
Maison >Périphériques technologiques >IA >Prévisions de séries chronologiques multivariées : prévision indépendante ou prévision conjointe ?
Prévisions de séries chronologiques multivariées : prévision indépendante ou prévision conjointe ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-20 21:04:381267parcourir
Aujourd'hui, je vous présente un article publié par NTU en avril de cette année. Il traite principalement des différences dans les effets de la prédiction indépendante (indépendante du canal) et de la prédiction conjointe (dépendante du canal) dans les problèmes de prédiction de séries chronologiques multivariées, ainsi que des raisons qui les sous-tendent. , et leur méthode d'optimisation.

Titre de l'article : Le compromis entre capacité et robustesse : revisiter la stratégie indépendante des canaux pour la prévision de séries chronologiques multivariées# 🎜🎜#
Adresse de téléchargement : https://arxiv.org/pdf/2304.05206v1.pdf1 Prévisions indépendantes et prévisions conjointesSéries chronologiques multiples. Dans les problèmes de prévision, il existe deux types du point de vue des méthodes de modélisation multivariées. L'un est la prévision indépendante du canal (indépendant du canal, CI), qui fait référence au traitement des séquences multivariées comme plusieurs prévisions univariées, et l'autre est modélisée séparément. est une prédiction conjointe (dépendante du canal, CD), qui fait référence à la modélisation de plusieurs variables ensemble et à la prise en compte de la relation entre chaque variable. La différence entre les deux est indiquée ci-dessous.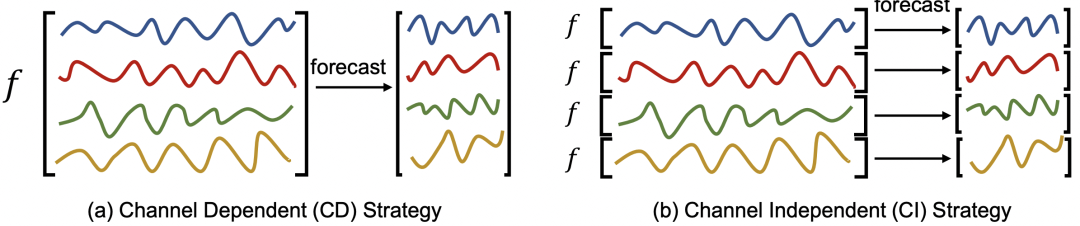
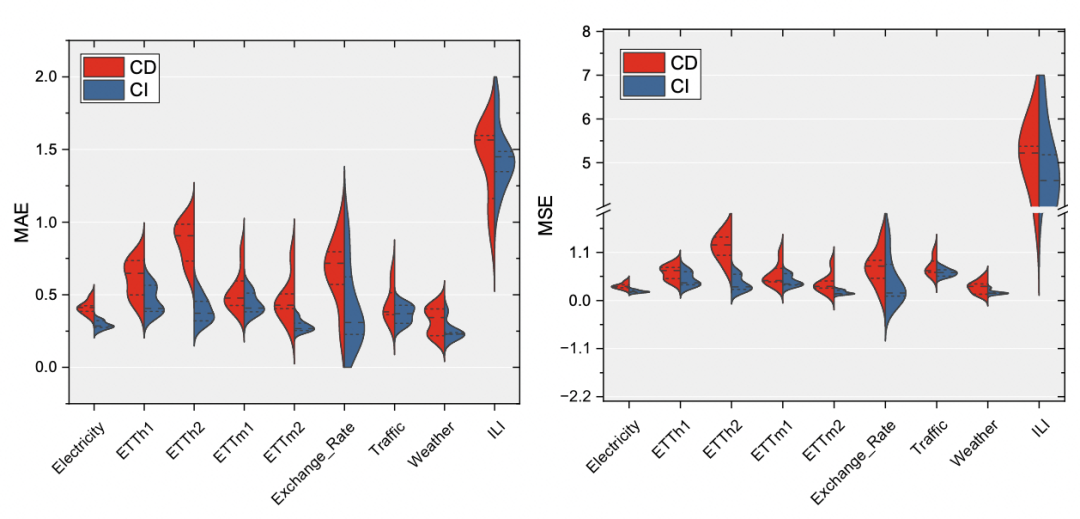
Longueur de la séquence historique d'entrée : pour le modèle CD, plus la séquence historique d'entrée est longue, l'effet peut être réduit. Cela est également dû au fait que plus la séquence historique est longue, plus. le modèle est sensible à l'influence du changement de distribution. Pour le modèle CI, l'augmentation de la longueur de la séquence historique peut améliorer de manière plus stable l'effet de prédiction. 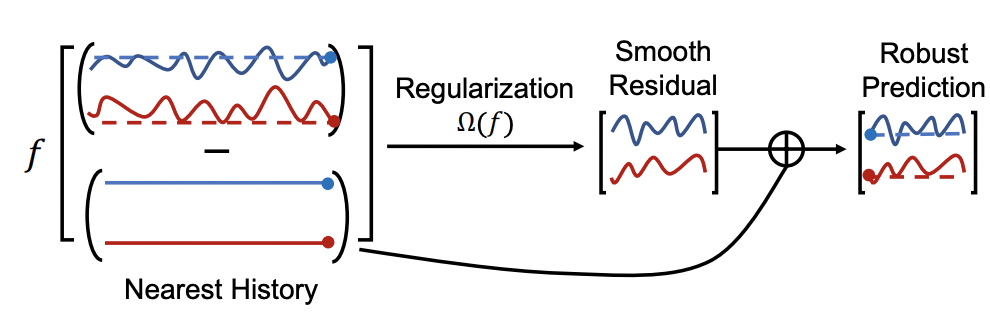
4. Résultats expérimentaux
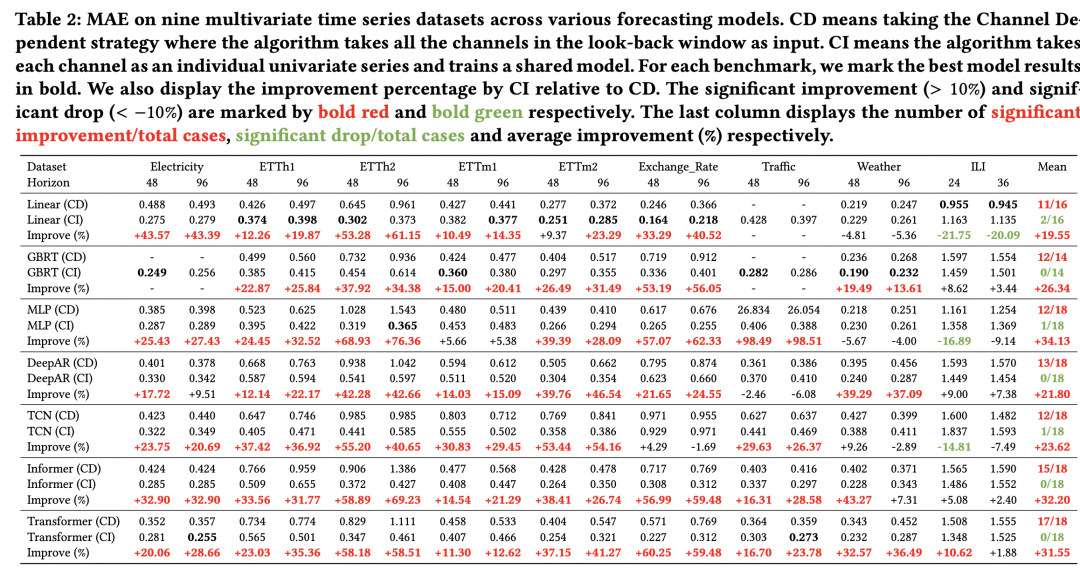
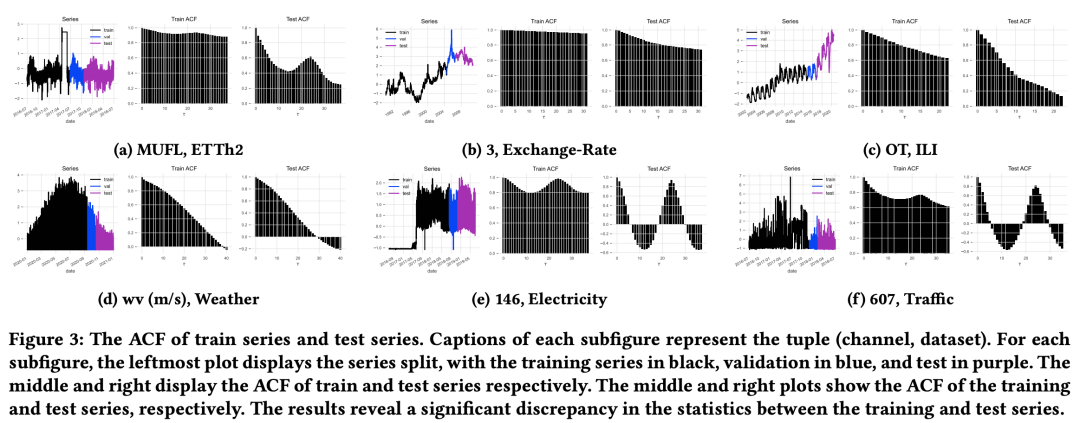
La méthode mentionnée ci-dessus pour améliorer le modèle CD a été testée sur plusieurs ensembles de données. Par rapport au CD, une amélioration de l'effet relativement stable a été obtenue, indiquant que la méthode ci-dessus est relativement efficace pour améliorer la robustesse du multivarié. prédiction de séquence. Les résultats expérimentaux montrent que des facteurs tels que la décomposition de bas rang, la longueur historique de la fenêtre et le type de fonction de perte sont également répertoriés dans l'article en termes d'influence sur l'effet.
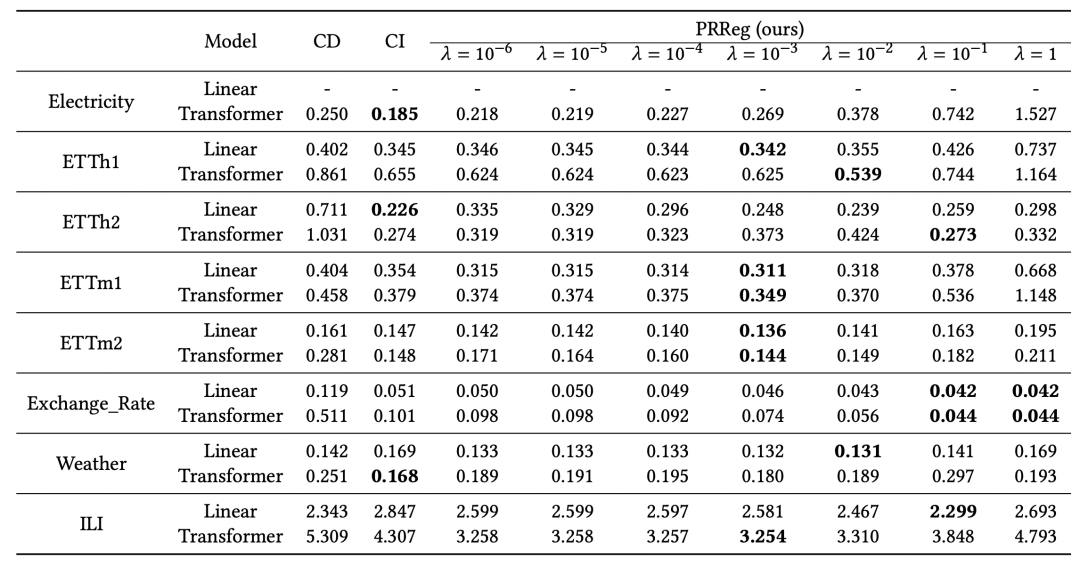
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI