
Maison >Périphériques technologiques >IA >Exploration et pratique de la technologie de pertinence de recherche Dianping
Exploration et pratique de la technologie de pertinence de recherche Dianping

- 王林avant
- 2023-05-19 19:04:04925parcourir
Auteur : Xiaoya Shen Yuan, Judy, etc.
1. Contexte
La recherche Dianping est l'une des principales entrées de l'application Dianping. Les utilisateurs utilisent la recherche pour trouver des magasins pour les marchands de services de vie dans différents scénarios. . L'objectif à long terme de la recherche est d'optimiser continuellement l'expérience de recherche et d'améliorer la satisfaction des utilisateurs en matière de recherche. Cela nous oblige à comprendre les intentions de recherche des utilisateurs, à mesurer avec précision la corrélation entre les termes de recherche et les marchands, à afficher autant que possible les marchands pertinents et à mieux les classer. commerçants concernés en fonction du transfert. Par conséquent, le calcul de la corrélation entre les termes de recherche et les commerçants est une partie importante de la recherche d’avis.
Les problèmes de pertinence rencontrés par les scénarios de recherche Dianping sont complexes et divers. Les termes de recherche des utilisateurs sont très divers, comme la recherche de noms de commerçants, de plats, d'adresses, de catégories et diverses combinaisons complexes entre eux. il existe également de nombreux types d'informations sur les commerçants, notamment le nom du commerçant, les informations sur l'adresse, les informations sur les commandes de groupe, les informations sur les plats et diverses autres informations sur les installations et les étiquettes, etc., ce qui entraîne des modèles de correspondance extrêmement complexes entre la requête et les commerçants, qui peuvent facilement conduire. à divers problèmes de corrélation. Plus précisément, elle peut être divisée selon les types suivants :
- Incompatibilité de texte : lors de la recherche, afin de garantir qu'un plus grand nombre de marchands sont récupérés et exposés, la requête peut être divisée en mots plus fins. Cela entraînera donc le problème de non-concordance des requêtes avec différents champs du commerçant. Comme le montre la figure 1 (a), l'utilisateur recherchant « potée d'huîtres » devrait rechercher une potée contenant des huîtres dans la base de soupe, tandis que « huîtres » et "potée" Deux plats différents du commerçant sont respectivement assortis.
- Décalage sémantique : la requête correspond littéralement au marchand, mais le marchand n'a aucun rapport sémantique avec l'intention principale de la requête, comme "thé au lait" - "sachet de thé au lait perlé à la cassonade", comme le montre la figure 1 ( b).
- Category offset : La requête correspond littéralement au marchand et est sémantiquement liée, mais la catégorie principale ne correspond pas aux besoins de l'utilisateur. Par exemple, lorsque l'utilisateur recherche « fruit », un marchand KTV qui fournit « fruit ». plate" correspond évidemment aux besoins de l’utilisateur. Non pertinent.
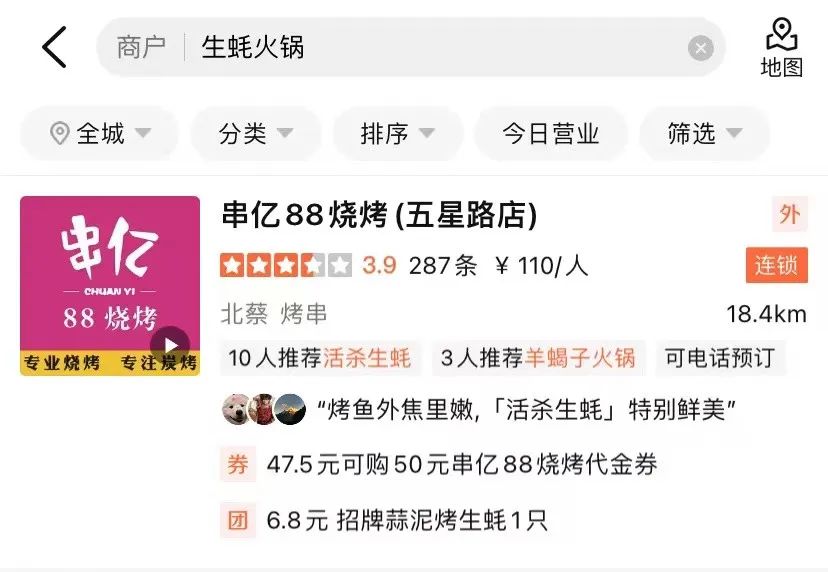
(a) Exemple d'incompatibilité de texte
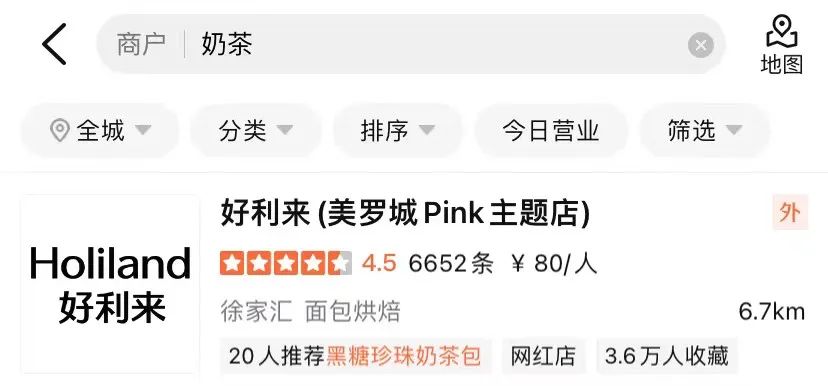
(b) Exemple de décalage sémantique
Figure 1 Exemple de problème de pertinence de recherche d'examen
Basé sur la correspondance littérale La méthode de corrélation ne peut pas traiter efficacement les problèmes ci-dessus.Afin de résoudre divers problèmes non pertinents dans la liste de recherche qui ne répondent pas aux intentions de l'utilisateur, il est nécessaire de caractériser plus précisément la corrélation sémantique profonde entre les termes de recherche et les commerçants. Basé sur le modèle de pré-formation MT-BERT formé sur le corpus commercial massif de Meituan, cet article optimise le modèle de corrélation sémantique profonde entre Query et les commerçants (POI, correspondant à Doc dans les moteurs de recherche généraux) dans les scénarios de recherche Dianping. informations de corrélation entre la requête et le POI dans chaque lien du lien de recherche.
Cet article présentera la technologie de pertinence de recherche d'avis sous quatre aspects : examen des technologies de pertinence de recherche existantes, schéma de calcul de pertinence de recherche d'avis, application pratique, résumé et perspectives. Le chapitre sur le calcul de la pertinence de la recherche Dianping présentera comment nous résolvons les trois principaux défis de la construction des informations d'entrée des commerçants, de l'adaptation du modèle au calcul de la pertinence de la recherche Dianping et de l'optimisation des performances du modèle en ligne. Le chapitre d'application pratique présentera le développement hors ligne du modèle. Modèle de pertinence de recherche Dianping et effets en ligne.
2. Technologie existante de pertinence de recherche
La pertinence de recherche vise à calculer le degré de corrélation entre la requête et le document renvoyé, c'est-à-dire à déterminer si le contenu du document répond aux besoins de la requête de l'utilisateur, correspondant à la correspondance sémantique en PNL. Tâche (Correspondance sémantique). Dans le scénario de recherche de Dianping, la pertinence de la recherche consiste à calculer la corrélation entre la requête de l'utilisateur et le POI du commerçant.
Méthode de correspondance de texte : les premières tâches de correspondance de texte ne prenaient en compte que le degré de correspondance littérale entre Query et Doc et calculaient la corrélation via des fonctionnalités de correspondance basées sur des termes telles que TF-IDF et BM25. L'efficacité du calcul en ligne de la corrélation de correspondance de mots est élevée, mais les performances de généralisation de la correspondance de mots clés basées sur des termes sont médiocres, manquent d'informations sémantiques et sur l'ordre des mots et ne peuvent pas résoudre le problème des significations multiples d'un mot ou de plusieurs mots avec une seule signification, donc Matchs manquants et malentendus Le phénomène de matching est grave.
Modèle de correspondance sémantique traditionnel : Afin de combler les lacunes de la correspondance littérale, le modèle de correspondance sémantique est proposé pour mieux comprendre la corrélation sémantique entre Query et Doc. Les modèles de correspondance sémantique traditionnels incluent principalement la correspondance basée sur un espace implicite : mapper à la fois Query et Doc sur des vecteurs dans le même espace, puis utiliser la distance vectorielle ou la similarité comme scores de correspondance, tels que les moindres carrés partiels (PLS)[1 ] ; et correspondance basée sur le modèle de traduction : faites correspondre Doc après l'avoir mappé à l'espace de requête ou calculez la probabilité que Doc soit traduit en Query[2].
Avec le développement de modèles d'apprentissage profond et de pré-formation, les modèles de correspondance sémantique approfondie sont également largement utilisés dans l'industrie. En termes de méthodes de mise en œuvre, les modèles de correspondance sémantique profonde sont divisés en méthodes basées sur la représentation (Representation-based) et méthodes basées sur l'interaction (Interaction-based). En tant que méthode efficace dans le domaine du traitement du langage naturel, les modèles pré-entraînés sont également largement utilisés dans les tâches de correspondance sémantique. (a) Modèle de corrélation multi-domaines basé sur la représentation
Modèle de correspondance sémantique profonde basé sur la représentation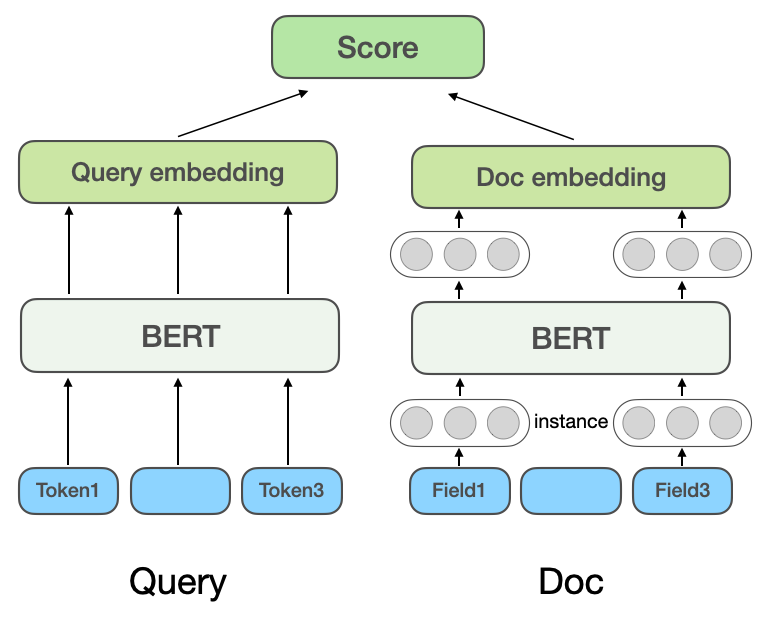 : la méthode basée sur la représentation apprend respectivement les représentations vectorielles sémantiques de Query et Doc, puis calcule la similarité en fonction des deux vecteurs. Le modèle DSSM de Microsoft
: la méthode basée sur la représentation apprend respectivement les représentations vectorielles sémantiques de Query et Doc, puis calcule la similarité en fonction des deux vecteurs. Le modèle DSSM de Microsoft
propose un modèle classique de correspondance de texte à structure à deux tours, qui utilise deux réseaux indépendants pour construire des représentations vectorielles de Query et Doc, et utilise la similarité cosinus pour mesurer la corrélation entre les deux vecteurs. Le NRM[4] de Microsoft Bing Search vise le problème de la représentation du document. En plus du titre et du contenu de base du document, il prend également en compte d'autres informations multi-sources (
Chaque type d'information est appelé un champ Champ), telles que. comme les liens externes et les clics de l'utilisateur sur la requête, etc., considérez qu'il existe plusieurs champs dans un document et qu'il y a plusieurs instances (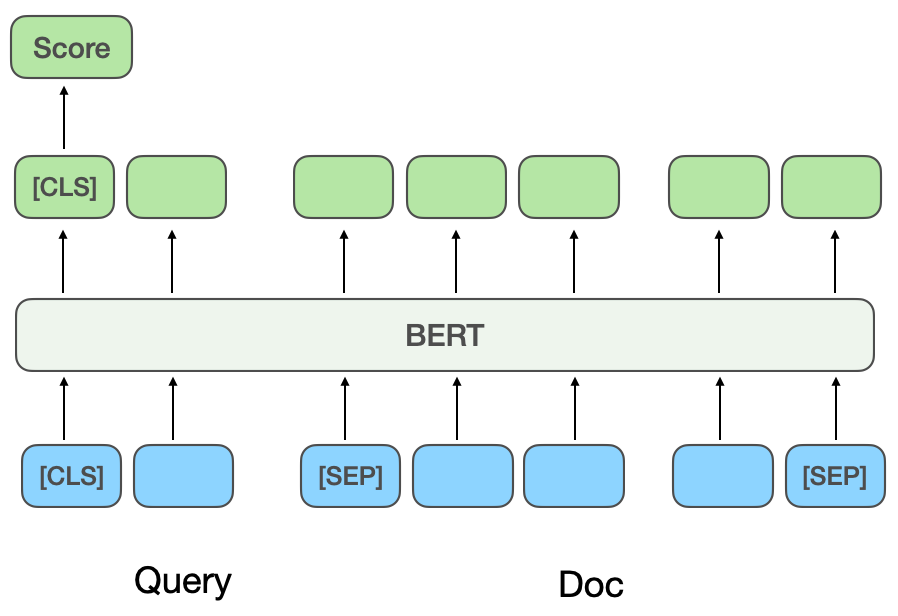 Instance
Instance
[5]Introduit le modèle pré-entraîné BERT dans la couche de codage de Query et Doc of Twin Towers, utilise différentes méthodes de pooling pour obtenir les vecteurs de phrases de Twin Towers et interagit avec Query et Doc via la multiplication de points, l'épissage, etc.
Le premier modèle de pertinence de recherche de Dianping s'est inspiré des idées de NRM et de SentenceBERT et a adopté la structure du modèle de pertinence multidomaine basée sur la représentation présentée dans la figure 2 (a). Il est calculé à l'avance et stocké dans le cache. Seule la partie interactive du vecteur de requête et du vecteur POI est calculée en ligne, la vitesse de calcul est donc plus rapide lorsqu'elle est utilisée en ligne.
Modèle de correspondance sémantique profonde basé sur l'interaction : La méthode basée sur l'interaction n'apprend pas directement les vecteurs de représentation sémantique de Query et Doc, mais permet à Query et Doc d'interagir dans l'étape d'entrée sous-jacente pour établir certains signaux de correspondance de base Les signaux de correspondance de base sont ensuite fusionnés dans un score de correspondance. ESIM[6] est un modèle classique largement utilisé dans l'industrie avant l'introduction des modèles de pré-formation. Tout d'abord, Query et Doc sont codés pour obtenir le vecteur initial, puis le mécanisme Attention est utilisé pour la pondération interactive, puis épissé. avec le vecteur initial, et enfin la corrélation est obtenue par classification Score. Lors de l'introduction du modèle pré-entraîné BERT pour les calculs interactifs, Query et Doc sont généralement épissés comme entrée de la tâche de relation inter-phrases BERT, et le score de corrélation final est obtenu via le réseau MLP [7 ], comme le montre la figure 2(b). CEDR[8]Après avoir obtenu les vecteurs Query et Doc à partir de la tâche de relation inter-phrases BERT, les vecteurs Query et Doc sont divisés et la matrice de similarité cosinus de Query et Doc est ensuite calculée. L'équipe de recherche Meituan[9] a introduit des méthodes basées sur l'interaction dans le modèle de corrélation de recherche Meituan, introduit des informations sur les catégories de commerçants pour la pré-formation et introduit des tâches de reconnaissance d'entités pour l'apprentissage multitâche. L'équipe de publicité de recherche en magasin Meituan [10]
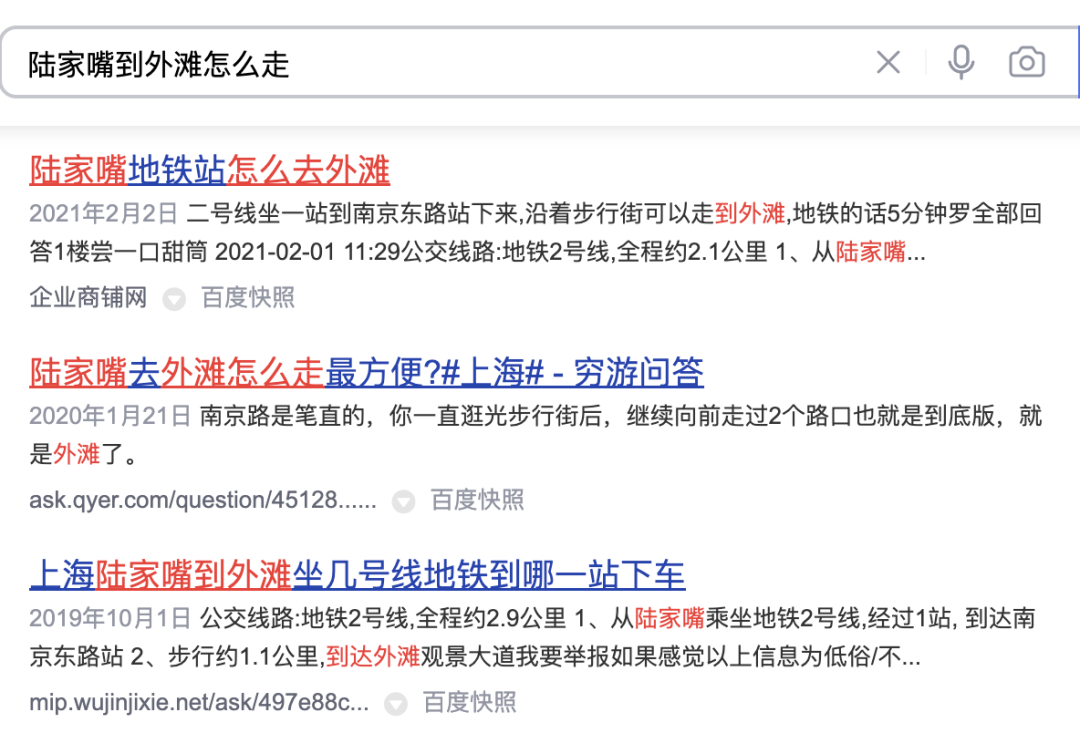
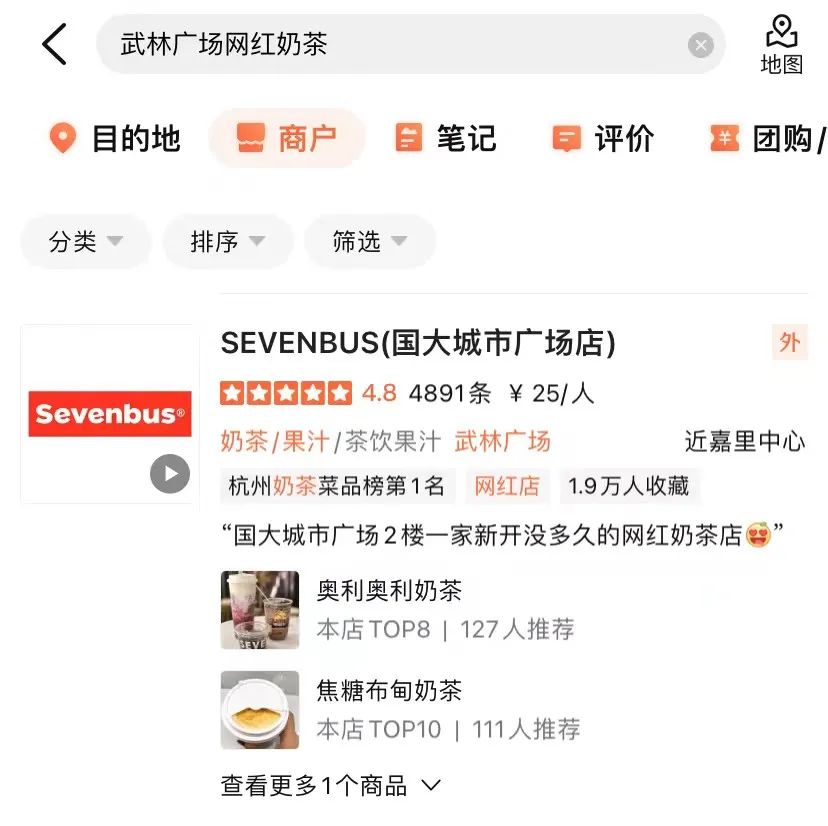
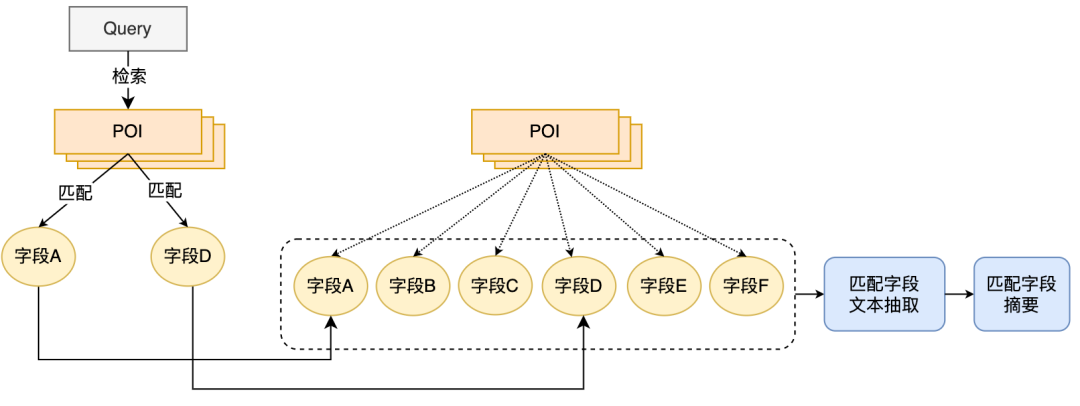
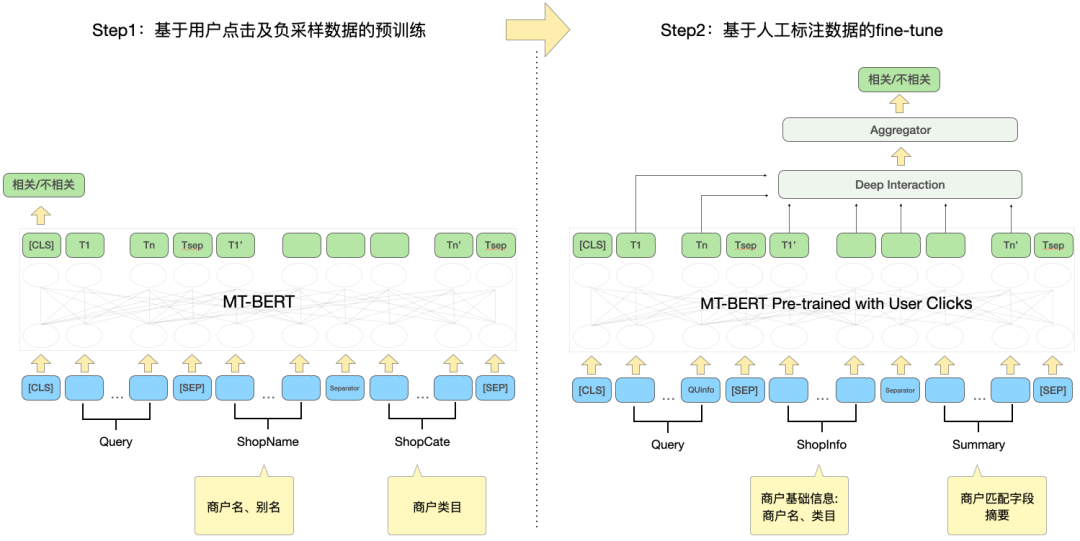
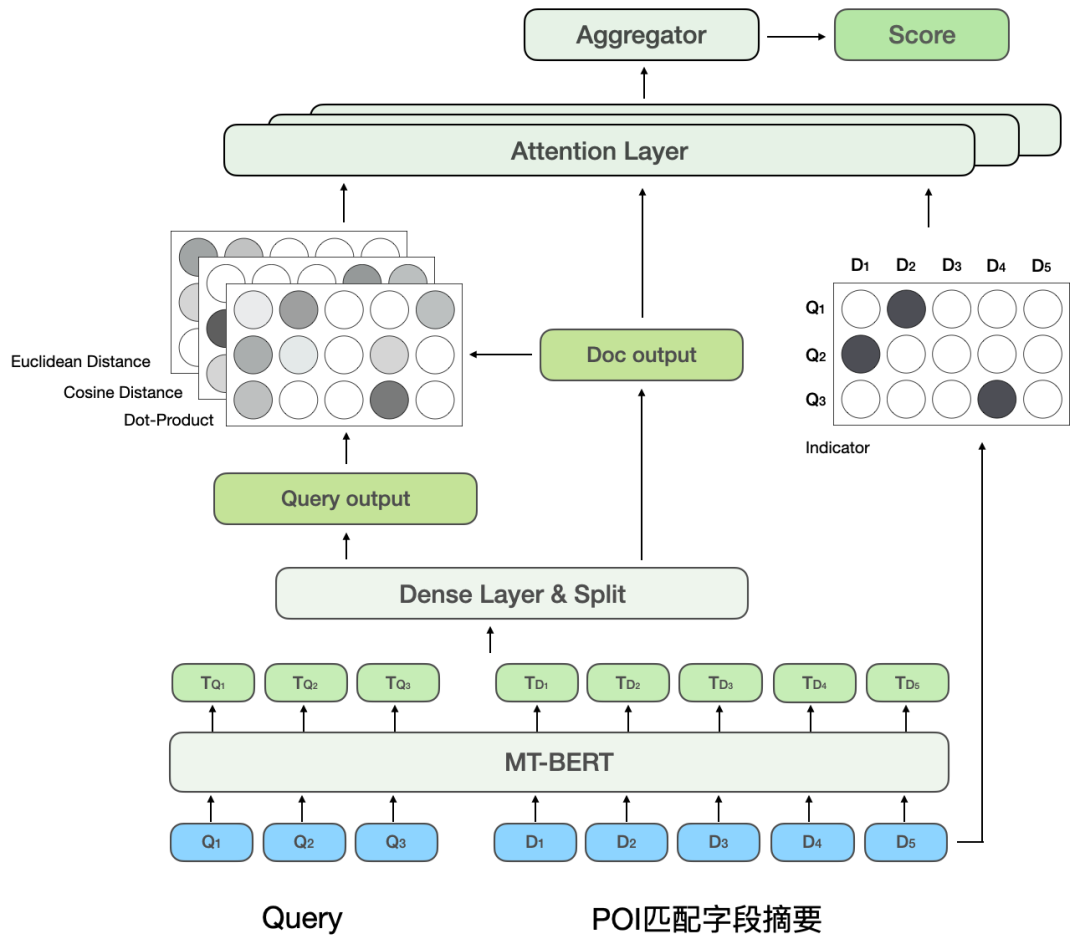
a proposé une méthode de distillation du modèle basé sur l'interaction en un modèle basé sur la représentation pour obtenir une interaction virtuelle du modèle à deux tours et augmenter l'interaction entre la requête et le POI tout en garantissant les performances. .Le modèle basé sur la représentation se concentre sur la représentation des caractéristiques globales des POI et manque d'informations de correspondance entre la requête en ligne et les POI. La méthode basée sur l'interaction peut compenser les lacunes de la représentation. et améliorer la requête et l'interaction des POI améliorent la capacité d'expression du modèle. Dans le même temps, compte tenu des fortes performances du modèle pré-entraîné dans les tâches de correspondance sémantique de texte, le calcul de corrélation de recherche d'examen a déterminé un interactif. solution basée sur le modèle pré-entraîné Meituan MT-BERT[11] . Lors de l'application du BERT interactif basé sur des modèles pré-entraînés à la tâche de pertinence des scénarios de recherche d'avis, il reste encore de nombreux défis : Après une exploration et une expérimentation continues, nous avons construit un résumé textuel des POI adapté au scénario de recherche d'avis pour les informations multi-sources complexes côté POI afin de mieux adapter le modèle au calcul de la pertinence de la recherche d'avis, deux méthodes ont été utilisées, méthode de formation par étapes, et ont transformé la structure du modèle en fonction des caractéristiques du calcul de corrélation ; enfin, en optimisant le processus de calcul, en introduisant la mise en cache et d'autres mesures, cela a réussi à réduire le temps de calcul en temps réel du modèle ; et le lien d'application global, et satisfait aux exigences de calcul en temps réel en ligne du BERT. Lors de la détermination de la corrélation entre la requête et le POI, il y a plus d'une douzaine de champs impliqués dans le calcul du côté POI, et il y a beaucoup de contenu sous certains champs (Par exemple, un commerçant peut avoir des centaines de plats recommandés), ils doivent donc trouver un moyen approprié d'extraire et d'organiser les informations secondaires des POI et de les saisir dans le modèle de corrélation. Les moteurs de recherche généraux (tels que Baidu) ou les moteurs de recherche verticaux courants (tels que Taobao) disposent d'une grande quantité d'informations dans le titre de la page Web ou le titre du produit de leur document, qui constitue généralement le contenu principal du document. Modèle côté document dans le processus de détermination de la pertinence. Comme le montre la figure 3(a), dans un moteur de recherche général, les informations clés du site Web correspondant et si elles sont liées à la requête peuvent être vues d'un coup d'œil à travers le titre des résultats de recherche, tandis que dans la figure 3 (b) les résultats de recherche de l'application Dianping, des informations suffisantes sur le commerçant ne peuvent pas être obtenues uniquement via le champ du nom du commerçant. Il est nécessaire de combiner la catégorie du commerçant (jus de thé au lait), les plats recommandés par l'utilisateur (thé au lait oli), tags (Magasin de célébrités Internet), adresse ( Wulin Plaza) Plusieurs champs peuvent être utilisés pour déterminer la pertinence du commerçant par rapport à la requête "Wulin Plaza Internet Celebrity Milk Tea". (a) Exemple de résultat de recherche général sur un moteur de recherche (b) Exemple de résultat de recherche sur l'application Dianping Figure 3 Comparaison des résultats de recherche du moteur de recherche général et de Dianping L'extraction de balises est un moyen relativement courant d'extraire des informations sur un sujet dans l'industrie, nous avons donc d'abord essayé de construire la méthode de saisie du modèle côté POI via des balises de marchand, et sur la base des commentaires du commerçant, des informations de base, des plats et des clics de recherche de tête correspondant au commerçant Les mots, etc. sont utilisés pour extraire des mots-clés représentatifs du commerçant en tant que balises du commerçant. Lorsqu'elles sont utilisées en ligne, les étiquettes de commerçant extraites, le nom du commerçant et les informations de base de la catégorie sont utilisés comme informations d'entrée du côté POI du modèle, et des calculs interactifs sont effectués avec Query. Cependant, la couverture des informations sur les commerçants par les balises des commerçants n'est toujours pas assez complète. Par exemple, lorsqu'un utilisateur recherche le plat « crème aux œufs », un restaurant coréen proche de l'utilisateur vend de la crème aux œufs, mais le plat signature du magasin, clique sur la tête. les mots ne sont pas liés à la « crème aux œufs », ce qui fait que les mots-clés extraits par le magasin ont également une faible corrélation avec la « crème aux œufs », de sorte que le modèle jugera le magasin comme non pertinent, nuisant ainsi à l'expérience utilisateur. Afin d'obtenir la représentation des POI la plus complète, une solution consiste à intégrer directement tous les champs du commerçant dans l'entrée du modèle sans extraire les mots-clés. Cependant, cette méthode affectera sérieusement les performances en ligne car la longueur de l'entrée du modèle est trop longue. , et une grande quantité d'informations redondantes affectera également les performances du modèle. Afin de construire des informations plus informatives sur les POI en tant qu'entrée du modèle, nous avons proposé la méthode d'extraction du résumé du champ de correspondance des POI, qui combine la situation de correspondance de requête en ligne pour extraire le texte du champ correspondant du POI en temps réel et construire la correspondance Le résumé du champ est utilisé comme information d'entrée du modèle côté POI. Le processus d'extraction du résumé des champs de correspondance de POI est illustré à la figure 4. Sur la base de certaines caractéristiques de similarité de texte, nous extrayons les champs de texte les plus pertinents et informatifs pour la requête, et intégrons les informations sur le type de champ pour créer un résumé des champs correspondants. Lorsqu'ils sont utilisés en ligne, le résumé du champ de correspondance de POI extrait, le nom du commerçant et les informations de base de la catégorie sont saisis en tant que modèle côté POI. Figure 4 Processus d'extraction du résumé du champ de correspondance des POIAprès avoir déterminé les informations d'entrée du modèle côté POI, nous utilisons la tâche de relation inter-phrases BERT, utilisons d'abord MT-BERT pour extraire les informations récapitulatives du champ correspondant sur le Codage côté requête et côté POI, puis utilisation des vecteurs de phrases regroupés pour calculer les scores de corrélation. Après avoir utilisé le schéma récapitulatif du champ de correspondance de POI pour construire le modèle côté POI, saisi les informations et travaillé avec des exemples d'itérations, l'effet du modèle a été considérablement amélioré par rapport à la méthode basée sur les étiquettes. Laisser le modèle mieux s'adapter à la tâche de calcul de la pertinence de la recherche d'avis contient deux significations : les informations textuelles dans le scénario de recherche Dianping et MT- Il existe certaines différences dans la distribution du corpus utilisé par le modèle de pré-formation BERT ; les tâches de relation inter-phrases du modèle de pré-formation sont également légèrement différentes des tâches de corrélation de requête et de POI, et la structure du modèle doit être modifiée. Après une exploration continue, nous avons adopté un schéma de formation en deux étapes basé sur des données de domaine, combiné à la construction d'échantillons de formation, pour rendre le modèle de pré-formation plus adapté à la tâche de corrélation des scénarios de recherche de révision et proposé une corrélation interactive approfondie basée sur plusieurs ; matrices de similarité Le modèle renforce l'interaction entre la requête et le POI, améliore la capacité du modèle à exprimer des informations complexes sur la requête et le POI et optimise l'effet de calcul de corrélation. Afin d'utiliser efficacement les données de clic des utilisateurs et de rendre le modèle pré-entraîné MT-BERT plus adapté à la recherche d'avis tâches de pertinence, nous nous appuyons sur l'idée de la pertinence de la recherche Baidu[12], introduisons une méthode de formation en plusieurs étapes et utilisons les clics des utilisateurs et les données d'échantillonnage négatives pour effectuer une pré-formation pour la première étape de l'adaptation du domaine (Continual Domain -Adaptive Pre-training), en utilisant des données annotées manuellement pour la deuxième étape de la formation (Fine-Tune), le modèle La structure est illustrée dans la figure 5 ci-dessous : Figure 5 Structure du modèle de formation en deux étapes basée sur un clic et une annotation manuelle data Formation de première étape basée sur les données de clic Le La raison directe de l'introduction des données de clic comme tâche de formation de première étape réside dans le scénario de recherche d'avis. Il existe des problèmes uniques. Par exemple, les mots « heureux » et « heureux » sont presque entièrement synonymes dans les scénarios généraux, mais dans le contexte de. Les recherches d'avis, « happy barbecue » et « happy barbecue » sont deux marques de restaurants complètement différentes, donc l'introduction des données de clic peut aider le modèle à acquérir des connaissances uniques dans le scénario de recherche. Cependant, l'utilisation directe d'échantillons de clics pour le jugement de corrélation entraînera beaucoup de bruit, car l'utilisateur peut cliquer sur un commerçant par erreur en raison d'un classement plus élevé, et l'utilisateur ne peut pas cliquer sur un commerçant simplement parce que le commerçant est éloigné. Ce n'est pas à cause d'un problème de corrélation, nous avons donc introduit une variété de fonctionnalités et de règles pour améliorer la précision de l'annotation automatique des échantillons d'entraînement. Lors de la construction de l'échantillon, les échantillons de candidats sont sélectionnés en comptant si les clics sont cliqués, la position du clic, la distance entre le plus grand marchand de clics et l'utilisateur, etc., et le taux de clics d'exposition est supérieur à un certain seuil. La paire Requête-POI est utilisée comme exemple positif, et différents seuils sont ajustés pour différents types de commerçants en fonction des caractéristiques commerciales. En termes de structure des exemples négatifs, la stratégie d'échantillonnage Skip-Above utilise comme échantillons négatifs les commerçants situés avant le commerçant cliqué et dont le taux de clics est inférieur au seuil. De plus, l'échantillonnage négatif aléatoire peut compléter les échantillons d'apprentissage avec des exemples négatifs simples, mais lorsque l'on considère l'échantillonnage négatif aléatoire, certaines données de bruit seront également introduites. Par conséquent, nous utilisons des règles artificiellement conçues pour débruiter les données d'entraînement : lorsque l'intention de catégorie de la requête est. identique à Lorsque le système de catégories d'un POI est relativement cohérent ou correspond fortement au nom du POI, il sera éliminé des échantillons négatifs. La deuxième étape de la formation basée sur les données d'annotation manuelle réussi Après la première étape de formation, étant donné que le bruit dans les données de clic ne peut pas être complètement éliminé et les caractéristiques de la tâche de corrélation, il est nécessaire d'introduire une deuxième étape de formation basée sur des échantillons étiquetés manuellement pour corriger le modèle. En plus d'échantillonner aléatoirement une partie des données et de les transmettre à l'annotation manuelle, afin d'améliorer autant que possible les capacités du modèle, nous produisons un grand nombre d'échantillons de grande valeur grâce à une extraction d'exemples difficiles et à une amélioration comparative des échantillons et à la main. passez-les à l’annotation manuelle. Les détails sont les suivants : 1) Difficult Case Digging Amélioration des échantillons de contraste : S'appuyer sur l'idée de l'apprentissage contrastif pour générer des échantillons de contraste pour certains très des échantillons correspondants. L'amélioration des données et l'annotation manuelle sont effectuées pour garantir l'exactitude de l'étiquetage des échantillons. En comparant les différences entre les échantillons, le modèle peut se concentrer sur des informations véritablement utiles et améliorer sa capacité de généralisation des synonymes, obtenant ainsi de meilleurs résultats. 3.2.2 Modèle d'interaction profonde basé sur plusieurs matrices de similarité La relation inter-phrases BERT est une tâche générale de PNL, utilisée pour juger deux La relation entre les phrases et la tâche de corrélation consiste à calculer le degré de corrélation entre la requête et le POI. Pendant le processus de calcul, la tâche de relation inter-phrases calcule non seulement l'interaction entre la requête et le POI, mais calcule également l'interaction au sein de la requête et au sein du POI, tandis que le calcul de corrélation accorde plus d'attention à l'interaction entre la requête et le POI. De plus, au cours du processus d'itération du modèle, nous avons constaté que certains types de difficulté BadCase ont des exigences plus élevées en matière de capacité d'expression du modèle, comme les types où le texte correspond fortement mais n'est pas pertinent. Par conséquent, afin d'améliorer encore l'effet de calcul du modèle sur les tâches complexes de corrélation de requêtes et de POI, nous avons transformé la tâche de relation inter-phrases BERT dans la deuxième étape de la formation et proposé un modèle d'interaction profonde basé sur plusieurs matrices de similarité en introduisant une similarité multiple. Les matrices sont utilisées pour interagir en profondeur avec les requêtes et les POI, et la matrice d'indicateurs est introduite pour mieux résoudre le problème difficile de BadCase. La structure du modèle est illustrée dans la figure 7 ci-dessous : Figure 7 Modèle de corrélation croisée profonde basé sur plusieurs matrices de similarité [8]#🎜🎜 Inspiré par #, nous divisons les vecteurs de requête et de POI codés par MT-BERT pour calculer explicitement la relation d'interaction approfondie entre les deux parties. Nous divisons la requête et le POI et menons une interaction en profondeur. d'une part, nous pouvons utiliser spécifiquement pour apprendre la corrélation entre la requête et le POI, d'autre part, l'augmentation du nombre de paramètres peut améliorer la capacité d'ajustement du modèle. En se référant au modèle MatchPyramid
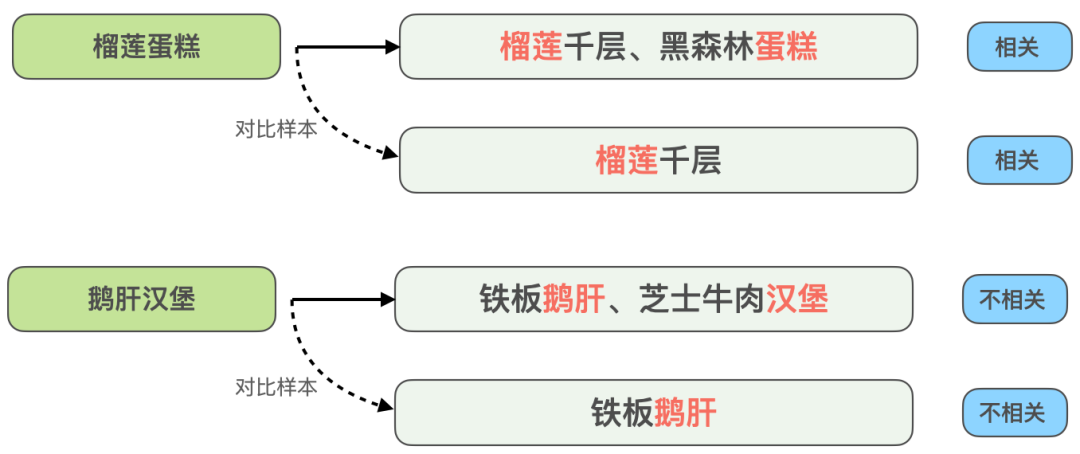
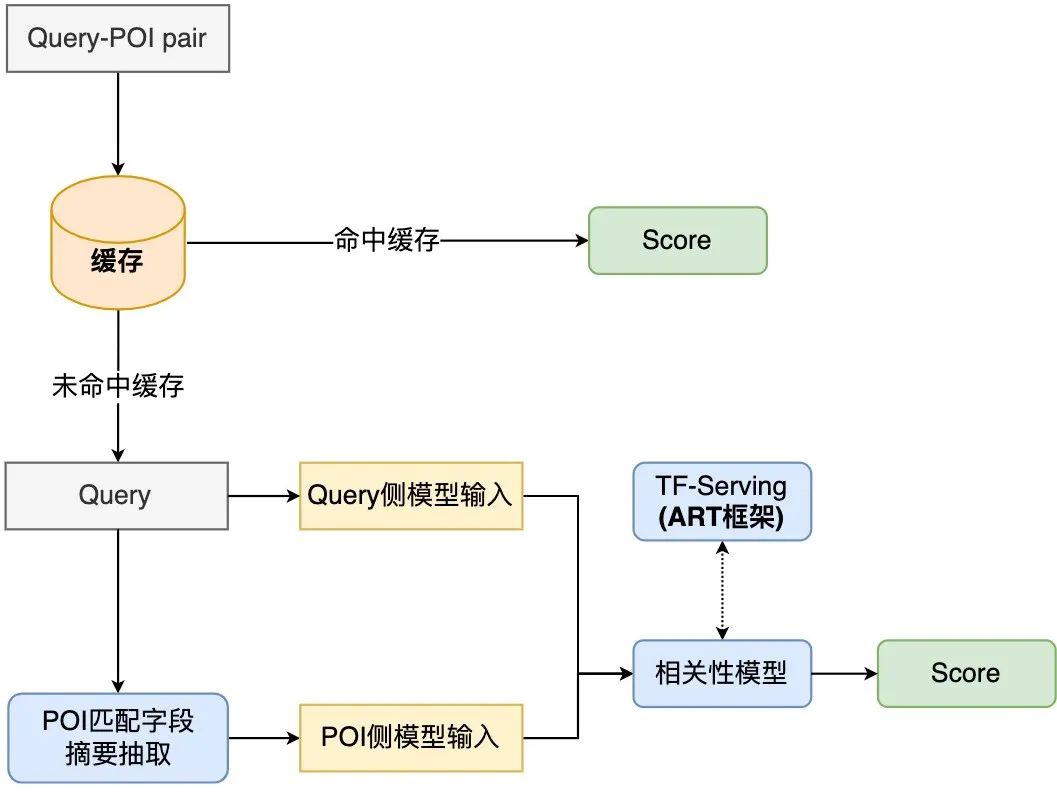
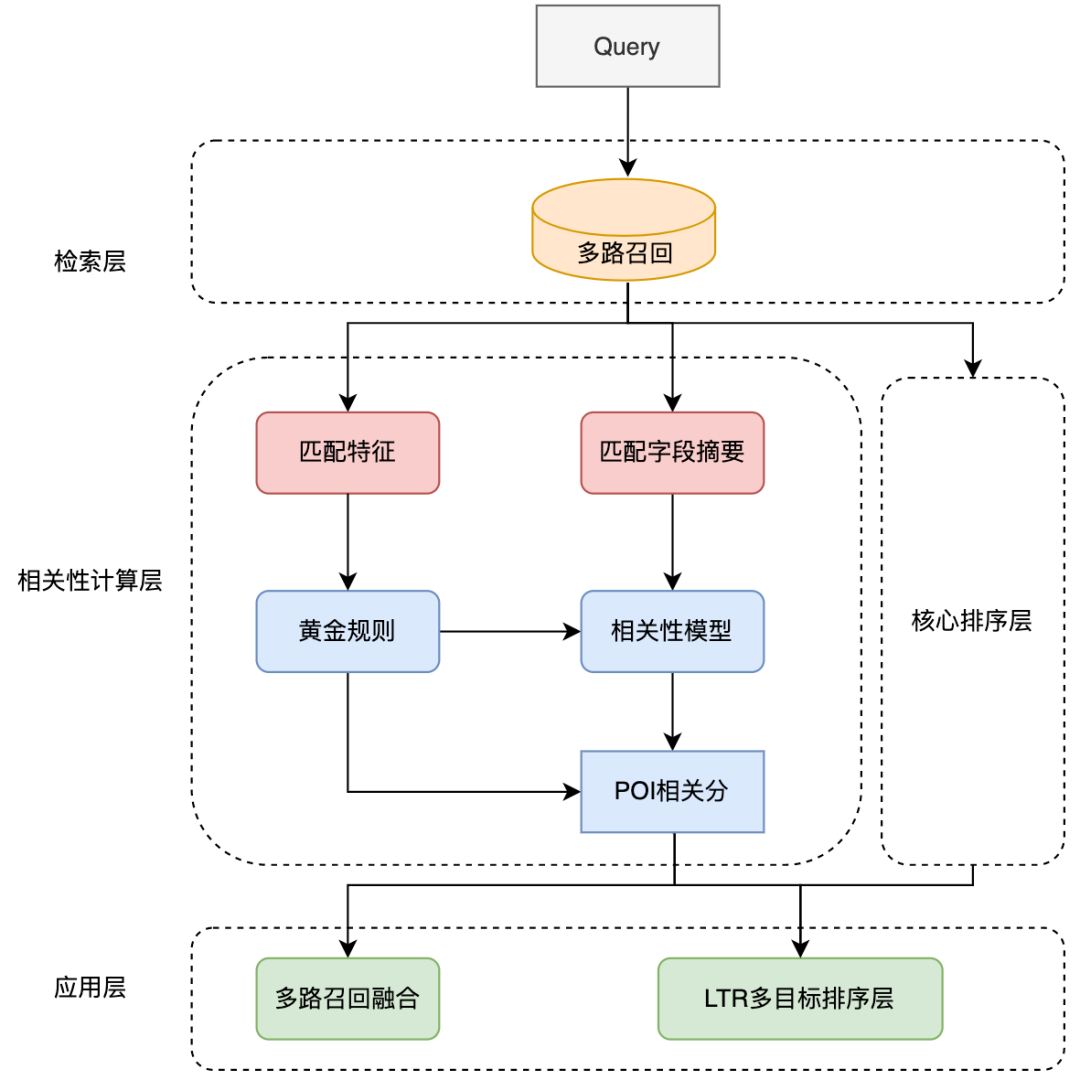
. , qui représente la matrice de correspondance. L'élément correspondant à la ligne et à la colonne représente le Token de Requête et le Token de POI. Étant donné que la matrice d'indicateur est une matrice qui indique si la requête et le POI correspondent littéralement, le format d'entrée des trois autres matrices de correspondance sémantique est différent. Les trois matrices de correspondance du produit scalaire, de la distance cosinus et de la distance euclidienne sont d'abord fusionnées. , puis les résultats obtenus sont combinés avec la matrice de l'indicateur. Les matrices sont ensuite fusionnées avant de calculer le score de corrélation final. La matrice d'indicateurs permet de mieux décrire la relation de correspondance entre requête et POI. L'introduction de cette matrice prend principalement en compte une difficulté de détermination de la corrélation entre requête et POI : parfois même si le texte correspond fortement, les deux ne sont pas pertinents. La structure du modèle BERT basée sur l'interaction facilite la détermination de la pertinence des requêtes et des POI présentant un degré élevé de correspondance de texte. Cependant, dans le scénario de recherche d'avis, cela peut ne pas être le cas dans certains cas difficiles. Par exemple, bien que le « jus de haricot » et le « jus de haricot mungo » soient très similaires, ils ne sont pas liés. Bien que "Maokong" et "Cat's Sky Castle" soient des matchs distincts, ils sont liés car le premier est l'abréviation du second. Par conséquent, différentes situations de correspondance de texte sont directement entrées dans le modèle via la matrice d'indicateurs, permettant au modèle de recevoir explicitement des situations de correspondance de texte telles que « contient » et « correspondance fractionnée », ce qui aide non seulement le modèle à améliorer sa capacité à distinguer les cas difficiles. , mais cela affectera également les performances de la plupart des cas normaux. Le modèle de corrélation interactive profonde basé sur plusieurs matrices de similarité divise la requête et le POI, puis calcule la matrice de similarité, ce qui équivaut à permettre au modèle d'interagir explicitement avec la requête et le POI, ce qui rend le modèle plus adapté aux tâches de corrélation. Plusieurs matrices de similarité augmentent la capacité de représentation du modèle dans le calcul de la corrélation entre la requête et le POI, tandis que la matrice d'indicateur est spécialement conçue pour les situations complexes de correspondance de texte dans les tâches de corrélation, ce qui rend le jugement du modèle sur les résultats non pertinents plus précis. Lors du déploiement de calculs de corrélation en ligne, les solutions existantes utilisent généralement une structure à double tour de distillation des connaissances[10,14] pour garantir l'efficacité informatique en ligne , mais cette méthode de traitement est plus ou moins préjudiciable à l'effet du modèle. Examiner le calcul de corrélation de recherche Afin de garantir l'effet du modèle, le modèle de corrélation pré-entraîné BERT à 12 couches basé sur l'interaction est utilisé en ligne, ce qui nécessite que des centaines de POI sous chaque requête soient prédits par le modèle BERT à 12 couches. Afin de garantir l'efficacité du calcul en ligne, nous sommes partis des deux perspectives du processus de calcul en temps réel du modèle et du lien d'application, et optimisés en introduisant un mécanisme de mise en cache, une accélération de la prédiction du modèle, l'introduction d'une couche de règles pré-or, la parallélisation du calcul de corrélation et du tri de base, etc. Le goulot d'étranglement des performances du modèle de corrélation lorsqu'il est déployé en ligne permet au modèle de corrélation BERT basé sur l'interaction à 12 couches de s'exécuter de manière stable et efficace en ligne, garantissant ainsi qu'il peut prendre en charge les calculs de corrélation entre des centaines de commerçants et Query. Figure 8 Organigramme de calcul en ligne du modèle de corrélation Le processus de calcul en ligne du modèle de corrélation de recherche d'avis est illustré à la figure 8, via la mise en cache Le mécanisme et l'accélération de la prédiction du modèle TF-Serving optimisent les performances du calcul en temps réel du modèle. Afin d'utiliser efficacement les ressources informatiques, le déploiement en ligne du modèle introduit un mécanisme de mise en cache pour écrire les scores de corrélation des requêtes haute fréquence dans le cache. Lors des appels suivants, le cache sera lu en premier. Si le cache est atteint, le score sera affiché directement. Si le cache n'est pas atteint, le score sera calculé en ligne en temps réel. Le mécanisme de mise en cache permet d'économiser considérablement les ressources informatiques et atténue efficacement la pression sur les performances de l'informatique en ligne. Pour la requête qui manque le cache, traitez-la en tant qu'entrée du modèle côté requête, obtenez le résumé du champ correspondant de chaque POI via le processus décrit dans la figure 4, et traitez-la dans le format d'entrée du modèle côté POI, puis appelez la corrélation en ligne Le modèle sexuel produit des scores de corrélation. Le modèle de corrélation est déployé sur TF-Serving. Lors de la prédiction du modèle, le framework ART, un outil d'optimisation de modèle de la plateforme d'apprentissage automatique Meituan (basé sur Faster-Transformer[15]amélioré) est utilisé pour l'accélération, ce qui garantit. précision tout en maximisant la précision, Dadi améliore la vitesse de prédiction du modèle. Figure 9 L'application du modèle de corrélation dans le lien de recherche d'avis L'application du modèle de corrélation dans le lien de recherche est illustrée dans la figure 9 ci-dessus. Optimisez les performances du lien de recherche global en introduisant la règle d'or frontale et en parallélisant le calcul de corrélation avec la couche de classement principale. Afin d'accélérer encore le lien d'appel de corrélation, nous avons introduit la règle d'or préalable pour détourner les requêtes et générer directement le score de corrélation via des règles pour certaines requêtes, allégeant ainsi la pression de calcul du modèle. Dans la couche de règles d'or, les fonctionnalités de correspondance de texte sont utilisées pour évaluer les requêtes et les POI. Par exemple, si le terme de recherche est exactement le même que le nom du commerçant, le jugement « pertinent » est directement émis via la couche de règles d'or sans calculer la corrélation. score grâce au modèle de corrélation. Dans le lien de calcul global, le processus de calcul de corrélation et la couche de tri principale fonctionnent simultanément pour garantir que le calcul de corrélation n'a fondamentalement aucun impact sur la durée globale du lien de recherche. Au niveau application, les calculs de corrélation sont utilisés dans de nombreux aspects tels que le rappel et le tri des liens de recherche. Afin de réduire la proportion de commerçants non pertinents sur le premier écran de la liste de recherche, nous avons introduit le score de pertinence dans le tri par fusion multi-objectifs LTR pour trier les pages de la liste et adopté une stratégie de fusion de rappel multidirectionnelle en utilisant les résultats. du modèle de corrélation, seul le chemin de rappel supplémentaire des commerçants associés est fusionné dans la liste. Afin de refléter avec précision l'effet hors ligne de l'itération du modèle , nous passons Plusieurs séries d'annotations manuelles ont été utilisées pour construire un lot de benchmarks. Considérant que l'objectif principal de l'utilisation réelle en ligne est de réduire l'indicateur BadCase, c'est-à-dire d'identifier avec précision les commerçants non pertinents, nous utilisons la précision, le taux de rappel, et valeur F1 des exemples négatifs comme indice de mesures. Les avantages apportés par la formation en deux étapes, la construction d'échantillons et l'itération du modèle sont présentés dans le tableau 1 ci-dessous : Examiner l'index hors ligne de l'itération du modèle de pertinence de la recherche 4.2 Effet en ligne Afin de mesurer efficacement la satisfaction des utilisateurs en matière de recherche, Dianping Search échantillonne et étiquette manuellement le trafic en ligne réel chaque jour. Le taux de BadCase sur le premier écran de la page de liste est utilisé comme indicateur principal pour évaluer l'efficacité du modèle de corrélation. Après le lancement du modèle de corrélation, l'indicateur de taux BadCase moyen mensuel de la recherche Dianping a chuté de manière significative de 2,9 points (Point de pourcentage, point absolu de pourcentage ) par rapport à avant le lancement, et dans les semaines suivantes, le BadCase L'indicateur de taux s'est stabilisé à Près du point bas, dans le même temps, l'indicateur NDCG de la page de liste de recherche a augmenté régulièrement de 2 points. On peut voir que le modèle de corrélation peut identifier efficacement les commerçants non pertinents et réduire considérablement la proportion de problèmes non pertinents sur le premier écran de recherche, améliorant ainsi l'expérience de recherche de l'utilisateur.
(a) Sœur Pei # 🎜🎜#(b) Buffet de cuisine japonaise Pomelo Cet article présente la solution technique et l'application pratique du modèle de corrélation de recherche Dianping. Afin de mieux construire les informations d'entrée du modèle côté commerçant, nous avons introduit une méthode d'extraction du texte récapitulatif des champs de correspondance des commerçants en temps réel pour construire des représentations de commerçants en tant qu'entrée du modèle afin d'optimiser le modèle pour mieux s'adapter aux calculs de corrélation de recherche ; un processus en deux étapes a été utilisé. La méthode de formation adopte un schéma de formation en deux étapes basé sur les clics et les données d'annotation manuelles pour utiliser efficacement les données de clic de l'utilisateur de Dianping. Selon les caractéristiques du calcul de corrélation, une structure d'interaction profonde basée sur de multiples similarités. des matrices sont proposées pour améliorer encore le modèle de corrélation.Effet;Afin d'alléger la pression de calcul en ligne du modèle de corrélation, le mécanisme de mise en cache et l'accélération de la prédiction TF-Serving sont introduits lors du déploiement en ligne, la couche de règles d'or est introduite pour décharger la requête, et le calcul de corrélation est parallélisé avec la couche de tri principale, satisfaisant ainsi les exigences en ligne les exigences de performances pour le calcul en temps réel du BERT. En appliquant le modèle de corrélation à chaque lien du lien de recherche, la proportion de questions non pertinentes est considérablement réduite et l'expérience de recherche de l'utilisateur est efficacement améliorée. Actuellement, le modèle de corrélation de recherche d'avis peut encore être amélioré en termes de performances du modèle et d'applications en ligne. En termes de structure du modèle, nous explorerons davantage de connaissances préalables dans le domaine en présentant des méthodes. , comme l'apprentissage multitâche pour identifier les types d'entités dans Query, l'intégration des entrées de modèles d'optimisation des connaissances externes, etc. en termes d'applications pratiques, il sera affiné à davantage de niveaux pour répondre aux besoins des utilisateurs en matière de recherche raffinée en magasin. Nous essaierons également d'appliquer la capacité de pertinence aux modules non marchands pour optimiser l'expérience de recherche de l'ensemble de la liste de recherche. xiaoya*, Shen Yuan *, Judy, Tang Biao, Zhang Gong, etc. sont tous du Centre de technologie de recherche de la division Meituan/Dianping. * est co-auteur de cet article. 3. Examiner le calcul de corrélation de recherche
3.1 Comment mieux construire les informations d'entrée du modèle côté POI
3.2.1 Formation en deux étapes basée sur les données de domaine
#🎜🎜 ##🎜 🎜#
2)
 [13]
[13]3.3 Comment résoudre le goulot d'étranglement des performances en ligne des modèles de corrélation pré-entraînés
3.3.1 Optimisation des performances du processus de calcul du modèle de corrélation
3.3.2 Optimisation des performances du lien d'application
4. Application pratique
4.1 Effet hors ligne
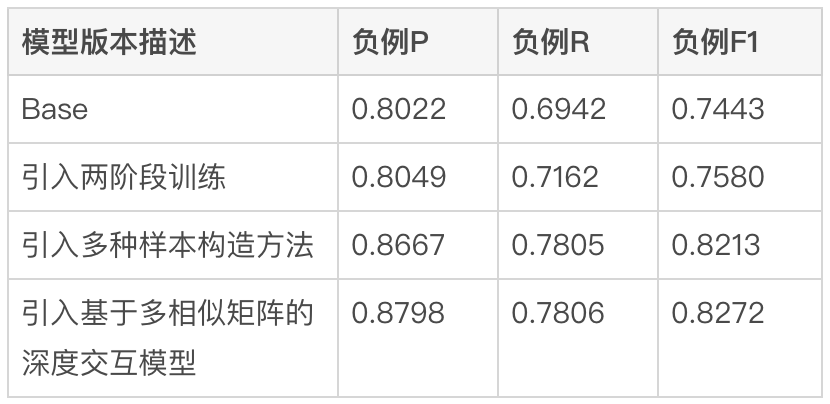 Méthode initiale (#🎜🎜 #Base
Méthode initiale (#🎜🎜 #Base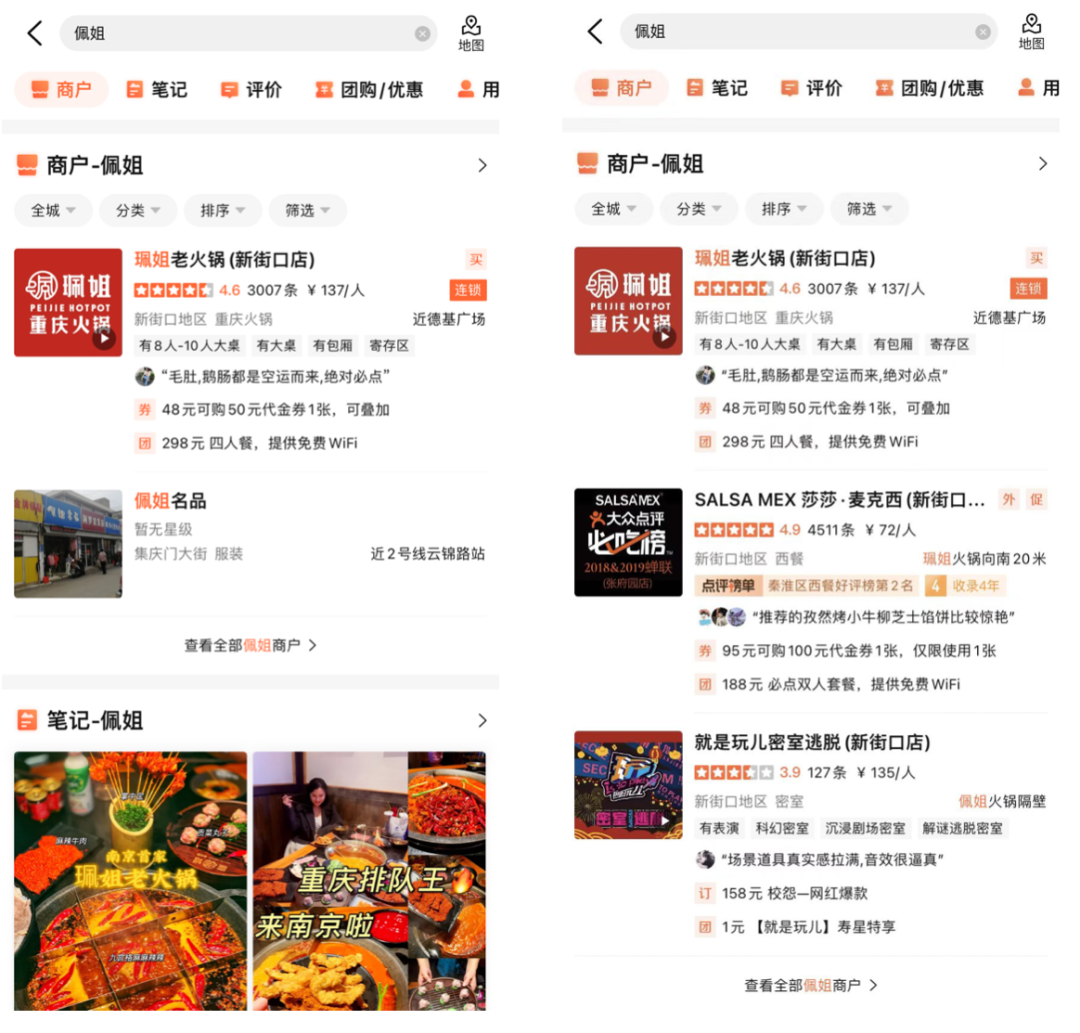
5. Résumé et perspectives
6. À propos de l'auteur
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI