
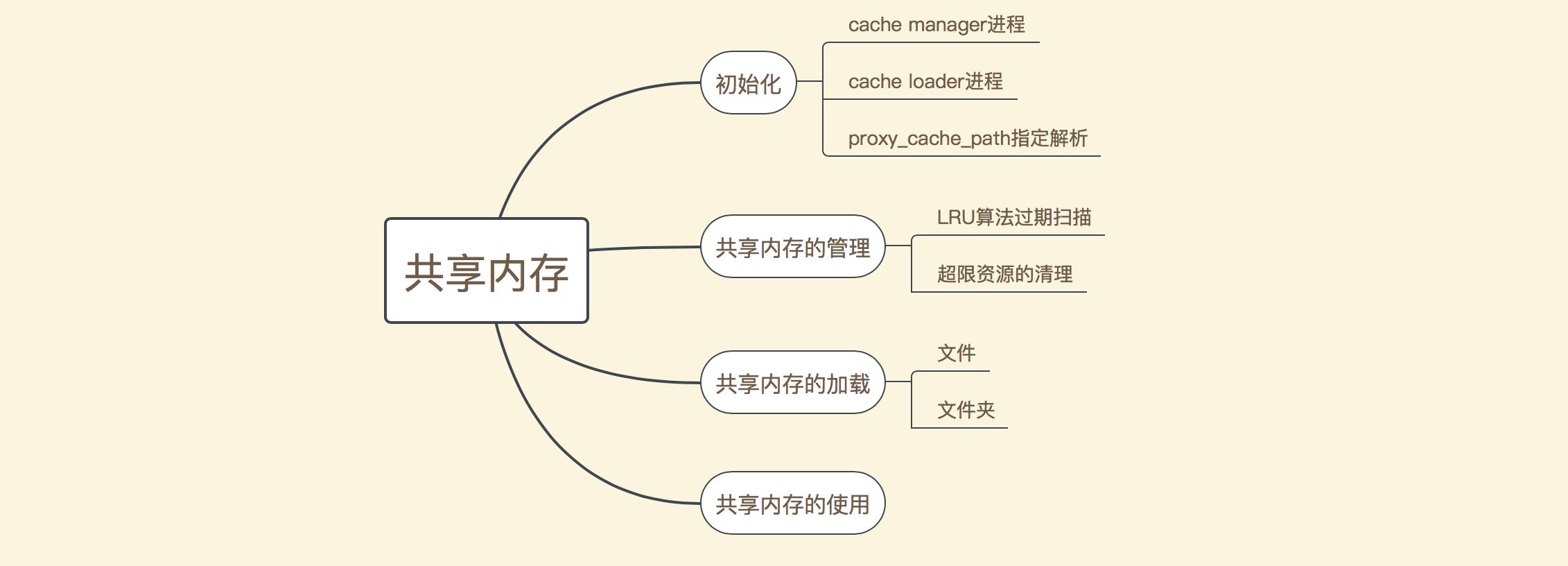
Maison >Opération et maintenance >Nginx >Analyse des exemples de mécanismes de mémoire partagée nginx
Analyse des exemples de mécanismes de mémoire partagée nginx

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-22 17:13:141651parcourir
1. Exemple d'utilisation
L'instruction nginx pour déclarer la mémoire partagée est :
proxy_cache_path /users/mike/nginx-cache levels=1:2 keys_zone=one:10m max_size=10g inactive=60m use_temp_path=off;
Ceci n'est qu'une déclaration Le nom en est un et la mémoire maximale disponible est de 10 g de mémoire partagée. La signification de chaque paramètre ici est la suivante :
/users/mike/nginx-cache : Il s'agit d'un paramètre de chemin qui spécifie le stockage des fichiers mis en cache dans la mémoire partagée. . Emplacement. La raison pour laquelle un fichier est généré ici est que pour la réponse du service en amont, un fichier peut être généré et stocké sur nginx. S'il y a une demande ultérieure pour celui-ci, le fichier peut être lu directement ou lu à partir de la mémoire partagée. . Mise en cache pour répondre au client ;
levels : Dans le système d'exploitation Linux, si tous les fichiers sont placés dans un dossier, alors lorsque le nombre de fichiers est très important. , Peut-être qu'un lecteur de disque ne peut pas lire autant de fichiers s'ils sont placés dans plusieurs dossiers, vous pouvez profiter de plusieurs lecteurs et les lire. Le paramètre niveaux spécifie ici comment générer le dossier. Supposons que le nom de fichier généré par nginx pour certaines données de réponse du service en amont est e0bd86606797639426a92306b1b98ad9. Ensuite, pour les niveaux ci-dessus = 1:2, il commencera à la fin du nom de fichier, en prenant 1 bit (c'est-à-dire 9). comme nom de premier niveau du sous-répertoire, puis prenez 2 chiffres (c'est-à-dire ad) comme nom de sous-répertoire secondaire : ce paramètre spécifie le nom du partage actuel. mémoire, en voici une, les 10 min suivants indiquent que la taille de la mémoire partagée actuelle utilisée pour stocker les clés est de 10 m
max_size : Ce paramètre spécifie la mémoire maximale ; disponible pour la mémoire partagée actuelle ; # 🎜🎜#
- inactive : Ce paramètre spécifie la durée de survie maximale de la mémoire partagée actuelle s'il n'y a pas de demande d'accès aux données de la mémoire pendant cette période. période, ce sera L'algorithme lru est éliminé
- Ce paramètre est défini sur use_temp_path pour contrôler si le fichier généré est d'abord stocké dans un dossier temporaire puis déplacé vers le répertoire spécifié#🎜🎜 #
- 2. Principe de fonctionnement
3. Interprétation du code source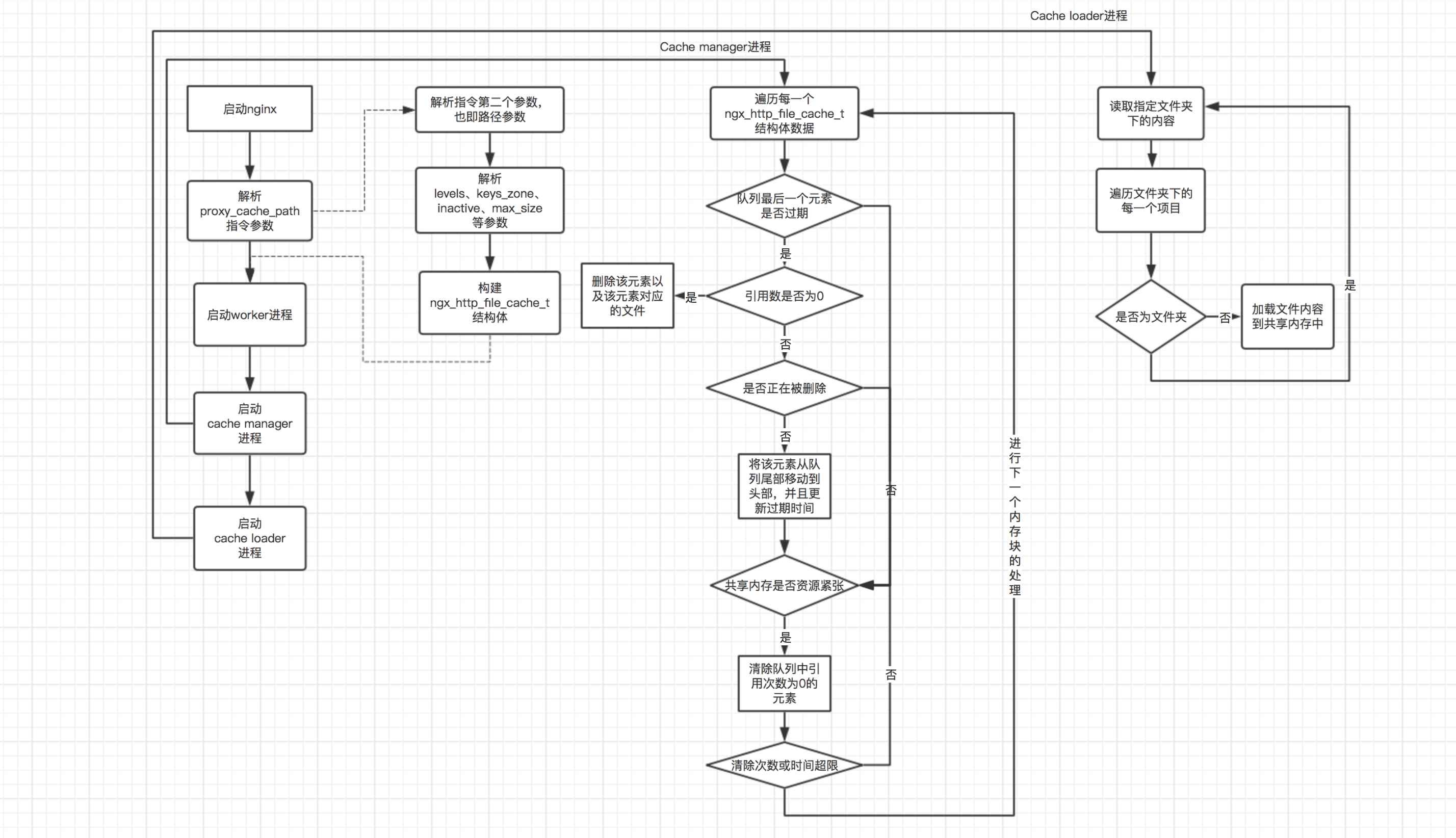
3.1 Analyse de la directive proxy_cache_path# 🎜 🎜#
Pour l'analyse de chaque instruction de nginx, il définira une structure ngx_command_t dans le module correspondant. Il existe une méthode set dans la structure qui spécifie la méthode utilisée pour analyser. la méthode d’enseignement actuelle. Voici la définition de la structure ngx_command_t correspondant à proxy_cache_path :
static ngx_command_t ngx_http_proxy_commands[] = {
{ ngx_string("proxy_cache_path"), // 指定了当前指令的名称
// 指定了当前指令的使用位置,即http模块,并且指定了当前模块的参数个数,这里是必须大于等于2
ngx_http_main_conf|ngx_conf_2more,
// 指定了set()方法所指向的方法
ngx_http_file_cache_set_slot,
ngx_http_main_conf_offset,
offsetof(ngx_http_proxy_main_conf_t, caches),
&ngx_http_proxy_module }
}Comme vous pouvez le voir, la méthode d'analyse utilisée par cette instruction est ngx_http_file_cache_set_slot(). Ici, nous lisons directement le code source de cette méthode : char *ngx_http_file_cache_set_slot(ngx_conf_t *cf, ngx_command_t *cmd, void *conf)
{
char *confp = conf;
off_t max_size;
u_char *last, *p;
time_t inactive;
ssize_t size;
ngx_str_t s, name, *value;
ngx_int_t loader_files, manager_files;
ngx_msec_t loader_sleep, manager_sleep, loader_threshold,
manager_threshold;
ngx_uint_t i, n, use_temp_path;
ngx_array_t *caches;
ngx_http_file_cache_t *cache, **ce;
cache = ngx_pcalloc(cf->pool, sizeof(ngx_http_file_cache_t));
if (cache == null) {
return ngx_conf_error;
}
cache->path = ngx_pcalloc(cf->pool, sizeof(ngx_path_t));
if (cache->path == null) {
return ngx_conf_error;
}
// 初始化各个属性的默认值
use_temp_path = 1;
inactive = 600;
loader_files = 100;
loader_sleep = 50;
loader_threshold = 200;
manager_files = 100;
manager_sleep = 50;
manager_threshold = 200;
name.len = 0;
size = 0;
max_size = ngx_max_off_t_value;
// 示例配置:proxy_cache_path /users/mike/nginx-cache levels=1:2 keys_zone=one:10m max_size=10g inactive=60m use_temp_path=off;
// 这里的cf->args->elts中存储了解析proxy_cache_path指令时,其包含的各个token项,
// 所谓的token项,指的就是使用空格分隔的字符片段
value = cf->args->elts;
// value[1]就是配置的第一个参数,也即cache文件会保存的根路径
cache->path->name = value[1];
if (cache->path->name.data[cache->path->name.len - 1] == '/') {
cache->path->name.len--;
}
if (ngx_conf_full_name(cf->cycle, &cache->path->name, 0) != ngx_ok) {
return ngx_conf_error;
}
// 从第三个参数开始进行解析
for (i = 2; i < cf->args->nelts; i++) {
// 如果第三个参数是以"levels="开头,则解析levels子参数
if (ngx_strncmp(value[i].data, "levels=", 7) == 0) {
p = value[i].data + 7; // 计算开始解析的其实位置
last = value[i].data + value[i].len; // 计算最后一个字符的位置
// 开始解析1:2
for (n = 0; n < ngx_max_path_level && p < last; n++) {
if (*p > '0' && *p < '3') {
// 获取当前的参数值,比如需要解析的1和2
cache->path->level[n] = *p++ - '0';
cache->path->len += cache->path->level[n] + 1;
if (p == last) {
break;
}
// 如果当前字符是冒号,则继续下一个字符的解析;
// 这里的ngx_max_path_level值为3,也就是说levels参数后最多接3级子目录
if (*p++ == ':' && n < ngx_max_path_level - 1 && p < last) {
continue;
}
goto invalid_levels;
}
goto invalid_levels;
}
if (cache->path->len < 10 + ngx_max_path_level) {
continue;
}
invalid_levels:
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid \"levels\" \"%v\"", &value[i]);
return ngx_conf_error;
}
// 如果当前的参数是以"use_temp_path="开头,则解析use_temp_path参数,该参数值为on或者off,
// 表示当前缓存文件是否首先存入临时文件夹中,最后再写入到目标文件夹中,如果为off则直接存入目标文件夹
if (ngx_strncmp(value[i].data, "use_temp_path=", 14) == 0) {
// 如果为on,则标记use_temp_path为1
if (ngx_strcmp(&value[i].data[14], "on") == 0) {
use_temp_path = 1;
// 如果为off,则标记use_temp_path为0
} else if (ngx_strcmp(&value[i].data[14], "off") == 0) {
use_temp_path = 0;
// 如果都不止,则返回解析异常
} else {
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid use_temp_path value \"%v\", "
"it must be \"on\" or \"off\"",
&value[i]);
return ngx_conf_error;
}
continue;
}
// 如果参数是以"keys_zone="开头,则解析keys_zone参数。该参数的形式如keys_zone=one:10m,
// 这里的one是一个名称,以供给后续的location配置使用,而10m则是一个大小,
// 表示供给存储key的缓存大小
if (ngx_strncmp(value[i].data, "keys_zone=", 10) == 0) {
name.data = value[i].data + 10;
p = (u_char *) ngx_strchr(name.data, ':');
if (p) {
// 计算name的长度,name记录了当前的缓存区的名称,也即这里的one
name.len = p - name.data;
p++;
// 解析所指定的size大小
s.len = value[i].data + value[i].len - p;
s.data = p;
// 对大小进行解析,会将指定的大小最终转换为字节数,这里的字节数必须大于8191
size = ngx_parse_size(&s);
if (size > 8191) {
continue;
}
}
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid keys zone size \"%v\"", &value[i]);
return ngx_conf_error;
}
// 如果参数是以"inactive="开头,则解析inactive参数。该参数的形式如inactive=60m,
// 表示缓存的文件在多长时间没有访问之后将会过期
if (ngx_strncmp(value[i].data, "inactive=", 9) == 0) {
s.len = value[i].len - 9;
s.data = value[i].data + 9;
// 对时间进行解析,最终将转换为以秒为单位的时间长度
inactive = ngx_parse_time(&s, 1);
if (inactive == (time_t) ngx_error) {
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid inactive value \"%v\"", &value[i]);
return ngx_conf_error;
}
continue;
}
// 如果参数是以"max_size="开头,则解析max_size参数。该参数的形式如max_size=10g,
// 表示当前缓存能够使用的最大内存空间
if (ngx_strncmp(value[i].data, "max_size=", 9) == 0) {
s.len = value[i].len - 9;
s.data = value[i].data + 9;
// 对解析得到的值进行转换,最终将以字节数为单位
max_size = ngx_parse_offset(&s);
if (max_size < 0) {
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid max_size value \"%v\"", &value[i]);
return ngx_conf_error;
}
continue;
}
// 如果参数是以"loader_files="开头,则解析loader_files参数。该参数形如loader_files=100,
// 表示在启动nginx的时候默认会加载多少个缓存目录中的文件到缓存中
if (ngx_strncmp(value[i].data, "loader_files=", 13) == 0) {
// 解析loader_files参数的值
loader_files = ngx_atoi(value[i].data + 13, value[i].len - 13);
if (loader_files == ngx_error) {
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid loader_files value \"%v\"", &value[i]);
return ngx_conf_error;
}
continue;
}
// 如果参数是以"loader_sleep="开头,则解析loader_sleep参数。该参数形如loader_sleep=10s,
// 表示每次加载一个文件之后休眠多长时间,然后再加载下一个文件
if (ngx_strncmp(value[i].data, "loader_sleep=", 13) == 0) {
s.len = value[i].len - 13;
s.data = value[i].data + 13;
// 对loader_sleep的值进行转换,这里是以毫秒数为单位
loader_sleep = ngx_parse_time(&s, 0);
if (loader_sleep == (ngx_msec_t) ngx_error) {
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid loader_sleep value \"%v\"", &value[i]);
return ngx_conf_error;
}
continue;
}
// 如果参数是以"loader_threshold="开头,则解析loader_threshold参数,该参数形如loader_threshold=10s,
// 表示每次加载一个文件能够使用的最长时间
if (ngx_strncmp(value[i].data, "loader_threshold=", 17) == 0) {
s.len = value[i].len - 17;
s.data = value[i].data + 17;
// 对loader_threshold的值进行解析并且转换,最终是以毫秒数为单位
loader_threshold = ngx_parse_time(&s, 0);
if (loader_threshold == (ngx_msec_t) ngx_error) {
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid loader_threshold value \"%v\"", &value[i]);
return ngx_conf_error;
}
continue;
}
// 如果参数是以"manager_files="开头,则解析manager_files参数,该参数形如manager_files=100,
// 表示当缓存空间用尽时,将会以lru算法将文件进行删除,不过每次迭代最多删除manager_files所指定的文件数
if (ngx_strncmp(value[i].data, "manager_files=", 14) == 0) {
// 解析manager_files参数值
manager_files = ngx_atoi(value[i].data + 14, value[i].len - 14);
if (manager_files == ngx_error) {
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid manager_files value \"%v\"", &value[i]);
return ngx_conf_error;
}
continue;
}
// 如果参数是以"manager_sleep="开头,则解析manager_sleep参数,该参数形如manager_sleep=1s,
// 表示每次迭代完成之后将会休眠manager_sleep参数所指定的时长
if (ngx_strncmp(value[i].data, "manager_sleep=", 14) == 0) {
s.len = value[i].len - 14;
s.data = value[i].data + 14;
// 对manager_sleep所指定的值进行解析
manager_sleep = ngx_parse_time(&s, 0);
if (manager_sleep == (ngx_msec_t) ngx_error) {
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid manager_sleep value \"%v\"", &value[i]);
return ngx_conf_error;
}
continue;
}
// 如果参数是以"manager_threshold="开头,则解析manager_threshold参数,该参数形如manager_threshold=2s,
// 表示每次清除文件的迭代的最长耗时不能超过该参数所指定的值
if (ngx_strncmp(value[i].data, "manager_threshold=", 18) == 0) {
s.len = value[i].len - 18;
s.data = value[i].data + 18;
// 解析manager_threshold参数值,并且将其转换为以毫秒数为单位的值
manager_threshold = ngx_parse_time(&s, 0);
if (manager_threshold == (ngx_msec_t) ngx_error) {
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid manager_threshold value \"%v\"", &value[i]);
return ngx_conf_error;
}
continue;
}
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"invalid parameter \"%v\"", &value[i]);
return ngx_conf_error;
}
if (name.len == 0 || size == 0) {
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"\"%v\" must have \"keys_zone\" parameter",
&cmd->name);
return ngx_conf_error;
}
// 这里的cache->path->manager和cache->path->loader的值为两个函数,需要注意的是,
// 在nginx启动之后,会启动两个单独的进程,一个cache manager,一个cache loader,其中cache manager
// 将会在一个循环中不断的为每个共享内存执行cache->path->manager所指定的方法,
// 从而实现对缓存进行清理。而另一个进程cache loader则会在nginx启动之后60s的时候只执行一次,
// 执行的方法就是cache->path->loader所指定的方法,
// 该方法的主要作用是加载已经存在的文件数据到当前的共享内存中
cache->path->manager = ngx_http_file_cache_manager;
cache->path->loader = ngx_http_file_cache_loader;
cache->path->data = cache;
cache->path->conf_file = cf->conf_file->file.name.data;
cache->path->line = cf->conf_file->line;
cache->loader_files = loader_files;
cache->loader_sleep = loader_sleep;
cache->loader_threshold = loader_threshold;
cache->manager_files = manager_files;
cache->manager_sleep = manager_sleep;
cache->manager_threshold = manager_threshold;
// 将当前的path添加到cycle中,后续会对这些path进行检查,如果path不存在,则会创建相应的路径
if (ngx_add_path(cf, &cache->path) != ngx_ok) {
return ngx_conf_error;
}
// 把当前共享内存添加到cf->cycle->shared_memory所指定的共享内存列表中
cache->shm_zone = ngx_shared_memory_add(cf, &name, size, cmd->post);
if (cache->shm_zone == null) {
return ngx_conf_error;
}
if (cache->shm_zone->data) {
ngx_conf_log_error(ngx_log_emerg, cf, 0,
"duplicate zone \"%v\"", &name);
return ngx_conf_error;
}
// 这里指定了每个共享内存的初始化方法,该方法在master进程启动的时候会被执行
cache->shm_zone->init = ngx_http_file_cache_init;
cache->shm_zone->data = cache;
cache->use_temp_path = use_temp_path;
cache->inactive = inactive;
cache->max_size = max_size;
caches = (ngx_array_t *) (confp + cmd->offset);
ce = ngx_array_push(caches);
if (ce == null) {
return ngx_conf_error;
}
*ce = cache;
return ngx_conf_ok;
} Comme le montre le code ci-dessus, dans la méthode proxy_cache_path, une structure ngx_http_file_cache_t est principalement initialisée. Chaque attribut de la structure est déterminé en analysant chaque paramètre de proxy_cache_path.
3.2 Démarrage des processus du gestionnaire de cache et du chargeur de cache
nginx程序的入口方法是nginx.c的main()方法,如果开启了master-worker进程模式,那么最后就会进入ngx_master_process_cycle()方法,该方法首先会启动worker进程,以接收客户端的请求;然后会分别启动cache manager和cache loader进程;最后进入一个无限循环中,以处理用户在命令行向nginx发送的指令。如下是cache manager和cache loader进程启动的源码:
void
ngx_master_process_cycle(ngx_cycle_t *cycle)
{
...
// 获取核心模块的配置
ccf = (ngx_core_conf_t *) ngx_get_conf(cycle->conf_ctx, ngx_core_module);
// 启动各个worker进程
ngx_start_worker_processes(cycle, ccf->worker_processes, ngx_process_respawn);
// 启动cache进程
ngx_start_cache_manager_processes(cycle, 0);
...
}对于cache manager和cache loader进程的启动,可以看到,其主要是在ngx_start_cache_manager_processes()方法中,如下是该方法的源码:
static void ngx_start_cache_manager_processes(ngx_cycle_t *cycle, ngx_uint_t respawn) {
ngx_uint_t i, manager, loader;
ngx_path_t **path;
ngx_channel_t ch;
manager = 0;
loader = 0;
path = ngx_cycle->paths.elts;
for (i = 0; i < ngx_cycle->paths.nelts; i++) {
// 查找是否有任何一个path指定了manager为1
if (path[i]->manager) {
manager = 1;
}
// 查找是否有任何一个path指定了loader为1
if (path[i]->loader) {
loader = 1;
}
}
// 如果没有任何一个path的manager指定为1,则直接返回
if (manager == 0) {
return;
}
// 创建一个进程以执行ngx_cache_manager_process_cycle()方法中所执行的循环,需要注意的是,
// 在回调ngx_cache_manager_process_cycle方法时,这里传入的第二个参数是ngx_cache_manager_ctx
ngx_spawn_process(cycle, ngx_cache_manager_process_cycle,
&ngx_cache_manager_ctx, "cache manager process",
respawn ? ngx_process_just_respawn : ngx_process_respawn);
ngx_memzero(&ch, sizeof(ngx_channel_t));
// 创建一个ch结构体,以将当前进程的创建消息广播出去
ch.command = ngx_cmd_open_channel;
ch.pid = ngx_processes[ngx_process_slot].pid;
ch.slot = ngx_process_slot;
ch.fd = ngx_processes[ngx_process_slot].channel[0];
// 广播cache manager process进程被创建的消息
ngx_pass_open_channel(cycle, &ch);
if (loader == 0) {
return;
}
// 创建一个进程以执行ngx_cache_manager_process_cycle()所指定的流程,需要注意的是,
// 在回调ngx_cache_manager_process_cycle方法时,这里传入的第二个参数是ngx_cache_loader_ctx
ngx_spawn_process(cycle, ngx_cache_manager_process_cycle,
&ngx_cache_loader_ctx, "cache loader process",
respawn ? ngx_process_just_spawn : ngx_process_norespawn);
// 创建一个ch结构体,以将当前进程的创建消息广播出去
ch.command = ngx_cmd_open_channel;
ch.pid = ngx_processes[ngx_process_slot].pid;
ch.slot = ngx_process_slot;
ch.fd = ngx_processes[ngx_process_slot].channel[0];
// 广播cache loader process进程被创建的消息
ngx_pass_open_channel(cycle, &ch);
}上面的代码其实比较简单,首先检查是否有任何一个路径指定了使用cache manager或者cache loader,如果有,则启动对应的继承,否则是不会创建cache manager和cache loader进程的。而启动这两个进程所使用的方法都是:
// 启动cache manager进程
ngx_spawn_process(cycle, ngx_cache_manager_process_cycle,
&ngx_cache_manager_ctx, "cache manager process",
respawn ? ngx_process_just_respawn : ngx_process_respawn);
// 启动cache loader进程
ngx_spawn_process(cycle, ngx_cache_manager_process_cycle,
&ngx_cache_loader_ctx, "cache loader process",
respawn ? ngx_process_just_spawn : ngx_process_norespawn);这里的ngx_spawn_process()方法的作用主要是创建一个新的进程,该进程创建之后就会执行第二个参数所指定的方法,并且执行该方法时传入的参数是这里第三个参数所指定的结构体对象。观察上面两个启动进程的方式,其在新进程创建之后所执行的方法都是ngx_cache_manager_process_cycle(),只不过调用该方法时传入的参数不一样,一个是ngx_cache_manager_ctx,另一个则是ngx_cache_loader_ctx。这里我们首先看一下这两个结构体的定义:
// 这里的ngx_cache_manager_process_handler指定了当前cache manager进程将会执行的方法,
// cache manager process则指定了该进程的名称,而最后的0表示当前进程在启动之后间隔多长时间才会执行
// ngx_cache_manager_process_handler()方法,这里是立即执行
static ngx_cache_manager_ctx_t ngx_cache_manager_ctx = {
ngx_cache_manager_process_handler, "cache manager process", 0
};
// 这里的ngx_cache_loader_process_handler指定了当前cache loader进程将会执行的方法,
// 其会在cache loader进程启动后60秒之后才会执行ngx_cache_loader_process_handler()方法
static ngx_cache_manager_ctx_t ngx_cache_loader_ctx = {
ngx_cache_loader_process_handler, "cache loader process", 60000
};可以看到,这两个结构体主要是分别定义了cache manager和cache loader两个进程的不同行为。下面我们来看一下ngx_cache_manager_process_cycle()方法是如何调用这两个方法的:
static void ngx_cache_manager_process_cycle(ngx_cycle_t *cycle, void *data) {
ngx_cache_manager_ctx_t *ctx = data;
void *ident[4];
ngx_event_t ev;
ngx_process = ngx_process_helper;
// 当前进程主要是用于处理cache manager和cache loader工作的,因而其不需要进行socket的监听,因而这里需要将其关闭
ngx_close_listening_sockets(cycle);
/* set a moderate number of connections for a helper process. */
cycle->connection_n = 512;
// 对当前的进程进行初始化,主要是设置一些参数属性,并且在最后为当前进行设置监听channel[1]句柄的事件,从而接收master进程的消息
ngx_worker_process_init(cycle, -1);
ngx_memzero(&ev, sizeof(ngx_event_t));
// 对于cache manager,这里的handler指向的是ngx_cache_manager_process_handler()方法,
// 对于cache loader,这里的handler指向的是ngx_cache_loader_process_handler()方法
ev.handler = ctx->handler;
ev.data = ident;
ev.log = cycle->log;
ident[3] = (void *) -1;
// cache模块不需要使用共享锁
ngx_use_accept_mutex = 0;
ngx_setproctitle(ctx->name);
// 把当前事件添加到事件队列中,事件的延迟时间为ctx->delay,对于cache manager,该值为0,
// 而对于cache loader,该值为60s。
// 需要注意的是,在当前事件的处理方法中,ngx_cache_manager_process_handler()如果处理完了当前事件,
// 会将当前事件再次添加到事件队列中,从而实现定时处理的功能;而对于
// ngx_cache_loader_process_handler()方法,其处理完一次之后,并不会将当前事件
// 再次添加到事件队列中,因而相当于当前事件只会执行一次,然后cache loader进程就会退出
ngx_add_timer(&ev, ctx->delay);
for ( ;; ) {
// 如果master将当前进程标记为terminate或者quit状态,则退出进程
if (ngx_terminate || ngx_quit) {
ngx_log_error(ngx_log_notice, cycle->log, 0, "exiting");
exit(0);
}
// 如果master进程发出了reopen消息,则重新打开所有的缓存文件
if (ngx_reopen) {
ngx_reopen = 0;
ngx_log_error(ngx_log_notice, cycle->log, 0, "reopening logs");
ngx_reopen_files(cycle, -1);
}
// 执行事件队列中的事件
ngx_process_events_and_timers(cycle);
}
}上面的代码中,首先创建了一个事件对象,ev.handler = ctx->handler;指定了该事件所需要处理的逻辑,也即上面两个结构体中的第一个参数所对应的方法;然后将该事件添加到事件队列中,即ngx_add_timer(&ev, ctx->delay);,需要注意的是,这里的第二个参数就是上面两个结构体中所指定的第三个参数,也就是说这里是以事件的延迟时间的方式来控制hander()方法的执行时间的;最后,在一个无限for循环中,通过ngx_process_events_and_timers()方法来不断检查事件队列的事件,并且处理事件。
3.3 cache manager进程处理逻辑
对于cache manager处理的流程,通过上面的讲解可以看出,其是在其所定义的cache manager结构体中的ngx_cache_manager_process_handler()方法中进行的。如下是该方法的源码:
static void ngx_cache_manager_process_handler(ngx_event_t *ev) {
ngx_uint_t i;
ngx_msec_t next, n;
ngx_path_t **path;
next = 60 * 60 * 1000;
path = ngx_cycle->paths.elts;
for (i = 0; i < ngx_cycle->paths.nelts; i++) {
// 这里的manager方法指向的是ngx_http_file_cache_manager()方法
if (path[i]->manager) {
n = path[i]->manager(path[i]->data);
next = (n <= next) ? n : next;
ngx_time_update();
}
}
if (next == 0) {
next = 1;
}
// 一次处理结束之后还会将当前事件再次添加到事件队列中而进行下一次的处理
ngx_add_timer(ev, next);
}这里首先会获取所有的路径定义,然后检查其manager()方法是否为空,如果不会空,则调用该方法。这里的manager()方法所指向的实际方法就是在前面3.1节中对proxy_cache_path指令进行解析中进行定义的,也即cache->path->manager = ngx_http_file_cache_manager;,也就是说该方法是管理cache的主要方法。在调用完了管理方法之后,接下来会继续将当前的事件添加到事件队列中,以进行下一次cache管理循环。如下是ngx_http_file_cache_manager()方法的源码:
static ngx_msec_t ngx_http_file_cache_manager(void *data) {
// 这里的ngx_http_file_cache_t结构体是解析proxy_cache_path配置项得到的
ngx_http_file_cache_t *cache = data;
off_t size;
time_t wait;
ngx_msec_t elapsed, next;
ngx_uint_t count, watermark;
cache->last = ngx_current_msec;
cache->files = 0;
// 这里的ngx_http_file_cache_expire()方法在一个无限循环中,不断检查缓存队列尾部是否有过期的
// 共享内存,如果存在,则将其以及其所对应的文件进行删除
next = (ngx_msec_t) ngx_http_file_cache_expire(cache) * 1000;
// next是ngx_http_file_cache_expire()方法的返回值,该方法只有在两种情况下才会返回0:
// 1. 当删除的文件个数超过了manager_files指定的文件个数时;
// 2. 当删除各个文件的总耗时超过了manager_threshold所指定的总时长时;
// 如果next为0,则说明完成了一个批次的缓存清理工作,此时是需要休眠一段时间然后再进行下一次的清理工作,
// 这个休眠的时长就是manager_sleep所指定的值。也就是说这里的next的值实际上就是下一次
// 执行缓存清理工作的等待时长
if (next == 0) {
next = cache->manager_sleep;
goto done;
}
for ( ;; ) {
ngx_shmtx_lock(&cache->shpool->mutex);
// 这里的size指的是当前缓存所使用的总大小
// count指定了当前缓存中的文件个数
// watermark则表示水位,其为总共能够存储的文件个数的7/8
size = cache->sh->size;
count = cache->sh->count;
watermark = cache->sh->watermark;
ngx_shmtx_unlock(&cache->shpool->mutex);
ngx_log_debug3(ngx_log_debug_http, ngx_cycle->log, 0,
"http file cache size: %o c:%ui w:%i",
size, count, (ngx_int_t) watermark);
// 如果当前的缓存所使用的内存大小小于能够使用的最大大小并且缓存文件个数小于水位,
// 说明还可以继续存储缓存文件,则跳出循环
if (size < cache->max_size && count < watermark) {
break;
}
// 走到这里说明共享内存可用资源不足
// 这里主要是强制删除当前队列中未被引用的文件,无论其是否过期
wait = ngx_http_file_cache_forced_expire(cache);
// 计算下次执行的时间
if (wait > 0) {
next = (ngx_msec_t) wait * 1000;
break;
}
// 如果当前nginx已经退出或者终止,则跳出循环
if (ngx_quit || ngx_terminate) {
break;
}
// 如果当前删除的文件个数超过了manager_files所指定的个数,则跳出循环,
// 并且指定距离下次清理工作所需要休眠的时间
if (++cache->files >= cache->manager_files) {
next = cache->manager_sleep;
break;
}
ngx_time_update();
elapsed = ngx_abs((ngx_msec_int_t) (ngx_current_msec - cache->last));
// 如果当前删除动作的耗时超过了manager_threshold所指定的时长,则跳出循环,
// 并且指定距离下次清理工作所需要休眠的时间
if (elapsed >= cache->manager_threshold) {
next = cache->manager_sleep;
break;
}
}
done:
elapsed = ngx_abs((ngx_msec_int_t) (ngx_current_msec - cache->last));
ngx_log_debug3(ngx_log_debug_http, ngx_cycle->log, 0,
"http file cache manager: %ui e:%m n:%m",
cache->files, elapsed, next);
return next;
}在ngx_http_file_cache_manager()方法中,首先会进入ngx_http_file_cache_expire()方法,该方法的主要作用是检查当前共享内存队列尾部的元素是否过期,如果过期,则根据其引用次数和是否正在被删除而判断是否需要将该元素以及该元素对应的磁盘文件进行删除。在进行这个检查之后,然后会进入一个无限for循环,这里循环的主要目的是检查当前的共享内存是否资源比较紧张,也即是否所使用的内存超过了max_size定义的最大内存,或者是当前所缓存的文件总数超过了总文件数的7/8。如果这两个条件有一个达到了,就会尝试进行强制清除缓存文件,所谓的强制清除就是删除当前共享内存中所有被引用数为0的元素及其对应的磁盘文件。这里我们首先阅读ngx_http_file_cache_expire()方法:
static time_t ngx_http_file_cache_expire(ngx_http_file_cache_t *cache) {
u_char *name, *p;
size_t len;
time_t now, wait;
ngx_path_t *path;
ngx_msec_t elapsed;
ngx_queue_t *q;
ngx_http_file_cache_node_t *fcn;
u_char key[2 * ngx_http_cache_key_len];
ngx_log_debug0(ngx_log_debug_http, ngx_cycle->log, 0,
"http file cache expire");
path = cache->path;
len = path->name.len + 1 + path->len + 2 * ngx_http_cache_key_len;
name = ngx_alloc(len + 1, ngx_cycle->log);
if (name == null) {
return 10;
}
ngx_memcpy(name, path->name.data, path->name.len);
now = ngx_time();
ngx_shmtx_lock(&cache->shpool->mutex);
for ( ;; ) {
// 如果当前nginx已经退出了,或者终止了,则跳出当前循环
if (ngx_quit || ngx_terminate) {
wait = 1;
break;
}
// 如果当前的共享内存队列为空的,则跳出当前循环
if (ngx_queue_empty(&cache->sh->queue)) {
wait = 10;
break;
}
// 获取队列的最后一个元素
q = ngx_queue_last(&cache->sh->queue);
// 获取队列的节点
fcn = ngx_queue_data(q, ngx_http_file_cache_node_t, queue);
// 计算节点的过期时间距离当前时间的时长
wait = fcn->expire - now;
// 如果当前节点没有过期,则退出当前循环
if (wait > 0) {
wait = wait > 10 ? 10 : wait;
break;
}
ngx_log_debug6(ngx_log_debug_http, ngx_cycle->log, 0,
"http file cache expire: #%d %d %02xd%02xd%02xd%02xd",
fcn->count, fcn->exists,
fcn->key[0], fcn->key[1], fcn->key[2], fcn->key[3]);
// 这里的count表示当前的节点被引用的次数,如果其引用次数为0,则直接删除该节点
if (fcn->count == 0) {
// 这里的主要动作是将当前的节点从队列中移除,并且删除该节点对应的文件
ngx_http_file_cache_delete(cache, q, name);
goto next;
}
// 如果当前节点正在被删除,那么当前进程就可以不用对其进行处理
if (fcn->deleting) {
wait = 1;
break;
}
// 走到这里,说明当前节点已经过期了,但是引用数大于0,并且没有进程正在删除该节点
// 这里计算的是该节点进行hex计算后文件的名称
p = ngx_hex_dump(key, (u_char *) &fcn->node.key, sizeof(ngx_rbtree_key_t));
len = ngx_http_cache_key_len - sizeof(ngx_rbtree_key_t);
(void) ngx_hex_dump(p, fcn->key, len);
// 由于当前节点在时间上已经过期了,但是有请求正在引用该节点,并且没有进程正在删除该节点,
// 说明该节点应该被保留,因而这里尝试将该节点从队列尾部删除,并且为其重新计算下次的过期时间,
// 然后将其插入到队列头部
ngx_queue_remove(q);
fcn->expire = ngx_time() + cache->inactive;
ngx_queue_insert_head(&cache->sh->queue, &fcn->queue);
ngx_log_error(ngx_log_alert, ngx_cycle->log, 0,
"ignore long locked inactive cache entry %*s, count:%d",
(size_t) 2 * ngx_http_cache_key_len, key, fcn->count);
next: // 这里是队列中的最后一个节点被删除,并且对应的文件也被删除之后才会执行的逻辑
// 这里的cache->files记录了当前已经处理的节点数,manager_files的含义在于,
// 在进行lru算法强制清除文件时,最多会清除该参数所指定的文件个数,默认为100。
// 因而这里如果cache->files如果大于等于manager_files,则跳出循环
if (++cache->files >= cache->manager_files) {
wait = 0;
break;
}
// 更新当前nginx缓存的时间
ngx_time_update();
// elapsed等于当前删除动作的总耗时
elapsed = ngx_abs((ngx_msec_int_t) (ngx_current_msec - cache->last));
// 如果总耗时超过了manager_threshold所指定的值,则跳出当前循环
if (elapsed >= cache->manager_threshold) {
wait = 0;
break;
}
}
// 释放当前的锁
ngx_shmtx_unlock(&cache->shpool->mutex);
ngx_free(name);
return wait;
}可以看到,这里的主要处理逻辑是首先会火嘴队列尾部的元素,根据lru算法,队列尾部的元素是最有可能过期的元素,因而只需要检查该元素即可。然后检查该元素是否过期,如果没有过期,则退出当前方法,否则检查当前元素是否引用数为0,也就是说如果当前元素已经过期,并且引用数为0,则直接删除该元素及其对应的磁盘文件。如果当前元素引用数不为0,则会检查其是否正在被删除,需要注意的是,如果一个元素正在被删除,那么删除进程是会将其引用数置为1的,以防止其他的进程也进行删除操作。如果其正在被删除,则当前进程不会处理该元素,如果没有被删除,则当前进程会尝试将该元素从队列尾部移动到队列头部,这么做的主要原因在于,虽然元素已经过期,但是其引用数不为0,并且没有进程正在删除该元素,那么说明该元素还是一个活跃元素,因而需要将其移动到队列头部。
下面我们来看一下,当资源比较紧张时,cache manager是如何强制清除元素的,如下是ngx_http_file_cache_forced_expire()方法的源码:
static time_t ngx_http_file_cache_forced_expire(ngx_http_file_cache_t *cache) {
u_char *name;
size_t len;
time_t wait;
ngx_uint_t tries;
ngx_path_t *path;
ngx_queue_t *q;
ngx_http_file_cache_node_t *fcn;
ngx_log_debug0(ngx_log_debug_http, ngx_cycle->log, 0,
"http file cache forced expire");
path = cache->path;
len = path->name.len + 1 + path->len + 2 * ngx_http_cache_key_len;
name = ngx_alloc(len + 1, ngx_cycle->log);
if (name == null) {
return 10;
}
ngx_memcpy(name, path->name.data, path->name.len);
wait = 10;
tries = 20;
ngx_shmtx_lock(&cache->shpool->mutex);
// 不断遍历队列中的每个节点
for (q = ngx_queue_last(&cache->sh->queue);
q != ngx_queue_sentinel(&cache->sh->queue);
q = ngx_queue_prev(q))
{
// 获取当前节点的数据
fcn = ngx_queue_data(q, ngx_http_file_cache_node_t, queue);
ngx_log_debug6(ngx_log_debug_http, ngx_cycle->log, 0,
"http file cache forced expire: #%d %d %02xd%02xd%02xd%02xd",
fcn->count, fcn->exists,
fcn->key[0], fcn->key[1], fcn->key[2], fcn->key[3]);
// 如果当前节点的引用数为0,则直接删除该节点
if (fcn->count == 0) {
ngx_http_file_cache_delete(cache, q, name);
wait = 0;
} else {
// 进行下一个节点的尝试,如果有连续的20个节点的引用数都大于0,则会跳出当前循环
if (--tries) {
continue;
}
wait = 1;
}
break;
}
ngx_shmtx_unlock(&cache->shpool->mutex);
ngx_free(name);
return wait;
}可以看到,这里的处理逻辑比较简单,主要是从队列尾部开始往前依次检查队列中的元素的引用次数是否为0,如果为0,则直接删除,然后检查下一个元素。如果不为0,则检查下一个元素,如此往复。这里需要注意的是,如果检查总共有20次元素正在被引用过程中,则跳出当前循环。
3.4 cache loader进程处理逻辑
前面已经讲到,cache loader的主要处理流程在ngx_cache_loader_process_handler()方法中,如下是该方法的主要处理逻辑:
static void ngx_cache_loader_process_handler(ngx_event_t *ev)
{
ngx_uint_t i;
ngx_path_t **path;
ngx_cycle_t *cycle;
cycle = (ngx_cycle_t *) ngx_cycle;
path = cycle->paths.elts;
for (i = 0; i < cycle->paths.nelts; i++) {
if (ngx_terminate || ngx_quit) {
break;
}
// 这里的loader方法指向的是ngx_http_file_cache_loader()方法
if (path[i]->loader) {
path[i]->loader(path[i]->data);
ngx_time_update();
}
}
// 加载完成后退出当前流程
exit(0);
}这里cache loader与cache manager的处理主流程是非常相似的,主要是通过调用各个路径的loader()方法进行数据加载的,而loader()方法的具体实现方法也是在proxy_cache_path配置项解析的时候定义的,具体的定义如下(在3.1节最后一部分):
cache->path->loader = ngx_http_file_cache_loader;
这里我们继续阅读ngx_http_file_cache_loader()方法的源码:
static void ngx_http_file_cache_loader(void *data) {
ngx_http_file_cache_t *cache = data;
ngx_tree_ctx_t tree;
// 如果已经加载完成或者正在加载,则直接返回
if (!cache->sh->cold || cache->sh->loading) {
return;
}
// 尝试加锁
if (!ngx_atomic_cmp_set(&cache->sh->loading, 0, ngx_pid)) {
return;
}
ngx_log_debug0(ngx_log_debug_http, ngx_cycle->log, 0,
"http file cache loader");
// 这里的tree就是加载的一个主要流程对象,加载的过程是通过递归的方式进行的
tree.init_handler = null;
// 封装了加载单个文件的操作
tree.file_handler = ngx_http_file_cache_manage_file;
// 在加载一个目录之前的操作,这里主要是检查当前目录有没有操作权限
tree.pre_tree_handler = ngx_http_file_cache_manage_directory;
// 在加载一个目录之后的操作,这里实际上是一个空方法
tree.post_tree_handler = ngx_http_file_cache_noop;
// 这里主要是处理特殊文件,即既不是文件也不是文件夹的文件,这里主要是删除了该文件
tree.spec_handler = ngx_http_file_cache_delete_file;
tree.data = cache;
tree.alloc = 0;
tree.log = ngx_cycle->log;
cache->last = ngx_current_msec;
cache->files = 0;
// 开始通过递归的方式遍历指定目录下的所有文件,然后按照上面定义的方法对其进行处理,也即加载到共享内存中
if (ngx_walk_tree(&tree, &cache->path->name) == ngx_abort) {
cache->sh->loading = 0;
return;
}
// 标记加载状态
cache->sh->cold = 0;
cache->sh->loading = 0;
ngx_log_error(ngx_log_notice, ngx_cycle->log, 0,
"http file cache: %v %.3fm, bsize: %uz",
&cache->path->name,
((double) cache->sh->size * cache->bsize) / (1024 * 1024),
cache->bsize);
}在加载过程中,首先将目标加载目录封装到一个ngx_tree_ctx_t结构体中,并且为其指定加载文件所使用的方法。最终的加载逻辑主要是在ngx_walk_tree()方法中进行的,而整个加载过程也是通过递归来实现的。如下是ngx_walk_tree()方法的实现原理:
ngx_int_t ngx_walk_tree(ngx_tree_ctx_t *ctx, ngx_str_t *tree) {
void *data, *prev;
u_char *p, *name;
size_t len;
ngx_int_t rc;
ngx_err_t err;
ngx_str_t file, buf;
ngx_dir_t dir;
ngx_str_null(&buf);
ngx_log_debug1(ngx_log_debug_core, ctx->log, 0,
"walk tree \"%v\"", tree);
// 打开目标目录
if (ngx_open_dir(tree, &dir) == ngx_error) {
ngx_log_error(ngx_log_crit, ctx->log, ngx_errno,
ngx_open_dir_n " \"%s\" failed", tree->data);
return ngx_error;
}
prev = ctx->data;
// 这里传入的alloc是0,因而不会进入当前分支
if (ctx->alloc) {
data = ngx_alloc(ctx->alloc, ctx->log);
if (data == null) {
goto failed;
}
if (ctx->init_handler(data, prev) == ngx_abort) {
goto failed;
}
ctx->data = data;
} else {
data = null;
}
for ( ;; ) {
ngx_set_errno(0);
// 读取当前子目录中的内容
if (ngx_read_dir(&dir) == ngx_error) {
err = ngx_errno;
if (err == ngx_enomorefiles) {
rc = ngx_ok;
} else {
ngx_log_error(ngx_log_crit, ctx->log, err,
ngx_read_dir_n " \"%s\" failed", tree->data);
rc = ngx_error;
}
goto done;
}
len = ngx_de_namelen(&dir);
name = ngx_de_name(&dir);
ngx_log_debug2(ngx_log_debug_core, ctx->log, 0,
"tree name %uz:\"%s\"", len, name);
// 如果当前读取到的是.,则表示其为当前目录,跳过该目录
if (len == 1 && name[0] == '.') {
continue;
}
// 如果当前读取到的是..,则表示其为返回上一级目录的标识,跳过该目录
if (len == 2 && name[0] == '.' && name[1] == '.') {
continue;
}
file.len = tree->len + 1 + len;
// 更新可用的缓存大小
if (file.len + ngx_dir_mask_len > buf.len) {
if (buf.len) {
ngx_free(buf.data);
}
buf.len = tree->len + 1 + len + ngx_dir_mask_len;
buf.data = ngx_alloc(buf.len + 1, ctx->log);
if (buf.data == null) {
goto failed;
}
}
p = ngx_cpymem(buf.data, tree->data, tree->len);
*p++ = '/';
ngx_memcpy(p, name, len + 1);
file.data = buf.data;
ngx_log_debug1(ngx_log_debug_core, ctx->log, 0,
"tree path \"%s\"", file.data);
if (!dir.valid_info) {
if (ngx_de_info(file.data, &dir) == ngx_file_error) {
ngx_log_error(ngx_log_crit, ctx->log, ngx_errno,
ngx_de_info_n " \"%s\" failed", file.data);
continue;
}
}
// 如果当前读取到的是一个文件,则调用ctx->file_handler()加载该文件的内容
if (ngx_de_is_file(&dir)) {
ngx_log_debug1(ngx_log_debug_core, ctx->log, 0,
"tree file \"%s\"", file.data);
// 设置文件的相关属性
ctx->size = ngx_de_size(&dir);
ctx->fs_size = ngx_de_fs_size(&dir);
ctx->access = ngx_de_access(&dir);
ctx->mtime = ngx_de_mtime(&dir);
if (ctx->file_handler(ctx, &file) == ngx_abort) {
goto failed;
}
// 如果当前读取到的是一个目录,则首先调用设置的pre_tree_handler()方法,然后调用
// ngx_walk_tree()方法,递归的读取子目录,最后调用设置的post_tree_handler()方法
} else if (ngx_de_is_dir(&dir)) {
ngx_log_debug1(ngx_log_debug_core, ctx->log, 0,
"tree enter dir \"%s\"", file.data);
ctx->access = ngx_de_access(&dir);
ctx->mtime = ngx_de_mtime(&dir);
// 应用读取目录的前置逻辑
rc = ctx->pre_tree_handler(ctx, &file);
if (rc == ngx_abort) {
goto failed;
}
if (rc == ngx_declined) {
ngx_log_debug1(ngx_log_debug_core, ctx->log, 0,
"tree skip dir \"%s\"", file.data);
continue;
}
// 递归的读取当前目录
if (ngx_walk_tree(ctx, &file) == ngx_abort) {
goto failed;
}
ctx->access = ngx_de_access(&dir);
ctx->mtime = ngx_de_mtime(&dir);
// 应用读取目录的后置逻辑
if (ctx->post_tree_handler(ctx, &file) == ngx_abort) {
goto failed;
}
} else {
ngx_log_debug1(ngx_log_debug_core, ctx->log, 0,
"tree special \"%s\"", file.data);
if (ctx->spec_handler(ctx, &file) == ngx_abort) {
goto failed;
}
}
}
failed:
rc = ngx_abort;
done:
if (buf.len) {
ngx_free(buf.data);
}
if (data) {
ngx_free(data);
ctx->data = prev;
}
if (ngx_close_dir(&dir) == ngx_error) {
ngx_log_error(ngx_log_crit, ctx->log, ngx_errno,
ngx_close_dir_n " \"%s\" failed", tree->data);
}
return rc;
}从上面的处理流程可以看出,真正的加载文件的逻辑在ngx_http_file_cache_manage_file()方法中,如下是该方法的源码:
static ngx_int_t ngx_http_file_cache_manage_file(ngx_tree_ctx_t *ctx, ngx_str_t *path) {
ngx_msec_t elapsed;
ngx_http_file_cache_t *cache;
cache = ctx->data;
// 将文件添加到共享内存中
if (ngx_http_file_cache_add_file(ctx, path) != ngx_ok) {
(void) ngx_http_file_cache_delete_file(ctx, path);
}
// 如果加载的文件个数超过了loader_files指定的个数,则休眠一段时间
if (++cache->files >= cache->loader_files) {
ngx_http_file_cache_loader_sleep(cache);
} else {
// 更新当前缓存的时间
ngx_time_update();
// 计算当前加载炒作的耗时
elapsed = ngx_abs((ngx_msec_int_t) (ngx_current_msec - cache->last));
ngx_log_debug1(ngx_log_debug_http, ngx_cycle->log, 0,
"http file cache loader time elapsed: %m", elapsed);
// 如果加载操作耗时超过了loader_threshold所指定的时间,则休眠指定的时间
if (elapsed >= cache->loader_threshold) {
ngx_http_file_cache_loader_sleep(cache);
}
}
return (ngx_quit || ngx_terminate) ? ngx_abort : ngx_ok;
}这里的加载逻辑整体而言比较简单,主要过程就是将该文件加载到共享内存中,并且会判断加载的文件数量是否超限,如果超限了,则会休眠指定的时长;另外,也会判断加载文件的总耗时是否超过了指定时长,如果超过了,也会休眠指定的时长。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!