
Maison >Périphériques technologiques >IA >La distillation peut également se faire étape par étape : une nouvelle méthode permet de comparer les petits modèles aux grands modèles 2 000 fois plus grands.
La distillation peut également se faire étape par étape : une nouvelle méthode permet de comparer les petits modèles aux grands modèles 2 000 fois plus grands.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-18 18:31:30822parcourir
Bien que les grands modèles de langage aient des capacités étonnantes, en raison de leur grande échelle, les coûts nécessaires à leur déploiement sont souvent énormes. L'Université de Washington, en collaboration avec le Google Cloud Computing Artificial Intelligence Research Institute et Google Research, a résolu ce problème et a proposé le paradigme Distilling Step-by-Step pour aider à modéliser la formation. Par rapport au LLM, cette méthode est plus efficace pour former de petits modèles et les appliquer à des tâches spécifiques, et nécessite moins de données de formation que le réglage et la distillation traditionnels. Lors d'une tâche de référence, leur modèle 770M T5 a surpassé le modèle 540B PaLM. Il est impressionnant de constater que leur modèle n’utilisait que 80 % des données disponibles.

Bien que les grands modèles de langage (LLM) aient démontré des capacités d'apprentissage impressionnantes en quelques étapes, il est difficile de déployer des modèles à si grande échelle dans des applications du monde réel. Une infrastructure dédiée au service d'un LLM à l'échelle de 175 milliards de paramètres nécessite au moins 350 Go de mémoire GPU. De plus, le LLM de pointe actuel est composé de plus de 500 milliards de paramètres, ce qui signifie qu'il nécessite plus de mémoire et de ressources informatiques. De telles exigences informatiques sont hors de portée pour la plupart des fabricants, sans parler des applications nécessitant une faible latence.
Afin de résoudre ce problème des grands modèles, les déployeurs utilisent souvent à la place des modèles spécifiques plus petits. Ces modèles plus petits sont formés à l'aide de paradigmes communs : réglage fin ou distillation. Le réglage fin met à niveau un petit modèle pré-entraîné à l’aide de données annotées humaines en aval. La distillation entraîne un modèle tout aussi plus petit en utilisant les étiquettes produites par le plus grand LLM. Malheureusement, ces paradigmes ont un coût en réduisant la taille du modèle : pour obtenir des performances comparables à celles du LLM, le réglage fin nécessite des étiquettes humaines coûteuses, tandis que la distillation nécessite de grandes quantités de données non étiquetées difficiles à obtenir.
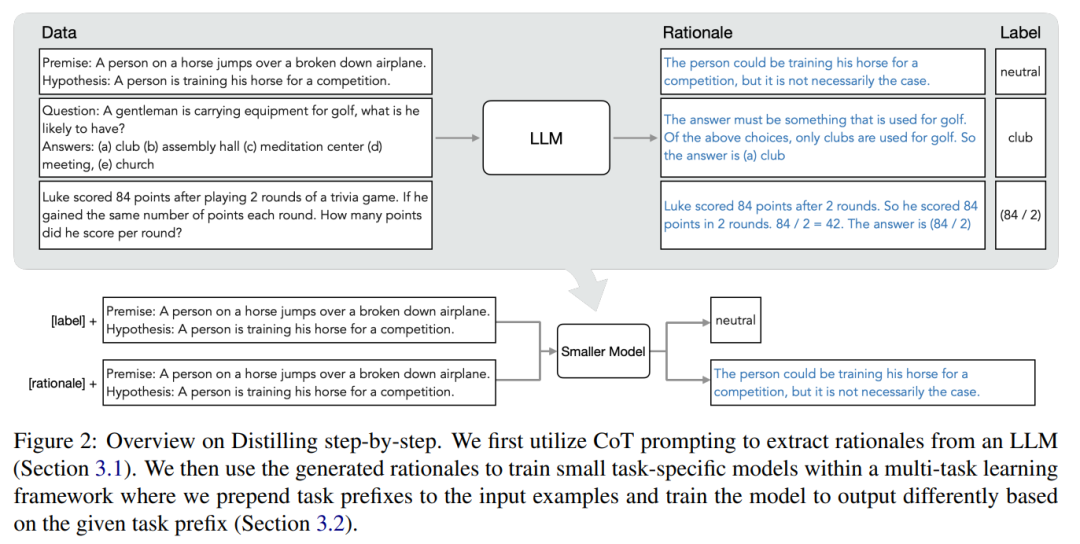
Dans un article intitulé "Distilling Step-by-Step ! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes", des chercheurs de l'Université de Washington et de Google ont présenté un nouveau mécanisme simple ——Distillation étape par étape, utilisé pour former des modèles plus petits en utilisant moins de données de formation. Ce mécanisme réduit la quantité de données de formation nécessaires pour affiner et distiller le LLM, ce qui entraîne une taille de modèle plus petite. Le cœur de ce mécanisme est de changer la perspective et de considérer le LLM comme quelque chose qui peut être un agent de raisonnement, plutôt qu'une source d'étiquettes bruyantes. LLM peut générer des justifications en langage naturel qui peuvent être utilisées pour expliquer et étayer les étiquettes prédites par le modèle. Par exemple, lorsqu'on lui demande « Un homme transporte du matériel de golf, que pourrait-il avoir ? (a) des clubs, (b) un auditorium, (c) un centre de méditation, (d) une conférence, (e) une église », LLM peut répondre « (un ) club" par le biais d'un raisonnement en chaîne de pensée (CoT), et rationalise cette étiquette en expliquant que "la réponse doit être quelque chose utilisé pour jouer au golf". Parmi les choix ci-dessus, seuls les clubs sont utilisés pour le golf. Nous utilisons ces justifications comme informations supplémentaires et plus riches pour former des modèles plus petits dans un cadre de formation multitâche et effectuer une prédiction d'étiquettes et une prédiction de justification.
Comme le montre la figure 1, la distillation étape par étape peut apprendre de petits modèles pour des tâches spécifiques, et le nombre de paramètres de ces modèles est inférieur à 1/500 de LLM. La distillation par étapes utilise également beaucoup moins d’exemples de formation que le réglage fin ou la distillation traditionnelle. 
Les résultats expérimentaux montrent que parmi les 4 benchmarks PNL, il existe trois conclusions expérimentales prometteuses.
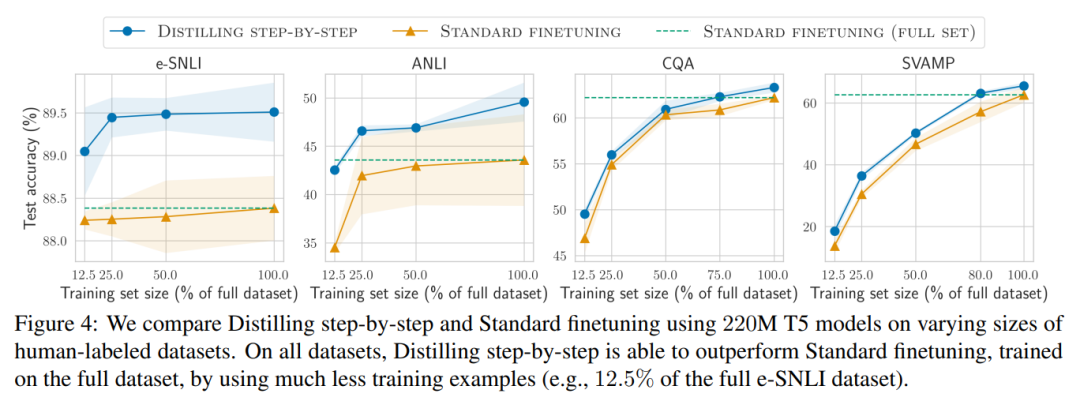
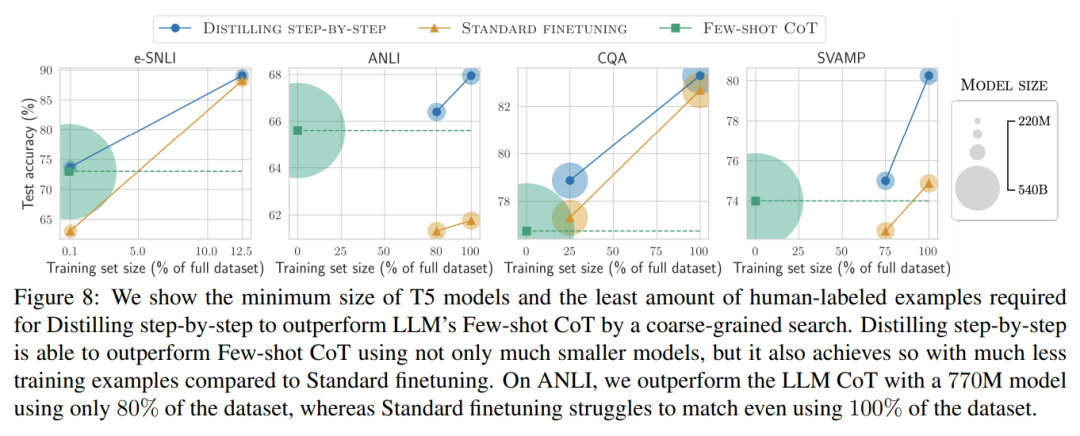
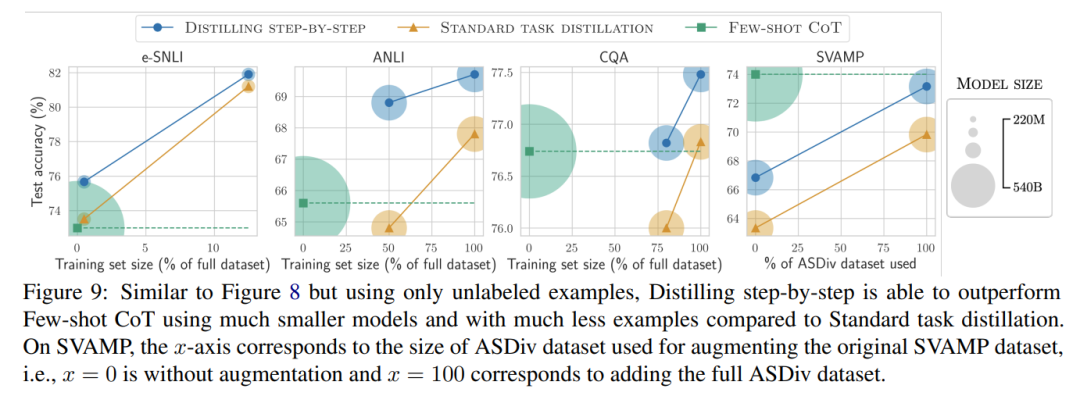
Lorsqu'il n'y a que des données non étiquetées, les performances du petit modèle sont toujours meilleures que celles du LLM - seule l'utilisation d'un modèle 11B T5 dépasse les performances du 540B PaLM. L'étude montre en outre que lorsqu'un modèle plus petit fonctionne moins bien que le LLM, la distillation par étapes peut utiliser plus efficacement des données supplémentaires non étiquetées que les méthodes de distillation standard pour rendre le modèle plus petit comparable aux performances du LLM. Les chercheurs ont proposé un nouveau paradigme de distillation par étapes, qui utilise la capacité de raisonnement du LLM pour prédire ses prédictions afin d'entraîner des modèles plus petits de manière efficace en termes de données. Le cadre global est présenté à la figure 2. Ce paradigme comporte deux étapes simples : premièrement, étant donné un LLM et un ensemble de données non étiqueté, inviter le LLM à générer une étiquette de sortie et une justification pour l'étiquette. La justification est expliquée en langage naturel et prend en charge les étiquettes prédites par le modèle (voir Figure 2). La justification est une propriété comportementale émergente des LLM auto-supervisés actuels. Ensuite, en plus des étiquettes de tâches, utilisez ces raisons pour former des modèles en aval plus petits. Pour parler franchement, les raisons peuvent fournir des informations plus riches et plus détaillées pour expliquer pourquoi une entrée est mappée à une étiquette de sortie spécifique. Les chercheurs ont vérifié l'efficacité de la distillation par étapes dans l'expérience. Premièrement, par rapport aux méthodes standard de réglage fin et de distillation de tâches, la distillation par étapes permet d'obtenir de meilleures performances avec un nombre beaucoup plus réduit d'exemples de formation, améliorant ainsi considérablement l'efficacité des données lors de l'apprentissage de petits modèles spécifiques à des tâches.
Distillation étape par étape
Résultats expérimentaux
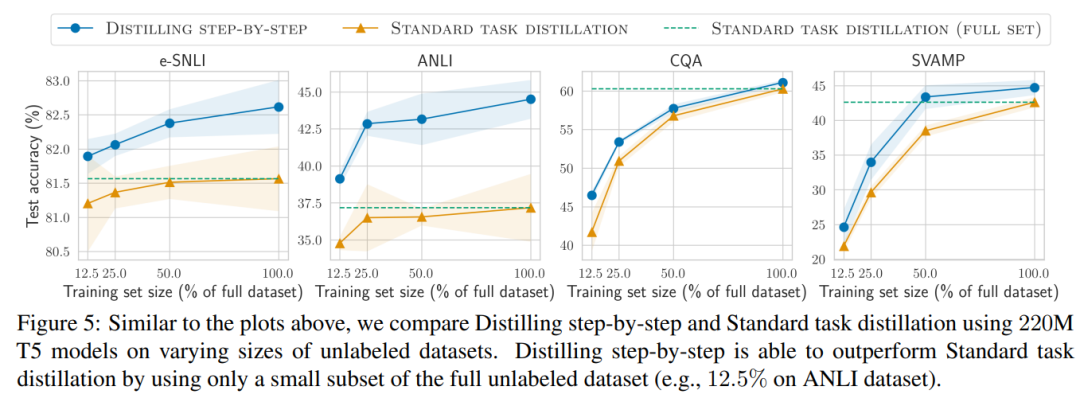
Deuxièmement, des études montrent que la méthode de distillation par étapes surpasse les performances du LLM avec des tailles de modèles plus petites, réduisant considérablement les coûts de déploiement par rapport au LLM.
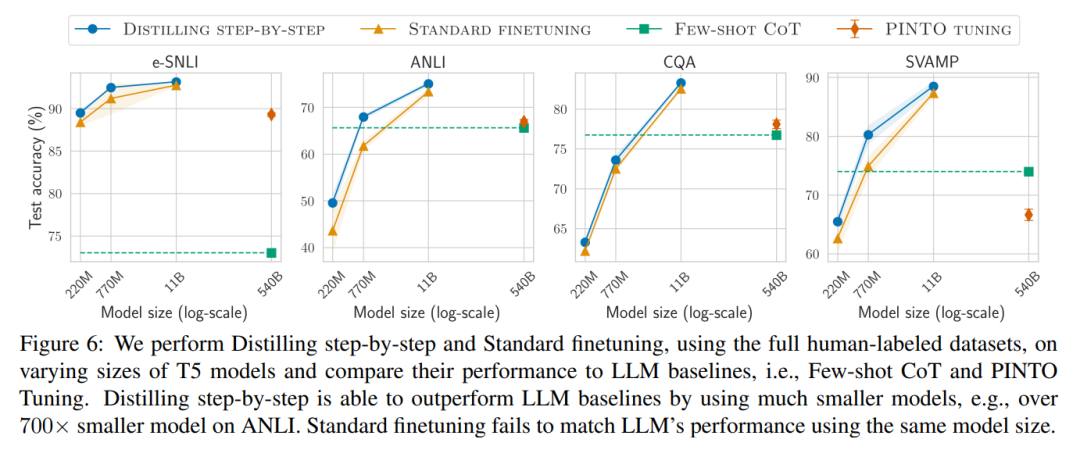
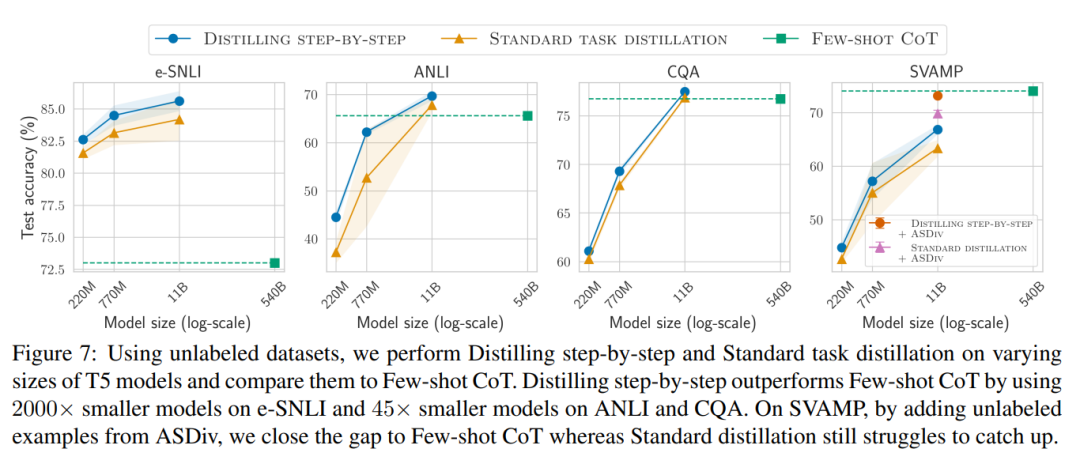
Enfin, nous avons étudié les ressources minimales requises par la méthode de distillation par étapes en termes de performances dépassant le LLM, y compris le nombre d'exemples de formation et la taille du modèle. Ils démontrent que l’approche de distillation par étapes améliore à la fois l’efficacité des données et celle du déploiement en utilisant moins de données et des modèles plus petits.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI