
Maison >Périphériques technologiques >IA >Imitant le divin résumé de Jeff Dean, un ancien ingénieur de Google a partagé les « secrets de développement LLM » : des chiffres que tout développeur devrait connaître !
Imitant le divin résumé de Jeff Dean, un ancien ingénieur de Google a partagé les « secrets de développement LLM » : des chiffres que tout développeur devrait connaître !

- 王林avant
- 2023-05-25 22:25:291548parcourir
Récemment, un internaute a compilé une liste de « chiffres que tout développeur LLM devrait connaître » et a expliqué pourquoi ces chiffres sont importants et comment nous devrions les utiliser.
Quand il était chez Google, il existait un document compilé par le légendaire ingénieur Jeff Dean intitulé "Les chiffres que chaque ingénieur devrait connaître".

Jeff Dean : "Les chiffres que tout ingénieur devrait connaître"
Pour les développeurs LLM (Large Language Model), il existe un ensemble similaire d'estimations approximatives. Les nombres sont également très utiles.

Invite
40-90% : Économies de coûts après avoir ajouté "concis et concis" à l'invite
Vous devez savoir que vous êtes basé sur le jeton utilisé par LLM lors de la sortie Payé.
Cela signifie que vous pouvez économiser beaucoup d'argent en laissant votre modèle être concis.
En même temps, ce concept peut être étendu à davantage de lieux.
Par exemple, vous vouliez à l'origine utiliser GPT-4 pour générer 10 alternatives, mais vous pourrez maintenant lui demander d'en fournir 5 en premier, puis vous pourrez conserver l'autre moitié de l'argent.
1.3 : Le nombre moyen de jetons par mot
LLM fonctionne en unités de jetons.
Et un jeton est un mot ou une sous-partie d'un mot. Par exemple, « manger » peut être décomposé en deux jetons « manger » et « ing ».
D'une manière générale, 750 mots anglais généreront environ 1000 jetons.
Pour les langues autres que l'anglais, le nombre de jetons par mot sera augmenté, en fonction de leur point commun dans le corpus d'intégration de LLM.

Prix
Considérant que le coût d'utilisation du LLM est très élevé, les chiffres liés au prix deviennent particulièrement importants.
~50 : rapport de coût de GPT-4 par rapport à GPT-3.5 Turbo
L'utilisation de GPT-3.5-Turbo est environ 50 fois moins chère que GPT-4. Je dis « approximativement » car GPT-4 facture différemment les invites et la génération.
Donc, dans l'application réelle, il est préférable de confirmer si GPT-3.5-Turbo est suffisant pour répondre à vos besoins.
Par exemple, pour des tâches comme la synthèse, GPT-3.5-Turbo est plus que suffisant.


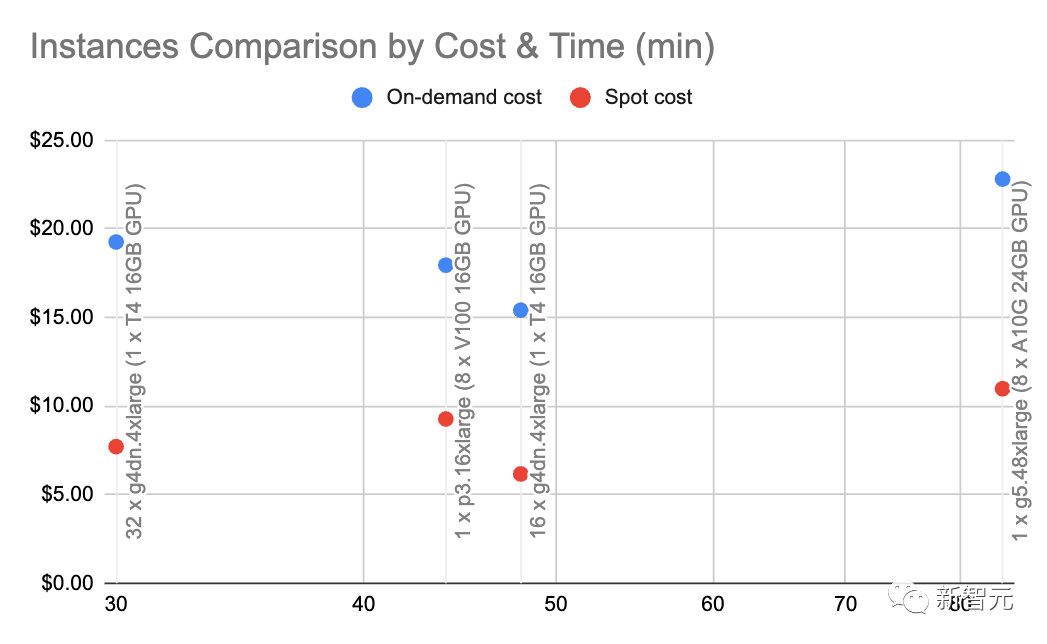
5 Il est beaucoup moins cher d'utiliser la génération LLM. Plus précisément, la recherche dans le système de recherche d'informations neuronales coûte environ 5 fois moins cher que de demander à GPT-3.5-Turbo. Par rapport à GPT-4, l’écart de coût peut atteindre 250 fois ! 10 : Ratio de coût de l'intégration OpenAI par rapport à l'intégration auto-hébergée REMARQUE : Ce nombre est très sensible à la charge et à la taille du lot intégré, veuillez donc le considérer comme une approximation. Avec g4dn.4xlarge (prix à la demande : 1,20 $/heure), nous pouvons exploiter SentenceTransformers avec HuggingFace (comparable aux intégrations d'OpenAI) pour que l'intégration se produise à un rythme d'environ 9 000 jetons par seconde. Effectuer quelques calculs de base à cette vitesse et à ce type de nœud montre que les intégrations auto-hébergées peuvent être 10 fois moins chères. 6 : Rapport de coût du modèle de base OpenAI et de la requête de modèle affinée Cela signifie également qu'il est plus rentable d'ajuster les pointes du modèle de base que d'affiner un modèle personnalisé.
1 : rapport de coût du modèle de base auto-hébergé par rapport aux requêtes de modèle affinées# 🎜🎜## 🎜🎜#Si vous hébergez vous-même le modèle, le coût du modèle affiné est quasiment le même que celui du modèle de base : le nombre de paramètres est le même pour les deux modèles. Formation et mise au point Adresse papier : https://arxiv.org/pdf/2302.13971.pdf #🎜 🎜#LLaMa a mentionné qu'il leur avait fallu 21 jours et utilisé 2048 GPU A100 de 80 Go pour entraîner le modèle LLaMa. En supposant que nous entraînons notre modèle sur l'ensemble d'entraînement Red Pyjama, en supposant que tout fonctionne bien, sans aucun plantage, et qu'il réussisse du premier coup, nous obtiendrons les chiffres ci-dessus . De plus, ce processus implique également une coordination entre 2048 GPU. La plupart des entreprises n'ont pas les conditions pour le faire. Cependant, le message le plus critique est le suivant : il est possible de former notre propre LLM, mais le processus n'est pas bon marché. Et à chaque exécution, cela prend plusieurs jours. En comparaison, utiliser un modèle pré-entraîné reviendra bien moins cher. <0,001 : Tarif pour la mise au point et la formation à partir de zéro # 🎜🎜#Ce chiffre est un peu général et, dans l'ensemble, le coût de la mise au point est négligeable. Même aux tarifs d'OpenAI pour son modèle affiné le plus cher, Davinci , et cela ne coûte que 3 cents pour 1 000 jetons. # 🎜🎜 #
~1 million de dollars : le coût de la formation d'un modèle de 13 milliards de paramètres sur 1,4 billion de jetons
Cependant, peaufiner est une chose, s'entraîner à partir de zéro en est une autre...
#🎜 🎜#GPU视频RAM#🎜 🎜#
Si vous auto-hébergez le modèle, il est très important de comprendre la mémoire GPU, car LLM pousse la mémoire GPU à ses limites.Les statistiques suivantes sont spécifiquement destinées à l'inférence. Si vous souhaitez effectuer un entraînement ou un réglage fin, vous avez besoin d'une certaine quantité de mémoire vidéo. V100 : 16 Go, A10G : 24 Go, A100 : 40/80 Go : capacité mémoire GPU Il est important de connaître la quantité de mémoire vidéo disponible sur les différents types de GPU, car cela limitera la quantité de paramètres que votre LLM peut avoir. De manière générale, nous aimons utiliser A10G car leur prix à la demande sur AWS est de 1,5 $ à 2 $ de l'heure et ils disposent de 24 Go de mémoire GPU. chaque A100 coûte environ 5 $/heure. 2x Taille du paramètre : exigences typiques en matière de mémoire GPU pour LLM Par exemple, lorsque vous disposez d’un modèle à 7 milliards de paramètres, vous avez besoin d’environ 14 Go de mémoire GPU. Cela est dû au fait que dans la plupart des cas, chaque paramètre nécessite un nombre à virgule flottante de 16 bits (ou 2 octets). Habituellement, vous n'avez pas besoin de plus de 16 bits de précision, mais la plupart du temps, lorsque la précision atteint 8 bits, la résolution commence à diminuer (dans certains cas, cela est également acceptable). Bien sûr, il y a aussi quelques projets qui ont amélioré cette situation. Par exemple, llama.cpp a exécuté un modèle de 13 milliards de paramètres en quantifiant à 4 bits sur un GPU de 6 Go (8 bits sont également disponibles), mais ce n'est pas courant. ~1 Go : exigences typiques en matière de mémoire GPU pour les modèles intégrés Chaque fois que vous intégrez des phrases (ce qui est souvent effectué pour des tâches de regroupement, de recherche sémantique et de classification), vous avez besoin d'un modèle d'intégration tel qu'un convertisseur de phrases. OpenAI possède également son propre modèle d'intégration commerciale. 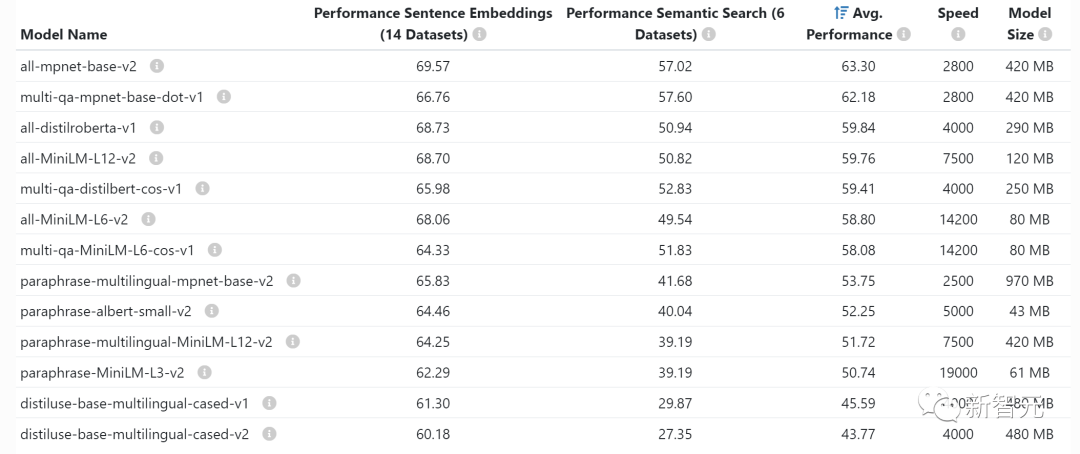
Habituellement, vous n'avez pas à vous soucier de la quantité de mémoire vidéo intégrée prennent le GPU, ils sont assez petits, il est même possible d'embarquer LLM sur le même GPU.
>10x : améliorez le débit en regroupant les requêtes LLM
# 🎜🎜# La latence d'exécution des requêtes LLM sur le GPU est très élevée : avec un débit de 0,2 requêtes par seconde, la latence peut prendre jusqu'à 5 secondes.Fait intéressant, si vous exécutez deux tâches, la latence peut n'être que de 5,2 secondes.
Cela signifie que si vous pouvez regrouper 25 requêtes ensemble, vous aurez besoin d'environ 10 secondes de latence, tandis que le débit a été augmenté à 2,5 requêtes par seconde.
Cependant, veuillez continuer à lire ci-dessous.
~1 Mo : mémoire GPU requise pour générer 1 jeton du modèle à 13 milliards de paramètres# 🎜🎜#La mémoire vidéo dont vous avez besoin est directement proportionnelle au nombre maximum de tokens que vous souhaitez générer.
Par exemple, générer une sortie allant jusqu'à 512 jetons (environ 380 mots) nécessite 512 Mo de mémoire vidéo.
Vous pourriez dire que ce n'est pas grave : j'ai 24 Go de mémoire vidéo, qu'est-ce que 512 Mo ? Cependant, si vous souhaitez exécuter des lots plus importants, ce nombre commence à s'additionner.
Par exemple, si vous souhaitez faire 16 batchs, la mémoire vidéo sera directement augmentée à 8Go.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI