
Maison >Périphériques technologiques >IA >Décrire brièvement les cinq types d'accélérateurs d'apprentissage automatique
Décrire brièvement les cinq types d'accélérateurs d'apprentissage automatique

- 王林avant
- 2023-05-25 14:55:251744parcourir
Traducteur | Bugatti
Critique | Sun Shujuan
Les dix dernières années ont été l'ère de l'apprentissage profond. Nous sommes enthousiasmés par une série de grands événements, d'AlphaGo au DELL-E 2. D’innombrables produits ou services basés sur l’intelligence artificielle (IA) sont apparus dans la vie quotidienne, notamment les appareils Alexa, les recommandations publicitaires, les robots d’entrepôt et les voitures autonomes. Ces dernières années, la taille des modèles d’apprentissage profond a augmenté de façon exponentielle. Ce n'est pas une nouveauté : le modèle Wu Dao 2.0 contient 1 750 milliards de paramètres et la formation de GPT-3 sur des instances de 240 ml.p4d.24xlarge dans la plateforme de formation SageMaker ne prend qu'environ 25 jours.
Mais à mesure que la formation et le déploiement du deep learning évoluent, cela devient de plus en plus difficile. À mesure que les modèles d’apprentissage profond évoluent, l’évolutivité et l’efficacité constituent deux défis majeurs en matière de formation et de déploiement. 
Figure 1. La relation entre formation et accélérateur de déploiement
On le voit , Les accélérateurs matériels et les frameworks d'IA sont le courant dominant de l'accélération. Mais récemment, les compilateurs ML, les plateformes informatiques d’IA et les services cloud ML sont devenus de plus en plus importants. 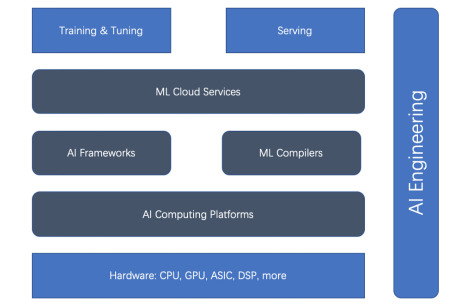
TensorFlow :
TensorFlow est le framework phare d'IA. TensorFlow domine la communauté open source du deep learning depuis le début. TensorFlow Serving est une plateforme bien définie et mature. Pour Internet et l'IoT, TensorFlow.js et TensorFlow Lite sont également matures. Mais en raison des limites de l'exploration précoce du deep learning, TensorFlow 1.x a été conçu pour créer des graphiques statiques d'une manière non Python. Cela devient un obstacle à une évaluation immédiate en utilisant le mode « impatient », qui permet à PyTorch de s'améliorer rapidement dans le domaine de la recherche. TensorFlow 2.x essaie de rattraper son retard, mais malheureusement, la mise à niveau de TensorFlow 1.x vers 2.x est fastidieuse. TensorFlow introduit également Keras pour faciliter son utilisation globale, et XLA (Accelerated Linear Algebra), un compilateur d'optimisation, pour accélérer la couche inférieure.PyTorch :
Avec son mode enthousiaste et son approche de type Python, PyTorch est un cheval de bataille dans la communauté du deep learning d'aujourd'hui, utilisé dans tout, de la recherche à la production. En plus de TorchServe, PyTorch s'intègre également à des plates-formes indépendantes du framework telles que Kubeflow. De plus, la popularité de PyTorch est indissociable du succès de la bibliothèque Transformers de Hugging Face.JAX :
Google présente JAX, NumPy et JIT accélérés par les appareils. Tout comme PyTorch l'a fait il y a quelques années, il s'agit d'un cadre d'apprentissage profond plus natif qui gagne rapidement en popularité dans la communauté des chercheurs. Mais ce n'est pas encore un produit Google « officiel », comme le prétend Google.2. Accélérateur matériel
Il ne fait aucun doute que le GPU de Nvidia peut accélérer la formation en deep learning, mais il a été conçu à l'origine pour les cartes vidéo.Après l'émergence des GPU à usage général, les cartes graphiques utilisées pour l'entraînement des réseaux neuronaux sont devenues extrêmement populaires. Ces GPU à usage général peuvent exécuter du code arbitraire, pas seulement le rendu des sous-programmes. Le langage de programmation CUDA de NVIDIA permet d'écrire du code arbitraire dans un langage de type C. Le GPU à usage général dispose d'un modèle de programmation relativement pratique, d'un mécanisme de parallélisme à grande échelle et d'une bande passante mémoire élevée, et constitue désormais une plate-forme idéale pour la programmation de réseaux neuronaux.
Aujourd'hui, NVIDIA prend en charge une gamme de GPU allant du bureau au mobile, en passant par la station de travail, la station de travail mobile, la console de jeu et le centre de données. Avec le grand succès du GPU NVIDIA, de nombreux successeurs sont en cours de route, comme le GPU d'AMD et le TPU ASIC de Google.3. AI Computing Platform
Comme mentionné précédemment, la vitesse de formation et de déploiement du ML dépend fortement du matériel (tel que le GPU et le TPU). Ces plates-formes pilotes (c'est-à-dire les plates-formes informatiques d'IA) sont essentielles à la performance. Il existe deux plates-formes informatiques d'IA bien connues : CUDA et OpenCL.
CUDA : CUDA (Compute Unified Device Architecture) est un paradigme de programmation parallèle publié par NVIDIA en 2007. Il est conçu pour de nombreuses applications générales sur processeurs graphiques et GPU. CUDA est une API propriétaire qui prend uniquement en charge les GPU à architecture Tesla de NVIDIA. Les cartes graphiques prises en charge par CUDA incluent les séries GeForce 8, Tesla et Quadro.
OpenCL : OpenCL (Open Computing Language) a été initialement développé par Apple et maintenant maintenu par l'équipe Khronos pour l'informatique hétérogène, y compris les CPU, GPU, DSP et autres types de processeurs. Ce langage portable est suffisamment adaptable pour permettre des performances élevées sur toutes les plates-formes matérielles, y compris les GPU de Nvidia.
NVIDIA est désormais compatible OpenCL 3.0 pour une utilisation avec les pilotes R465 et supérieurs. À l'aide de l'API OpenCL, on peut lancer des noyaux de calcul écrits dans un sous-ensemble limité du langage de programmation C sur le GPU.
4. ML Compiler
Le compilateur ML joue un rôle essentiel dans l'accélération de la formation et du déploiement. Les compilateurs ML peuvent améliorer considérablement l'efficacité du déploiement de modèles à grande échelle. Il existe de nombreux compilateurs populaires tels que Apache TVM, LLVM, Google MLIR, TensorFlow XLA, Meta Glow, PyTorch nvFuser et Intel PlaidML.
5. ML Cloud Services
La plateforme et les services cloud ML gèrent la plateforme ML dans le cloud. Ils peuvent être optimisés de plusieurs manières pour augmenter l’efficacité.
Prenons Amazon SageMaker comme exemple. Il s'agit d'un service de plate-forme cloud ML de premier plan. SageMaker fournit une large gamme de fonctionnalités pour le cycle de vie du ML : de la préparation, de la création, de la formation/réglage au déploiement/gestion.
Il optimise de nombreux aspects pour améliorer l'efficacité de la formation et du déploiement, tels que les points de terminaison multimodèles sur GPU, une formation rentable utilisant des clusters hétérogènes et un processeur Graviton propriétaire adapté à l'inférence ML basée sur le CPU.
Conclusion
À mesure que l'ampleur de la formation et du déploiement du deep learning continue de s'étendre, les défis deviennent de plus en plus grands. Améliorer l’efficacité de la formation et du déploiement du deep learning est complexe. Sur la base du cycle de vie du ML, cinq aspects peuvent accélérer la formation et le déploiement du ML : le cadre d'IA, l'accélérateur matériel, la plate-forme informatique, le compilateur ML et le service cloud. L’ingénierie de l’IA peut coordonner tous ces éléments et utiliser des principes d’ingénierie pour améliorer l’efficacité à tous les niveaux.
Titre original : 5 types d'accélérateurs de ML, auteur : Luhui Hu
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI