
Maison >développement back-end >Tutoriel Python >Comment utiliser tracemalloc dans Python3 pour suivre les modifications de la mémoire mmap
Comment utiliser tracemalloc dans Python3 pour suivre les modifications de la mémoire mmap

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-21 20:25:251067parcourir
Contexte technique
Dans le blog précédent, nous avons présenté quelques méthodes de traitement de données tabulaires avec python3, axées sur une solution de traitement de données à grande échelle telle que vaex. Cette solution de traitement de données est basée sur la technologie de carte mémoire. En créant des fichiers mappés en mémoire, nous évitons les problèmes d'utilisation de la mémoire à grande échelle causés par le chargement direct des données source en mémoire. Cela nous permet d'utiliser la taille de la mémoire de l'ordinateur local qui n'est pas traitée à grande échelle. données dans des conditions très larges. Dans Python 3, il existe une bibliothèque appelée mmap qui peut être utilisée pour créer directement des fichiers mappés en mémoire.
Utilisez tracemalloc pour suivre l'utilisation de la mémoire du programme Python
Ici, nous espérons comparer l'utilisation réelle de la mémoire de la technologie de mappage de mémoire, nous devons donc introduire un outil de suivi de la mémoire basé sur Python : tracemalloc. Prenons d'abord un exemple simple, c'est-à-dire créons un tableau aléatoire, puis observons la taille de la mémoire occupée par le tableau
# tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
length=10000
test_array=np.random.randn(length) # 分配一个定长随机数组
snapshot=tracemalloc.take_snapshot() # 内存摄像
top_stats=snapshot.statistics('lineno') # 内存占用数据获取
print ('[Top 10]')
for stat in top_stats[:10]: # 打印占用内存最大的10个子进程
print (stat)Le résultat de sortie est le suivant :
[dechin@dechin-manjaro mmap]$ python3 tracem. py
[Top 10 ]
tracem.py:8 : size=78,2 KiB, count=2, Average=39,1 KiB
Si nous utilisons la commande top pour détecter directement la mémoire, il ne fait aucun doute que Google Chrome a le plus haut partage de mémoire :
top - 10:04:08 en place 6 jours, 15:18, 5 utilisateurs, charge moyenne : 0,23, 0,33, 0,27
tâches : 309 au total, 1 en cours d'exécution, 264 en sommeil, 23 arrêtées, 21 zombies
%Cpu(s) : 0,6 us, 0,2 sy, 0,0 ni, 99,0 id, 0,0 wa, 0,0 hi, 0,0 si, 0,0 st
MiB Mem : 39913,6 au total, 25450,8 gratuits, 1875,7 utilisés, 12587,1 buff/cache
Mi B Swap : 16384.0 total, 16384.0 gratuit, 0.0 utilisé. 36775.8 dispo Mem
Process ID USER PR NI VIRT RES SHR %CPU %MEM TIME+ COMMAND
286734 dechin 20 0 36.6g 175832 117544 S 4.0 0.4 1:02 .32 chrome
Alors suivez l'enfant en fonction du numéro de processus L'utilisation de la mémoire du processus est un point clé de l'utilisation de tracemalloc. Nous constatons ici que l'utilisation de la mémoire d'un vecteur numpy de taille 10000 est d'environ 39,1 Ko, ce qui est en fait conforme à nos attentes :
In [3] : 39,1*1024/ 4
Out[3] : 10009,6
Parce que c'est presque l'empreinte mémoire de 10 000 nombres à virgule flottante float32, ce qui indique que tous les éléments ont été stockés en mémoire.
Utilisez tracemalloc pour suivre les changements de mémoire
Dans le chapitre précédent, nous avons présenté l'utilisation d'instantanés de mémoire d'instantanés, nous pouvons alors facilement penser à "prendre" deux instantanés de mémoire, puis à comparer les changements dans les instantanés. Puis-je obtenir la taille de. le changement de mémoire ? Ensuite, faites une simple tentative :
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
snapshot0=tracemalloc.take_snapshot() # 第一张快照
length=10000
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot() # 第二张快照
top_stats=snapshot1.compare_to(snapshot0,'lineno') # 快照对比
print ('[Top 10 differences]')
for stat in top_stats[:10]:
print (stat)Les résultats de l'exécution sont les suivants :
[dechin@dechin-manjaro mmap]$ python3 comp_tracem.py
[Top 10 des différences]
comp_tracem.py:9 : size=78.2 KiB (+78,2 Ko), nombre = 2 (+2), moyenne = 39,1 KiB
Vous pouvez voir que la différence moyenne de taille de mémoire avant et après cet instantané est de 39,1 KiB. Si nous changeons la dimension du vecteur à 1 000 000 :
length=1000000
Exécutez-le à nouveau Jetez un œil à l'effet :
[dechin@dechin-manjaro mmap]$ python3 comp_tracem.py
[Top 10 des différences]
comp_tracem.py:9: size=7813 KiB (+7813 KiB ), count=2 (+2) , moyenne=3906 KiB
Nous avons constaté que le résultat était de 3906, ce qui équivaut à être amplifié 100 fois, ce qui est plus conforme aux attentes. Bien sûr, si nous le calculons soigneusement :
In [4] : 3906*1024/4
Out[4] : 999936.0
Nous constatons que ce n'est pas entièrement un type float32 par rapport au float32 complet. tapez Une partie de la taille de la mémoire est manquante. Je me demande si des 0 ont été générés au milieu et si la taille a été automatiquement compressée ? Cependant, ce n’est pas sur cette question que nous souhaitons nous concentrer. Nous continuons à tester la courbe de changement de mémoire vers le bas.
Courbe d'utilisation de la mémoire
Continue le contenu des deux chapitres précédents. Nous testons principalement l'espace mémoire requis par des tableaux aléatoires de différentes dimensions. Sur la base du module de code ci-dessus, une boucle for est ajoutée : Dessinée par
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat): # 判断是否属于当前文件所产生的内存占用
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(m曲线em[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect') # float32的预期占用空间
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')Le rendu. est le suivant :
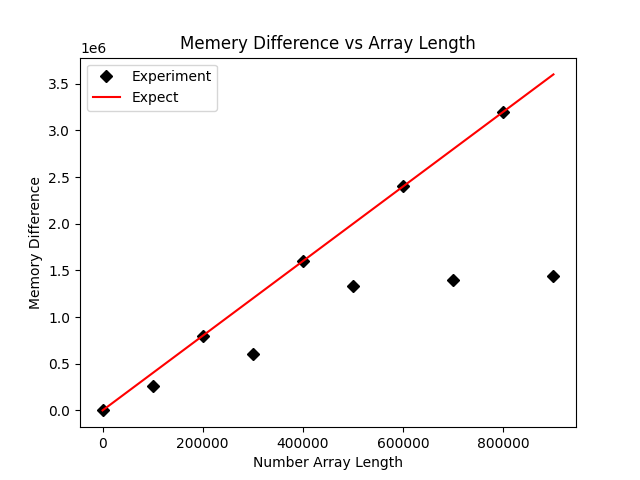
Ici, nous constatons également que même si dans la plupart des cas l'utilisation de la mémoire est conforme aux attentes, de nombreux points occupent moins que prévu. Nous soupçonnons que c'est parce qu'il y a 0 élément, donc c'est le cas. est légèrement j'ai modifié le code et ajouté une opération basée sur le code d'origine pour éviter autant que possible l'apparition de 0 :
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi # 在原数组基础上加一个圆周率,内存不变
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')Après la mise à jour, l'image du résultat est la suivante :
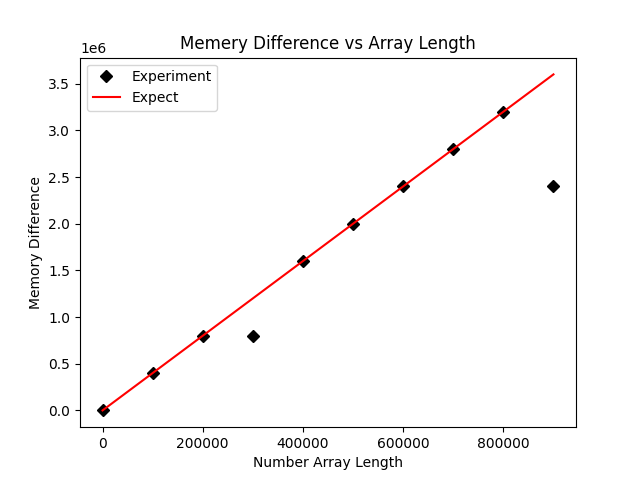
虽然不符合预期的点数少了,但是这里还是有两个点不符合预期的内存占用大小,疑似数据被压缩了。
mmap内存占用测试
在上面几个章节之后,我们已经基本掌握了内存追踪技术的使用,这里我们将其应用在mmap内存映射技术上,看看有什么样的效果。
将numpy数组写入txt文件
因为内存映射本质上是一个对系统文件的读写操作,因此这里我们首先将前面用到的numpy数组存储到txt文件中:
# write_array.py
import numpy as np
x=[]
y=[]
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi
np.savetxt('numpy_array_length_'+str(length)+'.txt',test_array)写入完成后,在当前目录下会生成一系列的txt文件:
-rw-r--r-- 1 dechin dechin 2500119 4月 12 10:09 numpy_array_length_100001.txt
-rw-r--r-- 1 dechin dechin 25 4月 12 10:09 numpy_array_length_1.txt
-rw-r--r-- 1 dechin dechin 5000203 4月 12 10:09 numpy_array_length_200001.txt
-rw-r--r-- 1 dechin dechin 7500290 4月 12 10:09 numpy_array_length_300001.txt
-rw-r--r-- 1 dechin dechin 10000356 4月 12 10:09 numpy_array_length_400001.txt
-rw-r--r-- 1 dechin dechin 12500443 4月 12 10:09 numpy_array_length_500001.txt
-rw-r--r-- 1 dechin dechin 15000526 4月 12 10:09 numpy_array_length_600001.txt
-rw-r--r-- 1 dechin dechin 17500606 4月 12 10:09 numpy_array_length_700001.txt
-rw-r--r-- 1 dechin dechin 20000685 4月 12 10:09 numpy_array_length_800001.txt
-rw-r--r-- 1 dechin dechin 22500788 4月 12 10:09 numpy_array_length_900001.txt
我们可以用head或者tail查看前n个或者后n个的元素:
[dechin@dechin-manjaro mmap]$ head -n 5 numpy_array_length_100001.txt
4.765938017253034786e+00
2.529836239939717846e+00
2.613420901326337642e+00
2.068624031433622612e+00
4.007000282914471967e+00
numpy文件读取测试
前面几个测试我们是直接在内存中生成的numpy的数组并进行内存监测,这里我们为了严格对比,统一采用文件读取的方式,首先我们需要看一下numpy的文件读取的内存曲线如何:
# npopen_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=np.loadtxt('numpy_array_length_'+str(length)+'.txt',delimiter=',')
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if '/home/dechin/anaconda3/lib/python3.8/site-packages/numpy/lib/npyio.py:1153' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,8),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('open_mem.png')需要注意的一点是,这里虽然还是使用numpy对文件进行读取,但是内存占用已经不是名为npopen_tracem.py的源文件了,而是被保存在了npyio.py:1153这个文件中,因此我们在进行内存跟踪的时候,需要调整一下对应的统计位置。最后的输出结果如下:
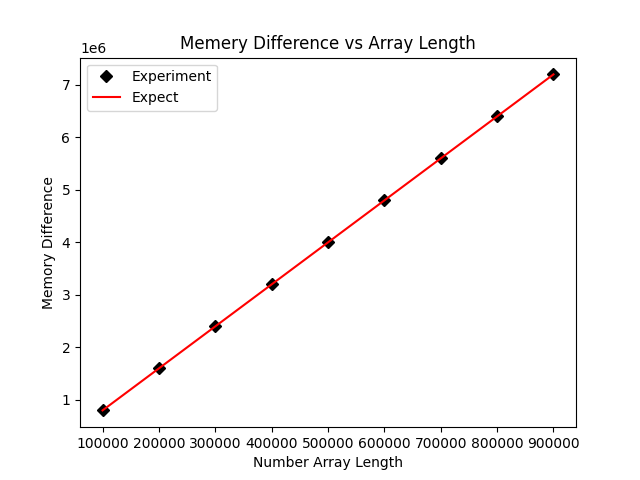
由于读入之后是默认以float64来读取的,因此预期的内存占用大小是元素数量×8,这里读入的数据内存占用是几乎完全符合预期的。
mmap内存占用测试
伏笔了一大篇幅的文章,最后终于到了内存映射技术的测试,其实内存映射模块mmap的使用方式倒也不难,就是配合os模块进行文件读取,基本上就是一行的代码:
# mmap_tracem.py
import tracemalloc
import numpy as np
import mmap
import os
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=mmap.mmap(os.open('numpy_array_length_'+str(length)+'.txt',os.O_RDWR),0) # 创建内存映射文件
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
print (stat)
if 'mmap_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('mmap.png')运行结果如下:
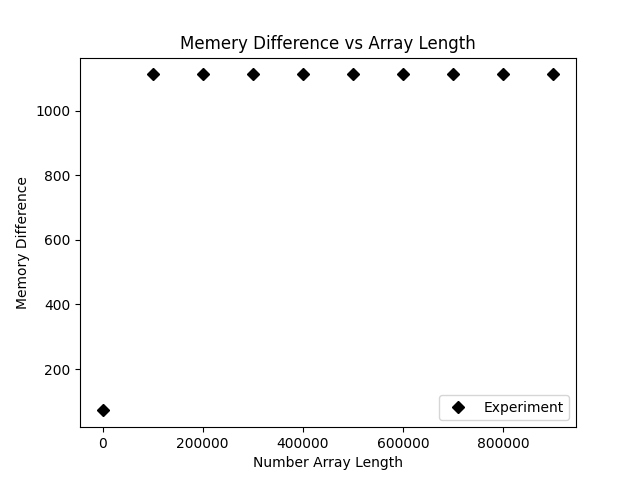
我们可以看到内存上是几乎没有波动的,因为我们并未把整个数组加载到内存中,而是在内存中加载了其内存映射的文件。我们能够以较小的内存开销读取文件中的任意字节位置。当我们去修改写入文件的时候需要额外的小心,因为对于内存映射技术来说,byte数量是需要保持不变的,否则内存映射就会发生错误。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!