的计算基于变量的数量。大O渐进表示法通常用来计算空间复杂度,其计算规则类似于实践复杂度的计算规则。
实例1:
// 计算bubbleSort的空间复杂度?
void bubbleSort(int[] array) {
for (int end = array.length; end > 0; end--) {
boolean sorted = true;
for (int i = 1; i < end; i++) {
if (array[i - 1] > array[i]) {
Swap(array, i - 1, i);
sorted = false;
}
}
if(sorted == true) {
break;
}
}
}实例2:
// 计算fibonacci的空间复杂度?
int[] fibonacci(int n) {
long[] fibArray = new long[n + 1];
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n ; i++) {
fibArray[i] = fibArray[i - 1] + fibArray [i - 2];
}
return fibArray;
}实例3:
// 计算阶乘递归Factorial的空间复杂度?
long factorial(int N) {
return N < 2 ? N : factorial(N-1)*N;
}实例1使用了常数个额外空间,所以空间复杂度为 O(1)
实例2动态开辟了N个空间,空间复杂度为 O(N)
实例3递归调用了N次,开辟了N个栈帧,每个栈帧使用了常数个空间。空间复杂度为O(N)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!