
Maison >Périphériques technologiques >IA >Huit problèmes entravant les progrès de l'intelligence artificielle
Huit problèmes entravant les progrès de l'intelligence artificielle

- PHPzavant
- 2023-05-22 10:06:321988parcourir

L’intelligence artificielle (IA) d’aujourd’hui est limitée. Il y a encore un long chemin à parcourir.
Certains chercheurs en IA ont découvert que les algorithmes d'apprentissage automatique, dans lesquels les ordinateurs apprennent par essais et erreurs, sont devenus une « force mystérieuse ».
Différents types d'intelligence artificielle
Les progrès récents en matière d'intelligence artificielle (IA) améliorent de nombreux aspects de nos vies.
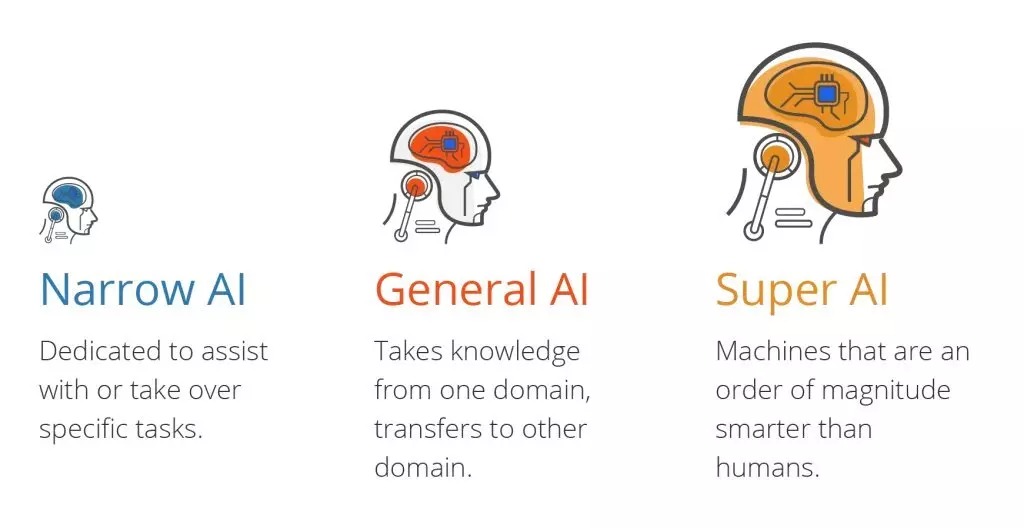
Il existe trois types d'intelligence artificielle :
- L'intelligence artificielle étroite (ANI), qui a un champ de capacités restreint.
- Intelligence Artificielle Générale (AGI), équivalente aux capacités humaines.
- Super Intelligence Artificielle (ASI), plus intelligente que les humains.
Qu’est-ce qui ne va pas avec l’intelligence artificielle aujourd’hui ?
L’intelligence artificielle d’aujourd’hui repose principalement sur des modèles et des algorithmes d’apprentissage statistique appelés analyse de données, apprentissage automatique, réseaux de neurones artificiels ou apprentissage profond. Il est implémenté comme une combinaison d'infrastructure informatique (plateforme ML, algorithmes, données, calcul) et de pile de développement (des bibliothèques aux langages, IDE, workflows et visualisations).
En résumé, cela implique :
- Des mathématiques appliquées, théorie des probabilités et statistiques
- Des algorithmes d'apprentissage statistique, régression logistique, régression linéaire, arbres de décision et forêts aléatoires
- Des algorithmes d'apprentissage automatique, supervisé, non supervisé et renforcement
- Certains réseaux de neurones artificiels, algorithmes et modèles d'apprentissage en profondeur pour filtrer les données d'entrée à travers plusieurs couches afin de prédire et de classer les informations
- Certains modèles de réseaux de neurones optimisés (compression et quantification)
- Certains modèles et inférences statistiques, tels que le SDK Qualcomm Neural Handling ,
- Certains langages de programmation comme Python et R.
- Certaines plates-formes, frameworks et runtimes ML comme PyTorch, ONNX, Apache MXNet, TensorFlow, Caffe2, CNTK, SciKit-Learn et Keras,
- Certains environnements de développement intégrés (IDE ), tels que PyCharm, Microsoft VS Code, Jupyter, MATLAB, etc.,
- Certains serveurs physiques, machines virtuelles, conteneurs, matériel spécialisé (tel que GPU), ressources informatiques basées sur le cloud (y compris les machines virtuelles, les conteneurs et l'informatique sans serveur ).
La plupart des applications d'IA utilisées aujourd'hui peuvent être classées comme IA étroites, appelées IA faibles.
Ils manquent tous d'intelligence artificielle générale et d'apprentissage automatique, qui sont définis par trois moteurs d'interaction clés :
- La machine modèle du monde [représentation, apprentissage et raisonnement], ou le simulateur de réalité (le réseau hypergraphique mondial).
- World Knowledge Engine (Global Knowledge Graph)
- World Data Engine (Global Data Graph Network)
La différence entre l'IA générale et les applications/machines/systèmes ML et DL réside dans la compréhension du monde comme de multiples représentations plausibles de l'état du monde. , Sa machine à réalité, son moteur de connaissances mondial et son moteur de données mondiales.
Il s'agit du composant le plus important de la pile d'IA générale/réelle, interagit avec son moteur de données du monde réel et fournit des fonctions/capacités intelligentes :
- Traiter les informations sur le monde
- Estimer/calculer/apprendre l'état de le modèle mondial
- Généraliser ses éléments de données, points, ensembles
- Spécifier ses structures et types de données
- Transférer son apprentissage
- Contextualiser son contenu
- Former/découvrir des modèles de données causales tels que des modèles causals, des règles et des régularités
- Inférer toutes les interactions, causes, effets, boucles, relations causales possibles dans les systèmes et les réseaux
- Anticiper/examiner l'état du monde à différentes portées et échelles et à différents niveaux de généralisation et de spécification
- Interagir avec le monde de manière efficace et efficiente, s'adapter à lui, naviguez-y et manipulez son environnement selon ses prédictions et prescriptions intelligentes
En fait, il s'agit principalement d'un moteur d'inférence statistique inductive qui s'appuie sur le big data computing, l'innovation algorithmique, la théorie de l'apprentissage statistique et la philosophie connexionniste.
Pour la plupart des gens, il s'agit simplement de créer un modèle d'apprentissage automatique (ML) simple, en passant par la collecte de données, la gestion, l'exploration, l'ingénierie des fonctionnalités, la formation du modèle, l'évaluation et enfin le déploiement.
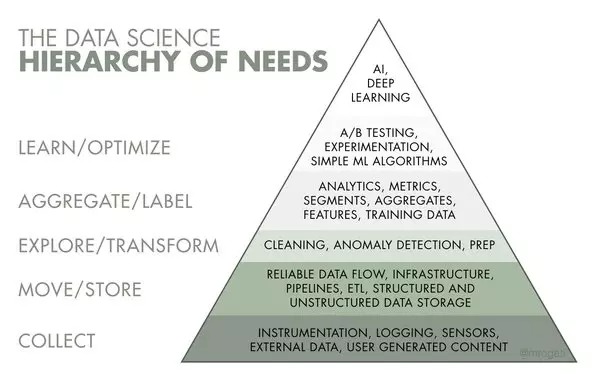
EDA : Analyse exploratoire des données
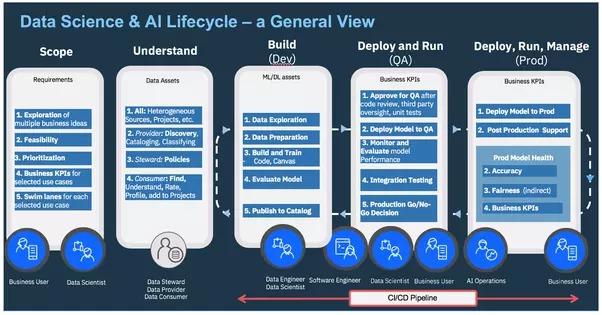
AI Ops — Gérer le cycle de vie de bout en bout de l'IA
Les capacités actuelles de l'IA proviennent du « machine learning », qui nécessite de configurer et d'ajuster des algorithmes pour chaque scénario du monde réel. Cela le rend très manuel et nécessite beaucoup de temps pour superviser son développement. Ce processus manuel est également sujet aux erreurs, inefficace et difficile à gérer. Sans parler du manque d’expertise pour configurer et régler différents types d’algorithmes.
La configuration, l'ajustement et la sélection de modèles sont de plus en plus automatisés, et toutes les grandes entreprises technologiques telles que Google, Microsoft, Amazon, IBM, etc. ont lancé des plates-formes AutoML similaires pour automatiser le processus de création de modèles d'apprentissage automatique.
AutoML consiste à automatiser les tâches nécessaires à la création de modèles prédictifs basés sur des algorithmes d'apprentissage automatique. Ces tâches incluent le nettoyage et le prétraitement des données, l'ingénierie des fonctionnalités, la sélection des fonctionnalités, la sélection du modèle et le réglage des hyperparamètres, qui peuvent être fastidieuses à effectuer manuellement.
SAS4485-2020.pdf
Le pipeline ML de bout en bout présenté se compose de 3 étapes clés tout en manquant la source de toutes les données, le monde lui-même :
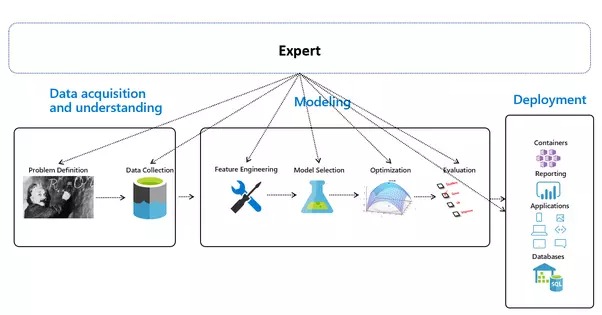
Apprentissage automatique automatisé - Présentation générale
Le secret clé de l’IA Big-Tech est le Skin-Deep Machine Learning en tant que réseau neuronal sombre et profond. Son modèle doit être formé à travers une grande quantité de données étiquetées et une architecture de réseau neuronal contenant autant de couches que possible.
Chaque tâche nécessite son architecture de réseau particulière :
- Réseaux de neurones artificiels (ANN) pour la régression et la classification
- Réseaux de neurones convolutifs (CNN) pour la vision par ordinateur
- Pour l'analyse de séries chronologiques Réseau de neurones récurrents (RNN)
- Auto- organiser des cartes pour l'extraction de fonctionnalités
- Machines Boltzmann profondes pour les systèmes de recommandation
- Encodeurs automatiques pour les systèmes de recommandation
ANN a été présenté comme un paradigme de traitement de l'information, semble être inspiré par la façon dont les systèmes nerveux/cerveaux biologiques traitent l'information. Et ces réseaux de neurones artificiels sont représentés comme des « approximateurs de fonctions universelles », qui peuvent apprendre/calculer diverses fonctions d'activation.
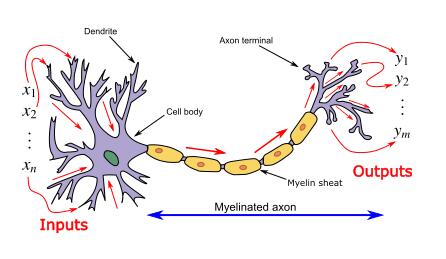
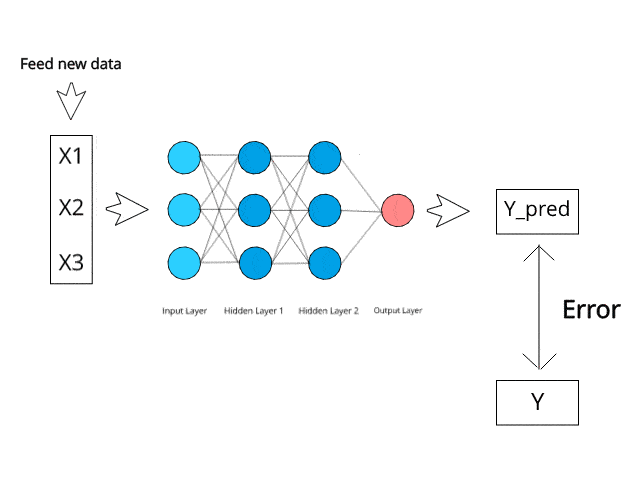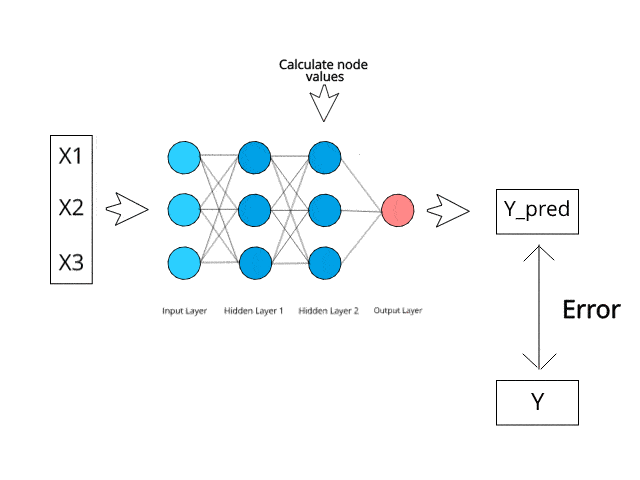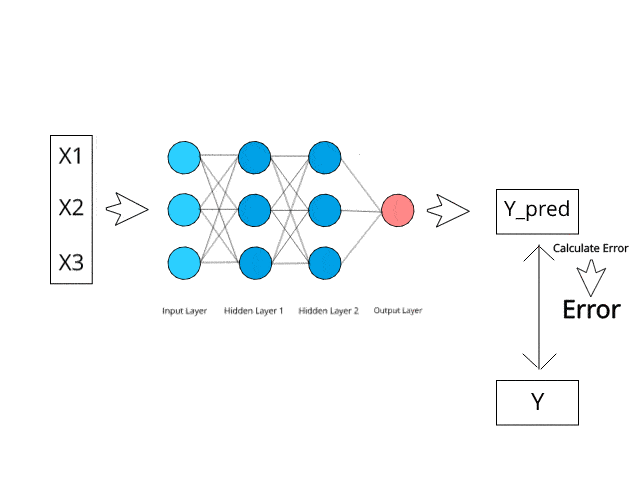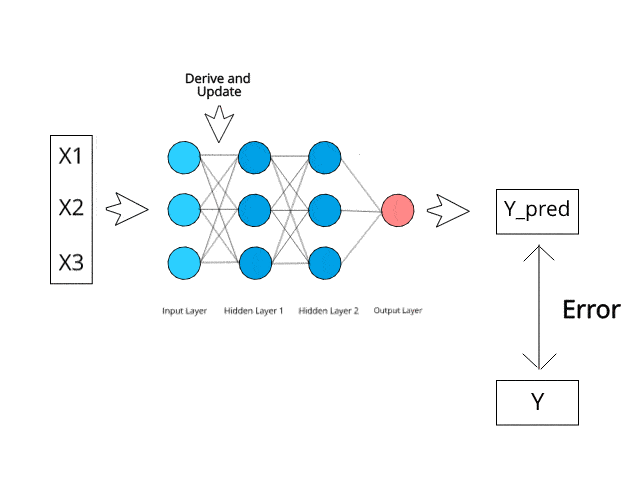
Le réseau neuronal calcule/apprend grâce à des mécanismes spécifiques de rétropropagation et de correction d'erreurs pendant la phase de test.
Imaginez simplement qu'en minimisant les erreurs, ces systèmes multicouches pourraient un jour apprendre et conceptualiser des idées par eux-mêmes.
Introduction aux réseaux de neurones artificiels (ANN)
Au total, quelques lignes de code R ou Python suffisent pour mettre en œuvre l'intelligence artificielle, et il existe des tonnes de ressources et de tutoriels en ligne pour former des réseaux quasi-neuraux, tels que divers réseaux deepfake, manipulation d'images - vidéos - Audio-texte, sans compréhension du monde, comme Generative Adversarial Networks, BigGAN, CycleGAN, StyleGAN, GauGAN, Artbreeder, DeOldify, etc.
Ils créent et modifient des visages, des paysages, des images génériques, etc. sans aucune compréhension de ce dont il s'agit.
L'utilisation de réseaux contradictoires cohérents avec les cycles pour la traduction image à image non appariée fait de 2019 la nouvelle ère de l'IA pour 14 utilisations de l'apprentissage profond et de l'apprentissage automatique.
Il existe d'innombrables outils et frameworks numériques qui fonctionnent à leur manière :
- Langages ouverts - Python est le plus populaire, R et Scala en font également partie.
- Framework ouvert - Scikit-learn, XGBoost, TensorFlow, etc.
- Méthodes et techniques – Techniques de ML classiques, de la régression aux GAN et RL de pointe
- Capacités d'amélioration de la productivité – Modélisation visuelle, AutoAI pour aider à l'ingénierie des fonctionnalités, à la sélection d'algorithmes et à l'optimisation des hyperparamètres
- Outils de développement – — DataRobot, H2O, Watson Studio, Azure ML Studio, Sagemaker, Anaconda, etc.
C'est dommage que les data scientists travaillent dans : scikit-learn, R, SparkML, Jupyter, R, Python, XGboost, Hadoop, Spark, TensorFlow, Keras, PyTorch, Docker, Plumbr, et la liste est longue. .
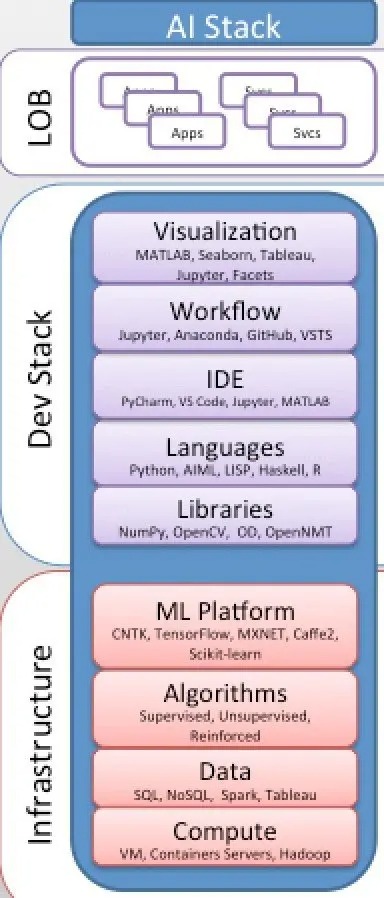
Modèle de consommation de la pile d'IA moderne et de l'IA en tant que service
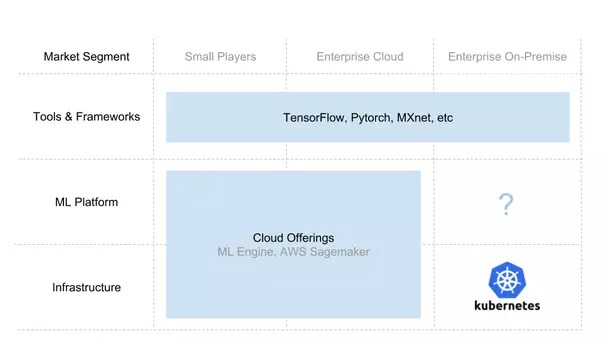
Building an AI Stack #🎜 🎜#
Ceux qui prétendent être une intelligence artificielle sont en réalité une fausse intelligence artificielle. Au mieux, il s’agit d’une technique d’apprentissage automatique, un outil de reconnaissance de modèles ML/DL/NN, de nature mathématique et statistique, incapable d’agir intuitivement ou de modéliser son environnement, avec zéro intelligence, zéro apprentissage et zéro compréhension. Des problèmes qui entravent les progrès de l'intelligence artificielleMalgré ses nombreux avantages, l'intelligence artificielle n'est pas parfaite. Voici 8 problèmes qui entravent les progrès de l'intelligence artificielle et où se situent les erreurs fondamentales : 1 Manque de donnéesL'intelligence artificielle nécessite de grands ensembles de données pour l'entraînement, et ces données. les ensembles doivent être inclusifs en matière de sexe/équité et de bonne qualité. Parfois, ils doivent attendre que de nouvelles données soient générées. 2. Cela prend du tempsL'intelligence artificielle nécessite suffisamment de temps pour que l'algorithme apprenne et se développe suffisamment pour atteindre son objectif avec un degré de précision et de pertinence raisonnablement élevé. Son fonctionnement nécessite également des ressources importantes. Cela peut impliquer des exigences supplémentaires concernant vos capacités informatiques. 3. Mauvaise interprétation des résultatsUn autre défi majeur est la capacité à interpréter avec précision les résultats générés par l'algorithme. Il faut également choisir soigneusement l'algorithme en fonction de son objectif. 4. Très sujette aux erreursL'intelligence artificielle est autonome, mais très sujette aux erreurs. Supposons que l'algorithme soit entraîné sur un ensemble de données suffisamment petit pour le rendre non inclusif. Vous vous retrouvez avec des prédictions biaisées provenant d’un ensemble d’entraînement biaisé. Dans le cas du machine learning, de tels faux pas peuvent déclencher une cascade d’erreurs qui peuvent rester longtemps indétectées. Lorsqu’ils sont remarqués, l’identification de la source du problème peut prendre un certain temps, et encore plus pour la corriger. 5. Questions éthiquesL'idée de faire confiance aux données et aux algorithmes plutôt qu'à notre propre jugement a ses avantages et ses inconvénients. De toute évidence, nous bénéficions de ces algorithmes, sinon nous ne les utiliserions pas en premier lieu. Ces algorithmes nous permettent d'automatiser les processus en portant des jugements éclairés à l'aide des données disponibles. Cependant, cela implique parfois de remplacer le travail de quelqu'un par un algorithme, ce qui a des conséquences éthiques. De plus, si quelque chose ne va pas, à qui devons-nous blâmer ? 6. Manque de ressources techniquesL'intelligence artificielle est encore une technologie relativement nouvelle. Des experts en machine learning sont nécessaires pour maintenir le processus, du code de démarrage à la maintenance et à la surveillance du processus. Le secteur de l’intelligence artificielle et de l’apprentissage automatique est encore relativement nouveau sur le marché. Trouver des ressources adéquates sous forme humaine est également difficile. Par conséquent, il y a un manque de représentants talentueux disponibles pour développer et gérer du matériel scientifique d’apprentissage automatique. Les chercheurs en données ont souvent besoin d’un mélange d’informations spatiales, ainsi que de connaissances mathématiques, techniques et scientifiques du début à la fin. 7. Infrastructure insuffisanteL'intelligence artificielle nécessite beaucoup de capacités de traitement de données. Les cadres d’héritage ne peuvent pas gérer les responsabilités et les contraintes sous pression. L'infrastructure doit être vérifiée si elle peut gérer les problèmes d'IA. Dans le cas contraire, elle doit être complètement mise à niveau avec un bon matériel et un stockage adaptable. 8. Résultats lents et biaisL'intelligence artificielle prend beaucoup de temps. En raison de la surcharge de données et de demandes, la livraison des résultats prend plus de temps que prévu. Se concentrer sur des fonctionnalités spécifiques d'une base de données pour généraliser les résultats est courant dans les modèles d'apprentissage automatique, ce qui peut conduire à des biais. ConclusionL'intelligence artificielle a pris le contrôle de nombreux aspects de nos vies. Même si elle n’est pas parfaite, l’intelligence artificielle est un domaine en pleine croissance et très demandé. Il fournit des résultats en temps réel en utilisant des données déjà existantes et traitées sans intervention humaine. Il permet d'analyser et d'évaluer de grandes quantités de données, souvent en développant des modèles basés sur les données. Bien que l’intelligence artificielle pose de nombreux problèmes, il s’agit d’un domaine en évolution. Du diagnostic médical au développement de vaccins en passant par les algorithmes commerciaux avancés, l’intelligence artificielle est devenue la clé du progrès scientifique.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI