
Maison >Java >javaDidacticiel >Comment spécifier dynamiquement plusieurs sujets à l'aide de @KafkaListener dans springboot+kafka
Comment spécifier dynamiquement plusieurs sujets à l'aide de @KafkaListener dans springboot+kafka

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-20 20:58:193962parcourir
Description
Ce projet est un projet d'intégration springboot+kafak, il utilise donc l'annotation de consommation kafak @KafkaListener dans springboot
Tout d'abord, configurez plusieurs sujets séparés par des virgules dans application.properties.
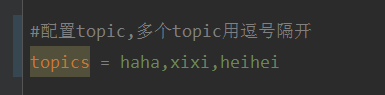
Méthode : utilisez l'expression SpEl de Spring pour configurer les sujets comme : @KafkaListener(topics = "#{’${topics}’.split(’,’)}")
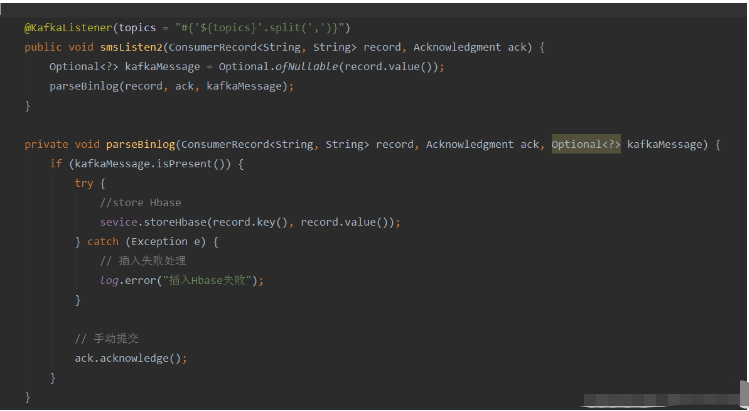
Exécuter le programme et l'effet d'impression de la console est le suivant :

Étant donné qu'un seul fil consommateur est ouvert, tous les sujets et partitions sont attribués à ce fil.
Si vous souhaitez ouvrir plusieurs fils de discussion pour consommer ces sujets, ajoutez le paramètre concurrency de l'annotation @KafkaListener au nombre de consommateurs souhaité (notez que le nombre de consommateurs doit être inférieur ou égal au nombre de consommateurs que vous souhaitez) La somme du nombre de partitions de tous les sujets)

Exécutez le programme et l'effet d'impression de la console est le suivant :

Pour résumer la question la plus fréquemment posée
Comment changer le sujet et consommer pendant l'exécution du programme ? L'utilisateur peut-il consommer le sujet modifié ?
ans : Après avoir essayé, cette exigence ne peut pas être satisfaite à l'aide de l'annotation @KafkaListener. Lorsque le programme démarre, le programme initialise le. consommateur basé sur les informations d'annotation @KafkaListener pour consommer le sujet spécifié. Si le sujet est modifié pendant l'exécution du programme, le consommateur ne sera pas autorisé à modifier la configuration du consommateur, puis à se réabonner au sujet.
Mais nous pouvons avoir un compromis, qui consiste à utiliser le paramètre topicPattern de @KafkaListener pour la correspondance de sujet.
Méthode ultime
Idée
Utilisez la dépendance client native de Kafka, initialisez manuellement les consommateurs et démarrez les threads consommateurs au lieu d'utiliser @KafkaListener.
Dans le fil de discussion consommateur, chaque cycle obtient les dernières informations sur le sujet à partir de la configuration, de la base de données ou d'autres sources de configuration, les compare avec le sujet précédent et, si des changements se produisent, se réabonne au sujet ou initialise le consommateur.
Implémentation
Ajouter une dépendance client Kafka (ce serveur de test version Kafka : 2.12-2.4.0)
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.3.0</version> </dependency>
code
@Service
@Slf4j
public class KafkaConsumers implements InitializingBean {
/**
* 消费者
*/
private static KafkaConsumer<String, String> consumer;
/**
* topic
*/
private List<String> topicList;
public static String getNewTopic() {
try {
return org.apache.commons.io.FileUtils.readLines(new File("D:/topic.txt"), "utf-8").get(0);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 初始化消费者(配置写死是为了快速测试,请大家使用配置文件)
*
* @param topicList
* @return
*/
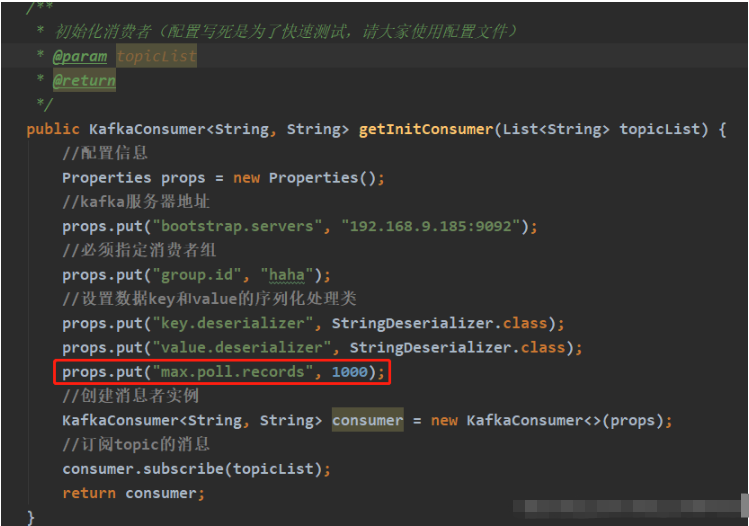
public KafkaConsumer<String, String> getInitConsumer(List<String> topicList) {
//配置信息
Properties props = new Properties();
//kafka服务器地址
props.put("bootstrap.servers", "192.168.9.185:9092");
//必须指定消费者组
props.put("group.id", "haha");
//设置数据key和value的序列化处理类
props.put("key.deserializer", StringDeserializer.class);
props.put("value.deserializer", StringDeserializer.class);
//创建消息者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅topic的消息
consumer.subscribe(topicList);
return consumer;
}
/**
* 开启消费者线程
* 异常请自己根据需求自己处理
*/
@Override
public void afterPropertiesSet() {
// 初始化topic
topicList = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
if (org.apache.commons.collections.CollectionUtils.isNotEmpty(topicList)) {
consumer = getInitConsumer(topicList);
// 开启一个消费者线程
new Thread(() -> {
while (true) {
// 模拟从配置源中获取最新的topic(字符串,逗号隔开)
final List<String> newTopic = Splitter.on(",").splitToList(Objects.requireNonNull(getNewTopic()));
// 如果topic发生变化
if (!topicList.equals(newTopic)) {
log.info("topic 发生变化:newTopic:{},oldTopic:{}-------------------------", newTopic, topicList);
// method one:重新订阅topic:
topicList = newTopic;
consumer.subscribe(newTopic);
// method two:关闭原来的消费者,重新初始化一个消费者
//consumer.close();
//topicList = newTopic;
//consumer = getInitConsumer(newTopic);
continue;
}
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("key:" + record.key() + "" + ",value:" + record.value());
}
}
}).start();
}
}
}Parlons de la 72ème ligne de code :
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
La ligne de code ci-dessus signifie : en 100 ms Attendez que le courtier de Kafka renvoie les données. Le paramètre supermarché spécifie combien de temps après le retour du sondage, que des données soient disponibles ou non.
Après avoir modifié le sujet, vous devez attendre que les messages extraits de ce sondage soient traités, et détecter les changements dans le sujet pendant la boucle while (true) avant de pouvoir vous réabonner au sujet. Le nombre par défaut de messages obtenus par. la méthode poll() à la fois est la suivante : 500, comme indiqué ci-dessous, est défini dans le code source du client kafka.
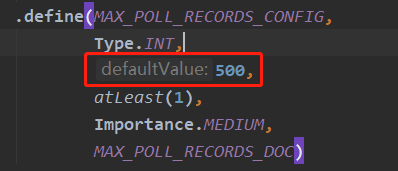 Si vous souhaitez personnaliser cette configuration, vous pouvez ajouter les
Si vous souhaitez personnaliser cette configuration, vous pouvez ajouter les
 résultats d'exécution lors de l'initialisation du consommateur (il n'y a aucune donnée dans le sujet testé)
résultats d'exécution lors de l'initialisation du consommateur (il n'y a aucune donnée dans le sujet testé)
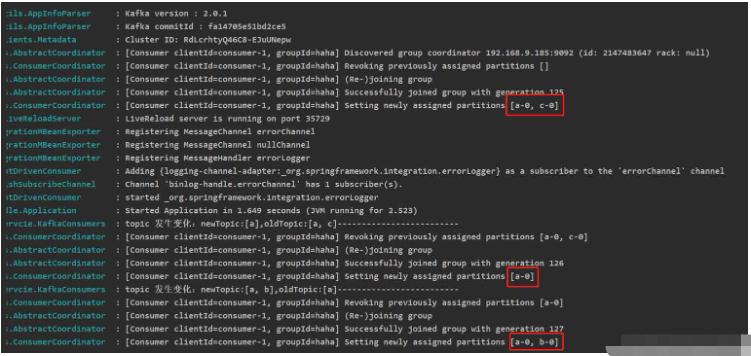 Remarque : KafkaConsumer n'est pas sécurisé pour les threads , n'utilisez pas une seule instance de KafkaConsumer pour ouvrir plusieurs consommateurs. Pour ouvrir plusieurs consommateurs, vous devez créer plusieurs nouvelles instances de KafkaConsumer.
Remarque : KafkaConsumer n'est pas sécurisé pour les threads , n'utilisez pas une seule instance de KafkaConsumer pour ouvrir plusieurs consommateurs. Pour ouvrir plusieurs consommateurs, vous devez créer plusieurs nouvelles instances de KafkaConsumer.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment les assertions Java peuvent-elles améliorer la qualité du code et prévenir les erreurs ?
- La déclaration de chaînes comme « finales » en Java affecte-t-elle les comparaisons « == » ?
- Quelles sont les spécifications d'utilisation du message Java Git Commit ?
- Manipulation de chaînes en Java
- Comment mettre à jour en permanence JLabel avec les résultats d'une tâche de longue durée ?