
Maison >Opération et maintenance >exploitation et maintenance Linux >Comment installer Hadoop sous Linux
Comment installer Hadoop sous Linux

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-18 20:19:134615parcourir
1 : Installez JDK
1. Exécutez la commande suivante pour télécharger le package d'installation de JDK1.8.
wget --no-check-certificate https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz
2. Exécutez la commande suivante pour décompresser le package d'installation JDK1.8 téléchargé.
tar -zxvf jdk-8u151-linux-x64.tar.gz
3. Déplacez et renommez le package JDK.
mv jdk1.8.0_151/ /usr/java8
4. Configurez les variables d'environnement Java.
echo 'export JAVA_HOME=/usr/java8' >> /etc/profile echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile source /etc/profile
5. Vérifiez si Java est installé avec succès.
java -version
Deux : Installez Hadoop
Remarque : Pour télécharger le package d'installation Hadoop, vous pouvez choisir la source Huawei (la vitesse est moyenne, acceptable, l'accent est mis sur la version complète), la source Tsinghua (la vitesse de téléchargement de la version 3.0 .0 ou supérieur est trop lent et il existe peu de versions), source de l'Université des études étrangères de Pékin (vitesse de téléchargement rapide, mais relativement peu de versions) - Je l'ai personnellement testé
1 Exécutez la commande suivante pour télécharger le package d'installation Hadoop. .
wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
2. Exécutez la commande suivante pour décompresser le package d'installation Hadoop dans /opt/hadoop.
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/ mv /opt/hadoop-3.1.3 /opt/hadoop
3. Exécutez la commande suivante pour configurer les variables d'environnement Hadoop.
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile source /etc/profile
4. Exécutez les commandes suivantes pour modifier les fichiers de configuration fil-env.sh et hadoop-env.sh.
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
5. Exécutez la commande suivante pour tester si Hadoop est installé avec succès.
hadoop version
Si les informations de version sont renvoyées, cela signifie que l'installation est réussie.
Trois : Configurez Hadoop
1. Modifiez le fichier de configuration Hadoop core-site.xml.
a. Exécutez la commande suivante pour accéder à la page d'édition. a. 执行以下命令开始进入编辑页面。
vim /opt/hadoop/etc/hadoop/core-site.xml
b. 输入i进入编辑模式。c. 在<configuration></configuration>节点内插入如下内容。
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>d. 按Esc键退出编辑模式,输入:wq保存退出。
2. 修改Hadoop配置文件 hdfs-site.xml。
a. 执行以下命令开始进入编辑页面。
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
b. 输入i进入编辑模式。c. 在<configuration></configuration>节点内插入如下内容。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>d. 按Esc键退出编辑模式,输入:wq保存退出。
四:配置SSH免密登录
1. 执行以下命令,创建公钥和私钥。
ssh-keygen -t rsa
2. 执行以下命令,将公钥添加到authorized_keys文件中。
cd ~ cd .ssh cat id_rsa.pub >> authorized_keys
若报错,执行下面操作后重新执行上面两句命令;若没有报错直接进入第五步:
输入如下命令,在环境变量中添加下面的配置
vi /etc/profile
然后向里面加入如下的内容
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
输入如下命令使改动生效
source /etc/profile
b. Entrez i pour passer en mode édition. c. Insérez le contenu suivant dans le nœud <configuration></configuration> hadoop namenode -format
d. Appuyez sur la touche Echap pour quitter le mode d'édition, entrez : wq pour enregistrer et quitter. 2. Modifiez le fichier de configuration Hadoop hdfs-site.xml.
a. Exécutez la commande suivante pour commencer à accéder à la page d'édition. start-dfs.sh
b. Entrez i pour passer en mode édition. c. Insérez le contenu suivant dans le nœud <configuration></configuration> start-yarn.sh
d. Appuyez sur la touche Echap pour quitter le mode d'édition, entrez : wq pour enregistrer et quitter.
Quatre : Configurez la connexion SSH sans mot de passe
1 Exécutez les commandes suivantes pour créer la clé publique et la clé privée. jps
2. Exécutez la commande suivante pour ajouter la clé publique au fichierauthorized_keys.
rrreee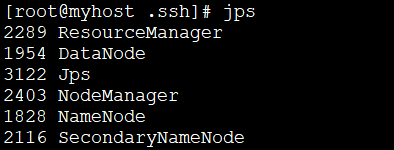 Si une erreur est signalée, effectuez les opérations suivantes puis réexécutez les deux commandes ci-dessus ; si aucune erreur n'est signalée, passez directement à la cinquième étape :
Si une erreur est signalée, effectuez les opérations suivantes puis réexécutez les deux commandes ci-dessus ; si aucune erreur n'est signalée, passez directement à la cinquième étape :
Entrez la commande suivante et ajoutez ce qui suit configuration à la variable d'environnement
rrreee
Puis ajoutez-y le contenu suivantrrreeeEntrez la commande suivante pour que les modifications prennent effetrrreeeCinq : Démarrez Hadoop
1.
 rrreee
rrreee
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Apprenez à installer le serveur Nginx sous Linux
- Introduction détaillée à la commande wget de Linux
- Explication détaillée d'exemples d'utilisation de yum pour installer Nginx sous Linux
- Explication détaillée des problèmes de connexions des travailleurs dans Nginx
- Explication détaillée du processus d'installation de python3 sous Linux