
Maison >Java >javaDidacticiel >Comment SpringBoot implémente le filtrage des mots sensibles
Comment SpringBoot implémente le filtrage des mots sensibles

- 王林avant
- 2023-05-20 19:28:042215parcourir
Filtrer les mots sensibles

1. Créez un fichier texte pour stocker les mots sensibles à filtrer
Créez d'abord un fichier texte pour stocker les mots sensibles à filtrer
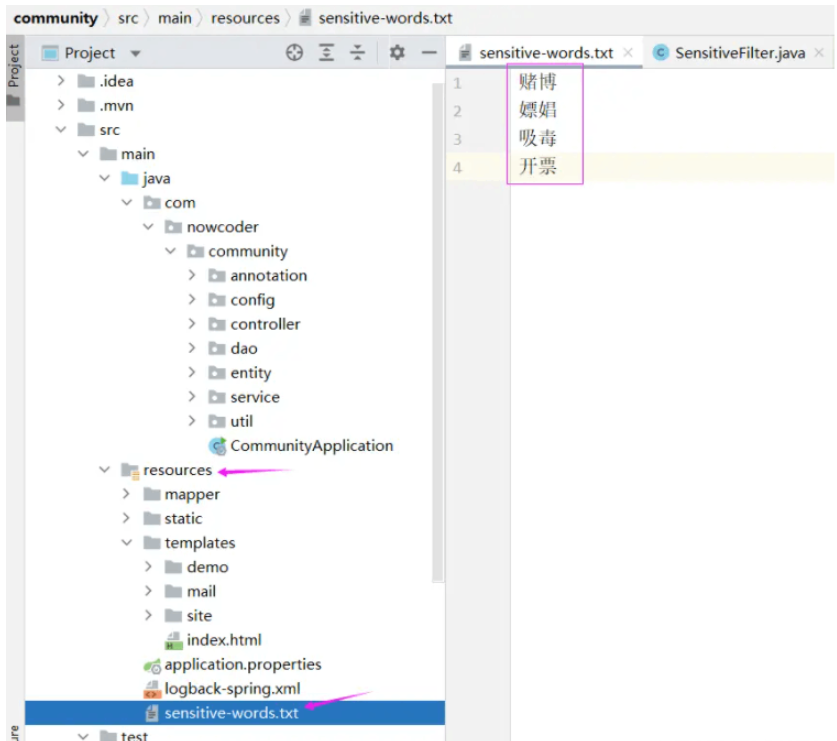
Dans l'outil classe ci-dessous Nous allons lire ce fichier texte, qui est donné ici à l'avance
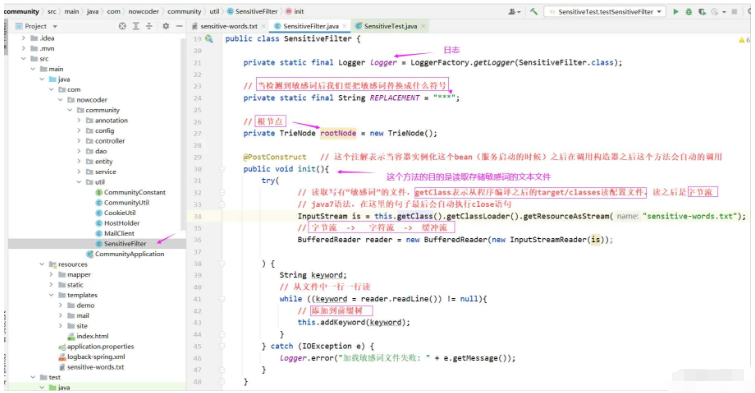
@PostConstruct // 这个注解表示当容器实例化这个bean(服务启动的时候)之后在调用构造器之后这个方法会自动的调用
public void init(){
try(
// 读取写有“敏感词”的文件,getClass表示从程序编译之后的target/classes读配置文件,读之后是字节流
// java7语法,在这里的句子最后会自动执行close语句
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
// 字节流 -> 字符流 -> 缓冲流
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
// 从文件中一行一行读
while ((keyword = reader.readLine()) != null){
// 添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败: " + e.getMessage());
}
}2. Développer une classe d'outils pour filtrer les mots sensibles
Développer un composant pour filtrer les mots sensibles
Afin de faciliter la réutilisation future, nous écrivons une classe d'outils pour filtrer les mots sensibles SensitiveFilter.
@Component
public class SensitiveFilter {
private static final Logger logger = LoggerFactory.getLogger(SensitiveFilter.class);
// 当检测到敏感词后我们要把敏感词替换成什么符号
private static final String REPLACEMENT = "***";
// 根节点
private TrieNode rootNode = new TrieNode();
@PostConstruct // 这个注解表示当容器实例化这个bean(服务启动的时候)之后在调用构造器之后这个方法会自动的调用
public void init(){
try(
// 读取写有“敏感词”的文件,getClass表示从程序编译之后的target/classes读配置文件,读之后是字节流
// java7语法,在这里的句子最后会自动执行close语句
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
// 字节流 -> 字符流 -> 缓冲流
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
// 从文件中一行一行读
while ((keyword = reader.readLine()) != null){
// 添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败: " + e.getMessage());
}
}
// 将一个敏感词添加到前缀树中
private void addKeyword(String keyword){
// 首先默认指向根
TrieNode tempNode = rootNode;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if(subNode == null){
// subNode为空,初始化子节点;subNode不为空,直接用就可以了
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指针指向子节点,进入下一轮循环
tempNode = subNode;
}
// 最后要设置结束标识
tempNode.setKeywordEnd(true);
}
/**
* 过滤敏感词
* @param text 待过滤的文本
* @return 过滤后的文本
*/
public String filter(String text){
if(StringUtils.isBlank(text)){
// 待过滤的文本为空,直接返回null
return null;
}
// 指针1,指向树
TrieNode tempNode = rootNode;
// 指针2,指向正在检测的字符串段的首
int begin = 0;
// 指针3,指向正在检测的字符串段的尾
int position = 0;
// 储存过滤后的文本
StringBuilder sb = new StringBuilder();
while (begin < text.length()){
char c = text.charAt(position);
// 跳过符号,比如 “开票”是敏感词 #开#票# 这个字符串中间的 '#' 应该跳过
if(isSymbol(c)){
// 是特殊字符
// 若指针1处于根节点,将此符号计入结果,指针2、3向右走一步
if(tempNode == rootNode){
sb.append(c);
begin++;
}
// 无论符号在开头或中间,指针3都向下走一步
position++;
// 符号处理完,进入下一轮循环
continue;
}
// 执行到这里说明字符不是特殊符号
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if(tempNode == null){
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = rootNode;
} else if(tempNode.isKeywordEnd()){
// 发现敏感词,将begin~position字符串替换掉,存 REPLACEMENT (里面是***)
sb.append(REPLACEMENT);
// 进入下一个位置
begin = ++position;
// 重新指向根节点
tempNode = rootNode;
} else {
// 检查下一个字符
position++;
}
}
return sb.toString();
}
// 判断是否为特殊符号,是则返回true,不是则返回false
private boolean isSymbol(Character c){
// CharUtils.isAsciiAlphanumeric(c)方法:a、b、1、2···返回true,特殊字符返回false
// 0x2E80 ~ 0x9FFF 是东亚的文字范围,东亚文字范围我们不认为是符号
return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
// 前缀树
private class TrieNode{
// 关键词结束标识
private boolean isKeywordEnd = false;
// 当前节点的子节点(key是下级字符、value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node){
subNodes.put(c, node);
}
// 获取子节点
public TrieNode getSubNode(Character c){
return subNodes.get(c);
}
}
}
Ce qui précède est tout le code de la classe d'outils de filtrage des mots sensibles. Ensuite, expliquons les étapes de développement
Le développement du composant de filtrage des mots sensibles est divisé en trois étapes :
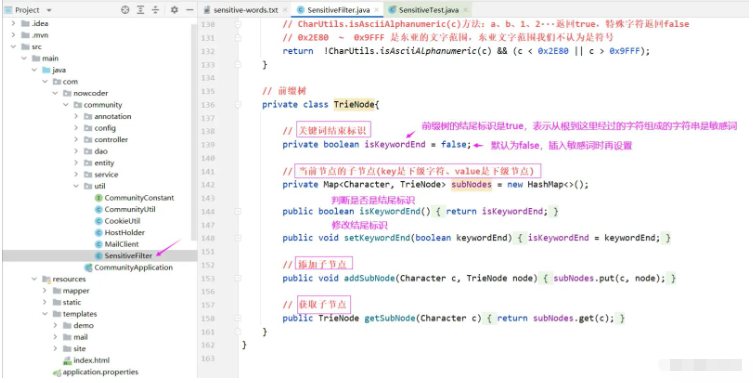
1. Définir l'arborescence des préfixes. (Arbre)
Nous allons définir l'arborescence des préfixes comme la classe interne de la classe d'outils SensitiveFilter
// 前缀树
private class TrieNode{
// 关键词结束标识
private boolean isKeywordEnd = false;
// 当前节点的子节点(key是下级字符、value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node){
subNodes.put(c, node);
}
// 获取子节点
public TrieNode getSubNode(Character c){
return subNodes.get(c);
}
}
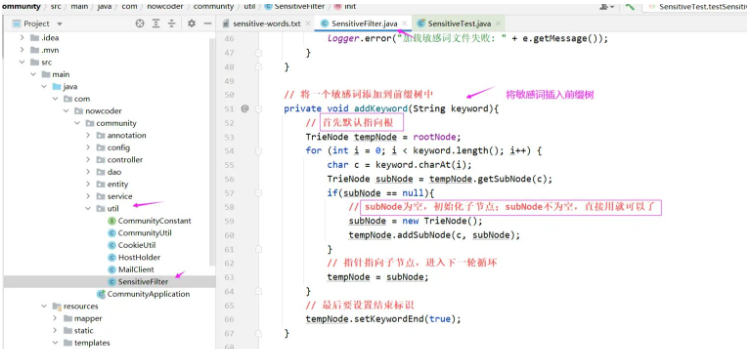
2. à l'arbre des préfixes
// 将一个敏感词添加到前缀树中
private void addKeyword(String keyword){
// 首先默认指向根
TrieNode tempNode = rootNode;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if(subNode == null){
// subNode为空,初始化子节点;subNode不为空,直接用就可以了
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指针指向子节点,进入下一轮循环
tempNode = subNode;
}
// 最后要设置结束标识
tempNode.setKeywordEnd(true);
}
 3. Écrivez une méthode pour filtrer les mots sensibles
3. Écrivez une méthode pour filtrer les mots sensibles
Comment filtrer les mots sensibles dans le texte :
Comment gérer les symboles spéciaux : 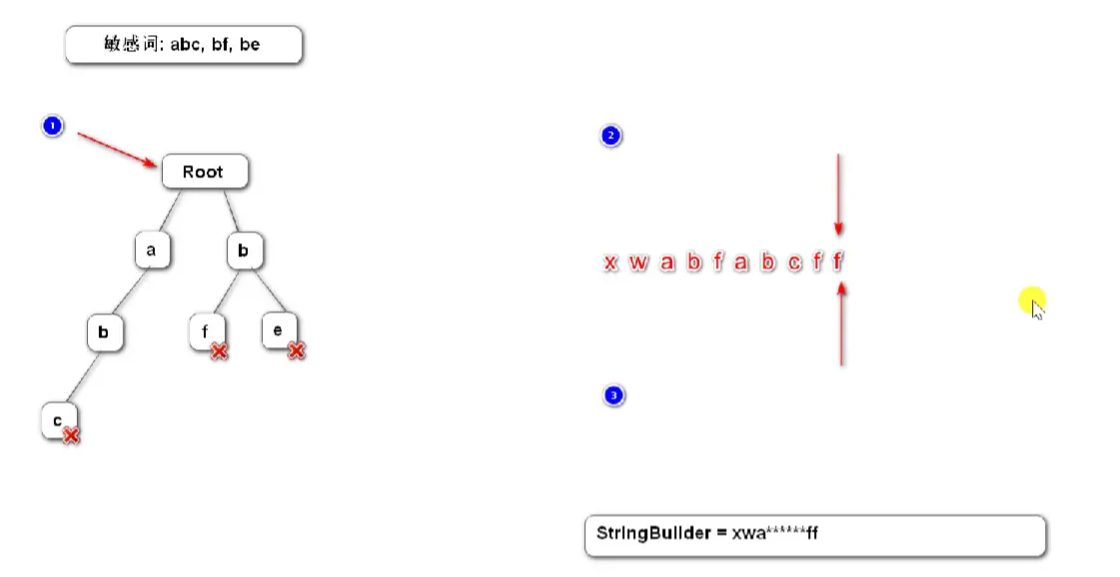
Après l'arbre des préfixes de mots sensibles est initialisé, filtrer les mots sensibles dans le texte L'algorithme doit être le suivant : 
- Pointeur 1
- pointe vers le
Arbre arbre
Pointeur 2 - pointe vers la
tête du segment de chaîne à filtrer Enfin : il Il est recommandé de le tester dans la classe de test
Après le test, la classe d'outils de filtrage des mots sensibles a été développée. Cet outil sera utilisé dans la prochaine Fonction Post - .
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!