
Maison >développement back-end >Tutoriel Python >Quel est le principe de mise en œuvre du dictionnaire dans la machine virtuelle Python
Quel est le principe de mise en œuvre du dictionnaire dans la machine virtuelle Python

- 王林avant
- 2023-05-19 20:19:04903parcourir
Analyse de la structure des données du dictionnaire
/* The ma_values pointer is NULL for a combined table
* or points to an array of PyObject* for a split table
*/
typedef struct {
PyObject_HEAD
Py_ssize_t ma_used;
PyDictKeysObject *ma_keys;
PyObject **ma_values;
} PyDictObject;
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
Py_ssize_t dk_size;
dict_lookup_func dk_lookup;
Py_ssize_t dk_usable;
PyDictKeyEntry dk_entries[1];
};
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;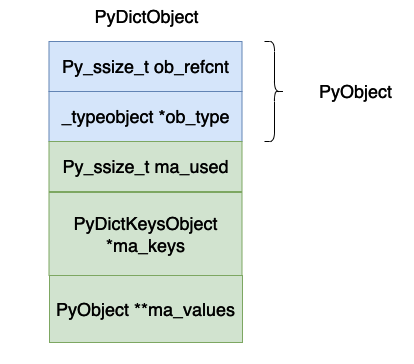
La signification de chaque champ ci-dessus est :
- # 🎜🎜#ob_refcnt, le nombre de références de l'objet.
- ob_type, le type de données de l'objet.
- ma_used, le nombre de données dans la table de hachage actuelle.
- ma_keys, pointe vers le tableau contenant les paires clé-valeur.
- ma_values, cela pointe vers un tableau de valeurs, mais cette valeur n'est pas nécessairement utilisée dans l'implémentation spécifique de python, car les objets du tableau PyDictKeyEntry dans _dictkeysobject peuvent également être une valeur stockée. Cette valeur ne peut être utilisée que lorsque toutes les clés sont des chaînes. Dans cet article, la valeur dans PyDictKeyEntry est principalement utilisée pour discuter de l'implémentation du dictionnaire, vous pouvez donc ignorer cette variable.
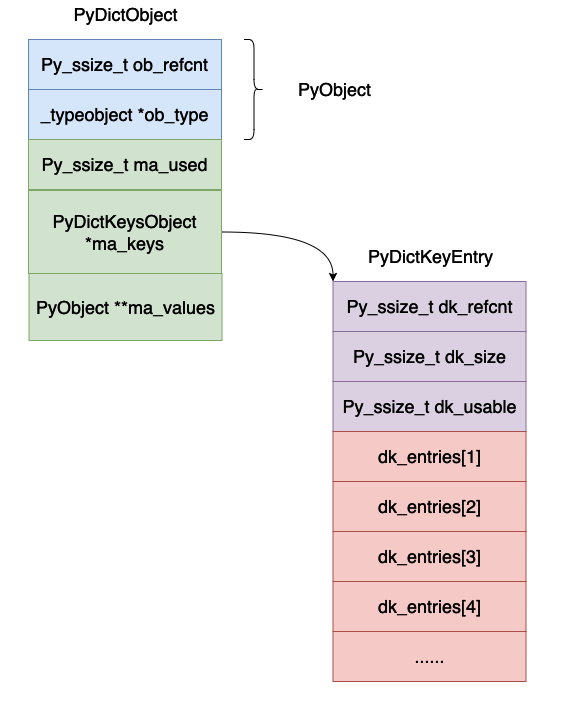
- dk_refcnt, ceci est également utilisé pour représenter le comptage de références. Ceci est lié à la vue du dictionnaire. Le principe est similaire au comptage de références, donc je m'en fiche. ça pour l'instant.
- dk_size, cela représente la taille de la table de hachage, qui doit être 2n. Dans ce cas, l'opération modulaire peut être transformée en une opération ET au niveau du bit.
- dk_lookup, cela représente la fonction de recherche de la table de hachage, c'est un pointeur de fonction.
- dk_usable, indique le nombre de paires clé-valeur disponibles dans le tableau actuel.
- dk_entries, table de hachage, où les paires clé-valeur sont réellement stockées.
static PyObject *
dict_new(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
PyObject *self;
PyDictObject *d;
assert(type != NULL && type->tp_alloc != NULL);
// 申请内存空间
self = type->tp_alloc(type, 0);
if (self == NULL)
return NULL;
d = (PyDictObject *)self;
/* The object has been implicitly tracked by tp_alloc */
if (type == &PyDict_Type)
_PyObject_GC_UNTRACK(d);
// 因为还没有增加数据 因此哈希表当中 ma_used = 0
d->ma_used = 0;
// 申请保存键值对的数组 PyDict_MINSIZE_COMBINED 是一个宏定义 值为 8 表示哈希表数组的最小长度
d->ma_keys = new_keys_object(PyDict_MINSIZE_COMBINED);
// 如果申请失败返回 NULL
if (d->ma_keys == NULL) {
Py_DECREF(self);
return NULL;
}
return self;
}
// new_keys_object 函数如下所示
static PyDictKeysObject *new_keys_object(Py_ssize_t size)
{
PyDictKeysObject *dk;
Py_ssize_t i;
PyDictKeyEntry *ep0;
assert(size >= PyDict_MINSIZE_SPLIT);
assert(IS_POWER_OF_2(size));
// 这里是申请内存的位置真正申请内存空间的大小为 PyDictKeysObject 的大小加上 size-1 个PyDictKeyEntry的大小
// 这里你可能会有一位为啥不是 size 个 PyDictKeyEntry 的大小 因为在结构体 PyDictKeysObject 当中已经申请了一个 PyDictKeyEntry 对象了
dk = PyMem_MALLOC(sizeof(PyDictKeysObject) +
sizeof(PyDictKeyEntry) * (size-1));
if (dk == NULL) {
PyErr_NoMemory();
return NULL;
}
// 下面主要是一些初始化的操作 dk_refcnt 设置成 1 因为目前只有一个字典对象使用 这个 PyDictKeysObject 对象
DK_DEBUG_INCREF dk->dk_refcnt = 1;
dk->dk_size = size; // 哈希表的大小
// 下面这行代码主要是表示哈希表当中目前还能存储多少个键值对 在 cpython 的实现当中允许有 2/3 的数组空间去存储数据 超过这个数则需要进行扩容
dk->dk_usable = USABLE_FRACTION(size); // #define USABLE_FRACTION(n) ((((n) << 1)+1)/3)
ep0 = &dk->dk_entries[0];
/* Hash value of slot 0 is used by popitem, so it must be initialized */
ep0->me_hash = 0;
// 将所有的键值对初始化成 NULL
for (i = 0; i < size; i++) {
ep0[i].me_key = NULL;
ep0[i].me_value = NULL;
}
dk->dk_lookup = lookdict_unicode_nodummy;
return dk;
}Mécanisme d'expansion de la table de hachageTout d'abord, comprenons le mécanisme d'expansion de la table de hachage dans l'implémentation du dictionnaire Lorsque nous continuerons à ajouter de nouvelles données au dictionnaire, bientôt. les données du dictionnaire atteindront 23 de la longueur du tableau. À ce stade, elles doivent être étendues. La taille du tableau après expansion est calculée comme suit : #define GROWTH_RATE(d) (((d)->ma_used*2)+((d)->ma_keys->dk_size>>1))La taille du nouveau tableau est égale. à la paire clé-valeur d'origine Le nombre est multiplié par 2 plus la moitié de la longueur du tableau d'origine. En général, il y a trois étapes principales pour l'expansion :
- Calculez la taille du nouveau tableau.
- Créez un nouveau tableau.
- Ajoutez les données de la table de hachage d'origine au nouveau tableau (c'est-à-dire le processus de re-hachage).
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}
static int
dictresize(PyDictObject *mp, Py_ssize_t minused)
{
Py_ssize_t newsize;
PyDictKeysObject *oldkeys;
PyObject **oldvalues;
Py_ssize_t i, oldsize;
// 下面的代码的主要作用就是计算得到能够大于等于 minused 最小的 2 的整数次幂
/* Find the smallest table size > minused. */
for (newsize = PyDict_MINSIZE_COMBINED;
newsize <= minused && newsize > 0;
newsize <<= 1)
;
if (newsize <= 0) {
PyErr_NoMemory();
return -1;
}
oldkeys = mp->ma_keys;
oldvalues = mp->ma_values;
/* Allocate a new table. */
// 创建新的数组
mp->ma_keys = new_keys_object(newsize);
if (mp->ma_keys == NULL) {
mp->ma_keys = oldkeys;
return -1;
}
if (oldkeys->dk_lookup == lookdict)
mp->ma_keys->dk_lookup = lookdict;
oldsize = DK_SIZE(oldkeys);
mp->ma_values = NULL;
/* If empty then nothing to copy so just return */
if (oldsize == 1) {
assert(oldkeys == Py_EMPTY_KEYS);
DK_DECREF(oldkeys);
return 0;
}
/* Main loop below assumes we can transfer refcount to new keys
* and that value is stored in me_value.
* Increment ref-counts and copy values here to compensate
* This (resizing a split table) should be relatively rare */
if (oldvalues != NULL) {
for (i = 0; i < oldsize; i++) {
if (oldvalues[i] != NULL) {
Py_INCREF(oldkeys->dk_entries[i].me_key);
oldkeys->dk_entries[i].me_value = oldvalues[i];
}
}
}
/* Main loop */
// 将原来数组当中的元素加入到新的数组当中
for (i = 0; i < oldsize; i++) {
PyDictKeyEntry *ep = &oldkeys->dk_entries[i];
if (ep->me_value != NULL) {
assert(ep->me_key != dummy);
insertdict_clean(mp, ep->me_key, ep->me_hash, ep->me_value);
}
}
// 更新一下当前哈希表当中能够插入多少数据
mp->ma_keys->dk_usable -= mp->ma_used;
if (oldvalues != NULL) {
/* NULL out me_value slot in oldkeys, in case it was shared */
for (i = 0; i < oldsize; i++)
oldkeys->dk_entries[i].me_value = NULL;
assert(oldvalues != empty_values);
free_values(oldvalues);
DK_DECREF(oldkeys);
}
else {
assert(oldkeys->dk_lookup != lookdict_split);
if (oldkeys->dk_lookup != lookdict_unicode_nodummy) {
PyDictKeyEntry *ep0 = &oldkeys->dk_entries[0];
for (i = 0; i < oldsize; i++) {
if (ep0[i].me_key == dummy)
Py_DECREF(dummy);
}
}
assert(oldkeys->dk_refcnt == 1);
DK_DEBUG_DECREF PyMem_FREE(oldkeys);
}
return 0;
}Insérer des données dans le dictionnaire Nous ajoutons constamment des données au dictionnaire Lors de l'insertion de données, vous risquez de rencontrer des conflits de hachage. La méthode de gestion des conflits de hachage dans les dictionnaires est fondamentalement la même que la méthode de gestion des conflits de hachage dans les collections. Ils utilisent tous deux la méthode d'adresse de développement, mais cette méthode d'adresse ouverte. est mis en œuvre. C'est relativement compliqué. La procédure spécifique est la suivante : static void
insertdict_clean(PyDictObject *mp, PyObject *key, Py_hash_t hash,
PyObject *value)
{
size_t i;
size_t perturb;
PyDictKeysObject *k = mp->ma_keys;
// 首先得到 mask 的值
size_t mask = (size_t)DK_SIZE(k)-1;
PyDictKeyEntry *ep0 = &k->dk_entries[0];
PyDictKeyEntry *ep;
i = hash & mask;
ep = &ep0[i];
for (perturb = hash; ep->me_key != NULL; perturb >>= PERTURB_SHIFT) {
// 下面便是遇到哈希冲突时的处理办法
i = (i << 2) + i + perturb + 1;
ep = &ep0[i & mask];
}
assert(ep->me_value == NULL);
ep->me_key = key;
ep->me_hash = hash;
ep->me_value = value;
}.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:
Cet article est reproduit dans:. en cas de violation, veuillez contacter admin@php.cn Supprimer
Article précédent:Comment utiliser Netmiko pour le transfert de fichiers en PythonArticle suivant:Comment utiliser Netmiko pour le transfert de fichiers en Python