
Maison >développement back-end >Tutoriel Python >Plusieurs façons d'implémenter la stack en Python et leurs avantages et inconvénients
Plusieurs façons d'implémenter la stack en Python et leurs avantages et inconvénients

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-19 09:37:051855parcourir

Pour en savoir plus sur l'open source, veuillez visiter :
# 🎜🎜 #51CTO Communauté des logiciels de base open source
https://ost.51cto.com#🎜 🎜 #1. Le concept de pile
La pile est une collection organisée par une série d'objets. Les opérations d'ajout et de suppression de ces objets suivent en principe un "Last In First Out" (LIFO).
Un seul objet peut être inséré dans la pile à tout moment, mais l'acquisition ou la suppression ne peut se faire qu'en haut de la pile. Par exemple, dans une pile de livres, le seul livre dont la couverture est exposée est celui du haut. Pour accéder aux autres livres, vous ne pouvez retirer que le livre du dessus, comme indiqué sur l'image :
.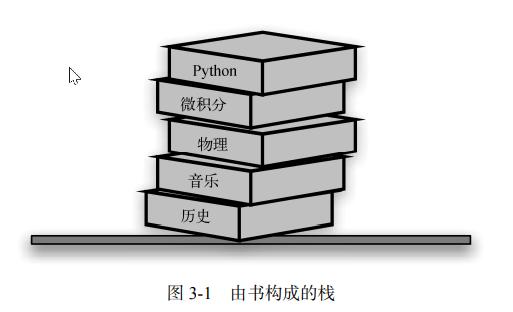 Application pratique de la stack
Application pratique de la stack
En fait, de nombreuses applications utiliseront la stack, telles que :
# 🎜🎜#Le navigateur Web affichera les URL récemment consultées et stockées dans une pile. Chaque fois qu'un utilisateur visite un nouveau site Web, l'URL du nouveau site Web est placée en haut de la pile. De cette façon, chaque fois que nous cliquons sur le bouton "Retour" dans le navigateur (ou appuyons sur le raccourci clavier CTRL+Z, la plupart des raccourcis d'annulation), l'URL la plus récemment visitée peut apparaître pour revenir à la navigation précédemment visitée. État.
- Les éditeurs de texte fournissent généralement un mécanisme « d'annulation » pour annuler l'opération d'édition la plus récente et revenir à l'état précédent. Cette opération d'annulation est également réalisée en enregistrant l'état modifié du texte dans une pile.
- Gestion de la mémoire de certains langages de haut niveau, pile JVM, pile Python sont également utilisées pour la gestion de la mémoire, l'environnement d'exécution des fonctionnalités de langage imbriquées, etc.
- Backtracking (jouer à des jeux , recherche de chemin, recherche exhaustive)
- Utilisé dans les algorithmes, tels que la tour de Hanoï, la traversée d'arbres, les problèmes d'histogramme, et également utilisé dans les algorithmes de graphes, tels que le tri topologique
- #🎜🎜 # Traitement de la syntaxe :
- L'espace pour les paramètres et les variables locales est créé en interne à l'aide de la pile.
- Prise en charge de la récursion
- Expressions comme les suffixes ou les préfixes dans le compilateur# 🎜🎜# # 🎜🎜#2. Type de données abstrait de pile
- Toute structure de données est indissociable de la manière de sauvegarder et d'obtenir des données. Comme mentionné précédemment, la pile est la possession d'éléments triés, d'addition, d'opération. et la suppression se produisent toutes en haut (en haut de la pile), puis ses types de données abstraits incluent :
- top() : Renvoie l'élément en haut de la pile, mais ne supprime pas l'élément en haut de la pile ; si la pile est vide, cette opération fonctionnera.
- is_empty() : Si la pile ne contient aucun élément, renvoie une valeur booléenne True.
- size() : Renvoie les données des éléments de la pile. Il ne nécessite aucun paramètre et renvoie un entier. En Python, cela peut être réalisé en utilisant la méthode spéciale __len__.
- La taille de la pile Python peut être fixe, ou il peut y avoir une implémentation dynamique qui permet à la taille de changer. Dans le cas d'une pile de taille fixe, tenter d'ajouter un élément à une pile déjà pleine entraînera une exception de débordement de pile. De même, essayer de supprimer un élément d'une pile déjà vide
pop() Cette situation est appelée sous-débordement.
 Lorsque vous apprenez Python, vous devez avoir appris les listes Python
Lorsque vous apprenez Python, vous devez avoir appris les listes Python list , il peut implémenter la pile via certaines méthodes intégrées Fonction :
pop() 操作这种情况被称为下溢。
三、用 Python 的列表实现栈
在学习 Python 的时候,一定学过 Python 列表 listLa méthode append est utilisée pour ajouter un élément à la fin de la liste. Cette méthode peut simuler l'opération push().
- La méthode pop() est utilisée pour simuler les opérations pop.
- Simulez l'opération top() via L[-1].
- Simulez l'opération isEmpty() en jugeant len(L)==0.
- La fonction size() est implémentée via la fonction len().
Le code est le suivant : 
class ArrayStack:
""" 通过 Python 列表实现 LIFO 栈"""
def __init__(self):
self._data = []
def size(self):
""" return the number of elements in the stack"""
return len(self._data)
def is_empty(self):
""" return True if the stack is empty"""
return len(self._data) == 0
def push(self, e):
""" add element e to the top of the stack"""
self._data.append(e)
def pop(self):
""" remove and return the element from the top of the stack
"""
if self.is_empty():
raise Exception('Stack is empty')
return self._data.pop()
def top(self):
"""return the top of the stack
Raise Empty exception if the stack is empty
"""
if self.is_empty():
raise Exception('Stack is empty')
return self._data[-1]# the last item in the list
arrayStack = ArrayStack()
arrayStack.push("Python")
arrayStack.push("Learning")
arrayStack.push("Hello")
print("Stack top element: ", arrayStack.top())
print("Stack length: ", arrayStack.size())
print("Stack popped item: %s" % arrayStack.pop())
print("Stack is empty?", arrayStack.is_empty())
arrayStack.pop()
arrayStack.pop()
print("Stack is empty?", arrayStack.is_empty())
# arrayStack.pop()
Exécutez ce programme, le résultat est :
Stack top element:Hello Stack length:3 Stack popped item: Hello Stack is empty? False Stack is empty? True
En plus d'utiliser la fin de la liste comme haut de la pile, vous pouvez également utiliser la tête de la liste comme haut de la pile. Cependant, dans ce cas, vous ne pouvez pas utiliser directement les méthodes pop() et append(), mais vous pouvez accéder explicitement à l'élément d'index 0, qui est le premier élément de la liste, via les méthodes pop() et insert(). . , le code est le suivant :
class ArrayStack:
""" 通过 Python 列表实现 LIFO 栈"""
def __init__(self):
self._data = []
def size(self):
""" return the number of elements in the stack"""
return len(self._data)
def is_empty(self):
""" return True if the stack is empty"""
return len(self._data) == 0
def push(self, e):
""" add element e to the top of the stack"""
self._data.insert(0, e)
def pop(self):
""" remove and return the element from the top of the stack
"""
if self.is_empty():
raise Exception('Stack is empty')
return self._data.pop(0)
def top(self):
"""return the top of the stack
Raise Empty exception if the stack is empty
"""
if self.is_empty():
raise Exception('Stack is empty')
return self._data[0]# the last item in the listBien que nous ayons modifié l'implémentation du type de données abstrait, nous avons conservé ses caractéristiques logiques. Cette capacité incarne des idées abstraites. Quoi qu'il en soit, bien que les deux méthodes implémentent des piles, leurs méthodes de performances sont différentes : la complexité temporelle des méthodes
- append() et pop() sont toutes deux *O(1), *opérations de niveau constant
- Les performances de la seconde l'implémentation est limitée par le nombre d'éléments dans la pile. En effet, la complexité temporelle de insert(0) et pop(0) est O(n), et plus il y a d'éléments, plus elle sera lente.
4. Utilisez collections.deque pour implémenter la pile
En Python, le module collections a une structure de données de file d'attente à double extrémité deque. Cette structure de données implémente également les méthodes append() et pop() :
>>> from collections import deque
>>> myStack = deque()
>>> myStack.append('Apple')
>>> myStack.append('Banana')
>>> myStack.append('Orange')
>>>
>>> myStack
deque(['Apple', 'Banana', 'Orange'])
>>> myStack.pop()
'Orange'
>>> myStack.pop()
'Banana'
>>>
>>> len(myStack)
1
>>> myStack[0]
'Apple'
>>> myStack.pop()
'Apple'
>>>
>>> myStack.pop()
Traceback (most recent call last):
File "<pyshell#13>", line 1, in <module>
myStack.pop()
IndexError: pop from an empty deque
>>>. Pourquoi ? List a encore besoin de Deque ?
Peut-être pouvez-vous voir que deque et list fonctionnent sur les éléments de la même manière, alors pourquoi Python ajoute-t-il une structure de données deque aux listes ?
C'est parce que les listes en Python sont construites dans des blocs de mémoire contigus, ce qui signifie que les éléments de la liste sont stockés les uns à côté des autres.
Cela fonctionne très bien pour certaines opérations, comme l'indexation d'une liste. Obtenir myList[3] est rapide car Python sait exactement où la chercher en mémoire. Cette disposition de la mémoire permet également au découpage de bien fonctionner sur les listes.
La disposition de la mémoire contiguë de la liste peut prendre plus de temps pour .append() certains objets. Si le bloc de mémoire continue est plein, il devra alors obtenir un autre bloc de mémoire et copier d'abord l'intégralité du bloc de mémoire. Cette action peut prendre plus de temps que l'opération normale .append().
Le deque de file d'attente à double extrémité est basé sur une liste à double lien. Dans une structure de liste chaînée, chaque entrée est stockée dans son propre bloc de mémoire et comporte une référence à l'entrée suivante de la liste.
Il en va de même pour une liste doublement chaînée, sauf que chaque entrée a une référence à l'entrée précédente et suivante de la liste. Cela facilite l'ajout de nœuds aux deux extrémités de la liste.
Pour ajouter un nouvel élément à une structure de liste chaînée, définissez simplement la référence du nouvel élément pour qu'elle pointe vers le haut de la pile actuelle, puis pointez le haut de la pile vers le nouvel élément.

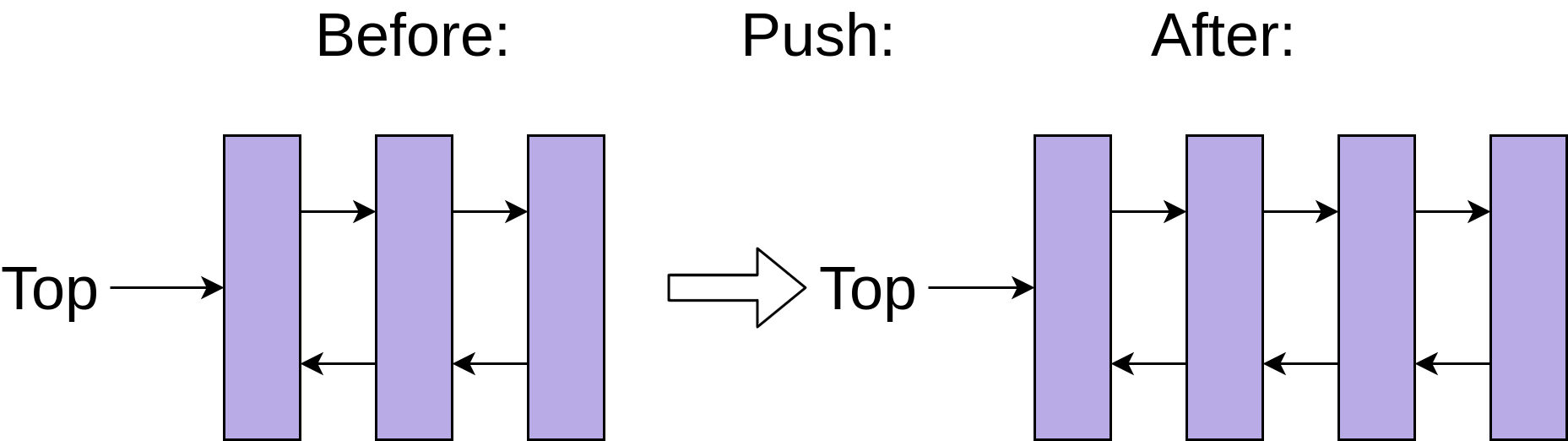
Cependant, cette période d'ajout et de suppression constants d'entrées sur la pile a un coût. Obtenir myDeque[3] est plus lent qu'une liste car Python doit parcourir chaque nœud de la liste pour obtenir le troisième élément.
Heureusement, vous souhaitez rarement indexer aléatoirement des éléments sur la pile ou effectuer des opérations de découpage de liste. La plupart des opérations sur la pile sont push ou pop.
Si votre code n'utilise pas de threads, les opérations à temps constant .append() et .pop() font de deque un meilleur choix pour implémenter la pile Python.
5. Utilisez queue.LifoQueue pour implémenter la stack
La pile Python est également très utile dans les programmes multithread. Nous avons déjà appris les deux méthodes list et deque. Pour toute structure de données accessible par plusieurs threads, nous ne devons pas utiliser de liste dans la programmation multithread car les listes ne sont pas thread-safe. Les méthodes .append() et .pop() de deque sont atomiques, ce qui signifie qu'elles ne seront pas interférées par différents threads.
Ainsi, même si l'utilisation de deque peut créer une pile Python thread-safe, cela vous expose à de futures utilisations abusives et crée des conditions de concurrence.
D'accord, si vous faites de la programmation multithread, vous ne pouvez pas utiliser list comme pile, et vous ne voulez probablement pas utiliser deque comme pile, alors comment créer une pile Python pour un programme threadé ?
La réponse réside dans le module de file d'attente : queue.LifoQueue. Rappelez-vous comment vous avez appris que la pile fonctionne selon le principe du dernier entré, premier sorti (LIFO) ? Eh bien, c'est ce que représente la partie "Lifo" de LifoQueue.
Bien que les interfaces de list et deque soient similaires, LifoQueue utilise .put() et .get() pour ajouter et supprimer des données de la pile.
>>> from queue import LifoQueue
>>> stack = LifoQueue()
>>> stack.put('H')
>>> stack.put('E')
>>> stack.put('L')
>>> stack.put('L')
>>> stack.put('O')
>>> stack
<queue.LifoQueue object at 0x00000123159F7310>
>>>
>>> stack.get()
'O'
>>> stack.get()
'L'
>>> stack.empty()
False
>>> stack.qsize()
3
>>> stack.get()
'L'
>>> stack.get()
'E'
>>> stack.qsize()
1
>>> stack.get()
'H'
>>> stack.get_nowait()
Traceback (most recent call last):
File "<pyshell#31>", line 1, in <module>
stack.get_nowait()
_queue.Empty
>>>
>>> stack.put('Apple')
>>> stack.get_nowait()
'Apple'与 deque 不同,LifoQueue 被设计为完全线程安全的。它的所有方法都可以在线程环境中安全使用。它还为其操作添加了可选的超时功能,这在线程程序中经常是一个必须的功能。
然而,这种完全的线程安全是有代价的。为了实现这种线程安全,LifoQueue 必须在每个操作上做一些额外的工作,这意味着它将花费更长的时间。
通常情况下,这种轻微的减速对你的整体程序速度并不重要,但如果你已经测量了你的性能,并发现你的堆栈操作是瓶颈,那么小心地切换到 deque 可能是值得做的。
六、选择哪一种实现作为栈
一般来说,如果你不使用多线程,你应该使用 deque。如果你使用多线程,那么你应该使用 LifoQueue,除非你已经测量了你的性能,发现 push 和 pop 的速度的小幅提升会带来足够的差异,以保证维护风险。
你可以对列表可能很熟悉,但需要谨慎使用它,因为它有可能存在内存重新分配的问题。deque 和 list 的接口是相同的,而且 deque 没有线程不安全问题。
七、总结
本文介绍了栈这一数据结构,并介绍了在现实生活中的程序中如何使用它的情况。在文章的中,介绍了 Python 中实现栈的三种不同方式,知道了 deque 对于非多线程程序是一个更好的选择,如果你要在多线程编程环境中使用栈的话,可以使用 LifoQueue。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!