| Taille de l'arène |
256 Ko |
1 Mo |
| Taille de la piscine 4 Ko |
16 Ko |
|
ALIGNEMENT
| 8 B |
16 B |
|
Prenons comme exemple une machine 64 bits. Toutes les tailles de bloc possibles sont 16, 32, 48... 496, 512. Chaque taille correspond à une classe de taille, de petite à grande, 0, 1, 2... 30. , 31. Lors de l'allocation de mémoire, vous devez trouver un bloc libre dont la taille n'est pas inférieure à la taille demandée et est la plus petite. Le but de l'évaluation de la taille des blocs est de s'adapter aux demandes de mémoire de différentes tailles, de réduire la génération de fragments de mémoire et d'améliorer l'utilisation de l'arène.
Logique de gestion de la mémoire
Après avoir compris les concepts d'arène, de pool et de bloc, vous pouvez décrire la logique d'allocation de mémoire si la taille de mémoire requise est de n octets
Si n > 512, la solution de secours est malloc( ) , car la taille maximale du bloc est de 512 octets
Sinon, calculez la taille minimale du bloc qui n'est pas inférieure à n, par exemple n = 105, la taille minimale du bloc sur une machine 64 bits est de 112
De la taille et la seconde Allouer un bloc dans le même pool de mémoire. S'il n'y a pas de pool disponible, attribuez un pool à partir de l'arène disponible, utilisez malloc() pour demander une nouvelle arène à partir du système d'exploitation
La logique de libération de mémoire est la suivante
Déterminez d'abord s'il faut libérer La mémoire est-elle allouée par le gestionnaire de mémoire Python ? Si elle n'est pas renvoyée directement, recherchez le bloc et le pool correspondant à la mémoire à libérer, et remettez le bloc dans le pool en le laissant pour le suivant. allocation.Si libéré L'arène où se trouve le bloc est libre sauf pour elle-même. Ensuite, une fois le bloc renvoyé, l'arène entière est libre. Vous pouvez utiliser free() pour libérer l'arène et la renvoyer au système d'exploitation
- .
en Python, les objets ne sont généralement pas volumineux et ont un cycle de vie court, donc une fois l'arène demandée, l'allocation et la libération des objets sont principalement effectuées dans l'arène, ce qui améliore l'efficacité.
La logique de base du gestionnaire de mémoire Python a été clairement décrite ci-dessus, mais certains problèmes détaillés n'ont pas encore été résolus, tels que comment trouver le pool correspondant en fonction de la taille du bloc lors de l'allocation de mémoire, et comment ces pools sont liés les uns aux autres Lorsque la mémoire est libérée, comment déterminer si la mémoire à libérer est allouée par le gestionnaire de mémoire Python, etc. Ce qui suit combine le code source pour développer en détail la logique d'allocation et de libération de mémoire.
- Présentez d'abord la disposition de la mémoire et les structures de données correspondantes de l'arène et du pool, puis analysez en détail la logique de pymalloc_alloc() et pymalloc_free(), en prenant une machine 64 bits comme exemple. Disposition de la mémoire et structure de données correspondante
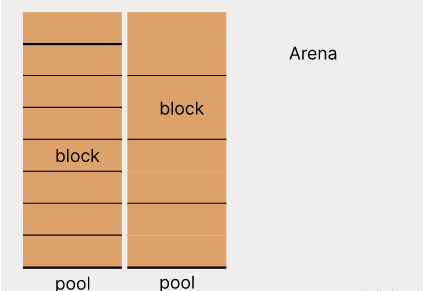
Arena
arena fait 1 Mo, le pool fait 16 Ko, les pools sont adjacents dans l'arène et il y a jusqu'à 1 Mo / 16 Ko = 64 pools dans une arène. Le gestionnaire de mémoire Python alignera la première adresse du premier pool de l'arène avec POOL_SIZE, de sorte que la première adresse de chaque pool soit un multiple entier de POOL_SIZE, étant donné n'importe quelle adresse mémoire, la première adresse du pool dans lequel il se trouve. peut être facilement calculée. L'adresse sera utilisée lorsque la mémoire sera libérée. POOL_SIZE est de 4 Ko sur une machine 32 bits et de 16 Ko sur une machine 64 bits. Un autre avantage est que chaque pool se trouve exactement sur une ou plusieurs pages physiques, ce qui améliore l'efficacité de l'accès à la mémoire. Le bloc mémoire gris dans l'image ci-dessus est ignoré pour l'alignement. Si la première adresse mémoire allouée par malloc() est alignée, alors le nombre de pools est de 64, sinon il est de 63. Bien sûr, Arena ne divise pas tous les pools au début, mais divisera un nouveau pool lorsqu'il n'y a pas de pool disponible. Lorsque tous les pools sont divisés, la disposition est celle indiquée dans la figure ci-dessus. Chaque arène est représentée par une structure arena_object, mais toutes les structures arena_objects n'ont pas d'arènes correspondantes, car les structures arena_objects correspondantes sont toujours conservées après la libération de l'arena_objects. Ces structures arena_objects qui ne correspondent pas aux arènes sont stockées dans un seul lien. list unused_arena_objects , qui peut être utilisé lors de la prochaine allocation de l'arène. Si struct arena_object a une arène correspondante et qu'il existe un pool qui peut être alloué dans l'arène, alors struct arena_object sera stocké dans la liste doublement chaînée usable_arenas. En même temps, tous les struct arena_objects seront stockés dans le tableau arenas indépendamment. de savoir s'ils ont des arènes correspondantes ou non. Les arènes dans usable_arenas sont triées de petite à grande en fonction du nombre de pools libres qu'elles contiennent. Ce tri est tel que les arènes qui ont utilisé plus de mémoire seront utilisées en premier la prochaine fois que le pool sera alloué, puis classées plus tard lorsque la mémoire sera épuisée. est libéré. Les Arenas avec plus de mémoire libre sont plus susceptibles de devenir complètement inactives, libérant ainsi leur espace mémoire et le restituant au système d'exploitation, réduisant ainsi la consommation globale de mémoire. La structure de struct arena_object et la signification de chaque champ sont les suivantesstruct arena_object {
uintptr_t address; // 指向 arena 的起始地址,如果当前 arena_object 没有对应的 arena 内存则 address = 0
block* pool_address; // pool 需要初始化之后才能使用,pool_address 指向的地址可以用来初始化一个 pool 用于分配
int nfreepools; // arena 中目前可以用来分配的 pool 的数量
uint ntotalpools; // arena 中 pool 的总数量,64 或 63
struct pool_header* freepools; // arena 中可以分配的 pool 构成一个单链表,freepools 指针是单链表的第一个节点
struct arena_object* nextarena; // 在 usable_arenas 或 unused_arena_objects 指向下一个节点
struct arena_object* prevarena; // 在 usable_arenas 中指向上一个节点
} Pool
Pool
pool 的内部等分成多个大小相等的 block,与 arena 一样,也有一个数据结构 struct pool_header 用来表示 pool。与 arena 不同的是,struct pool_header 位于 pool 的内部,在最开始的一段内存中,紧接之后的是第一个 block,为了让每个 block 的地址都能对齐机器访问内存的步长,可能需要在 struct pool_header 和第一个 block 之间做一些 padding,图中灰色部分所示。这部分 padding 不一定存在,在 64 位机器上 sizeof(struct pool_header) 为 48 字节,本来就已经对齐了,后面就直接跟第一个 block,中间没有 padding。即使如此,pool 最后的一小块内存也可能用不上,上图中下面的灰色部分所示,因为每个 pool 中 block 大小是相等的,假设 block 为 64 字节,一个 pool 中可以分出 255 个 block,前面 48 字节存储 struct pool_header,后面 16 字节用不上,当然如果 block 大小为 48 字节或 16 字节那么整个 pool 就会被完全利用上。同 arena 一样,pool 一开始不是把所有的 block 全部划分出来,而是在没有可用 block 的时候才回去新划分一个,在所有的 block 全部划分之后 pool 的布局如上图所示。
接下来看看 struct pool_header 的结构
struct pool_header {
union { block *_padding;
uint count; } ref; // 当前 pool 中已经使用的 block 数量,共用体中只有 count 字段有意义,_padding 是为了让 ref 字段占 8 个字节,这个特性在 usedpools 初始化的时候有用
block *freeblock; // pool 中可用来进行分配的 block 单链表的头指针
struct pool_header *nextpool; // 在 arena_object.freepools 或 usedpools 中指向下一个 pool
struct pool_header *prevpool; // 在 usedpools 中指向上一个 pool
uint arenaindex; // pool 所在 arena 在 arenas 数组中的索引
uint szidx; // pool 中 block 大小的分级
uint nextoffset; // 需要新的 block 可以从 nextoffset 处分配
uint maxnextoffset; // nextoffset 最大有效值
};
typedef struct pool_header *poolp;一旦被分配,每个池子都会处于三种状态之一:满、空或使用中。
usedpools 是内存分配最常访问的数据结构,分配内存时先计算申请的内存大小对应的 block 分级 i,usedpools[i+i] 指向的就是属于分级 i 的所有处于 used 状态的 pool 构成的双向循环链表的头结点,如果链表不空就从头结点中选择一个空闲 block 分配。下面我们来探究一下为什么 usedpools[i+i] 指向的链表,属于分级 i 的池。
usedpools 的原始定义如下
#define PTA(x) ((poolp )((uint8_t *)&(usedpools[2*(x)]) - 2*sizeof(block *)))
#define PT(x) PTA(x), PTA(x)
static poolp usedpools[2 * ((NB_SMALL_SIZE_CLASSES + 7) / 8) * 8] = {
PT(0), PT(1), PT(2), PT(3), PT(4), PT(5), PT(6), PT(7),
…
}将宏定义稍微展开一下
static poolp usedpools[64] = {
PTA(0), PTA(0), PTA(1), PTA(1), PTA(2), PTA(2), PTA(3), PTA(3),
PTA(4), PTA(4), PTA(5), PTA(5), PTA(6), PTA(6), PTA(7), PTA(7),
…
}PTA(x) 表示数组 usedpools 中第 2*x 个元素的地址减去两个指针的大小也就是 16 字节(64 位机器),假设数组 usedpools 首地址为 1000,则数组初始化的值如下图所示
假设 i = 2,则 usedpools[i+i] = usedpools[4] = 1016,数组元素的类型为 poolp 也就是 struct pool_header *,如果认为 1016 存储的是 struct pool_header,那么 usedpools[4] 和 usedpools[5] 的值也就是地址 1032 和 1040 存储的值,分别是字段 nextpool 和 prevpool 的值,可以得到
usedpools[4]->prevpool = usedpools[4]->nextpool = usedpools[4] = 1016
将 usedpools[4] 用指针 p 表示就有 p->prevpool = p->nextpool = p,那么 p 就是双向循环链表的哨兵节点,初始化的时候哨兵节点的前后指针都指向自己,表示当前链表为空。
虽然 usedpools 的定义非常绕,但是这样定义有个好处就是省去了哨兵节点的数据域,只保留前后指针,可以说是将节省内存做到了极致。
接下来我们将看一下 Python 3.10.4 源码中内存分配和释放逻辑的实现。另外说明一下,源码中有比本文详细的多注释说明,有兴趣的读者可以直接看源码,本文为了代码不至于过长会对代码做简化处理并且省略掉了大部分注释。
内存分配
内存分配的主逻辑在函数 pymalloc_alloc 中,简化后代码如下
static inline void*
pymalloc_alloc(void *ctx, size_t nbytes)
{
// 计算请求的内存大小 ntybes 所对应的内存分级 size
uint size = (uint)(nbytes - 1) >> ALIGNMENT_SHIFT;
// 找到属于内存分级 size 的 pool 所在的双向循环链表的头指针 pool
poolp pool = usedpools[size + size];
block *bp;
// pool != pool->nextpool,说明 pool 不是哨兵节点,是真正的 pool
if (LIKELY(pool != pool->nextpool)) {
++pool->ref.count;
// 将 pool->freeblock 指向的 block 分配给 bp,因为 pool 是从 usedpools 中取的,
// 根据 usedpools 的定义,pool->freeblock 指向的一定是空闲的 block
bp = pool->freeblock;
// 如果将 bp 分配之后 pool->freeblock 为空,需要从 pool 中划分一个空闲 block
// 到 pool->freeblock 链表中留下次分配使用
if (UNLIKELY((pool->freeblock = *(block **)bp) == NULL)) {
pymalloc_pool_extend(pool, size);
}
}
// 如果没有对应内存分级的可用 pool,就从 arena 中分配一个 pool 之后再从中分配 block
else {
bp = allocate_from_new_pool(size);
}
return (void *)bp;
}主体逻辑还是比较清晰的,代码中注释都做了说明,不过还是要解释一下下面的这个判断语句。
if (UNLIKELY((pool->freeblock = *(block **)bp) == NULL))
前文已经介绍过 pool->freeblock 表示 pool 中可用来进行分配的 block 所在单链表的头指针,类型为 block*,但是 block 的定义为 typedef uint8_t block;,并不是一个结构体,所以没有指针域,那么是怎么实现单链表的呢。考虑到 pool->freeblock 的实际含义,只需要把空闲 block 用单链表串起来就可以了,不需要数据域,Python 内存管理器把空闲 block 内存的起始 8 字节(64 位机器)当做虚拟的 next 指针,指向下一个空闲 block,具体是通过 *(block **)bp 实现的。首先用 (block **) 将 bp 转换成 block 的二级指针,然后用 * 解引用,将 bp 指向内存的首地址内容转换成 (block *) 类型,表示下一个 block 的地址,不得不说,C 语言真的是可以为所欲为。再来看一下上面判断语句,首先将 bp 的下一个空闲 block 地址赋值给 pool->freeblock,如果是 NULL 证明没有更多空闲 block,需要调用 pymalloc_pool_extend 扩充。
pymalloc_pool_extend 的源码简化后如下
static void
pymalloc_pool_extend(poolp pool, uint size)
{
// 如果 pool 还有更多空间,就划分一个空闲 block 放到 pool->freeblock 中
if (UNLIKELY(pool->nextoffset <= pool->maxnextoffset)) {
pool->freeblock = (block*)pool + pool->nextoffset;
pool->nextoffset += INDEX2SIZE(size);
// pool->freeblock 只有一个 block,需要将虚拟的 next 指针置为 NULL
*(block **)(pool->freeblock) = NULL;
return;
}
// 如果没有更多空间,需要将 pool 从 usedpools[size+size] 中移除
poolp next;
next = pool->nextpool;
pool = pool->prevpool;
next->prevpool = pool;
pool->nextpool = next;
}过程也很清晰,如果有更多空间就划分一个 block 到 pool->freeblock,如果没有更多空间就将 pool 从 usedpools[size+size] 中移除。pool->nextoffset 指向的是 pool 中从未被使用过内存的地址,分配 block 时候优先使用 pool->nextoffset 之前的空闲 block,这些空闲的 block 一般是之前分配过后来又被释放到 pool->freeblock 中的。这种复用空闲 block 的方式让 pool 更加经久耐用,如果每次都从 pool->nextoffset 划分一个新的 block,pool 很快就会被消耗完,变成 full 状态。
在 pymalloc_alloc 中如果没有可用 pool 就会调用 allocate_from_new_pool 先分配一个新的 pool,再从新的 pool 中分配 block,其源码简化后如下
static void*
allocate_from_new_pool(uint size)
{
// 没有可用的 arena 就新申请一个
if (UNLIKELY(usable_arenas == NULL)) {
usable_arenas = new_arena();
if (usable_arenas == NULL) {
return NULL;
}
// 将新的 arena 作为 usable_arenas 链表的头结点
usable_arenas->nextarena = usable_arenas->prevarena = NULL;
nfp2lasta[usable_arenas->nfreepools] = usable_arenas;
}
// 如果有可用 arena 就从中分配一个空闲 pool,并调整当前 arena 在 usable_arenas 中的位置,使 usable_arenas 按空闲 pool 的数量从小到大排序
if (nfp2lasta[usable_arenas->nfreepools] == usable_arenas) {
nfp2lasta[usable_arenas->nfreepools] = NULL;
}
if (usable_arenas->nfreepools > 1) {
nfp2lasta[usable_arenas->nfreepools - 1] = usable_arenas;
}
// 执行到这里,usable_arenas->freepools 就是当前需要的可用 pool
poolp pool = usable_arenas->freepools;
// 更新 freepools 链表和 nfreepools 计数
if (LIKELY(pool != NULL)) {
usable_arenas->freepools = pool->nextpool;
usable_arenas->nfreepools--;
// 分配之后,如果 arena 中没有空闲 pool,需要更新 usable_arenas 链表
if (UNLIKELY(usable_arenas->nfreepools == 0)) {
usable_arenas = usable_arenas->nextarena;
if (usable_arenas != NULL) {
usable_arenas->prevarena = NULL;
}
}
}
// 如果当前 arena 中没有可用 pool,就重新划分一个
else {
pool = (poolp)usable_arenas->pool_address;
pool->arenaindex = (uint)(usable_arenas - arenas);
pool->szidx = DUMMY_SIZE_IDX;
usable_arenas->pool_address += POOL_SIZE;
--usable_arenas->nfreepools;
// 划分之后,如果 arena 中没有空闲 pool,需要更新 usable_arenas 链表
if (usable_arenas->nfreepools == 0) {
usable_arenas = usable_arenas->nextarena;
if (usable_arenas != NULL) {
usable_arenas->prevarena = NULL;
}
}
}
// 执行到这里,变量 pool 就是找到的可用 pool,将其置为链表 usedpools[size+size] 的头节点
block *bp;
poolp next = usedpools[size + size];
pool->nextpool = next;
pool->prevpool = next;
next->nextpool = pool;
next->prevpool = pool;
pool->ref.count = 1;
// 如果 pool 的内存分级跟请求的一致,直接从中分配一个 block 返回
// 证明这个 pool 之前被使用之后又释放到 freepools 中了
// 并且当时使用的时候内存分级也是 size
if (pool->szidx == size) {
bp = pool->freeblock;
pool->freeblock = *(block **)bp;
return bp;
}
// 执行到这里,说明 pool 是 arena 新划分的,需要对其进行初始化
// 然后分配 block 返回
pool->szidx = size;
size = INDEX2SIZE(size);
bp = (block *)pool + POOL_OVERHEAD;
pool->nextoffset = POOL_OVERHEAD + (size << 1);
pool->maxnextoffset = POOL_SIZE - size;
pool->freeblock = bp + size;
*(block **)(pool->freeblock) = NULL;
return bp;
}这段代码比较长,归纳一下做了下面 3 件事
如果没有可用的 arena 就重新申请一个
从可用的 arena 中分配一个新的 pool
从分配的 pool 中分配空闲的 block
首先是 arena 的申请,申请流程在函数 new_arena() 中,申请完之后将对应的 arena_object 置为 双线链表 usable_arenas 的头结点,并且前后指针都置为 NULL,因为只有在没有可用 arena 的时候才回去调用 new_arena(),所以申请之后系统里只有一个可用 arena。另外还有一个操作如下
nfp2lasta[usable_arenas->nfreepools] = usable_arenas;
nfp2lasta 是一个数组,nfp2lasta[i] 表示的是在 usable_arenas 链表中,空闲 pool 的数量为 i 的所有 arena 中最后一个 arena。前文已经说明 usable_arenas 是按照 arena 中空闲 pool 的数量从小到大排序的,为了维护 usable_arenas 的有序性,在插入或删除一个 arena 的时候需要找到对应的位置,时间复杂度为 O(N),为了避免线性搜索,Python 3.8 引入了 nfp2lasta,将时间复杂度降为常量级别。
有了可用的 arena 就可以从中分配 pool 了,分配 pool 之后 arena->nfreepools 就会减少,需要更新 nfp2lasta,由于使用的是链表 usable_arenas 的头结点,并且是减少其空闲 pool 数量,所以整个链表依然有序。接下来优先复用 arena->freepools 中空闲的 pool,如果没有就从 arena->pool_address 指向的未使用内存处新划分一个 pool,这点跟 pool 中复用空闲 block 的策略是一样的。
分配了可用的 pool,先将其置为链表 usedpools[size+size] 的头结点,然后从中分配 block,如果 pool 不是从新分配的 arena 获得的,那么 pool 就是之前初始化使用之后释放掉的,如果 pool 的分级恰好就是请求的内存分级那么直接从 pool->freeblock 分配 block,否则需要将 pool 重新初始化,当然如果 pool 来自新分配的 arena 也要进行初始化。初始化的时候,先将第一个 block 的地址进行内存对齐,然后将 pool->freeblock 指向第 2 个 block 留下次分配使用(第 1 个 block 本次要返回),将 pool->nextoffset 指向第 3 个 block,在下次划分新的 block 时使用。
内存释放
内存释放的主逻辑在 pymalloc_free 函数中,代码简化后如下
static inline int
pymalloc_free(void *ctx, void *p)
{
// 假设 p 是 pool 分配的,计算 p 所在 pool 的首地址
poolp pool = POOL_ADDR(p);
// 如果 p 不是内存管理器分配的直接返回
if (UNLIKELY(!address_in_range(p, pool))) {
return 0;
}
// 将 p 指向的 block 归还给 pool,置为 pool->freeblock 的头结点
block *lastfree = pool->freeblock;
*(block **)p = lastfree;
pool->freeblock = (block *)p;
pool->ref.count--;
// 如果 pool 原来处于 full 状态,现在有一个空闲的 block 就变成了 used 状态
// 需要将其作为头结点插到 usedpools[size+size] 中
if (UNLIKELY(lastfree == NULL)) {
insert_to_usedpool(pool);
return 1;
}
if (LIKELY(pool->ref.count != 0)) {
return 1;
}
// 如果 block 释放之后,其所在 pool 所有的 block 都是空闲状态,
// 将 pool 从 usedpools[size+size] 中移到 arena->freepools
insert_to_freepool(pool);
return 1;
}pymalloc_free 函数的逻辑也很清晰
计算地址 p 所在 pool 首地址,前文介绍过每个 pool 首地址都是 POOL_SIZE 的整数倍,所以将 p 的低位置 0 就得到了 pool 的地址
address_in_range(p, pool) 判断 p 是否是由 pool 分配的,如果不是直接返回
将 p 指向的 block 释放掉,被 pool->freeblock 回收
如果 pool 开始为 full 状态,那么回收 block 之后就是 used 状态,调用函数 insert_to_usedpool(pool) 将其置为 usedpools[size+size] 的头结点。这里的策略跟 usable_arenas 一样,优先使用快满的 pool,让比较空闲的 pool 有较高的概率被释放掉。
如果 pool 回收 block 之后变成 empty 状态,需要调用 insert_to_freepool(pool) 将 pool 也释放掉
address_in_range 函数如下
address_in_range(void *p, poolp pool)
{
uint arenaindex = *((volatile uint *)&pool->arenaindex);
return arenaindex < maxarenas &&
(uintptr_t)p - arenas[arenaindex].address < ARENA_SIZE &&
arenas[arenaindex].address != 0;
}这段逻辑能在常量时间内判断出 p 是否由 pool 分配,但是存在一个可能出问题的地方,毕竟这里的 pool 是在假设 p 是由 pool 分配的前提下计算出来的,有可能 pool 指向的地址可能还没被初始化,pool->arenaindex 操作可能会出错。Python 3.10 在这个 commit 中利用基数树来判断任意一个地址 p 是不是由内存管理器分配的,避免了可能出现的内存访问错误。
insert_to_usedpool 函数中只是简单的指针操作就不展开了,insert_to_freepool 稍微复杂一点,下面再展开一下
static void
insert_to_freepool(poolp pool)
{
poolp next = pool->nextpool;
poolp prev = pool->prevpool;
next->prevpool = prev;
prev->nextpool = next;
// 将 pool 置为 ao->freepools 头结点
struct arena_object *ao = &arenas[pool->arenaindex];
pool->nextpool = ao->freepools;
ao->freepools = pool;
uint nf = ao->nfreepools;
struct arena_object* lastnf = nfp2lasta[nf];
// 如果 arena 是排在最后的包含 nf 个空闲 pool 的 arena,
// 需要将 nfp2lasta[nf] 置为 arena 的前驱结点或 NULL
if (lastnf == ao) { /* it is the rightmost */
struct arena_object* p = ao->prevarena;
nfp2lasta[nf] = (p != NULL && p->nfreepools == nf) ? p : NULL;
}
ao->nfreepools = ++nf;
// 如果 pool 释放后 arena 变成完全空闲状态,并且系统中还有其他可用 arena,
// 需要将 arena 从 usable_arenas 中移除并调用 free() 函数将其释放归还给操作系统
if (nf == ao->ntotalpools && ao->nextarena != NULL) {
if (ao->prevarena == NULL) {
usable_arenas = ao->nextarena;
}
else {
ao->prevarena->nextarena = ao->nextarena;
}
if (ao->nextarena != NULL) {
ao->nextarena->prevarena = ao->prevarena;
}
ao->nextarena = unused_arena_objects;
unused_arena_objects = ao;
arena_map_mark_used(ao->address, 0);
_PyObject_Arena.free(_PyObject_Arena.ctx, (void *)ao->address, ARENA_SIZE);
ao->address = 0;
--narenas_currently_allocated;
return;
}
// 如果 pool 释放后 arena 从满变成可用,需要将其置为 usable_arenas 头结点,
// 因为 arena 空闲 pool 数量为 1,作为头结点不会破坏 usable_arenas 有序性
if (nf == 1) {
ao->nextarena = usable_arenas;
ao->prevarena = NULL;
if (usable_arenas)
usable_arenas->prevarena = ao;
usable_arenas = ao;
if (nfp2lasta[1] == NULL) {
nfp2lasta[1] = ao;
}
return;
}
if (nfp2lasta[nf] == NULL) {
nfp2lasta[nf] = ao;
}
// 如果 arena 本来就是包含 lastnf 个空闲 pool 的最后一个,现在空闲 pool 数量加 1,
// 整个 usable_arenas 还是有序的
if (ao == lastnf) {
return;
}
// arena->nfreepools 的增加导致 usable_arenas 失序,
// 重新调整 arena 在 usable_arenas 的位置
if (ao->prevarena != NULL) {
ao->prevarena->nextarena = ao->nextarena;
}
else {
usable_arenas = ao->nextarena;
}
ao->nextarena->prevarena = ao->prevarena;
ao->prevarena = lastnf;
ao->nextarena = lastnf->nextarena;
if (ao->nextarena != NULL) {
ao->nextarena->prevarena = ao;
}
lastnf->nextarena = ao;
}首先将这个空闲的 pool 置为 ao->freepools 的头结点,这样可以保证最后释放的 pool 会最先被使用,提高访存效率,因为之前释放的 pool 可能被置换出了物理内存。然后根据不同情况更新 nfp2lasta,便于后续维护 usable_arenas 的有序性。接着根据 pool 释放前后其所在 arena 状态的变化做不同操作。
如果 arena 由可用状态变成空闲状态,并且系统中还有其他可用 arena,就调用 free() 将 arena 释放掉归还给操作系统。不释放唯一空闲 arena,以避免内存抖动。
如果 arena 由不可用状态(所有 pool 都分配了)变成可用状态,将其置为 usable_arenas 的头结点。
如果 pool 释放前后 arena 都是可用状态,也就是一直都在 usable_arenas 链表中,如果其可用 pool 数量的增加导致 usable_arenas 链表失序,需要移动 arena 到合适位置来保持 usable_arenas 的有序性。


 Pool
Pool
