
Maison >Périphériques technologiques >IA >Choisir le meilleur GPU pour le deep learning
Choisir le meilleur GPU pour le deep learning

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-20 17:04:061885parcourir
Lorsque vous travaillez sur des projets d'apprentissage automatique, en particulier lorsqu'il s'agit de deep learning et de réseaux de neurones, il est préférable de travailler avec un GPU plutôt qu'un CPU car même un GPU très basique surpassera un CPU en matière de réseaux de neurones.

Mais quel GPU devriez-vous acheter ? Cet article résume les facteurs pertinents à prendre en compte afin que vous puissiez prendre une décision en fonction de votre budget et de votre modélisation spécifique ? exigences. Un choix intelligent.
Pourquoi le GPU est-il meilleur pour le machine learning que le CPU ?
CPU (Central Processing Unit) est le travail principal de l'ordinateur. Il est très flexible. Il doit non seulement traiter les instructions de divers programmes et matériels, mais a également certaines exigences en matière de vitesse de traitement. Pour bien fonctionner dans cet environnement multitâche, un processeur dispose d'un petit nombre d'unités de traitement flexibles et rapides (également appelées cœurs).
GPU (Graphics Processing Unit) Le GPU n'est pas si flexible en matière de multitâche. Mais il peut effectuer en parallèle un grand nombre de calculs mathématiques complexes. Ceci est obtenu grâce à un plus grand nombre de cœurs simples (des milliers à des dizaines de milliers) capables de gérer simultanément de nombreux calculs simples.
L'obligation d'effectuer plusieurs calculs en parallèle est idéale pour :
- Rendu graphique - les objets graphiques en mouvement doivent constamment calculer leurs trajectoires, ce qui nécessite beaucoup de Calculs mathématiques parallèles répétés.
- Machine et deep learning - un grand nombre de calculs matriciels/tenseurs, le GPU peut traiter en parallèle.
- Tout type de calcul mathématique peut être divisé pour être exécuté en parallèle.
Les principales différences entre CPU et GPU ont été résumées sur le blog de Nvidia : Processing Unit (TPU)
Avec le développement de l'intelligence artificielle et de la machine/deep apprentissage, il existe désormais des cœurs de traitement plus spécialisés appelés cœurs tenseurs. Ils sont plus rapides et plus efficaces lors de l’exécution de calculs tenseurs/matrices. Parce que le type de données que nous traitons dans l’apprentissage automatique/profond est celui des tenseurs. 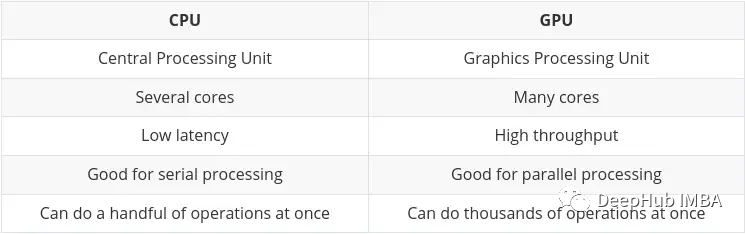
De quelle quantité de mémoire dispose le GPU ?
Combien de cœurs CUDA et/ou tenseurs le GPU possède-t-il ?
Quelle est l'architecture de la puce l'utilisation de la carte ?
- Quelles sont les exigences en matière de consommation électrique (le cas échéant) ?
- Nous explorerons ces aspects un par un ci-dessous, en espérant vous permettre de mieux comprendre ce qui est important pour vous.
- Mémoire GPU
- La réponse est : plus on est de fous, plus on est de fous
4GB : Je pense que c'est le minimum absolu, tant que vous n'avez pas affaire à un modèle trop complexe, ou Pour de grandes images, vidéo ou audio, cela fonctionnera dans la plupart des situations, mais ce ne sera pas suffisant pour un usage quotidien. Si vous débutez et que vous voulez l'essayer mais que vous ne voulez pas vous lancer à fond, vous pouvez commencer par
8GB : C'est un bon début pour l'apprentissage quotidien et vous pouvez en faire le maximum sans dépasser la limite de RAM, mais peut rencontrer des problèmes lorsque vous travaillez avec des modèles d'image, vidéo ou audio plus complexes.
12GB : Je pense que c'est l'exigence la plus fondamentale pour la recherche scientifique. Peut gérer la plupart des modèles plus grands, même ceux travaillant avec des images, de la vidéo ou de l'audio.
- 12GB+ : Plus il y en a, mieux c'est, vous serez en mesure de gérer des ensembles de données plus volumineux et des lots de plus grande taille. Au-dessus de 12 Go, c’est là que les prix commencent vraiment à augmenter.
- D'une manière générale, si le coût est le même, il vaut mieux choisir une carte "plus lente" avec plus de mémoire. Gardez à l’esprit que l’avantage des GPU est leur débit élevé, qui dépend fortement de la RAM disponible pour transférer les données via le GPU.
- Cœur CUDA et noyau Tensor
- C'est en fait très simple, plus il y en a, mieux c'est.
Mais cela n'a pas d'importance car les noyaux CUDA sont déjà assez rapides. Si vous pouvez obtenir une carte comprenant des cœurs Tensor, c'est un avantage appréciable, mais ne vous y attardez pas trop.
Vous verrez "CUDA" mentionné plusieurs fois plus tard, résumons-le d'abord :
Cœurs CUDA - ce sont les processeurs physiques de la carte graphique, il y en a généralement des milliers, et le 4090 en a 16 000.
CUDA 11 - Les chiffres peuvent changer, mais cela fait référence aux logiciels/pilotes installés pour permettre à la carte graphique de fonctionner correctement. NV publie régulièrement de nouvelles versions et peut être installé et mis à jour comme n'importe quel autre logiciel.
CUDA Generation (ou Compute Power) - Ceci décrit le nom de code de la carte graphique dans sa nouvelle itération. Ceci est corrigé sur le matériel et ne peut donc être modifié qu'en effectuant une mise à niveau vers une nouvelle carte. Il se distingue par des chiffres et un nom de code. Exemple : 3. x[Kepler],5. x[Maxwell], 6. x [Pascal], 7. x[Turing] et 8. x(Ampère).
Chip Architecture
C'est en fait plus important que vous ne le pensez. Nous ne parlons pas de DMLA ici, je n'ai que "Old Huang" dans les yeux.
Nous avons déjà mentionné ci-dessus que les cartes de la série 30 sont à architecture Ampère et que les dernières cartes de la série 40 sont Ada Lovelace. Habituellement, Huang donne à l'architecture le nom d'un célèbre scientifique et mathématicien. Cette fois, il a choisi Ada Lovelace, la fille du célèbre poète britannique Byron, la mathématicienne et fondatrice de programmes informatiques qui a établi les concepts de boucles et de sous-programmes.
Pour comprendre la puissance de calcul de la carte, nous devons comprendre 2 aspects :
- Améliorations fonctionnelles significatives
- Une caractéristique importante ici est l'entraînement à précision mixte :
Utiliser des nombres avec une précision inférieure à la virgule flottante de 32 bits nombres Le format présente de nombreux avantages. Premièrement, ils nécessitent moins de mémoire, ce qui permet la formation et le déploiement de réseaux neuronaux plus vastes. Deuxièmement, ils nécessitent moins de bande passante mémoire, accélérant ainsi les opérations de transfert de données. Les troisièmes opérations mathématiques s'exécutent plus rapidement avec une précision réduite, en particulier sur les GPU dotés de cœurs Tensor. L'entraînement de précision mixte offre tous ces avantages tout en garantissant aucune perte de précision spécifique à une tâche par rapport à un entraînement de précision complète. Pour ce faire, il identifie les étapes qui nécessitent une précision totale et utilise une virgule flottante 32 bits uniquement pour ces étapes et une virgule flottante 16 bits partout ailleurs.
Voici le document officiel de Nvidia, si vous êtes intéressé, vous pouvez y jeter un oeil :
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html
Si votre GPU a une architecture 7.x (Turing) ou supérieure, une formation de précision hybride est possible. Cela signifie la série RTX 20 ou supérieure sur le bureau, ou la série « T » ou « A » sur le serveur.
La principale raison pour laquelle l'entraînement de précision mixte présente de tels avantages est qu'il réduit l'utilisation de la RAM. Le GPU de Tensor Core accélérera l'entraînement de précision mixte. Dans le cas contraire, l'utilisation de FP16 permettra également d'économiser de la mémoire vidéo et pourra entraîner des lots de plus grande taille, améliorant indirectement la vitesse d'entraînement. .
Sera-t-il obsolète
Si vous avez des besoins particulièrement élevés en RAM mais que vous n'avez pas assez d'argent pour acheter une carte haut de gamme, vous pouvez choisir un GPU plus ancien sur le marché de l'occasion. Il y a un gros inconvénient à cela... la vie de la carte est terminée.
Un exemple typique est le Tesla K80, qui possède 4992 cœurs CUDA et 24 Go de RAM. En 2014, il se vendait environ 7 000 $. Le prix actuel varie de 150 à 170 dollars américains ! (Le prix du poisson salé est d'environ 600-700) Vous devez être très excité d'avoir une si grande mémoire à un si petit prix.
Mais il y a un très gros problème. L'architecture informatique du K80 est 3.7 (Kepler), qui n'est plus prise en charge à partir de CUDA 11 (la version actuelle de CUDA est 11.7). Cela signifie que la carte a expiré, c'est pourquoi elle est vendue à un prix si bas.
Ainsi, lorsque vous choisissez une carte d'occasion, assurez-vous de vérifier si elle prend en charge la dernière version du pilote et de CUDA. C'est la chose la plus importante.
Cartes de jeu haut de gamme VS cartes de poste de travail/serveur
Lao Huang a essentiellement divisé la carte en deux parties. Cartes graphiques grand public et cartes graphiques pour postes de travail/serveurs (c'est-à-dire cartes graphiques professionnelles).
Il y a une nette différence entre les deux parties, pour les mêmes spécifications (RAM, cœurs CUDA, architecture), les cartes graphiques grand public sont généralement moins chères. Mais les cartes professionnelles ont généralement une meilleure qualité et une consommation d'énergie moindre (en fait, le bruit de la turbine est assez fort, ce qui est bien lorsqu'elle est placée dans une salle informatique, mais un peu bruyant lorsqu'elle est placée à la maison ou dans un laboratoire).
Cartes professionnelles haut de gamme (très chères), vous remarquerez peut-être qu'elles ont beaucoup de RAM (ex : RTX A6000 a 48 Go, A100 a 80 Go !). En effet, ils ciblent généralement les marchés professionnels de la modélisation 3D, du rendu et de l’apprentissage automatique/deep learning, qui nécessitent des niveaux élevés de RAM. Encore une fois, si vous avez de l'argent, achetez simplement du A100 ! (Le H100 est une nouvelle version du A100 et ne peut pas être évalué pour le moment)
Mais je pense personnellement que nous devrions choisir des cartes de jeu grand public haut de gamme, car si vous n'en manquez pas, l'argent, vous Vous ne lirez pas non plus cet article, n'est-ce pas ?
Choisissez des suggestions
Donc à la fin, je fais quelques suggestions en fonction du budget et des besoins. Je l'ai divisé en trois parties :
- Petit budget
- Budget moyen
- Budget élevé
Un budget élevé ne prend en compte rien au-delà des cartes graphiques grand public haut de gamme. Encore une fois, si vous avez de l'argent : achetez A100 ou H100.
Cet article inclura les cartes achetées sur le marché de l'occasion. C’est principalement parce que je pense que l’occasion est quelque chose à considérer si vous avez un petit budget. Les cartes Professional Desktop Series (T600, A2000 et A4000) sont également incluses ici, car certaines de leurs configurations sont légèrement pires que celles des cartes graphiques grand public similaires, mais la consommation électrique est nettement meilleure.
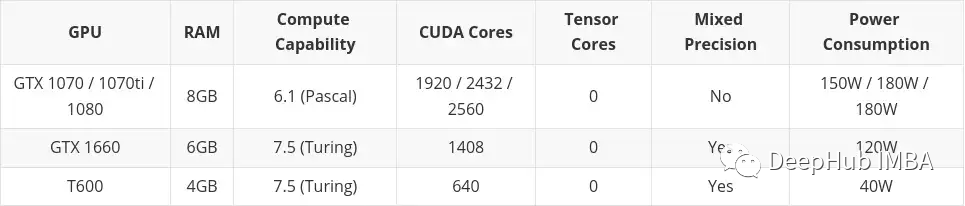
Petit budget
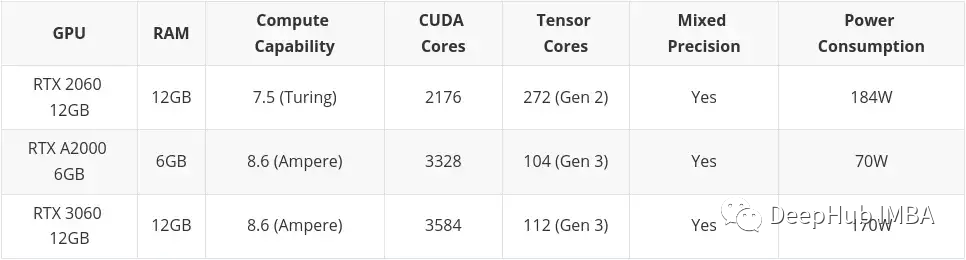
Budget moyen
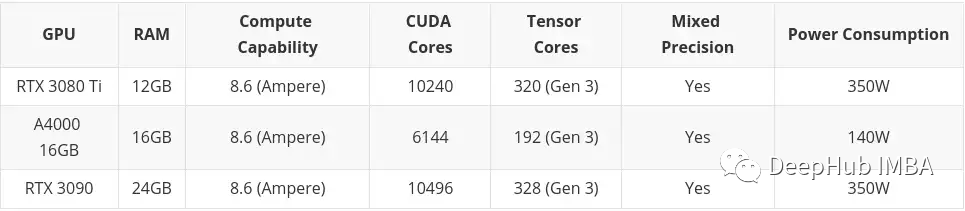
Budget élevé
Services en ligne/cloud
Si vous décidez que dépenser de l'argent pour une carte graphique n'est pas pour vous, vous pouvez profiter de Google Colab, qui vous permet d'utiliser gratuitement le GPU.
Mais il y a une limite de temps, si vous utilisez le GPU trop longtemps, ils vous expulseront et reviendront au CPU. Il récupérera également le GPU s'il reste inactif pendant trop longtemps, éventuellement pendant que vous écrivez du code. Le GPU est également automatiquement alloué, vous ne pouvez donc pas choisir le GPU exact que vous souhaitez (vous pouvez également obtenir un Colab Pro pour 9,99 $ par mois, ce que je pense personnellement est bien meilleur que le budget inférieur, mais nécessite une échelle, et le 49,99 $ Colab Pro+ est un peu cher, non recommandé).
Au moment de la rédaction, les GPU suivants sont disponibles via Colab :
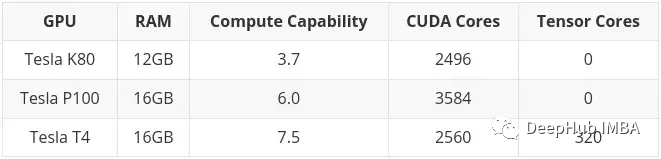
Comme mentionné précédemment, le K80 dispose de 24 Go de RAM et de 4992 cœurs CUDA, soit essentiellement deux cartes K40 reliées entre elles. Cela signifie que lorsque vous utilisez le K80 dans Colab, vous avez en fait accès à la moitié de la carte, soit seulement 12 Go et 2 496 cœurs CUDA.
Résumé
Au final, le 4090 est toujours à l'état de singe. En gros, il faut se précipiter pour l'acheter ou trouver des scalpers à un prix plus élevé
Mais 16384 CUDA + 24Go, par rapport aux 10496 CUDA du 3090. , c'est vraiment bien.
Et si le prix du 4080 16G 9728CUDA peut atteindre 7000, cela devrait être un choix très rentable. Ne considérez pas le 12G 4080, il ne mérite pas ce nom.
Le 7900XTX d'AMD devrait également être un bon choix, mais la compatibilité est un gros problème. Si quelqu'un le teste, vous pouvez laisser un message.
Lao Huang a joué des tours sur la série 40, alors si vous n'êtes pas pressé, attendez encore un peu :
Vous ne l'achetez pas, je ne l'achète pas, et il sera réduit à 200 heures demain
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI