
Maison >Périphériques technologiques >IA >PandaLM, un « grand modèle d'arbitre » open source de l'Université de Pékin, de l'Université de West Lake et d'autres : trois lignes de code pour évaluer de manière entièrement automatique le LLM, avec une précision de 94 % de ChatGPT
PandaLM, un « grand modèle d'arbitre » open source de l'Université de Pékin, de l'Université de West Lake et d'autres : trois lignes de code pour évaluer de manière entièrement automatique le LLM, avec une précision de 94 % de ChatGPT

- 王林avant
- 2023-05-19 11:55:051737parcourir
Après la sortie de ChatGPT, l'écosystème dans le domaine du traitement du langage naturel a complètement changé De nombreux problèmes qui ne pouvaient pas être résolus auparavant peuvent l'être en utilisant ChatGPT.
Cependant, cela pose aussi un problème : les performances des grands modèles sont trop fortes, et il est difficile d'évaluer les différences de chaque modèle à l'œil nu.
Par exemple, si vous entraînez plusieurs versions du modèle avec différents modèles de base et hyperparamètres, les performances peuvent être similaires à celles des exemples et il est impossible de quantifier pleinement l'écart de performances entre les deux modèles.
Actuellement, il existe deux options principales pour évaluer les grands modèles de langage : 1 Appelez l'interface API d'OpenAI pour évaluation.
ChatGPT peut être utilisé pour évaluer la qualité de la sortie de deux modèles. Cependant, ChatGPT a été mis à niveau de manière itérative. Les réponses à la même question à des moments différents peuvent être différentes. Les résultats de l'évaluation présentent le problème de ne pas pouvoir l'être. reproduit
.2. Annotation manuelle
Si une annotation manuelle est demandée sur la plateforme de crowdsourcing, les équipes disposant de fonds insuffisants pourraient ne pas être en mesure de se le permettre, et il existe également des cas où des sociétés tierces
divulguent des données. Afin de résoudre de tels « problèmes d'évaluation de grands modèles », des chercheurs de l'Université de Pékin, de l'Université de Westlake, de l'Université d'État de Caroline du Nord, de l'Université Carnegie Mellon et de la MSRA ont collaboré pour développer un nouveau cadre d'évaluation de modèle de langage PandaLM. -des solutions d'évaluation de grands modèles préservées, fiables, reproductibles et bon marché.
 Lien du projet : https://github.com/WeOpenML/PandaLM
Lien du projet : https://github.com/WeOpenML/PandaLM
En fournissant le même contexte, PandaLM peut comparer les résultats de réponse de différents LLM et fournir des raisons spécifiques.
Pour démontrer la fiabilité et la cohérence de l'outil, les chercheurs ont créé un ensemble de données de test diversifié, étiqueté par des humains, composé d'environ 1 000 échantillons, dans lequel PandaLM-7B a atteint une précision de 94 % des Compétences d'évaluation ChatGPT .
Trois lignes de code utilisant PandaLMLorsque deux grands modèles différents produisent des réponses différentes à la même instruction et au même contexte, PandaLM vise à comparer la qualité de réponse des deux grands modèles et à afficher les résultats de la comparaison et les raisons de la comparaison. et les réponses pour référence.
Il y a trois résultats de comparaison : la réponse 1 est meilleure, la réponse 2 est meilleure, la réponse 1 et la réponse 2 ont une qualité similaire.
Lorsque vous comparez les performances de plusieurs grands modèles, il vous suffit d'utiliser PandaLM pour les comparer par paires, puis de résumer les résultats des comparaisons par paires pour classer les performances de plusieurs grands modèles ou dessiner un diagramme de relation d'ordre partiel de modèle. Analysez de manière claire et intuitive les différences de performances entre les différents modèles.
PandaLM doit seulement être "déployé localement" et "ne nécessite pas de participation humaine", de sorte que l'évaluation de PandaLM peut protéger la vie privée et est assez bon marché.
Afin d'offrir une meilleure interprétabilité, PandaLM peut également expliquer ses sélections en langage naturel et générer un ensemble supplémentaire de réponses de référence.
Dans le projet, les chercheurs prennent non seulement en charge l'utilisation de PandaLM à l'aide de l'interface utilisateur Web pour faciliter l'analyse de cas, mais prennent également en charge trois lignes de code pour appeler PandaLM pour l'évaluation de texte généré par des modèles et des données arbitraires. 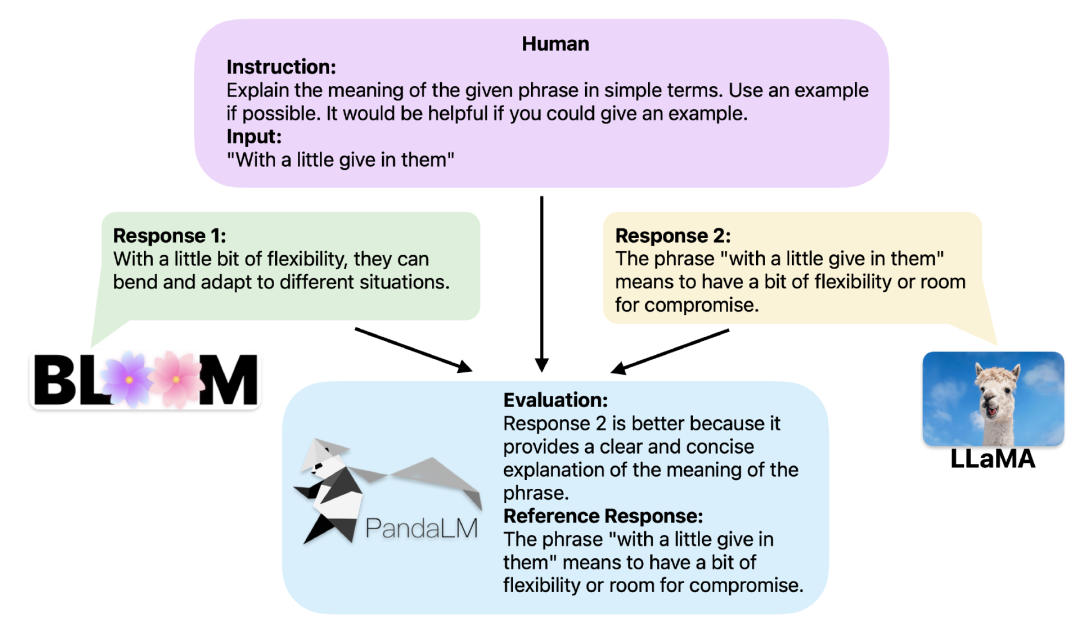
Étant donné que de nombreux modèles et frameworks existants ne sont pas open source ou sont difficiles à réaliser localement, PandaLM prend en charge l'utilisation de poids de modèle spécifiés pour générer le texte à évaluer, ou la transmission directe d'un fichier .json contenant le texte. à évaluer.
Les utilisateurs doivent uniquement transmettre une liste contenant le nom du modèle/l'ID du modèle HuggingFace ou le chemin du fichier .json, et PandaLM peut être utilisé pour réaliser des modèles définis par l'utilisateur et données d’entrée. Ce qui suit est un exemple d'utilisation minimaliste :

Afin de rendre tout le monde flexible PandaLM a été utilisé pour une évaluation gratuite. Les chercheurs ont également publié les poids du modèle PandaLM sur le site Web huggingface. Vous pouvez charger le modèle PandaLM-7B via la commande suivante :
#. 🎜 Caractéristiques de PandaLM 🎜🎜#
La mise à jour du modèle basée sur l'API en ligne n'est pas transparente, sa sortie peut être très incohérente à différents moments, et l'ancienne version du modèle n'est plus accessible, donc l'évaluation basée sur l'API en ligne n'est souvent pas reproductible. Automatisation, confidentialité et faibles frais généraux
Déployez simplement le PandaLM modélisez localement et appelez des commandes prêtes à l'emploi pour commencer à évaluer divers grands modèles. Il n'est pas nécessaire de rester en communication constante avec des experts lors de l'embauche d'experts pour l'annotation, et il n'y aura pas de problèmes de fuite de données. tous les frais d'API et la main d'œuvre. Le coût est très bon marché.
Niveau d'évaluation
Afin de prouver la fiabilité de PandaLM , l'étude Nous avons embauché trois experts pour effectuer des annotations répétées indépendantes et créé un ensemble de tests annoté manuellement.L'ensemble de tests contient 50 scénarios différents, et chaque scénario contient plusieurs tâches. Cet ensemble de tests est diversifié, fiable et cohérent avec les préférences humaines en matière de texte. Chaque échantillon de l'ensemble de tests se compose d'une instruction et d'un contexte, ainsi que de deux réponses générées par différents grands modèles, et la qualité des deux réponses est comparée par des humains.
Filtrez les échantillons présentant de grandes différences entre les annotateurs pour garantir que l'IAA (Inter Annotator Agreement) de chaque annotateur sur l'ensemble de test final est proche de 0,85. Il convient de noter que l'ensemble de formation de PandaLM ne chevauche pas l'ensemble de test annoté manuellement créé.
Ces échantillons filtrés nécessitent des connaissances supplémentaires ou des informations difficiles à obtenir. aider au jugement, il est donc difficile pour les humains de les étiqueter avec précision.
L'ensemble de tests filtré contient 1 000 échantillons, tandis que l'ensemble de tests non filtré d'origine contient 2 500 échantillons. La distribution de l'ensemble de test est {0:105, 1:422, 2:472}, où 0 indique que les deux réponses sont de qualité similaire, 1 indique que la réponse 1 est meilleure et 2 indique que la réponse 2 est meilleure. En prenant l'ensemble de tests humains comme référence, la comparaison des performances de PandaLM et de gpt-3.5-turbo est la suivante : 🎜# peut être vu, PandaLM-7B a atteint le niveau de gpt-3.5-turbo en termes de précision de 94%, et en termes de précision, de rappel et de score F1, PandaLM-7B est presque le même que gpt-3.5 -turbo.
Par conséquent, par rapport au gpt-3.5-turbo, on peut considérer que PandaLM-7B dispose déjà de capacités considérables d'évaluation de grands modèles.
En plus de l'exactitude, de la précision, du rappel et du score F1 sur l'ensemble de test, il fournit également des résultats de comparaison entre 5 grands modèles open source de taille similaire.
Tout d'abord, nous avons utilisé les mêmes données d'entraînement pour affiner les cinq modèles, puis nous avons utilisé des humains, gpt-3.5-turbo et PandaLM pour comparer les cinq modèles respectivement.
Le premier tuple (72, 28, 11) dans la première rangée du tableau ci-dessous indique qu'il y a 72 réponses LLaMA-7B qui sont meilleures que Bloom-7B, et 28 réponses LLaMA-7B sont meilleures que Bloom- 7B La différence, les deux modèles ont 11 qualités de réponse similaires.
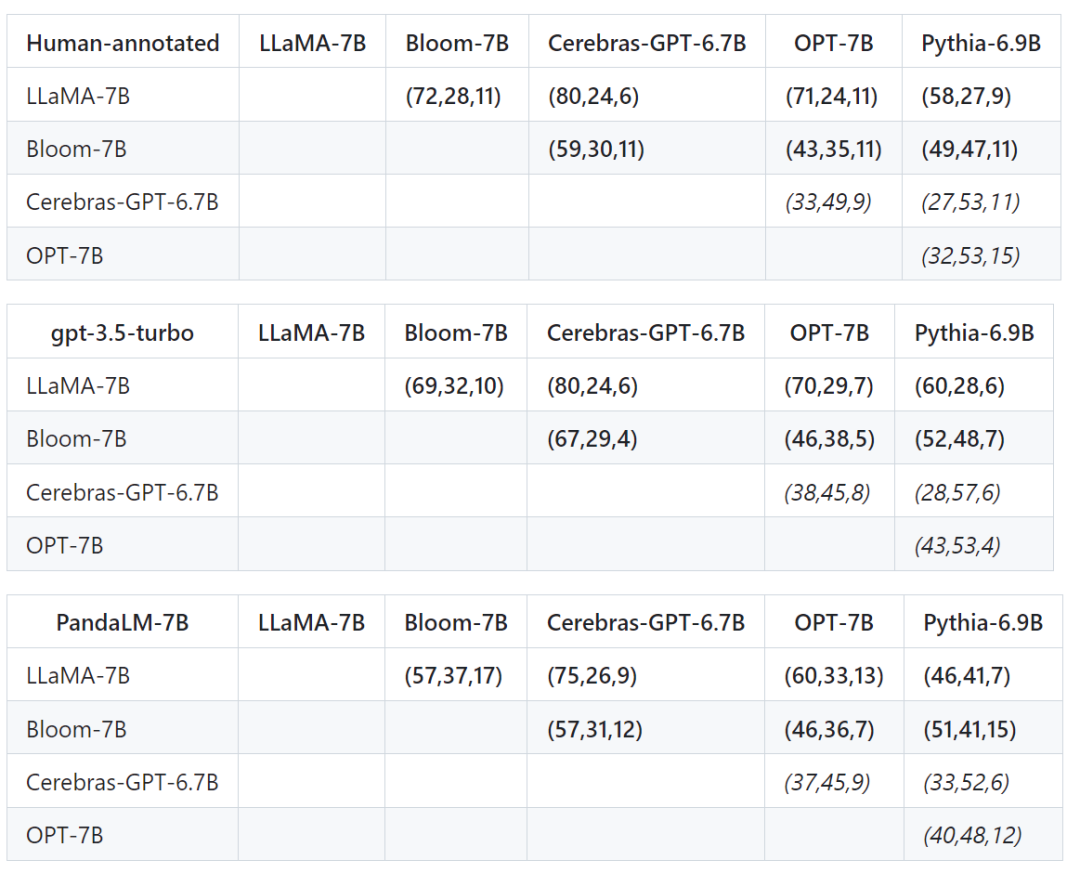
Donc, dans cet exemple, les humains pensent que LLaMA-7B est meilleur que Bloom-7B. Les résultats des trois tableaux suivants montrent que les humains, gpt-3.5-turbo et PandaLM-7B ont des jugements tout à fait cohérents sur la relation entre les avantages et les inconvénients de chaque modèle.
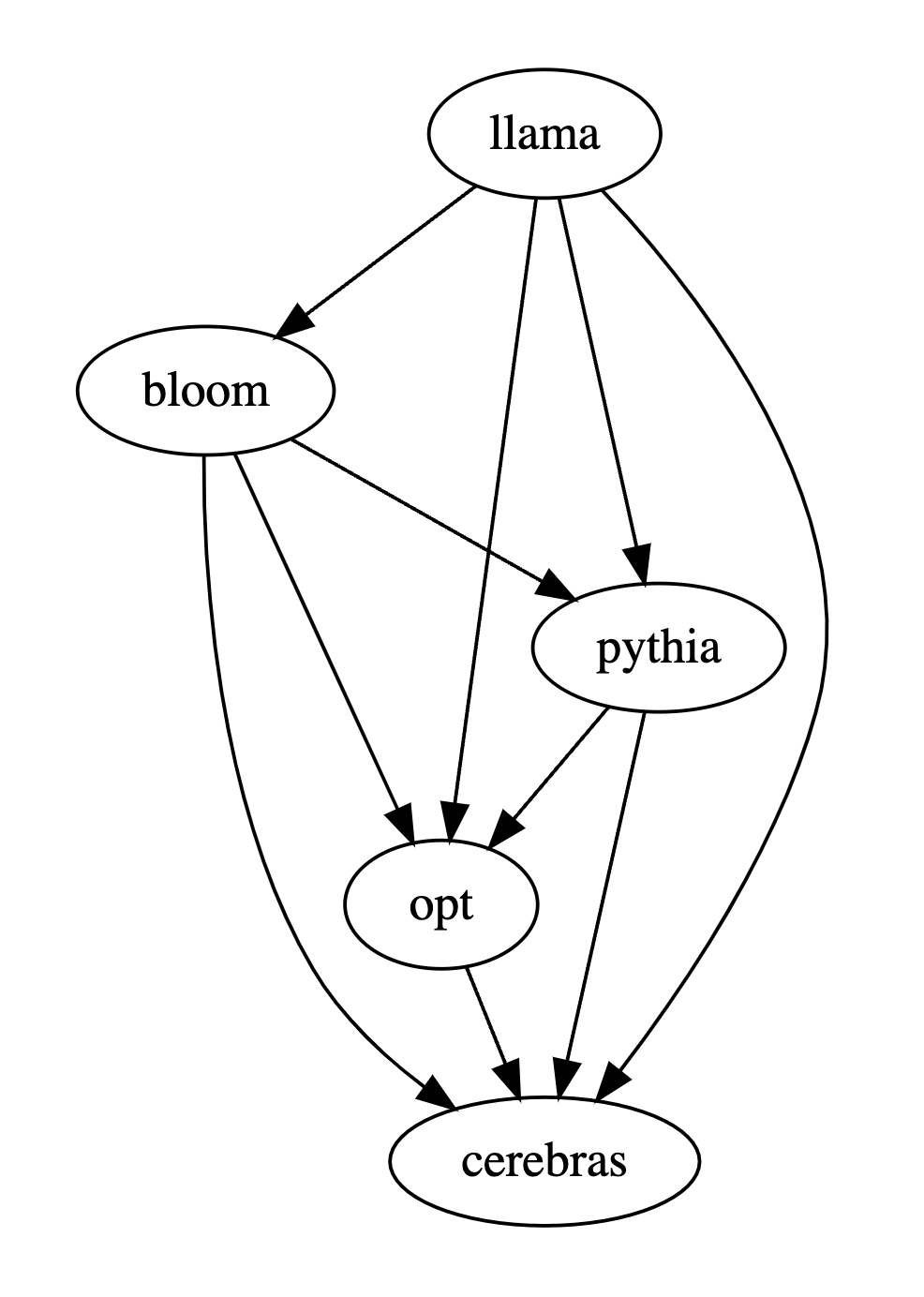
Résumé
PandaLM fournit une troisième solution pour évaluer les grands modèles en plus de l'évaluation humaine et de l'évaluation de l'API OpenAI. PandaLM a non seulement un niveau d'évaluation élevé, mais les résultats de l'évaluation sont également reproductibles et l'évaluation. Le processus est automatisé, préserve la confidentialité et réduit les frais généraux.
À l'avenir, PandaLM promouvra la recherche sur les grands modèles dans le monde universitaire et industriel, permettant ainsi à davantage de personnes de bénéficier du développement de grands modèles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI