
Maison >Périphériques technologiques >IA >La barre des étoiles a dépassé les 100 000 ! Après Auto-GPT, Transformer franchit une nouvelle étape
La barre des étoiles a dépassé les 100 000 ! Après Auto-GPT, Transformer franchit une nouvelle étape

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-21 21:34:041272parcourir
En 2017, l'équipe de Google a proposé l'architecture révolutionnaire NLP Transformer dans l'article "L'attention est tout ce dont vous avez besoin" et triche depuis.
Au fil des années, cette architecture a été populaire auprès des grandes entreprises technologiques telles que Microsoft, Google et Meta. Même ChatGPT, qui a balayé le monde, a été développé sur la base de Transformer.
Et aujourd'hui encore, Transformer a dépassé les 100 000 étoiles sur GitHub !
Hugging Face, à l'origine juste un programme de chatbot, est devenu célèbre en tant que centre du modèle Transformer et est devenu d'un seul coup une communauté open source de renommée mondiale.
Pour célébrer cette étape importante, Hugging Face a également résumé 100 projets basés sur l'architecture Transformer.
Transformer a fait exploser le cercle de l'apprentissage automatique
En juin 2017, lorsque Google a publié le document "L'attention est tout ce dont vous avez besoin", personne ne s'attendait peut-être au nombre de surprises que cette architecture d'apprentissage profond Transformer pourrait apporter.
Depuis sa naissance, Transformer est devenu la pierre angulaire du domaine de l'IA. En 2019, Google a également déposé un brevet spécifiquement pour ce produit.

Alors que Transformer occupe une position dominante dans le domaine de la PNL et a commencé à s'étendre à d'autres domaines, de plus en plus de travaux ont commencé pour tenter de l'introduire dans le domaine du CV.
De nombreux internautes étaient très heureux de voir Transformer franchir cette étape.
"J'ai contribué à de nombreux projets open source populaires, mais voir Transformer atteindre 100 000 étoiles sur GitHub est assez spécial !" Le nombre d'étoiles GitHub de GPT a dépassé celui de pytorch, provoquant une grande sensation.
Les internautes ne peuvent s'empêcher de se demander comment Auto-GPT se compare à Transformer ? 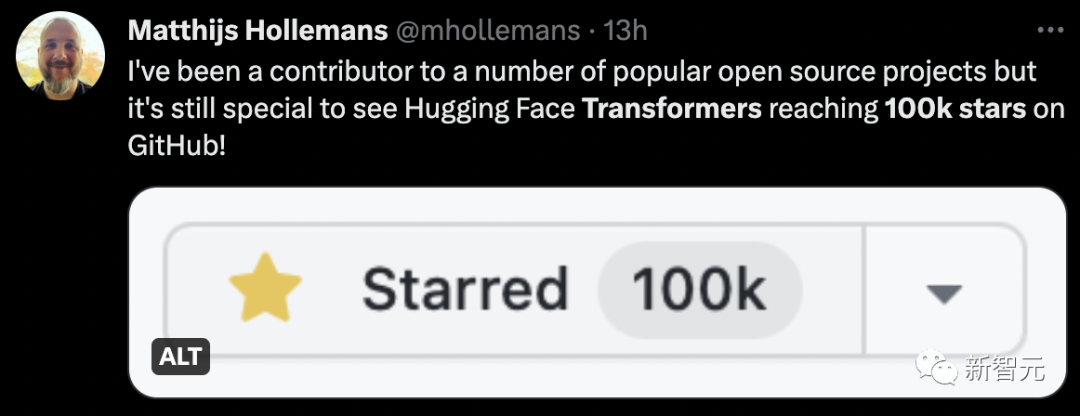
En fait, Auto-GPT surpasse de loin Transformer et compte déjà 130 000 étoiles.

Actuellement, Tensorflow compte plus de 170 000 étoiles. On peut constater que Transformer est la troisième bibliothèque d'apprentissage automatique avec une note de plus de 100 000 étoiles après ces deux projets.
Certains internautes ont rappelé que lorsqu'ils ont utilisé pour la première fois la bibliothèque Transformers, elle s'appelait "pytorch-pretrained-BERT". 
Transformers n'est pas seulement une boîte à outils pour utiliser des modèles pré-entraînés, c'est également une communauté de projets construits autour de Transformers et Hugging Face Hub.
Dans la liste ci-dessous, Hugging Face a résumé 100 projets étonnants et novateurs basés sur Transformer.
Ci-dessous, nous avons sélectionné les 50 meilleurs projets à présenter :
gpt4all
gpt4all est un écosystème de chatbot open source. Il est formé sur une vaste collection de données d’assistant propres, notamment du code, des histoires et des conversations. Il fournit des modèles de langage open source à grande échelle, tels que LLaMA et GPT-J, pour une formation de manière assistante.
Mots clés : open source, LLaMa, GPT-J, commande, assistant
recommenders
Ce référentiel contient des exemples et bonnes pratiques pour construire des systèmes de recommandation, fournis sous forme de notebooks Jupiter. Il couvre plusieurs aspects nécessaires à la construction d'un système de recommandation efficace : la préparation des données, la modélisation, l'évaluation, la sélection et l'optimisation du modèle, ainsi que l'opérationnalisation.
Mots clés : système de recommandation, AzureML
lama-cleaner
Image outil de réparation basé sur la technologie Stable Diffusion. Vous pouvez effacer tous les objets, défauts ou même personnes indésirables de l'image et remplacer n'importe quoi sur l'image.
Mots clés : Réparation, SD, Diffusion Stable
FLAIR est un puissant framework de traitement du langage naturel PyTorch qui peut transformer plusieurs tâches importantes : NER, analyse des sentiments, marquage de parties du discours, texte et dualité. Intégrer etc.
Mots clés : PNL, intégration de texte, intégration de documents, biomédecine, NER, PoS, analyse des sentiments
#🎜 🎜#
Mots clés : base de données, low code, table AI
langchain
#🎜🎜 # Langchain vise à aider au développement d'applications compatibles avec le LLM et d'autres sources de connaissances. La bibliothèque permet d'enchaîner les appels aux applications, créant ainsi une séquence dans de nombreux outils.
Mots clés : LLM, grand modèle linguistique, agent, chaîne
ParlAI
#🎜 🎜#ParlAI est un framework Python permettant de partager, de former et de tester des modèles de conversation, du chat de domaine ouvert au dialogue orienté tâches, en passant par la réponse visuelle aux questions. Il fournit plus de 100 ensembles de données, de nombreux modèles pré-entraînés, un ensemble d'agents et plusieurs intégrations sous la même API.Mots clés : dialogue, chatbot, VQA, jeu de données, agent
sentence-transformers #🎜🎜 #Ce framework fournit un moyen simple de calculer des représentations vectorielles denses de phrases, de paragraphes et d'images. Ces modèles sont basés sur des réseaux basés sur Transformer tels que BERT/RoBERTa/XLM-RoBERTa et ont atteint SOTA dans diverses tâches. Le texte est intégré dans un espace vectoriel de telle sorte que les textes similaires soient proches et puissent être trouvés efficacement grâce à la similarité cosinusoïdale.
Mots clés : représentation vectorielle dense, intégration de texte, intégration de phrases
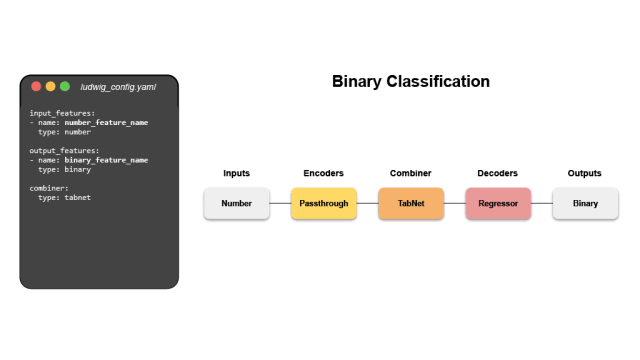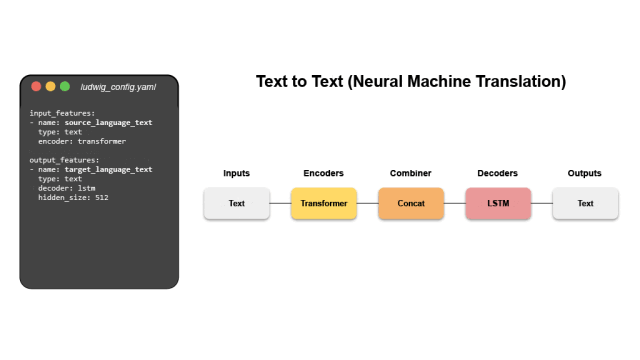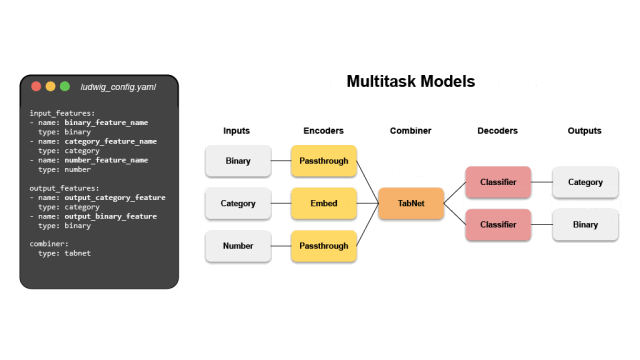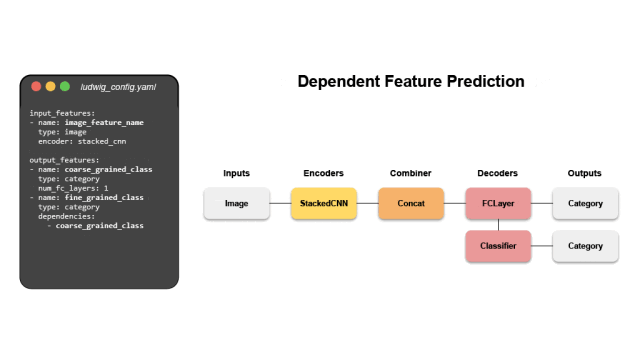
ludwig# 🎜 🎜 #Ludwig est un framework d'apprentissage automatique déclaratif qui facilite la définition de pipelines d'apprentissage automatique à l'aide d'un système de configuration simple et flexible basé sur les données. Ludwig cible diverses tâches d'IA, en fournissant un système de configuration basé sur les données, des scripts de formation, de prédiction et d'évaluation, ainsi qu'une API de programmation.
Mots clés : déclaratif, basé sur les données, framework ML
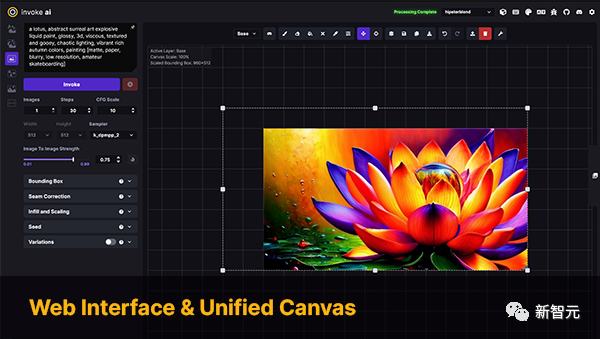
InvokeAI
InvokeAI est un moteur pour le modèle Stable Diffusion, destiné aux professionnels, artistes et passionnés. Il exploite la dernière technologie basée sur l'IA via CLI ainsi que WebUI.
Mots clés : Stable Diffusion, WebUI, CLI
PaddleNLP
PaddleNLP est une bibliothèque NLP facile à utiliser et puissante, en particulier pour la langue chinoise. Il prend en charge plusieurs zoos modèles pré-entraînés et prend en charge un large éventail de tâches PNL, de la recherche aux applications industrielles.
Mots clés : traitement du langage naturel, chinois, recherche, industrie
stanza
La bibliothèque officielle Python NLP du groupe NLP de l'université de Stanford. Il prend en charge l'exécution d'une large gamme d'outils précis de traitement du langage naturel dans plus de 60 langues et prend en charge l'accès au logiciel Java Stanford CoreNLP depuis Python.
Mots clés : PNL, multilingue, CoreNLP
DeepPavlov
DeepPavlov est une bibliothèque d'intelligence artificielle conversationnelle open source. Il est conçu pour le développement de chatbots prêts à la production et de systèmes de dialogue complexes, ainsi que pour la recherche dans le domaine de la PNL, en particulier les systèmes de dialogue.
Mots clés : dialogue, chatbot
alpaca-lora
Alpaca-lora contient du code pour reproduire les résultats de Stanford Alpaca en utilisant l'adaptation de bas rang (LoRA). Ce référentiel propose des scripts de formation (mise au point) et de génération.
Mots clés : LoRA, réglage fin efficace des paramètres
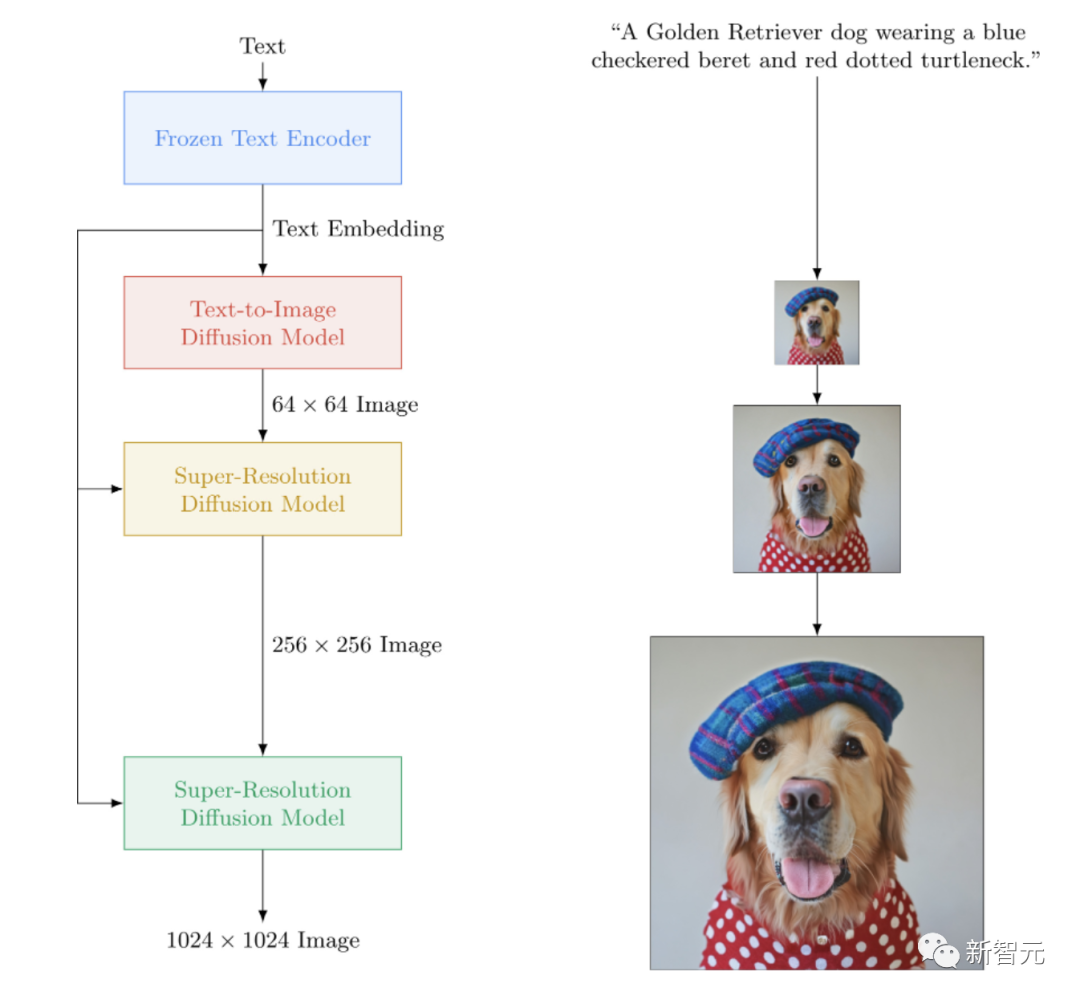
imagen-pytorch
Une implémentation open source d'Imagen, le réseau neuronal texte-image à source fermée de Google qui bat DALL-E2. imagen-pytorch est le nouveau SOTA pour la synthèse texte-image.
Mots clés : Imagen, Wenshengtu
adapter-transformers
adapter-transformers est une extension de la bibliothèque Transformers qui intègre des adaptateurs dans les modèles de langage les plus avancés en incorporant AdapterHub. référentiel de modules adaptateurs pré-entraînés. Il s'agit d'un remplacement instantané de Transformers et est régulièrement mis à jour pour suivre le rythme des développements de Transformers.
Mots clés : Adaptateur, LoRA, réglage précis des paramètres, Hub
NeMo
NVIDIA NeMo est conçu pour la reconnaissance vocale automatique (ASR), la synthèse texte-parole (TTS), les grands modèles de langage et Traitement du langage naturel Boîte à outils d'IA conversationnelle créée par des chercheurs. L'objectif principal de NeMo est d'aider les chercheurs de l'industrie et du monde universitaire à réutiliser leurs travaux antérieurs (code et modèles pré-entraînés) et à faciliter la création de nouveaux projets.
Mots clés : Conversation, ASR, TTS, LLM, NLP
Runhouse
Runhouse permet d'envoyer du code et des données en Python à n'importe quel ordinateur ou données sous-jacentes et de continuer à fonctionner normalement avec le code et les environnements existants avec lesquels ils interagissent. Les développeurs de Runhouse ont mentionné :
Vous pouvez le considérer comme un package d'extension pour l'interpréteur Python, qui peut contourner les machines distantes ou exploiter des données distantes.
Mots clés : MLOps, infrastructure, stockage de données, modélisation
MONAI
MONAI fait partie de l'écosystème PyTorch et est un framework open source basé sur PyTorch pour l'apprentissage profond dans le domaine de l'imagerie médicale. Ses objectifs sont :
- Développer une communauté collaborative sur une base commune entre les chercheurs académiques, industriels et cliniques ;
- Créer des SOTA, des workflows formés de bout en bout pour l'imagerie médicale ; - Fournit des méthodes d'optimisation et de standardisation pour l'établissement et l'évaluation de modèles d'apprentissage profond.
Mots clés : imagerie médicale, formation, évaluation
simpletransformers
Les Simple Transformers vous permettent de former et d'évaluer rapidement des modèles Transformer. Seules 3 lignes de code sont nécessaires pour initialiser, entraîner et évaluer le modèle. Il prend en charge une grande variété de tâches PNL.Mots clés : framework, simplicité, NLP
JARVIS
JARVIS est un système qui fusionne LLM, y compris GPT-4, avec d'autres modèles de la communauté d'apprentissage automatique open source, exploitant jusqu'à 60 modèles en aval pour effectuer tâches déterminées par LLM.Mots clés : LLM, Agent, HF Hub
transformers.js
Mots clés : Transformers, JavaScript, navigateur
bumblebee
Bumblebee fournit des modèles de réseaux neuronaux pré-entraînés au-dessus d'Axon, une bibliothèque de réseaux neuronaux pour le langage Elixir. Il inclut des intégrations avec des modèles, permettant à quiconque de télécharger et d'effectuer des tâches d'apprentissage automatique avec seulement quelques lignes de code.Mots clés : Elixir, Axon
argilla
Argilla est une plate-forme open source qui fournit un étiquetage, une surveillance et des espaces de travail PNL avancés. Il est compatible avec de nombreux écosystèmes open source tels que Hugging Face, Stanza, FLAIR, etc.Mots clés : PNL, balises, surveillance, espace de travail
haystack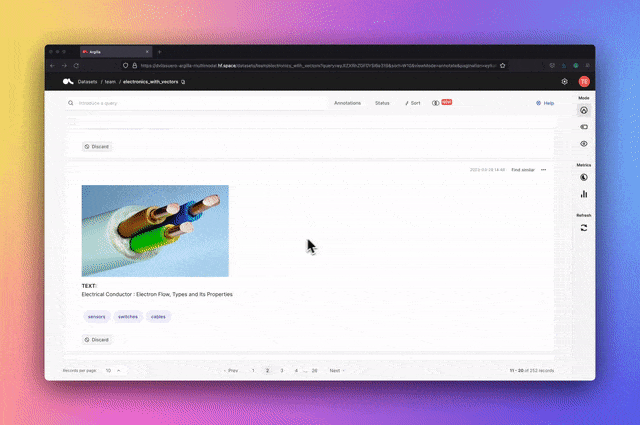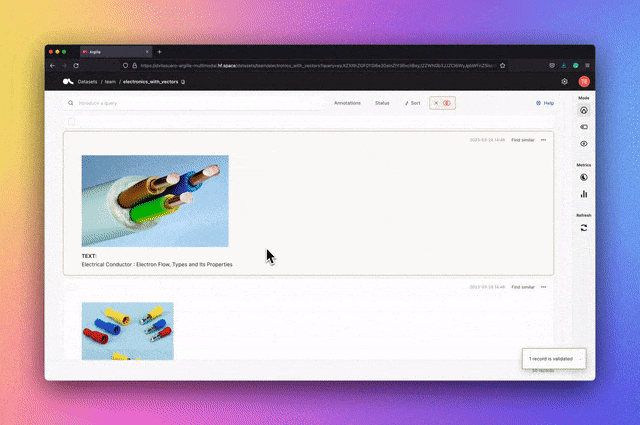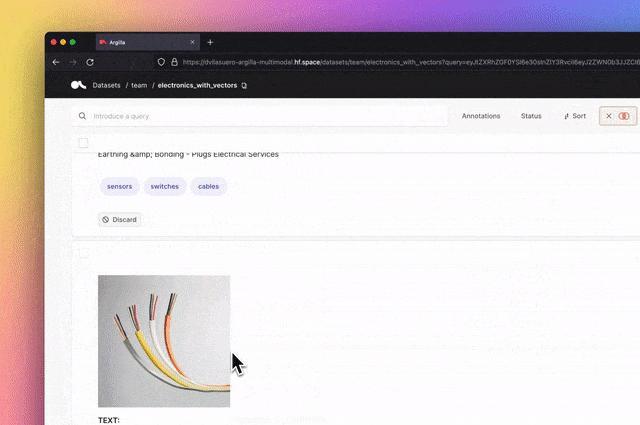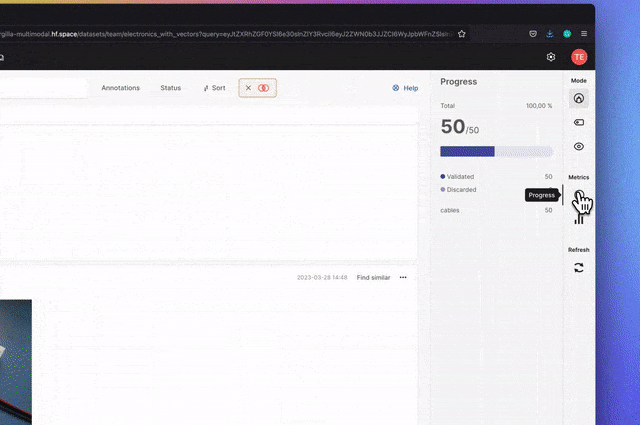
Mots clés : NLP, Framework, LLM
spaCy
Mots clés : PNL, architecture
speechbrain
SpeechBrain est une boîte à outils d'IA conversationnelle open source intégrée basée sur PyTorch. Notre objectif est de créer une boîte à outils unique, flexible et conviviale qui peut être utilisée pour développer facilement des technologies vocales de pointe, notamment la reconnaissance vocale, l'identification du locuteur, l'amélioration de la parole, la séparation de la parole, la reconnaissance vocale, l'utilisation de plusieurs microphones. traitement du signal et autres systèmes.
Mots clés : dialogue, parole
skorch
Skorch est une bibliothèque de réseaux neuronaux avec compatibilité scikit-learn qui enveloppe PyTorch. Il prend en charge les modèles dans Transformers, ainsi que les tokenizers des tokenizers.
Mots clés : Scikit-Learning, PyTorch
bertviz
BertViz est un outil interactif pour visualiser l'attention dans les modèles de langage Transformer tels que BERT, GPT2 ou T5. Il peut être exécuté dans les notebooks Jupiter ou Colab via une simple API Python qui prend en charge la plupart des modèles Huggingface.
Mots clés : Visualisation, Transformers

mesh-transformer-jax
mesh-transformer-jax est une bibliothèque haïku qui implémente le parallélisme des modèles Transformers à l'aide des opérateurs xmap/pjit dans JAX.
Cette bibliothèque est conçue pour évoluer jusqu'à environ 40 B de paramètres sur TPUv3. Il s'agit d'une bibliothèque utilisée pour entraîner des modèles GPT-J.
Mots clés : Haiku, parallélisme de modèles, LLM, TPUdeepchem
OpenNRE
Un progiciel open source (NRE) pour l'extraction de relations neuronales. Il s'adresse à un large éventail d'utilisateurs, des novices aux développeurs, chercheurs ou étudiants.
Mots clés : extraction de relations neuronales, framework
pycorrector
Un outil de correction d'erreurs de texte chinois. Cette méthode utilise les erreurs de détection du modèle linguistique, les fonctionnalités pinyin et les fonctionnalités de forme pour corriger les erreurs de texte chinois. Peut être utilisé pour les méthodes de saisie du pinyin chinois et des traits.
Mots clés : chinois, outil de correction d'erreurs, modèle de langage, Pinyin
nlpaug
Cette bibliothèque python peut vous aider à améliorer le nlp pour les projets d'apprentissage automatique. Il s'agit d'une bibliothèque légère dotée de fonctionnalités permettant de générer des données synthétiques pour améliorer les performances du modèle, prend en charge l'audio et le texte et est compatible avec plusieurs écosystèmes (scikit-learn, pytorch, tensorflow).
Mots clés : augmentation des données, génération de données synthétiques, audio, traitement du langage naturel
dream-textures
dream-textures est une bibliothèque conçue pour apporter un support de diffusion stable à Blender. Il prend en charge plusieurs cas d'utilisation tels que la génération d'images, la projection de textures, la peinture in/out, ControlNet et les mises à niveau.
Mots clés : Stable-Diffusion, Blender

seldon-core
Le noyau Seldon transforme votre modèle ML (Tensorflow, Pytorch, H2o, etc.) ou votre wrapper de langage (Python, Java, etc. .) ) en microservices REST/GRPC de production. Seldon peut gérer l'évolutivité vers des milliers de modèles d'apprentissage automatique de production et fournit des fonctionnalités avancées d'apprentissage automatique, notamment des métriques avancées, des journaux de requêtes, des interprètes, des détecteurs de valeurs aberrantes, des tests A/B, des canaris, etc.
Mots clés : microservices, modélisation, packaging linguistique
open_model_zoo
Cette bibliothèque comprend des modèles d'apprentissage profond optimisés et un ensemble de démos pour accélérer le développement d'applications d'inférence d'apprentissage profond hautes performances. Utilisez ces modèles pré-entraînés gratuits au lieu de former les vôtres pour accélérer les processus de développement et de déploiement en production.
Mots clés : modèle d'optimisation, démonstration
ml-stable-diffusion
ML-Stable-Diffusion est un référentiel d'Apple qui apporte la prise en charge de Stable Diffusion à Core ML sur les appareils à puce Apple. Il prend en charge les points de contrôle de diffusion stables hébergés sur Hugging Face Hub.
Mots clés : Stable Diffusion, Apple Chip, Core ML
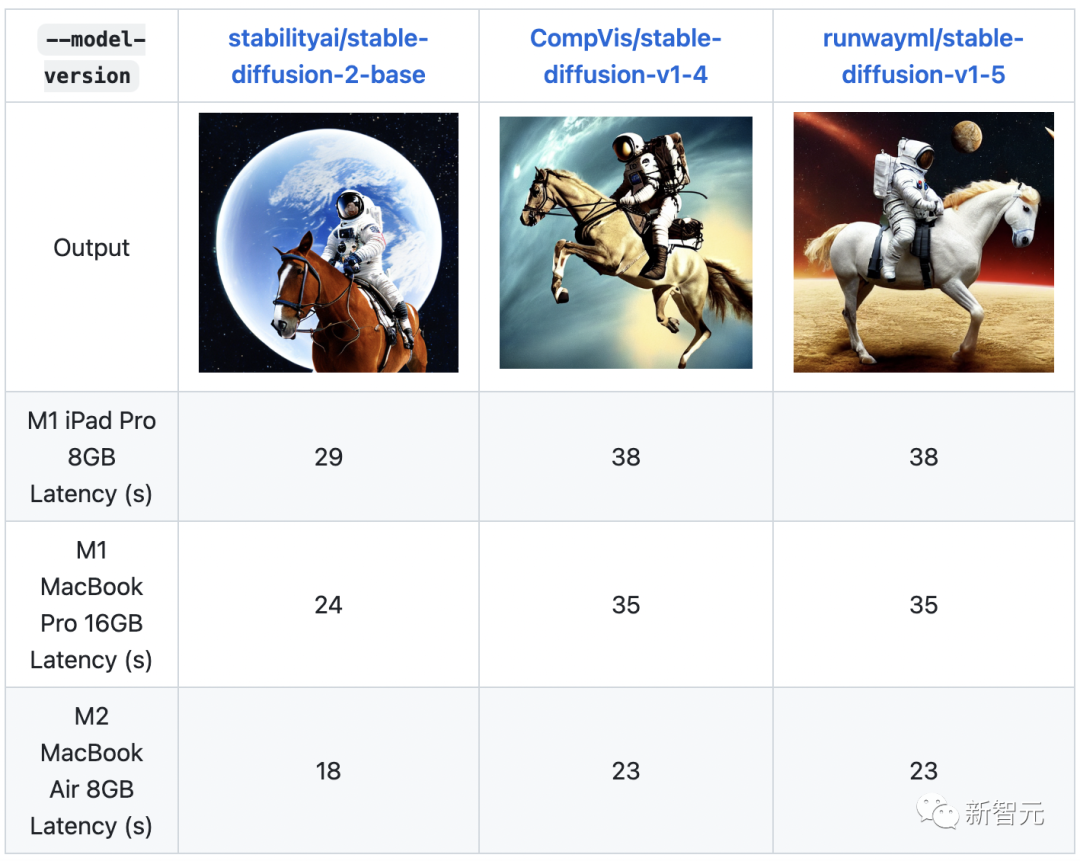
stable-dreamfusion
Stable-Dreamfusion est une implémentation pytorch de texte en modèle 3D Dreamfusion, fournie par Stable Diffusion text to 2D model pouvoir.
Mots clés : Texte en 3D, diffusion stable

txtai
Txtai est une plate-forme open source qui prend en charge la recherche sémantique et les flux de travail basés sur des modèles de langage. Txtai construit une base de données intégrée, qui est une combinaison d'index vectoriel et de base de données relationnelle, prenant en charge la recherche SQL du voisin le plus proche. Les workflows sémantiques connectent les modèles de langage à des applications unifiées.
Mots clés : Recherche sémantique, LLM

djl
Deep Java Library (DJL) est un framework Java open source, de haut niveau et indépendant du moteur pour l'apprentissage en profondeur, facile pour les développeurs utiliser. DJL offre une expérience de développement Java native et des fonctions similaires aux autres bibliothèques Java classiques. DJL fournit des liaisons Java pour HuggingFace Tokenizer et une boîte à outils de conversion simple pour déployer des modèles HuggingFace en Java.
Mots clés : Java, architecture

lm-evaluation-harness
Ce projet fournit un cadre unifié pour tester des modèles de langage génératifs sur un grand nombre de tâches d'évaluation différentes. Il prend en charge plus de 200 tâches et prend en charge différents écosystèmes : HF Transformers, GPT-NeoX, DeepSpeed et OpenAI API.
Mots clés : LLM, évaluation, quelques-shots
gpt-neox
Ce référentiel documente la bibliothèque d'EleutherAI pour la formation de modèles de langage à grande échelle sur les GPU. Le framework est basé sur le modèle de langage Megatron de NVIDIA et est amélioré avec la technologie DeepSpeed et quelques nouvelles optimisations. Il se concentre sur la formation de modèles comportant des milliards de paramètres.
Mots clés : formation, LLM, Megatron, DeepSpeed
muzic
Muzic est un projet de recherche sur la musique à intelligence artificielle, qui peut comprendre et générer de la musique grâce à l'apprentissage profond et à l'intelligence artificielle. Muzic a été créé par des chercheurs de Microsoft Research Asia.
Mots clés : compréhension musicale, génération musicale

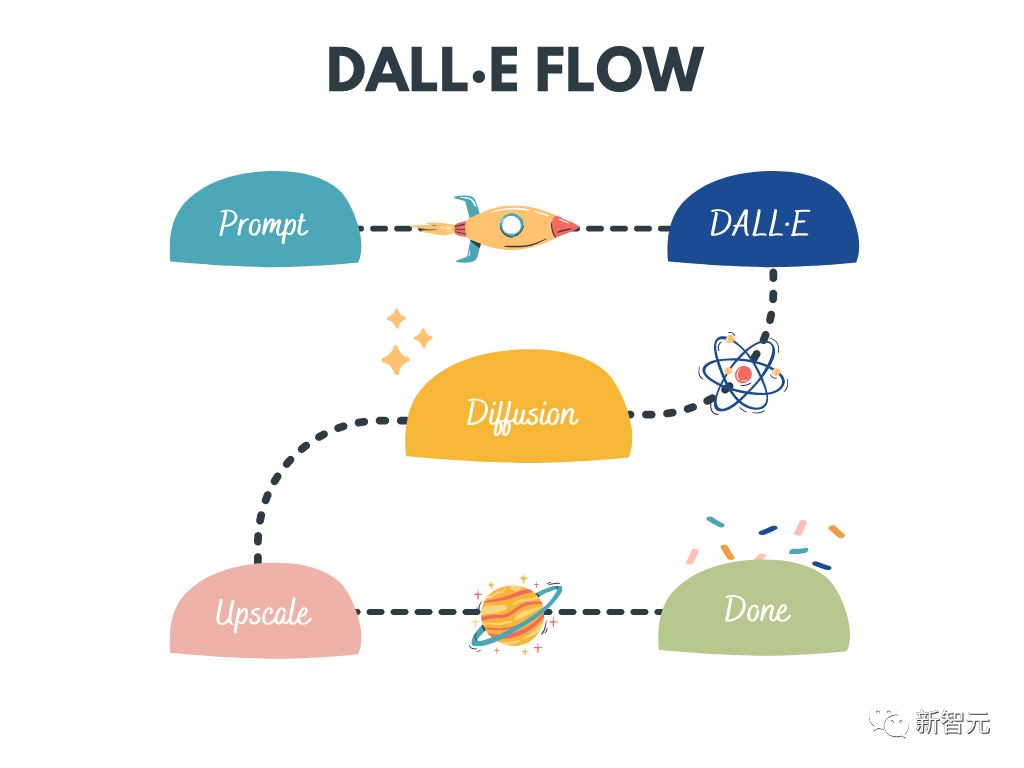
dalle-flow
DALL · E Flow est un flux de travail interactif permettant de générer des images HD à partir d'invites de texte. Il utilise DALL·E-Mega, GLID-3 XL et Stable Diffusion pour générer des images candidates, puis appelle CLIP-as-service pour trier rapidement les images candidates. Les candidats préférés sont transmis au GLID-3 XL pour diffusion, ce qui enrichit souvent les textures et les arrière-plans. Enfin, le candidat est étendu à 1024x1024 via SwinIR.
Mots clés : Génération d'images haute définition, Diffusion stable, DALL-E Mega, GLID-3 XL, CLIP, SwinIR
lightseq
LightSeq est implémenté dans CUDA pour les séquences Haute performance bibliothèque de formation et d’inférence pour le traitement et la génération. Il est capable de calculer efficacement des modèles NLP et CV modernes tels que BERT, GPT, Transformer, etc. Par conséquent, il est utile pour la traduction automatique, la génération de texte, la classification d’images et d’autres tâches liées aux séquences.
Mots clés : formation, inférence, traitement de séquence, génération de séquences

LaTeX-OCR
Le but de ce projet est de créer un système basé sur l'apprentissage qui prend des images de formules mathématiques, et renvoie le code LaTeX correspondant.
Mots clés : OCR, LaTeX, formules mathématiques
open_clip
OpenCLIP est une implémentation open source du CLIP d'OpenAI.
L'objectif de ce référentiel est de permettre la formation de modèles avec une supervision contrastée image-texte et d'étudier leurs propriétés telles que la robustesse aux changements de distribution. Le point de départ du projet est une implémentation de CLIP qui correspond à la précision du modèle CLIP d'origine lorsqu'il est formé sur le même ensemble de données.
Plus précisément, un modèle ResNet-50 formé sur le sous-ensemble de 15 millions d'images YFCC d'OpenAI comme base de code a atteint la précision la plus élevée de 32,7 % sur ImageNet.
Mots clés : CLIP, open source, comparaison, texte d'image

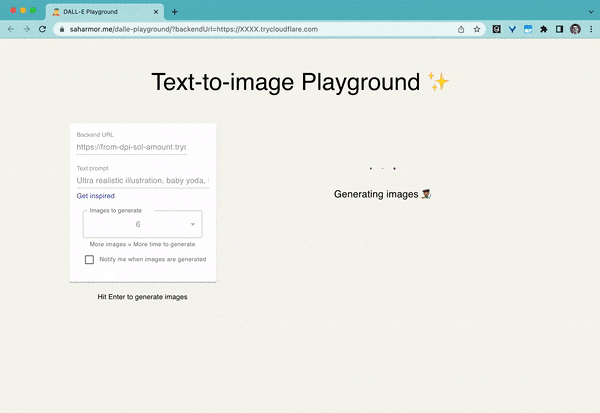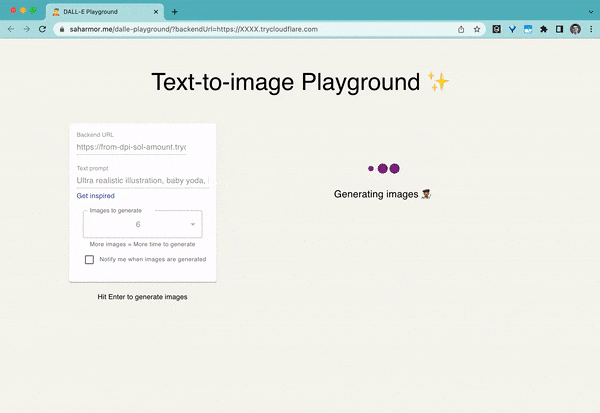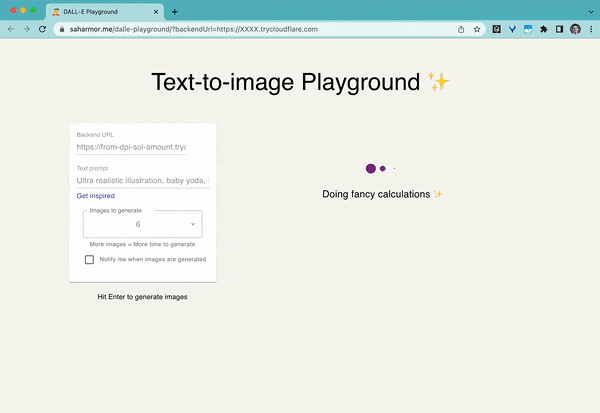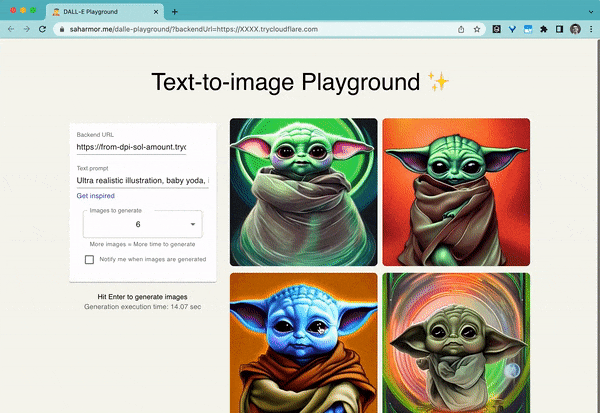
dalle-playground
Un terrain de jeu pour générer des images à partir de n'importe quelle invite de texte en utilisant Stable Diffusion et Dall-E mini.
Mots clés : WebUI, Stable Diffusion, Dall-E mini
FedML
FedML est une bibliothèque d'apprentissage et d'analyse fédérée qui permet des performances sécurisées sur des données décentralisées n'importe où et à n'importe quelle échelle et sur une machine collaborative apprentissage.
Mots clés : apprentissage fédéré, analytique, apprentissage automatique collaboratif, décentralisé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI