
Maison >Périphériques technologiques >IA >Reproductible, automatisé, peu coûteux et de haut niveau d'évaluation, PandaLM, le premier grand modèle à évaluer automatiquement de grands modèles, est là
Reproductible, automatisé, peu coûteux et de haut niveau d'évaluation, PandaLM, le premier grand modèle à évaluer automatiquement de grands modèles, est là

- PHPzavant
- 2023-05-25 19:16:321868parcourir
Le développement des grands modèles peut être considéré comme rapide. Les méthodes de réglage fin des instructions ont poussé comme des champignons après la pluie. Un grand nombre de grands modèles dits de « remplacement » de ChatGPT ont été publiés les uns après les autres. Dans la formation et le développement d'applications de grands modèles, l'évaluation des capacités réelles de divers grands modèles tels que l'open source, le fermé et l'auto-recherche est devenue un maillon important dans l'amélioration de l'efficacité et de la qualité de la recherche et du développement.
Plus précisément, lors de la formation et de l'application de grands modèles, vous avez peut-être rencontré les problèmes suivants :
1. Différentes bases sont utilisées pour le réglage fin ou la pré-formation améliorée des grands modèles. . Selon les effets d'échantillon observés, les performances du modèle ont leurs propres avantages et inconvénients dans différents scénarios. Comment déterminer quel modèle utiliser dans les applications réelles ?
2. Utilisez ChatGPT pour évaluer la sortie du modèle, mais ChatGPT obtient des résultats d'évaluation différents pour la même entrée à des moments différents.
3. Utiliser l'annotation manuelle pour évaluer les résultats de la génération de modèles prend du temps et est laborieux. Comment accélérer le processus d'évaluation et réduire les coûts lorsque le budget est limité et que le temps presse ?
4. Lorsque vous traitez des données confidentielles, que ce soit en utilisant ChatGPT/GPT4 ou en étiquetant des entreprises pour l'évaluation de modèles, vous serez confronté à des problèmes de fuite de données.
Sur la base de ces questions, des chercheurs de l'Université de Pékin, de l'Université de West Lake et d'autres institutions ont proposé conjointement un nouveau paradigme d'évaluation de grands modèles - PandaLM. PandaLM effectue des tests et une vérification automatisés et reproductibles des capacités des grands modèles en entraînant un grand modèle spécifiquement pour l'évaluation. PandaLM, publié sur GitHub le 30 avril, est le premier grand modèle d'évaluation au monde. Des articles pertinents seront publiés dans un avenir proche.

Adresse GitHub : https://github.com/WeOpenML/PandaLM
PandaLM vise à faire apprendre au grand modèle la préférence humaine globale pour le texte généré par différents grands modèles grâce à la formation Et effectuez des évaluations relatives basées sur les préférences pour remplacer les méthodes d'évaluation manuelles ou basées sur des API afin de réduire les coûts et d'augmenter l'efficacité. Les pondérations de PandaLM sont entièrement divulguées et peuvent être exécutées sur du matériel grand public avec de faibles seuils matériels. Les résultats d'évaluation de PandaLM sont fiables, entièrement reproductibles et peuvent protéger la sécurité des données. Le processus d'évaluation peut être effectué localement, ce qui le rend très approprié pour une utilisation dans le milieu universitaire et les unités qui nécessitent des données confidentielles. L'utilisation de PandaLM est très simple et ne nécessite que trois lignes de code pour être appelées. Pour vérifier les capacités d'évaluation de PandaLM, l'équipe PandaLM a invité trois annotateurs professionnels à juger indépendamment les résultats de différents grands modèles et a construit un ensemble de tests diversifié contenant 1 000 échantillons dans 50 champs. Sur cet ensemble de tests, la précision de PandaLM a atteint le niveau de 94 % de ChatGPT, et PandaLM a produit les mêmes conclusions sur les avantages et les inconvénients du modèle que l'annotation manuelle.
Présentation de PandaLM
Actuellement, il existe deux manières principales d'évaluer les grands modèles :
(1) En appelant l'interface API d'une entreprise tierce
(2) En embauchant des experts pour ; annotation manuelle.
Cependant, le transfert de données vers des sociétés tierces peut entraîner des problèmes de violation de données similaires à ceux des employés de Samsung qui fuient du code [1] et l'embauche d'experts pour étiqueter de grandes quantités de données prend du temps et coûte cher. Un problème urgent à résoudre est le suivant : comment réaliser une évaluation de grands modèles préservant la confidentialité, fiable, reproductible et bon marché ?
Afin de surmonter les limites de ces deux méthodes d'évaluation, cette étude a développé PandaLM, un modèle d'arbitre spécifiquement utilisé pour évaluer les performances des grands modèles, et fournit une interface simple. Les utilisateurs peuvent appeler PandaLM pour obtenir la confidentialité avec seulement trois. lignes de code. Évaluation de modèles à grande échelle protectrice, fiable, reproductible et économique. Pour plus de détails sur la formation sur PandaLM, consultez le projet open source.
Pour valider la capacité de PandaLM à évaluer de grands modèles, l’équipe de recherche a construit un ensemble de tests diversifiés annotés par des humains d’environ 1 000 échantillons, avec un contexte et des étiquettes générés par des humains. Sur l'ensemble de données de test, PandaLM-7B a atteint une précision de 94 % de ChatGPT (gpt-3.5-turbo).
Comment utiliser PandaLM ?
Lorsque deux modèles à grande échelle différents produisent des réponses différentes aux mêmes instructions et contexte, l'objectif de PandaLM est de comparer la qualité des réponses des deux modèles et de produire les résultats de comparaison, la base de comparaison et les réponses pour référence . Il existe trois résultats de comparaison : la réponse 1 est meilleure ; la réponse 2 est meilleure ; la réponse 1 et la réponse 2 sont de qualité égale. Lorsque vous comparez les performances de plusieurs grands modèles, utilisez simplement PandaLM pour effectuer des comparaisons par paires, puis agrégez ces comparaisons pour classer les performances des modèles ou tracer l'ordre partiel des modèles. Cela permet une analyse visuelle des différences de performances entre les différents modèles. Étant donné que PandaLM doit uniquement être déployé localement et ne nécessite aucune intervention humaine, il peut être évalué de manière respectueuse de la vie privée et à faible coût. Pour offrir une meilleure interprétabilité, PandaLM peut également expliquer ses sélections en langage naturel et générer un ensemble supplémentaire de réponses de référence.
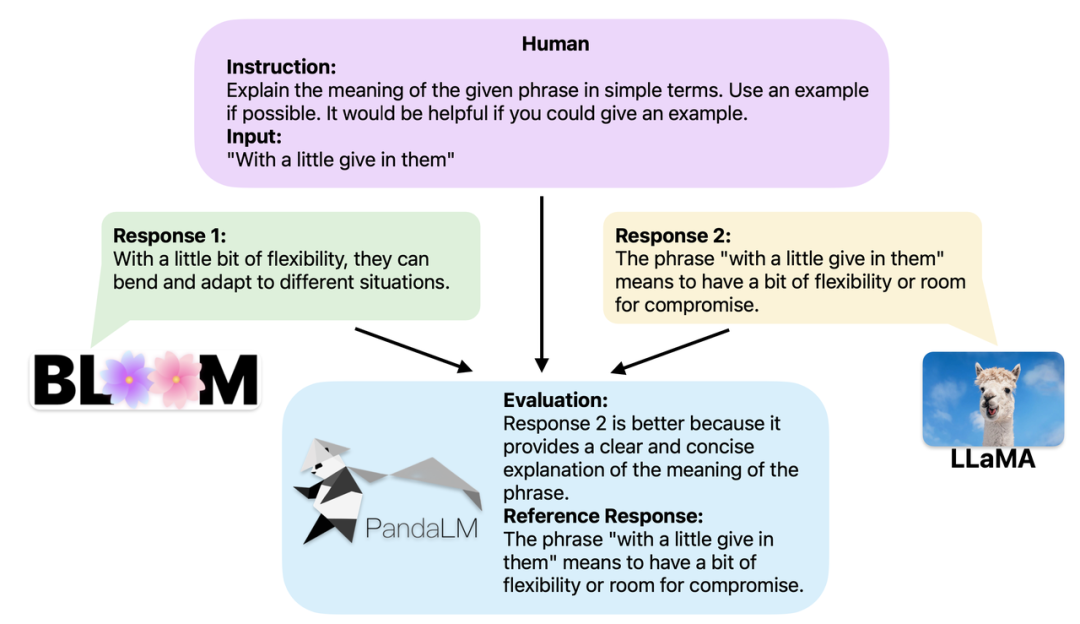
PandaLM prend non seulement en charge l'utilisation de l'interface utilisateur Web pour l'analyse de cas, mais prend également en charge trois lignes de code pour appeler PandaLM pour l'évaluation de texte généré par des modèles et des données arbitraires. Étant donné que de nombreux modèles et frameworks existants peuvent ne pas être open source ou difficiles à déduire localement, PandaLM permet de générer du texte à évaluer en spécifiant les pondérations du modèle ou en transmettant directement un fichier .json contenant le texte à évaluer. Les utilisateurs peuvent utiliser PandaLM pour évaluer les modèles définis par l'utilisateur et saisir des données simplement en fournissant une liste de noms de modèles, d'ID de modèle HuggingFace ou de chemins de fichiers .json. Ce qui suit est un exemple d'utilisation minimaliste :

De plus, afin de permettre à chacun d'utiliser PandaLM de manière flexible pour une évaluation gratuite, l'équipe de recherche a divulgué les poids des modèles de PandaLM sur le site Web HuggingFace. Vous pouvez facilement charger le modèle PandaLM-7B avec la commande suivante :

Caractéristiques de PandaLM
Les fonctionnalités de PandaLM incluent la reproductibilité, l'automatisation, la protection de la vie privée, un faible coût et un niveau d'attente d'évaluation élevé.
1. Reproductibilité : étant donné que les poids de PandaLM sont publics, même s'il y a du caractère aléatoire dans la sortie du modèle de langage, les résultats de l'évaluation de PandaLM resteront cohérents après avoir corrigé la graine aléatoire. Les méthodes d'évaluation qui s'appuient sur des API en ligne peuvent avoir des mises à jour incohérentes à différents moments en raison de mises à jour opaques, et à mesure que les modèles sont itérés, les anciens modèles de l'API peuvent ne plus être accessibles, de sorte que les évaluations basées sur des API en ligne ne sont souvent pas reproductibles.
2. Automatisation, protection de la vie privée et faible coût : les utilisateurs n'ont qu'à déployer le modèle PandaLM localement et à appeler des commandes prêtes à l'emploi pour évaluer divers grands modèles. Il n'est pas nécessaire de maintenir une communication en temps réel et de s'inquiéter des fuites de données. comme embaucher des experts. Dans le même temps, l'ensemble du processus d'évaluation de PandaLM n'implique aucun frais d'API ni coût de main-d'œuvre, ce qui est très bon marché.
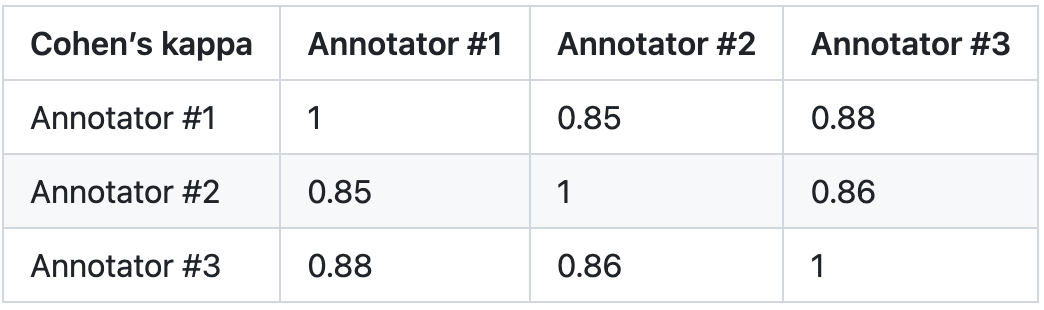
3. Niveau d'évaluation : Pour vérifier la fiabilité de PandaLM, cette étude a embauché trois experts pour effectuer indépendamment des annotations répétées et a créé un ensemble de tests d'annotation manuelle. L'ensemble de test contient 50 scénarios différents, chacun comportant plusieurs tâches. Cet ensemble de tests est diversifié, fiable et cohérent avec les préférences humaines en matière de texte. Chaque échantillon de l'ensemble de test se compose d'instructions et de contexte, ainsi que de deux réponses générées par différents grands modèles, et la qualité des deux réponses est comparée par des humains.
Cette étude élimine les échantillons présentant de grandes différences entre les annotateurs, garantissant que l'IAA (Inter Annotator Agreement) de chaque annotateur sur l'ensemble de test final est proche de 0,85. Il convient de noter qu'il n'y a aucun chevauchement entre l'ensemble de formation PandaLM et l'ensemble de test annoté manuellement créé dans cette étude.
Ces échantillons filtrés nécessitent des connaissances supplémentaires ou des informations difficiles à obtenir pour faciliter le jugement, ce qui rend difficile pour les humains de les étiqueter avec précision. L’ensemble de tests filtré contient 1 000 échantillons, tandis que l’ensemble de tests non filtré d’origine contient 2 500 échantillons. La distribution de l'ensemble de test est {0:105, 1:422, 2:472}, où 0 indique que les deux réponses sont de qualité similaire ; 1 indique que la réponse 1 est meilleure ; 2 indique que la réponse 2 est meilleure.
Basée sur l'ensemble de tests humains, la comparaison des performances entre PandaLM et gpt-3.5-turbo est la suivante :
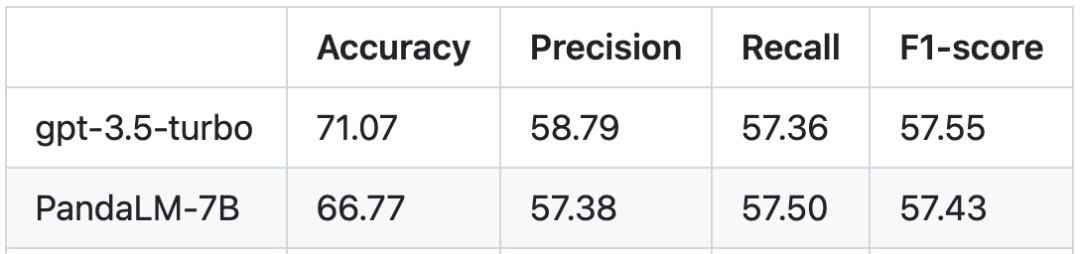
On peut voir que PandaLM-7B a atteint gpt-3.5-turbo en termes de précision, Turbo atteint un niveau de 94 %, et en termes de précision, de rappel et de scores F1, PandaLM-7B est presque le même que gpt-3.5-turbo. On peut dire que PandaLM-7B dispose déjà de capacités d'évaluation de grands modèles équivalentes à gpt-3.5-turbo.
En plus de l'exactitude, de la précision, du rappel et des scores F1 sur l'ensemble de tests, cette étude fournit également les résultats de comparaisons entre 5 grands modèles open source de taille similaire. L'étude a d'abord utilisé les mêmes données d'entraînement pour affiner les cinq modèles, puis a utilisé des humains, gpt-3.5-turbo et PandaLM pour effectuer des comparaisons par paires des cinq modèles. Le premier tuple (72, 28, 11) de la première ligne du tableau ci-dessous indique qu'il existe 72 réponses LLaMA-7B meilleures que Bloom-7B et 28 réponses LLaMA-7B pires que Bloom-7B Two. Il y a 11 réponses de modèles de qualité similaire. Ainsi, dans cet exemple, les humains pensent que LLaMA-7B est meilleur que Bloom-7B. Les résultats des trois tableaux suivants montrent que les humains, gpt-3.5-turbo et PandaLM-7B ont des jugements tout à fait cohérents sur la relation entre les avantages et les inconvénients de chaque modèle.
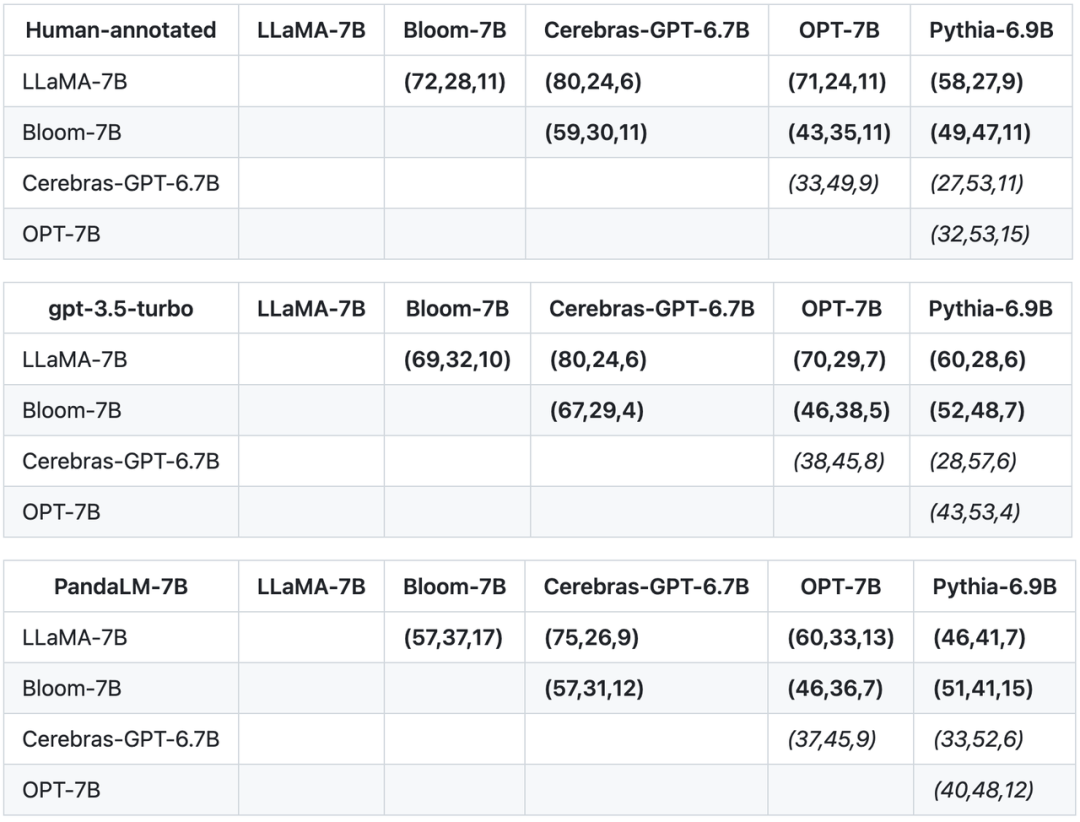
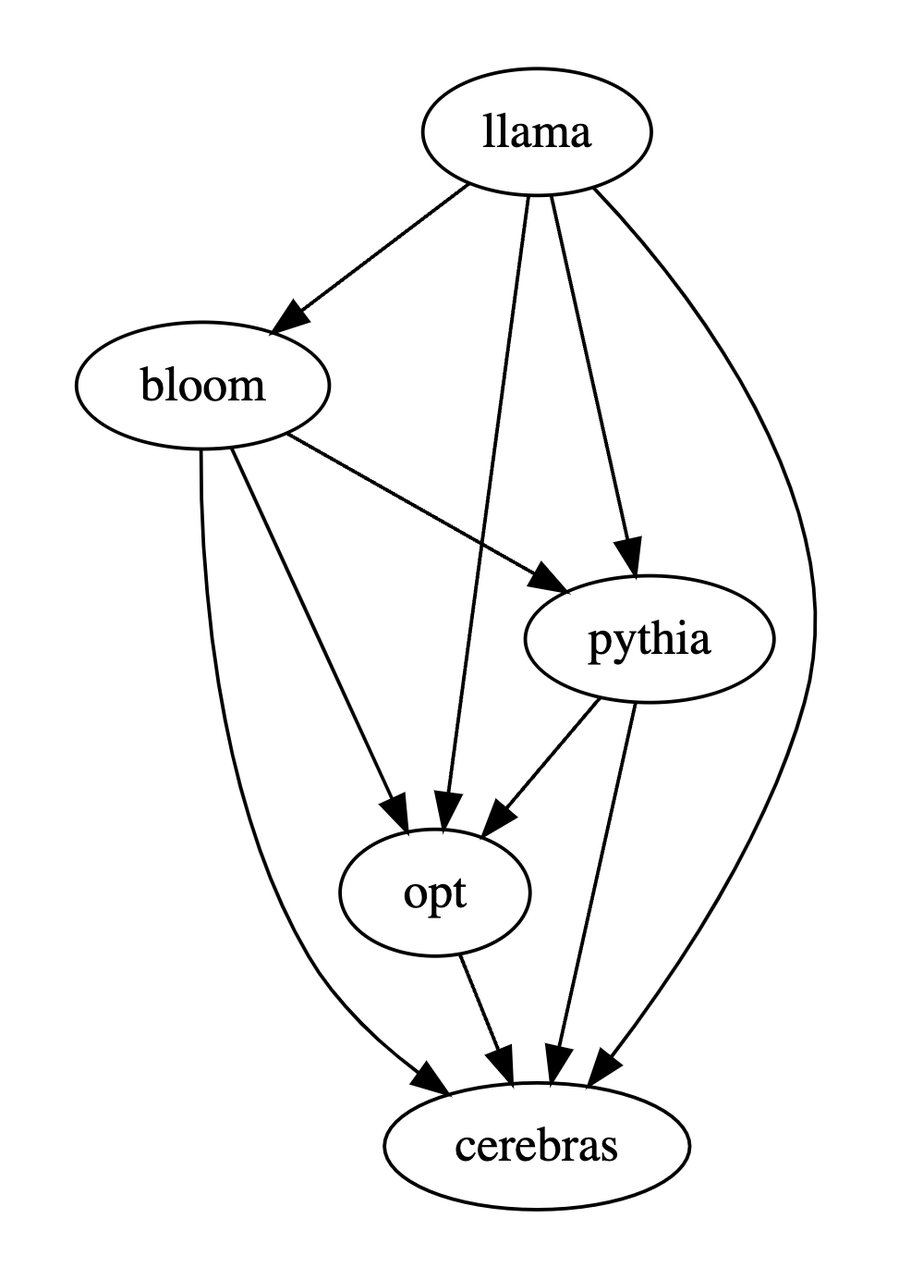
Sur la base des trois tableaux ci-dessus, cette étude a généré un diagramme d'ordre partiel des avantages et des inconvénients du modèle. Ce diagramme d'ordre partiel constitue la relation d'ordre total, qui peut être exprimée comme suit : LLaMA-. 7B > Bloom-7B > ; Pythie-6.9B >
Résumé
En résumé, PandaLM propose une troisième option pour évaluer les grands modèles en plus de l'évaluation manuelle et des API tierces. Le niveau d'évaluation de PandaLM est non seulement élevé, mais ses résultats sont reproductibles, le processus d'évaluation est hautement automatisé, la confidentialité est protégée et le coût est faible. L'équipe de recherche estime que PandaLM favorisera la recherche sur des modèles à grande échelle dans le monde universitaire et industriel, et permettra à davantage de personnes de bénéficier des avancées dans ce domaine de recherche. Tout le monde est invité à prêter attention au projet PandaLM. Plus de détails sur la formation, les tests, les articles connexes et les travaux de suivi seront publiés sur le site Web du projet : https://github.com/WeOpenML/PandaLM
Introduction à l'équipe des auteurs
Auteur Dans l'équipe, Wang Yidong* est du Centre national d'ingénierie pour le génie logiciel de l'Université de Pékin (Ph.D.) et de l'Université de West Lake (assistant de recherche), et Yu Zhuohao*, Zeng Zhengran , Jiang Chaoya, Xie Rui, Ye Wei† et Zhang Shikun† sont du Centre national d'ingénierie du génie logiciel de l'Université de Pékin, Yang Linyi, Wang Cunxiang et Zhang Yue† sont de l'Université de Westlake, Heng Qiang est de l'État de Caroline du Nord. Université, Chen Hao est de l'Université Carnegie Mellon et Wang Jindong et Xie Xing sont de Microsoft Research Asia. * indique le co-premier auteur, † indique l'auteur co-correspondant.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI