
Maison >base de données >tutoriel mysql >Quelle est la différence entre count(*), count(1) et count(col) dans MySQL ?
Quelle est la différence entre count(*), count(1) et count(col) dans MySQL ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-26 13:37:081792parcourir
count Fonction
COUNT(expression) : renvoie le nombre total d'enregistrements interrogés. Le paramètre d'expression est un champ ou un signe *.
Test
Version MySQL : 5.7.29
Créez une table utilisateur et insérez un million de données, dont un demi-million de lignes dans le champ sexe ont des valeurs nulles
CREATE TABLE `users` ( `Id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `name` varchar(32) DEFAULT NULL COMMENT '名称', `gender` varchar(20) DEFAULT NULL COMMENT '性别', `create_date` datetime DEFAULT NULL COMMENT '创建时间', PRIMARY KEY (`Id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='用户表';
count(*)
in Avant MySQL 5.7.18, InnoDB traitait les instructions en analysant l'index clusterisé. SELECT COUNT( *) À partir de MySQL 5.7.18, InnoDB gère les instructions SELECT COUNT( *) en parcourant le plus petit index secondaire disponible, à moins que l'index ou l'indice de l'optimiseur ne demande à l'optimiseur d'utiliser un index différent. Si l'index secondaire n'existe pas, l'index clusterisé est analysé.
Le sens général est que s'il existe un index secondaire, utilisez l'index secondaire. S'il y a plusieurs index secondaires, donnez la priorité au plus petit index secondaire pour réduire les coûts. S'il n'y a pas d'index secondaire, utilisez un index clusterisé.
Les tests suivants sont utilisés pour vérifier ces vues.
Tout d'abord, interrogez le plan d'exécution lorsqu'il n'y a que l'index de clé primaire d'Id

Vous pouvez voir que le type est index, ce qui signifie que l'index est utilisé, et la clé est PRIMARY, ce qui signifie. l'index de clé primaire est utilisé, key_len=8.
Deuxièmement, ajoutez un index au champ de nom et utilisez à nouveau le plan d'exécution pour afficher

Vous pouvez voir que l'index est également utilisé, mais l'index utilise l'index du champ de nom, key_len=99.
Ajoutez ensuite un index au champ create_date tout en conservant l'index du champ nom. Vérifiez à nouveau le plan d'exécution

Vous pouvez voir que cette fois l'index du champ create_date est utilisé, key_len=6.
Quel que soit l'index utilisé ci-dessus, le nombre total de lignes finalement interrogées est d'un million, qu'elles contiennent ou non des valeurs NULL.
count(1)
count(1) a les mêmes résultats de requête que count(*) et renvoie finalement un million de données, qu'elles contiennent ou non des valeurs NULL.
count(col)
count(col) compte la valeur d'une certaine colonne, qui est divisée en trois situations :
count(id) : compte l'identifiant
et count(*) Il en va de même pour l'exécution de la requête résultats, et renvoie finalement un million de données.
count(index col) : Statistiques des champs indexés
Requête avec count(name), le plan d'exécution est le suivant :

Vous pouvez voir que l'index le champ est utilisé pour les statistiques, index Également touché.
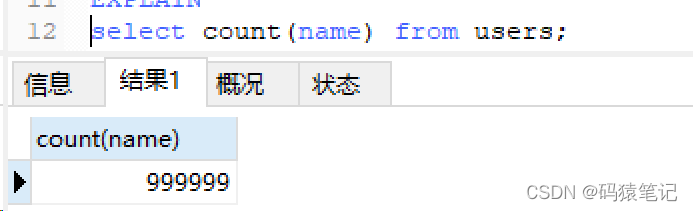
Définissez le champ de nom dans une colonne sur NULL, puis effectuez une requête de comptage, le résultat renvoie 999999
Définissez ensuite la valeur NULL de cette colonne sur une chaîne vide, puis effectuez une requête de comptage, le résultat renvoie 1000000
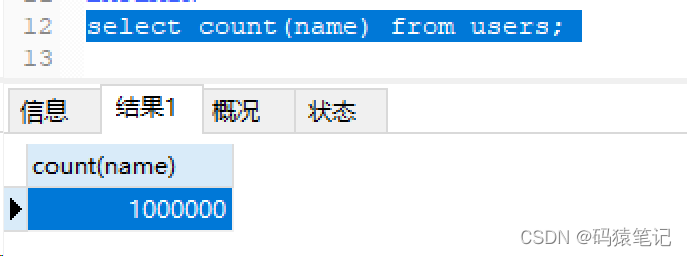
Par conséquent, en résumé, utiliser simplement le champ d'index pour compter le nombre de lignes peut atteindre l'index et ne compter que le nombre de lignes qui ne sont pas des valeurs NULL.
count(normal col) : Compter les champs sans index
Si vous comptez les champs sans index, l'index ne sera pas utilisé et seul le nombre de lignes qui ne sont pas des valeurs NULL sera compté.

Le compromis entre count(1) et count(*)
Je ne savais pas où je l'avais vu ou entendu auparavant Count(1) est plus efficace que count(*). perception erronée. Il existe une telle phrase sur le site officiel, InnoDB gère les opérations SELECT COUNT( *) et SELECT COUNT(1) de la même manière.
Traduit, InnoDB gère SELECT COUNT( *) et SELECT. de la même manière. COUNT(1), il n’y a aucune différence de performances.
Pour les tables MyISAM, COUNT(*) est optimisé pour revenir très rapidement en cas de récupération d'une table, aucune autre colonne n'est récupérée et il n'y a pas de clause. Cette optimisation s'applique uniquement aux tables MyISAM car le moteur de stockage stocke le nombre exact de lignes et. accès très rapide. COUNT(1) effectue la même optimisation uniquement si la première colonne est définie comme NOT NULL. ----Depuis le site officiel de MySQL
Ces optimisations sont basées sur le principe qu'il n'y a pas d'endroit et de regroupement.
Il est également mentionné dans les spécifications de développement d'Alibaba

Donc, si vous pouvez utiliser count(*) pendant le développement, utilisez simplement count(*).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!