
Maison >Périphériques technologiques >IA >Recommandations de nouveaux livres | Intelligence artificielle embarquée
Recommandations de nouveaux livres | Intelligence artificielle embarquée

- 王林avant
- 2023-05-25 13:37:441443parcourir

《Intelligence artificielle embarquée》
Compilé par Li Bin
ISBN : 978-7-302-62796-8
Prix : 69,00 yuans
Scannez le code QR pour acheter des livres à prix réduit
L'avènement de ChatGPT a révélé à l'humanité le prototype de l'intelligence artificielle générale (AGI). Les gens ont découvert que lorsque les réseaux de neurones artificiels atteignent une certaine échelle et sont couplés à des méthodes d'apprentissage anthropomorphes (comme le RLHF), un miracle se produit soudainement et l'intelligence commence à se débarrasser des chaînes du cerveau humain et se réalise sur les ordinateurs !
Cependant, il reste encore un défi à résoudre : Peut-on réaliser les miracles ci-dessus sur des machines comparables en taille et en consommation d'énergie à celles des humains, comme les robots humanoïdes ?
Actuellement, ChatGPT nécessite l'utilisation de plus de 30 000 GPU pour la formation et l'inférence, avec une puissance totale de plus de 10 millions de watts et une facture d'électricité quotidienne d'environ 50 000 $ US. Le volume du cerveau humain n’est que d’environ 1,5 litre et sa puissance est inférieure à 20 watts. Si nous voulons intégrer l’intelligence artificielle générale dans les robots, ou même dans les drones, les téléphones mobiles, les appareils électroménagers intelligents ou les appareils IoT, nous devrons surmonter les défis ci-dessus. C’est le sujet que souhaite explorer le livre « Embedded Artificial Intelligence ».
Dans le domaine de l'intelligence artificielle embarquée, nous utiliserons une efficacité énergétique plus élevée pour exécuter des algorithmes plus rationalisés et les placerons dans une machine de taille et de poids plus petits pour effectuer des tâches de raisonnement en temps réel dans le monde réel. En un mot, nous devons mettre en œuvre l’intelligence artificielle de la manière la plus simple possible !
Pour relever ce défi, le problème doit être abordé à tous les niveaux. En résumé, pour réaliser l’intelligence artificielle embarquée, cinq composants sont nécessaires.
Puce IA intégrée. Il s’agit d’un accélérateur d’IA avec une efficacité énergétique plus élevée.
Algorithme d'IA léger. Il a une complexité de calcul moindre et moins de paramètres, mais sa précision est comparable à celle des grands algorithmes d’IA.
Compression du modèle. Il supprime en outre les paramètres redondants dans les algorithmes d’IA légers et les exprime de manière plus rationalisée.
Optimisation de la compilation. Il traduit le modèle en un codage plus adapté aux instructions de l'accélérateur IA.
Cadre d'application en cascade multicouche. Il utilise des algorithmes plus appropriés à des moments plus appropriés, réduisant ainsi le coût global du système et la consommation d'énergie.
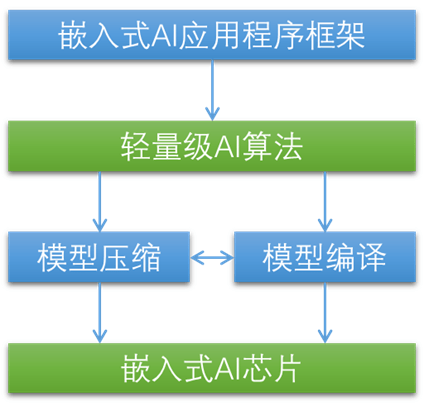
En utilisant ces 5 composants en combinaison, l'intelligence artificielle générale devrait être véritablement intégrée dans la machine, lui permettant de voir, d'entendre, de parler et de penser, véritablement « vivante » et de devenir une autre forme de vie : la vie artificielle.
Bien sûr, il reste un long chemin à parcourir pour réaliser les rêves ci-dessus. Ce livre est un guide d'introduction qui explore les problèmes et présente les méthodes et outils actuels pour les résoudre. Ce n’est pas la réponse définitive, mais cela fournit la clé pour y parvenir.
Si vous souhaitez réaliser une intelligence artificielle générale sur les robots, les drones, les téléphones mobiles, les appareils électroménagers intelligents et les appareils Internet des objets, c'est sans aucun doute un livre d'introduction utile.
Caractéristiques de ce livre
1. Domestic Le premier livrequi présente de manière exhaustive l'intelligence artificielle embarquée.
2. Le contenu est riche et détaillé, couvrant les principes, plateformes et pratiques de l'intelligence artificielle embarquée.
3. Faire une synthèse systématique des principes de l'intelligence artificielle embarquée, Le concept est inédit et l'organisation est claire.
4. Introduction complète à la mise en œuvre de la plateforme d'intelligence artificielle embarquée, y compris les puces de réseaux neuronaux embarqués grand public et les cadres logiciels.
5. Résumer le processus de développement de l'intelligence artificielle embarquée.
6. Combiner les principes avec la pratique, utiliser le code pour démontrer des cas d'application pratiques de l'intelligence artificielle embarquée.
Exemples d'application
Dans le dernier chapitre du livre, nous essayons de réaliser un parasol volant basé sur un drone. Ce type de parapluie peut suivre les mouvements des personnes en temps réel et les bloquer du soleil à tout moment, libérant ainsi les mains des gens et vous permettant de les utiliser. pour voler pendant l'été chaud. Amusez-vous à faire du shopping, à jouer et à être le centre d'attention.
Afin de réaliser le suivi du corps humain pour les parachutes sans pilote, nous utiliserons des méthodes de vision industrielle. Le corps humain est photographié par la caméra située à l'avant du parachute, et le contour du corps humain est calculé grâce à un algorithme léger d'estimation de la posture humaine pour obtenir les positions de la tête, des traits du visage et des articulations des membres de la personne, puis analyser les mouvements du corps humain pour prédire dans quelle direction la personne avancera, reculera, tournera ou montera ou descendra, de sorte que le parachute volant sans pilote puisse suivre ce mouvement, ajuster la position spatiale du parachute volant sans pilote à tout moment, et obtenez l'effet suivant et pare-soleil sur le corps humain.
Compte tenu du poids, de la consommation d'énergie et d'autres raisons, une puce IA intégrée dédiée doit être utilisée. Dans le livre, NVIDIA Jetson est utilisé comme exemple de développement. Désormais, des puces offrant des performances d'inférence par watt plus élevées, telles que les SoC basés sur ARM, sont largement utilisées pour relever les défis posés par le développement rapide de la technologie. Mais les processus et méthodes présentés dans le livre sont toujours applicables.
Pour que l'algorithme léger ci-dessus réponde aux exigences du raisonnement en temps réel sur la puce IA intégrée, il est nécessaire d'utiliser la technologie de compression et d'optimisation du modèle pour élaguer et quantifier le modèle, réduire les paramètres du modèle et améliorer la performances de raisonnement. Doublez l'augmentation, la consommation d'énergie est doublée et elle est optimisée pour l'inférence de puce AI intégrée dédiée. Le livre utilise TensorRT comme exemple pour illustrer que si un SoC basé sur ARM est utilisé, des technologies de compression et d'optimisation telles que Tensorflow Lite peuvent être utilisées.
Enfin, avec l'aide des connaissances contenues dans ce livre, nous pouvons enfin faire voler le parasol sans pilote !
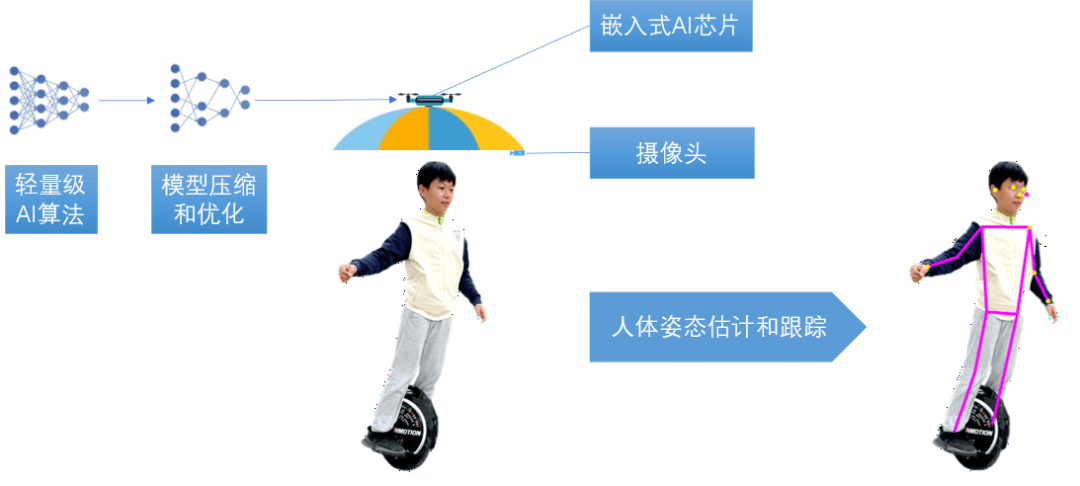
Table des matières
Faites glisser votre doigt vers le haut pour lire
Principes de la première partie
Chapitre 1 Intelligence artificielle et réseau de neurones artificiels
1.1 Qu'est-ce que l'intelligence artificielle
1.2 Qu'est-ce qu'un réseau neuronal artificiel
1.3 Cerveau humain
1.4 Composition de base du réseau neuronal artificiel
1.4.1 Neurone artificiel
1.4.2 Structure du réseau neuronal artificiel
1.5 Mécanisme d'apprentissage du réseau neuronal artificiel
1.6 Types de réseaux de neurones artificiels
1.7 Avantages des réseaux de neurones artificiels
1.8 Réseau neuronal profond
1.8.1 Qu'est-ce qu'un réseau neuronal profond
18.2 Réseaux de neurones profonds communs
1.8.3 Réseau neuronal convolutif
1.9 Recherche d'architecture de réseau neuronal (NAS)
1.9.1 Espace de recherche
1.9.2 Recherche d'apprentissage par renforcement
1.9.3 Recherche progressive
1.9.4 Recherche discrète
1.10 Apprentissage par transfert
1.10.1 Qu'est-ce que l'apprentissage par transfert
1.10.2 Types d'apprentissage par transfert
1.10.3 Avantages de l'apprentissage par transfert
1.10.4 Méthode d'apprentissage par transfert
1.10.5 Apprentissage par transfert et intelligence artificielle embarquée
Chapitre 2 Intelligence artificielle embarquée
2.1 Qu'est-ce que l'intelligence artificielle embarquée
2.2 Pourquoi l'intelligence artificielle embarquée est nécessaire
2.3 Première tentative : modèle de cloud computing
2.4 Du cloud à l'appareil : le mode local
2.5 Défis techniques de l'intelligence artificielle embarquée
2.5.1 Échelle du modèle
2.5.2 Efficacité énergétique
2.5.3 Accès à la mémoire
2.5.4 Vitesse d'inférence
2.5.5 Dimensions et poids
2.6 Approches de mise en œuvre de l'intelligence artificielle embarquée
2.7 Composants de mise en œuvre de l'intelligence artificielle embarquée
Chapitre 3 Principe de la puce IA embarquée
3.1 Calcul parallèle
3.2 Réseau pulsé
3.3 Cache multi-niveaux
3.4 Flux de données
Chapitre 4 Réseau neuronal léger
4.1 Réduire la complexité informatique
4.1.1 Convolution groupée
4.1.2 Convolution dans le sens de la profondeur
4.1.3 Convolution ponctuelle
4.1.4 Convolution séparable en profondeur
4.1.5 Mixage des canaux dans le désordre
4.2 SqueezeNet
4.2.1 Idée de base
4.2.2 Structure du réseau
4.2.3 Performances
4.3 Xception
4.3.1 Idée de base
4.3.2 Structure du réseau
4.3.3 Performances
4.4 MobileNet v1
4.4.1 Idée de base
4.4.2 Structure du réseau
4.4.3 Performances
4.5 MobileNet v2
4.5.1 Idée de base
4.5.2 Structure du réseau
4.5.3 Performances
4.6 MnasNet
4.6.1 Idée de base
4.6.2 Structure du réseau
4.6.3 Performances
4.7 MobileNet v3
4.7.1 Idée de base
4.7.2 Structure du réseau
4.7.3 Performances
4.6 Application du réseau neuronal léger
Chapitre 5 Compression profonde du réseau neuronal
5.1 Méthode générale de compression du réseau neuronal
5.1.1 Taille
5.1.2 Partage du poids
5.1.3 Quantification
5.1.4 Conversion binaire/ternaire
5.1.5 Convolution de Winograd
5.2 Co-conception compression-compilation
5.2.1 Le concept de co-conception de compression et de compilation
5.2.2 Compresseur
5.2.5 Compilateur
5.2.6 Avantages de la co-conception de compression et de compilation
Chapitre 6 Cadre d'application de réseau neuronal intégré
6.1 Structure du système hiérarchique en cascade
6.2 Efficacité du système hiérarchique en cascade
6.4 Mode de collaboration local-cloud
Chapitre 7 Apprentissage profond tout au long de la vie
7.1 Défauts et raisons du deep learning traditionnel
7.2 L'objectif de l'apprentissage profond tout au long de la vie
7.3 Caractéristiques de l'apprentissage profond tout au long de la vie
7.4 Implications neurobiologiques
7.5 Mise en œuvre d'un réseau neuronal profond à vie
7.5.1 Système de double apprentissage
7.5.2 mise à jour en temps réel
7.5.3 Fusion de mémoire
7.5.4 S'adapter à des scénarios réels
7.6 Apprentissage profond tout au long de la vie et intelligence artificielle embarquée
Plateforme Partie 2
Chapitre 8 Accélérateur matériel de réseau neuronal intégré
8.1 Aperçu
8.2 NVIDIA Jetson
8.2.1 Présentation du module Jetson
8.2.1 Structure interne du module Jetson
8.2.3 Performances Jetson
8.3 Intel Movidius
8.3.1 Puce VPU Movidius Myriad X
8.3.2 Clé de calcul neuronale Intel
8.4 Google Edge TPU
8.4.1 Introduction à Google Edge TPU
8.4.2 Fonctionnement de Google Edge TPU
8.5 XILINX DPU
8.6 ARM Ethos NPU
8.6.1 Processeur d'apprentissage automatique ARM
8.6.2 Série Ethos-N
8.6.3 Série Ethos-U
Résumé
Chapitre 9 Cadre logiciel de réseau neuronal intégré
9.1 Tensorflow Lite
9.1.1 Introduction à TensorFlow Lite
9.1.2 Comment fonctionne TensorFlow Lite
9.2 TensorRT
9.3 OuvrirVINO
9.3.1 Introduction à OpenVINO
9.3.2 Structure d'Open VINO
9.3.3 Développement d'applications Open VINO
9.4 XILINX Vitis
9.5 uTensor
9.6 Apache TVM
Résumé
Partie 3 Réalisation
Chapitre 10 Création d'un environnement de développement de réseau neuronal intégré
10.1 Processus de développement de l'IA embarquée
10.2 Processus de développement NVIDIA Jetson
Chapitre 11 Optimisation du modèle de réseau neuronal intégré
11.1 Optimisation du modèle TensorFlow
11.1.1 Optimisation post-formation
11.1.2 Optimisation pendant l'entraînement
11.2 Optimisation du modèle TensorRT
11.2.1 Intégration aux frameworks d'apprentissage profond traditionnels
11.2.2 Déploiement sur des systèmes embarqués
11.2.3 API TensorRT
11.2.4 Exemple d'application TensorRT
11.2.5 Convertisseur de modèle
11.3 Comparaison de deux techniques d'optimisation de modèle
Chapitre 12 Effectuer une inférence sur des appareils intégrés
12.1 Construire un projet à partir des sources
12.2 Utiliser ImageNet pour implémenter la classification d'images
12.2.1 Classification d'images statiques
12.2.2 Classification vidéo en temps réel de la caméra
12.3 Utilisez DetectNet pour réaliser la détection de cible
13.3.1 Détection de cible d'image statique
13.3.2 Détection de cible vidéo en temps réel de la caméra
12.4 Utiliser SegNet pour implémenter la segmentation sémantique
12.4.1 Segmentation sémantique d'images statiques
12.4.2 Segmentation sémantique vidéo
12.5 Utiliser PyTorch pour mettre en œuvre l'apprentissage par transfert
12.6 Utiliser des modèles transformés
Chapitre 13 Exemple d'application de réseau neuronal intégré
13.1 Scénarios d'application
13.2 Sélection du matériel
13.3 Développement du modèle
Conclusion : L'intelligence en toutes choses
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI