
Maison >Périphériques technologiques >IA >Les grands modèles inaugurent la « saison de l'open source », faisant le point sur le LLM et les ensembles de données open source du mois dernier.
Les grands modèles inaugurent la « saison de l'open source », faisant le point sur le LLM et les ensembles de données open source du mois dernier.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-18 16:31:131764parcourir
Il y a quelque temps, des documents internes divulgués par Google exprimaient l'opinion que même si, à première vue, il semble qu'OpenAI et Google se poursuivent sur de grands modèles d'IA, le véritable gagnant ne viendra peut-être pas de ces deux-là car il existe un tiers. se lève tranquillement. Cette puissance est « open source ».
Tournant autour du modèle open source LLaMA de Meta, l'ensemble de la communauté crée rapidement des modèles dotés de fonctionnalités similaires à celles d'OpenAI et des grands modèles de Google. De plus, le modèle open source itère plus rapidement, est plus personnalisable et plus privé.
Récemment, Sebastian Raschka, ancien professeur adjoint à l'Université du Wisconsin-Madison et directeur de la formation en IA de la startup Lightning AI, a déclaré : Pour l'open source, le mois dernier a été formidable.
Cependant, tant de grands modèles de langage (LLM) sont apparus les uns après les autres, et il n'est pas facile de garder une bonne maîtrise de tous les modèles. Ainsi, dans cet article, Sebastian partage des ressources et des informations sur la recherche sur les derniers LLM et ensembles de données open source.
Articles et tendances
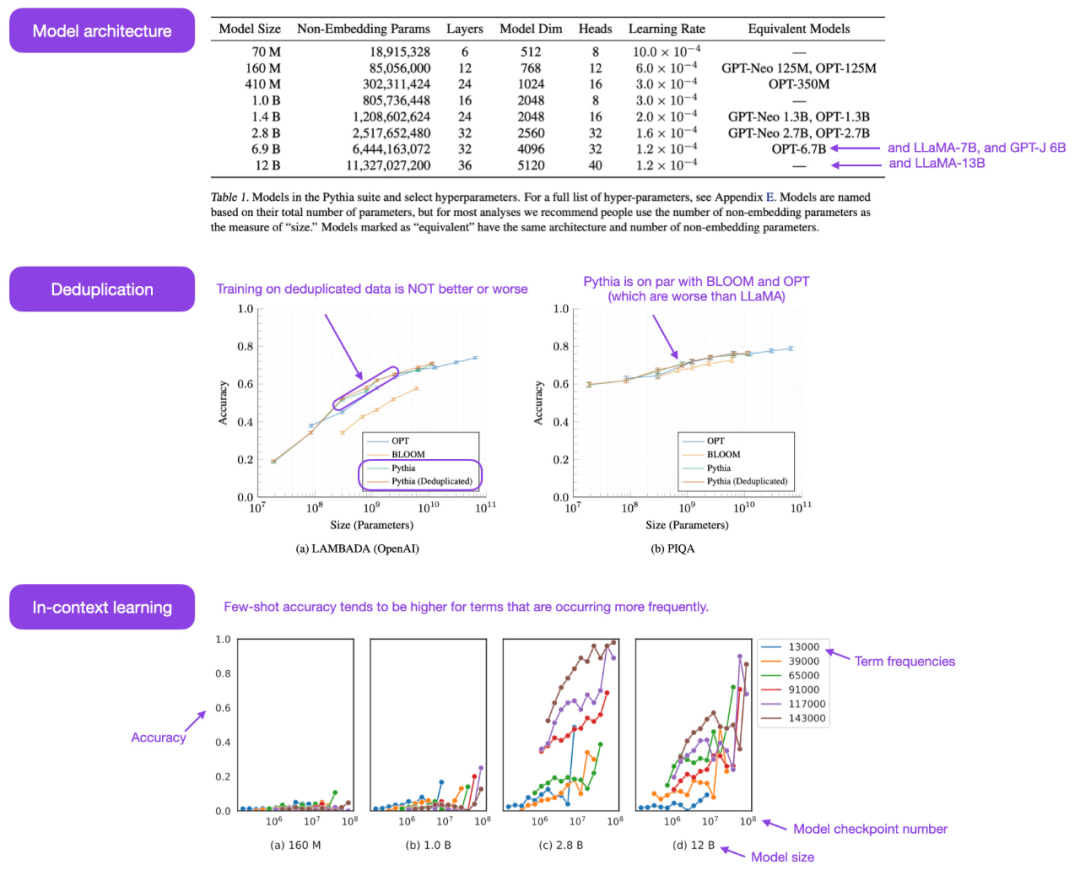
De nombreux articles de recherche ont été publiés au cours du mois dernier, il est donc difficile de choisir quelques favoris pour en discuter en profondeur. Sebastian préfère les articles qui fournissent des informations supplémentaires plutôt que de simplement démontrer des modèles plus puissants. Compte tenu de cela, ce qui a d’abord attiré son attention a été l’article Pythia co-écrit par des chercheurs d’Eleuther AI, de l’Université de Yale et d’autres institutions.

Adresse papier : https://arxiv.org/pdf/2304.01373.pdf
Pythia : Obtenir des informations grâce à une formation à grande échelle
Série Pythie open source Le modèle est vraiment une alternative intéressante aux autres modèles de style décodeur autorégressif (c'est-à-dire les modèles de type GPT). L'article révèle des informations intéressantes sur le mécanisme de formation et présente des modèles correspondants allant de 70M à 12B paramètres.
L'architecture du modèle Pythia est similaire à GPT-3 mais inclut quelques améliorations telles que l'attention Flash (comme LLaMA) et l'intégration de la position de rotation (comme PaLM). Dans le même temps, Pythia a été entraînée avec 300 B de jetons sur la pile d'ensembles de données texte diversifiés de 800 Go (1 époque sur la pile normale et 1,5 époque sur la pile de déduplication).
Voici quelques idées et réflexions tirées de l'article Pythia :
- L'entraînement sur des données répétées (c'est-à-dire l'époque d'entraînement> 1) aura-t-il un impact ? Les résultats montrent que la déduplication des données n'améliore ni ne nuit aux performances
- Les commandes d'entraînement affectent-elles la mémoire ? Malheureusement, il s’avère que non. Je dis désolé car, si c'est le cas, le problème de mémoire textuelle peut être atténué en réorganisant les données d'entraînement
- Doubler la taille du lot peut réduire de moitié le temps d'entraînement sans nuire à la convergence ;
Données Open Source
Le mois dernier a été particulièrement passionnant pour l'IA open source, avec l'émergence de plusieurs implémentations open source de LLM et une grande vague d'ensembles de données open source. Ces ensembles de données incluent Databricks Dolly 15k, OpenAssistant Conversations (OASST1) pour le réglage fin des instructions et RedPajama pour la pré-formation. Ces efforts en matière d'ensembles de données sont particulièrement louables, car la collecte et le nettoyage des données représentent 90 % des projets d'apprentissage automatique réels, et pourtant, peu de gens apprécient ce travail. Ensemble de données Databricks-Dolly-15 ).
Ensemble de données OASST1
L'ensemble de données OASST1 est utilisé pour affiner le LLM pré-entraîné sur une collection de conversations de type assistant ChatGPT créées et annotées par des humains, contenant 161 443 messages écrits en 35 langues et 461 292 évaluations de qualité . Ceux-ci sont organisés en plus de 10 000 arbres de dialogue entièrement annotés.
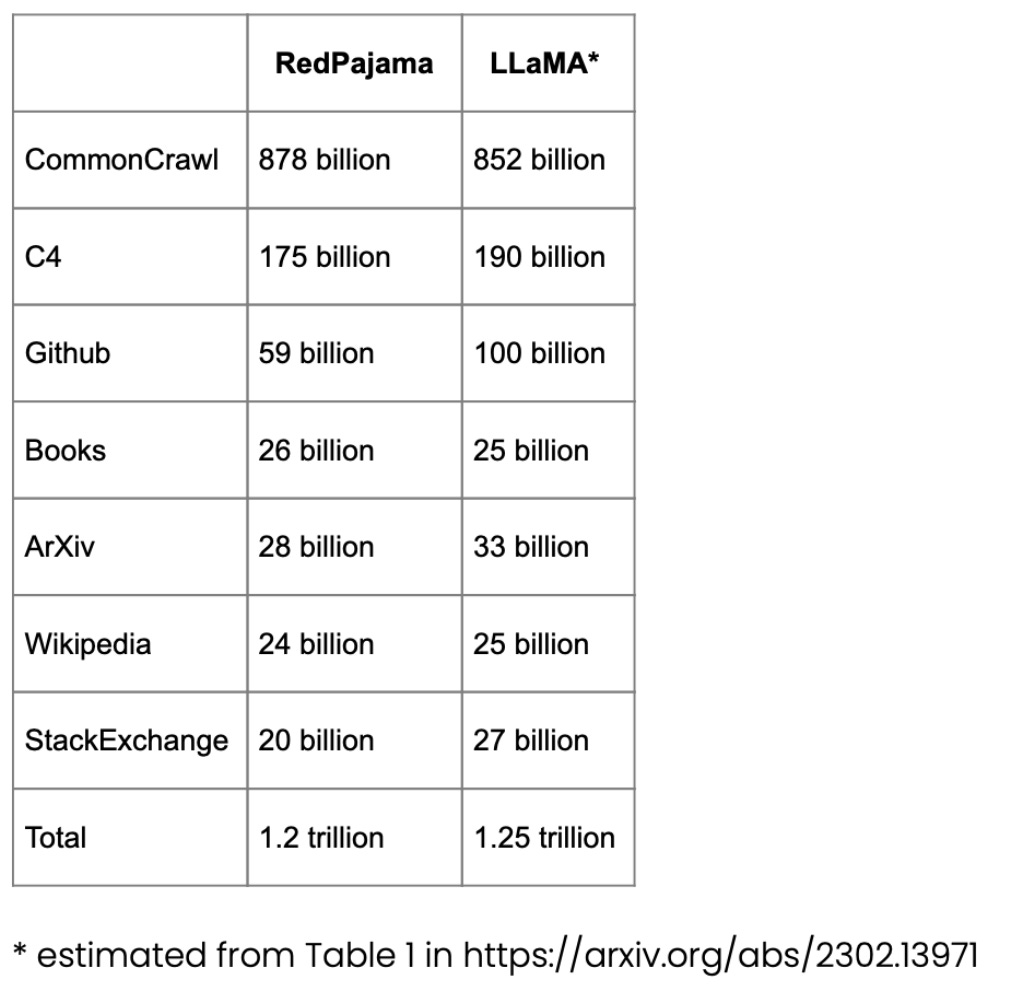
Ensemble de données RedPajama pour la pré-formation

RedPajama est un ensemble de données open source pour la pré-formation LLM, similaire au modèle SOTA LLaMA de Meta. Cet ensemble de données vise à créer un concurrent open source des LLM les plus populaires, qui sont actuellement soit des modèles commerciaux à source fermée, soit seulement partiellement open source.
La majeure partie de RedPajama se compose de CommonCrawl, qui filtre les sites en anglais, mais les articles Wikipédia couvrent 20 langues différentes.
Ensemble de données LongForm
L'article "The LongForm: Optimizing Instruction Tuning for Long Text Generation with Corpus Extraction" présente une collection de documents créés manuellement basés sur des corpus existants tels que C4 et Wikipedia et des instructions pour ces documents, créant ainsi un ensemble de données optimisé pour les instructions, adapté à la génération de textes longs. Adresse T Paper : https://arxiv.org/abs/2304.08460
Projets alPaca Libre
Le projet Alpaca Libre vise des démos sous licence MIT converties au format compatible Alpaca pour reproduire des projets Alpaca.
Élargir l'ensemble de données open source
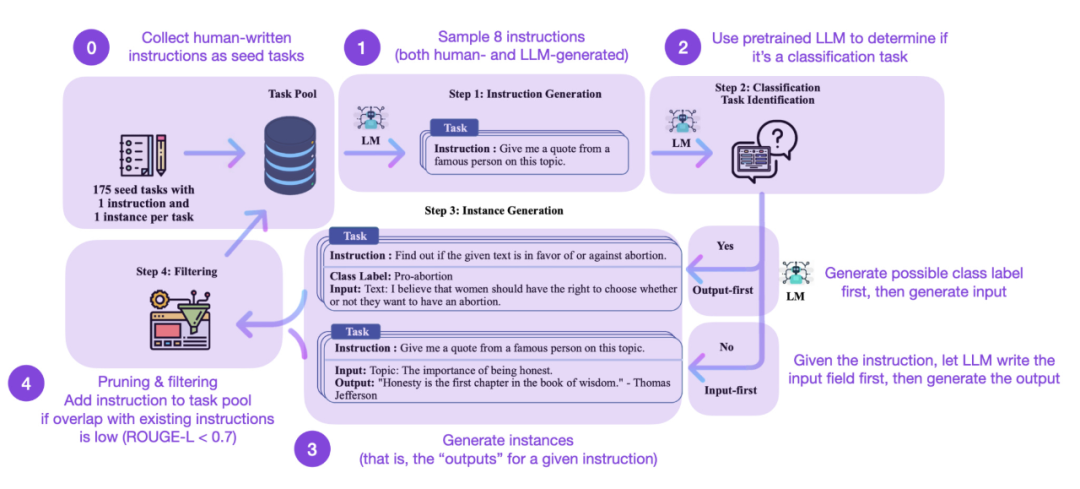
Le réglage fin des instructions est le moyen clé pour nous d'évoluer d'un modèle de base pré-entraîné de type GPT-3 à un modèle de langage étendu de type ChatGPT plus puissant. . Des ensembles de données d’instructions open source générées par l’homme, tels que Databricks-Dolly-15, contribuent à y parvenir. Mais comment pouvons-nous évoluer davantage ? Est-il possible de ne pas collecter de données supplémentaires ? Une approche consiste à amorcer un LLM à partir de sa propre itération. Bien que la méthode Self-Instruct ait été proposée il y a 5 mois (et soit dépassée par les standards actuels), elle reste une méthode très intéressante. Il convient de souligner qu'il est possible d'aligner des LLM pré-entraînés avec des instructions grâce au Self-Instruct, une méthode qui ne nécessite quasiment aucune annotation.
Comment ça marche ? En bref, il peut être divisé en quatre étapes suivantes :
La première est un pool de tâches de départ avec un ensemble d'instructions écrites manuellement (175 dans ce cas) et des exemples d'instructions ;
- La seconde consiste à utiliser ; un LLM pré-entraîné (comme GPT-3) pour déterminer la catégorie de tâche
- Ensuite, compte tenu de nouvelles instructions, le LLM pré-entraîné génère des réponses
- Enfin, les réponses sont collectées, tronquées et filtrées ; avant d'ajouter les instructions au pool de tâches.
Mais bien sûr, la référence en matière d'évaluation des LLM est de demander à des évaluateurs humains. Basé sur une évaluation humaine, Self-Instruct surpasse les LLM de base, ainsi que les LLM formés sur des ensembles de données d'instructions humaines de manière supervisée (comme SuperNI, T0 Trainer). Il est toutefois intéressant de noter que l’auto-instruction ne fonctionne pas mieux que les méthodes formées par apprentissage par renforcement avec feedback humain (RLHF).
Ensemble de données d'entraînement généré artificiellement ou synthétique
Ensemble de données d'instructions générées artificiellement ou ensemble de données d'auto-instruction, lequel est le plus prometteur ? Sebastian voit un avenir dans les deux. Pourquoi ne pas commencer avec un ensemble de données d'instructions généré manuellement (par exemple databricks-dolly-15k de 15k instructions), puis l'étendre à l'aide de l'auto-instruction ? L'article « Les données synthétiques des modèles de diffusion améliorent la classification ImageNet » montre que la combinaison d'ensembles de formation d'images réelles avec des images générées par l'IA peut améliorer les performances du modèle. Il serait intéressant de déterminer si cela est également vrai pour les données textuelles.
Adresse papier : https://arxiv.org/abs/2304.08466
L'article récent "De meilleurs modèles linguistiques de code grâce à l'auto-amélioration" porte sur la recherche dans cette direction. Les chercheurs ont découvert que les tâches de génération de code peuvent être améliorées si un LLM pré-entraîné utilise ses propres données générées.
Adresse papier : https://arxiv.org/abs/2304.01228
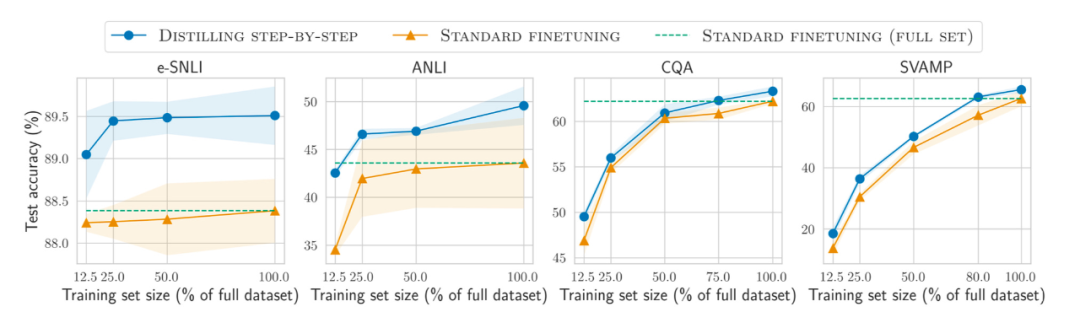
Moins c'est plus (Moins c'est plus) ?
De plus, en plus de données de plus en plus volumineuses En plus au pré-entraînement et au réglage fin du modèle sur l'ensemble, comment améliorer l'efficacité sur des ensembles de données plus petits ? L'article « Distilling Step-by-Step ! Surperforming Larger Language Models with Less Training Data and Smaller Model Sizes » propose d'utiliser un mécanisme de distillation pour gérer des modèles plus petits spécifiques à des tâches qui utilisent moins de données de formation mais dépassent les performances de réglage fin standard.
Adresse papier : https://arxiv.org/abs/2305.02301
Tracking open source LLM
Le nombre de LLM open source explose. une main , c'est une très bonne tendance (par rapport au contrôle du modèle via une API payante), mais d'un autre côté, suivre tout cela peut être fastidieux. Les quatre ressources suivantes fournissent différents résumés des modèles les plus pertinents, y compris leurs relations, les ensembles de données sous-jacents et diverses informations sur les licences.
La première ressource est le site Web des graphes d'écosystèmes basé sur l'article "Ecosystem Graphs: The Social Footprint of Foundation Models", qui fournit les tableaux et graphiques de dépendances interactifs suivants (non présentés ici).
Ce diagramme d'écosystème est la liste la plus complète que Sebastian ait vue à ce jour, mais il peut être un peu déroutant car il comprend de nombreux LLM moins populaires. La vérification du référentiel GitHub correspondant montre qu'il est mis à jour depuis au moins un mois. On ne sait pas non plus si des modèles plus récents seront ajoutés.
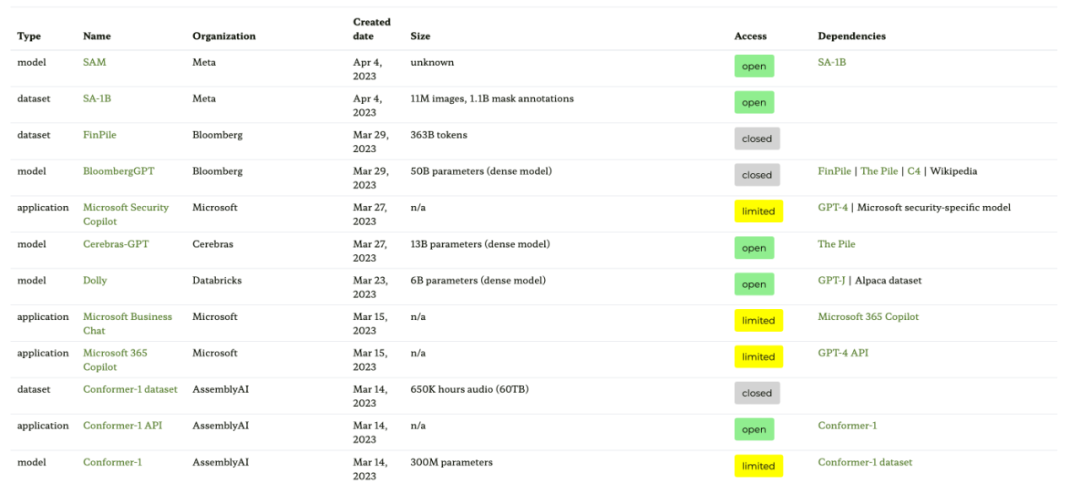
- Adresse papier : https://arxiv.org/abs/2303.15772
- Adresse du site Web du graphique de l'écosystème : https://crfm.stanford.edu/ecosystem-graphs / index.html?mode=table
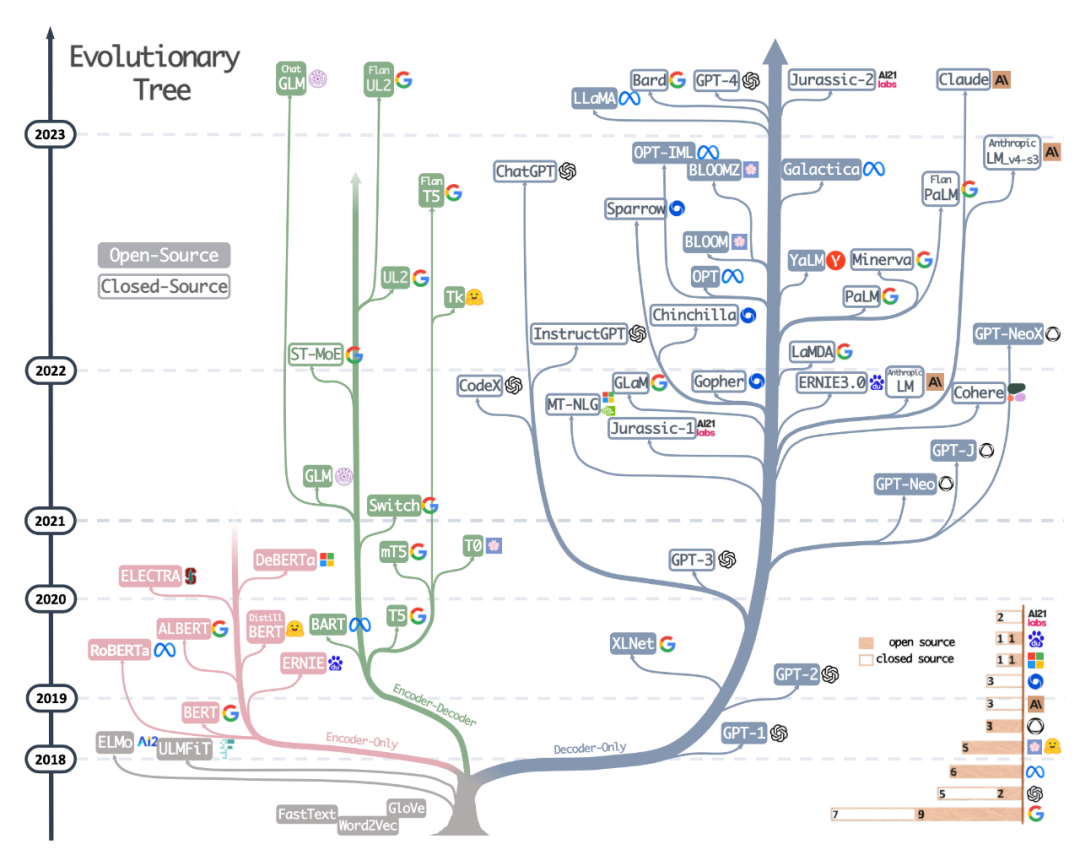
La deuxième ressource est l'arbre évolutif magnifiquement dessiné du récent article Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond, qui se concentre sur les LLM les plus populaires et leurs relations.
Bien que les lecteurs aient vu un arbre évolutif visuel LLM très beau et clair, ils ont également quelques petits doutes. Par exemple, il n'est pas clair pourquoi le bas ne part pas de l'architecture originale du transformateur. De plus, les étiquettes open source ne sont pas très précises, par exemple LLaMA est répertorié comme open source, mais les poids ne sont pas disponibles sous licence open source (seul le code d'inférence l'est).
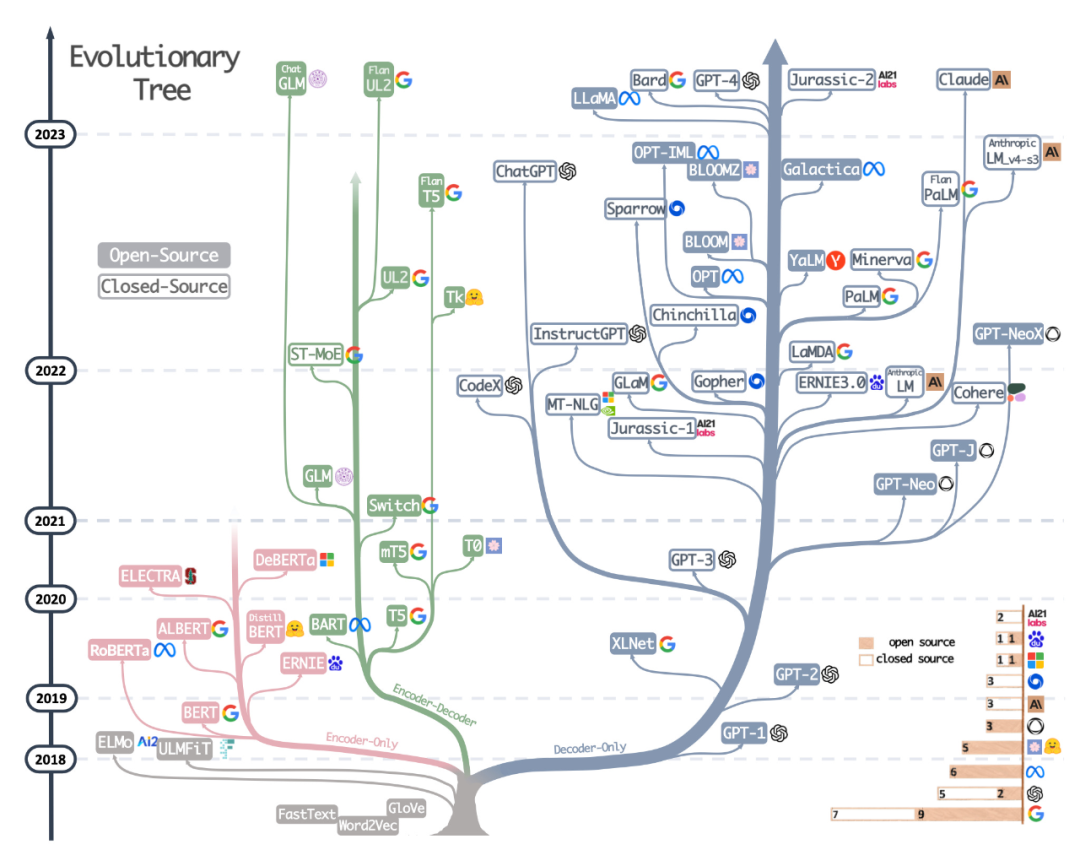
Adresse papier : https://arxiv.org/abs/2304.13712
La troisième ressource est un tableau dessiné par la collègue de Sebastian Daniela Dapena, du blog "The Ultimate Battle of Language Models: Lit-LLaMA vs GPT3.5 vs Bloom vs...".
Bien que le tableau ci-dessous soit plus petit que les autres ressources, il présente l'avantage d'inclure les dimensions du modèle et les informations de licence. Ce tableau sera très utile si vous envisagez d'utiliser ces modèles dans n'importe quel projet.
Adresse du blog : https://lightning.ai/pages/community/community-discussions/the-ultimate-battle-of-lingual-models-lit-llama-vs-gpt3.5-vs -bloom-vs/
La quatrième ressource est le tableau de présentation LLaMA-Cult-and-More, qui fournit des informations supplémentaires sur les méthodes de réglage fin et les coûts du matériel.
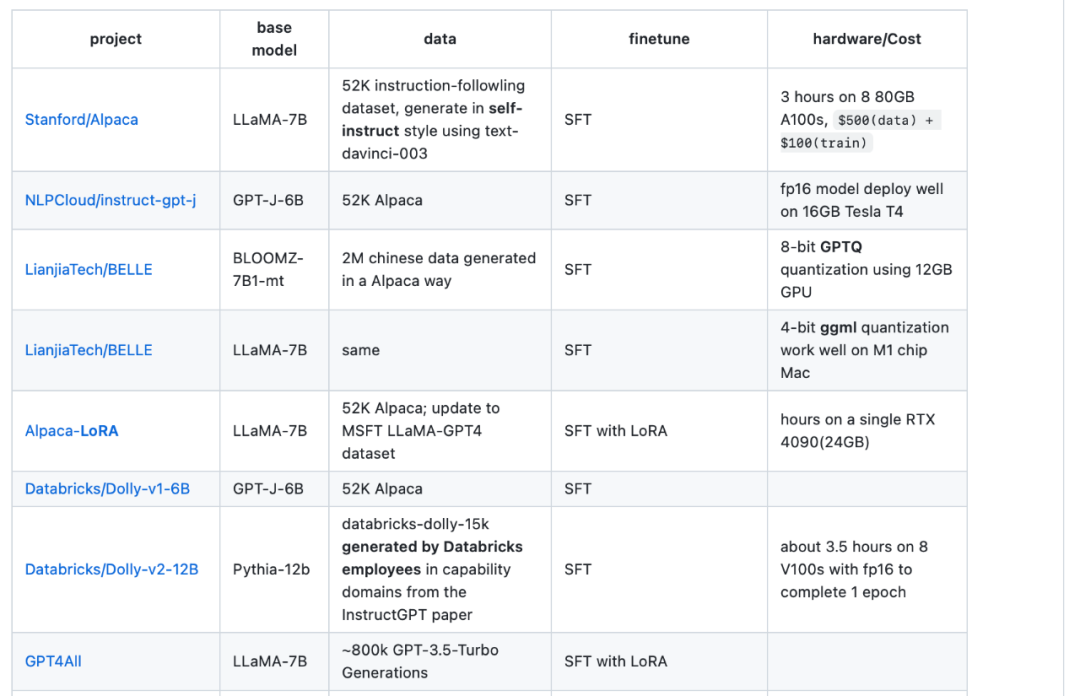
Adresse du tableau d'aperçu : https://github.com/shm007g/LLaMA-Cult-and-More/blob/main/chart.md
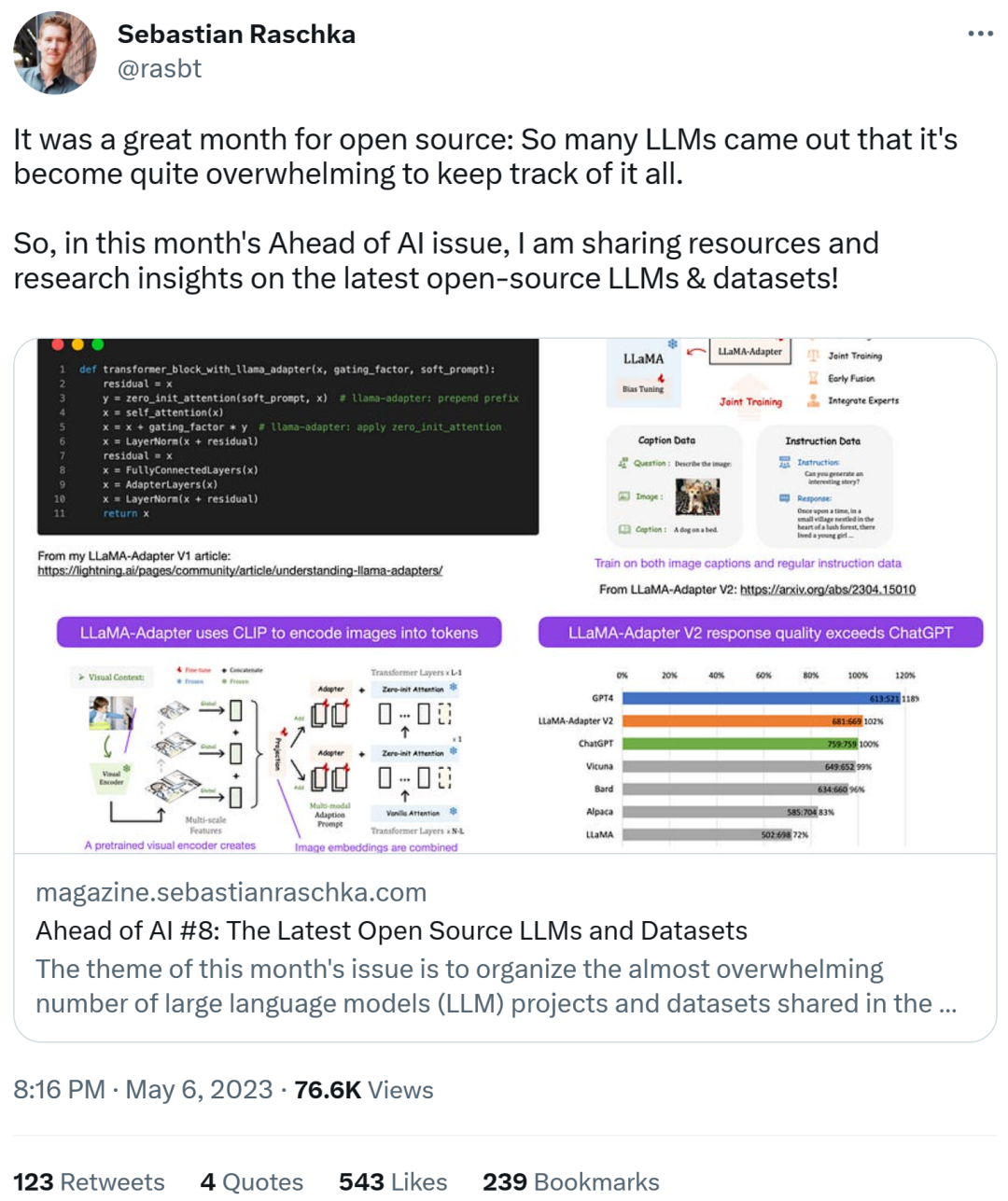
Utilisation de LLaMA-Adapter V2 Affiner le LLM multimodal
Sebastian prédit que nous verrons plus de modèles LLM multimodaux ce mois-ci, nous devons donc parler de l'article "LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model" publié non il y a longtemps. Tout d’abord, voyons ce qu’est LLaMA-Adapter ? Il s'agit d'une technique de réglage fin LLM efficace en termes de paramètres qui modifie les blocs de transformateurs précédents et introduit un mécanisme de déclenchement pour stabiliser l'entraînement.
Adresse papier : https://arxiv.org/abs/2304.15010
Grâce à la méthode LLaMA-Adapter, les chercheurs ont pu obtenir 52 000 paires d'instructions en seulement 1 heure (8 GPU A100). -réglage d'un modèle LLaMA à paramètres 7B. Bien que seuls les paramètres 1,2M nouvellement ajoutés (couche adaptateur) aient été affinés, le modèle 7B LLaMA est toujours figé.
LLaMA-Adapter V2 se concentre sur la multimodalité, c'est-à-dire la construction d'un modèle de commande visuelle pouvant recevoir une entrée d'image. Bien que la V1 originale puisse recevoir des jetons de texte et des jetons d'image, les images n'ont pas été entièrement explorées.
LLaMA-Adaptateur De la V1 à la V2, les chercheurs ont amélioré la méthode de l'adaptateur grâce aux trois techniques principales suivantes.
- Fusion précoce des connaissances visuelles : au lieu de fusionner des repères visuels et adaptés à chaque couche adaptée, connectez le jeton visuel au jeton de mot dans le premier bloc de transformateur
- Utilisez plus de paramètres : débloquez toutes les couches de normalisation et ajoutez-les ; unités de biais et facteurs d'échelle pour chaque couche linéaire du bloc de transformateur ;
- Entraînement conjoint avec des paramètres disjoints : pour les données de sous-titres, seule la couche de projection visuelle est entraînée ; seule la couche d'adaptation (et les paramètres nouvellement ajoutés ci-dessus) est entraînée ; sur les données, les instructions suivent.
LLaMA V2 (14M) a beaucoup plus de paramètres que LLaMA V1 (1,2 M), mais il est toujours léger, ne représentant que 0,02% du total des paramètres de 65B LLaMA. Ce qui est particulièrement impressionnant est qu'en ajustant uniquement 14 millions de paramètres du modèle 65B LLaMA, le LLaMA-Adapter V2 résultant fonctionne à égalité avec ChatGPT (lorsqu'il est évalué à l'aide du modèle GPT-4). LLaMA-Adapter V2 surpasse également le modèle 13B Vicuna en utilisant l'approche de réglage complet.
Malheureusement, l'article LLaMA-Adapter V2 omet le test de performances de calcul inclus dans l'article V1, mais nous pouvons supposer que la V2 est toujours beaucoup plus rapide que la méthode entièrement affinée.

Autre LLM open source
Le développement de grands modèles est si rapide que nous ne pouvons pas tous les lister. Certains des célèbres LLM et chatbots open source lancés ce mois-ci incluent Open-Assistant, Baize, StableVicuna, ColossalChat, Mosaic's MPT, etc. De plus, vous trouverez ci-dessous deux LLM multimodaux particulièrement intéressants.
OpenFlamingo
OpenFlamingo est une copie open source du modèle Flamingo publié par Google DeepMind l'année dernière. OpenFlamingo vise à fournir des capacités d'inférence d'image multimodales pour LLM, permettant aux utilisateurs d'entrelacer la saisie de texte et d'image.
MiniGPT-4
MiniGPT-4 est un autre modèle open source doté de capacités de langage visuel. Il est basé sur l'encodeur visuel gelé BLIP-27 et le Vicuna LLM gelé.
NeMo Guardrails
Avec l'émergence de ces grands modèles de langage, de nombreuses entreprises réfléchissent à la manière et à l'opportunité de les déployer, et les problèmes de sécurité sont particulièrement importants. Il n’existe pas encore de bonnes solutions, mais il existe au moins une autre approche prometteuse : NVIDIA a mis à disposition une boîte à outils open source pour résoudre le problème des hallucinations LLM.
En un mot, comment cela fonctionne, c'est que cette méthode utilise des liens de base de données vers des invites codées en dur qui doivent être gérées manuellement. Ensuite, si l'utilisateur saisit une invite, ce contenu sera d'abord mis en correspondance avec l'entrée la plus similaire dans cette base de données. La base de données renvoie ensuite une invite codée en dur qui est ensuite transmise à LLM. Ainsi, si l'on teste soigneusement l'invite codée en dur, on peut s'assurer que l'interaction ne s'écarte pas des sujets autorisés, etc.
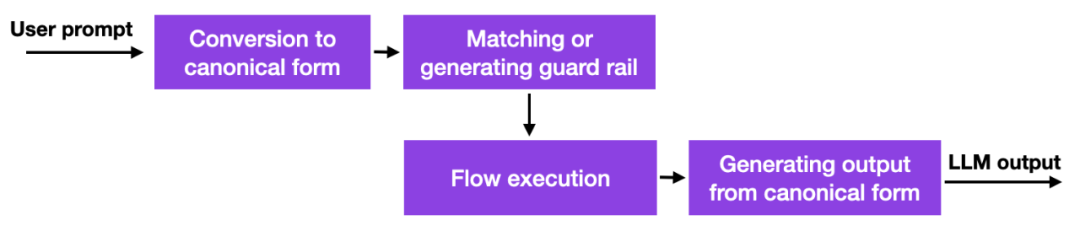
Il s'agit d'une approche intéressante mais pas révolutionnaire car elle n'offre pas de fonctionnalités meilleures ou nouvelles au LLM, elle limite simplement la mesure dans laquelle l'utilisateur peut interagir avec le LLM. Pourtant, jusqu'à ce que les chercheurs trouvent des moyens alternatifs pour atténuer les problèmes d'hallucinations et les comportements négatifs en LLM, cela peut être une approche viable.
L'approche des garde-corps peut également être combinée avec d'autres techniques d'alignement, telles que le paradigme populaire de formation par apprentissage par renforcement par feedback humain présenté par l'auteur dans un numéro précédent d'Ahead of AI.
Consistency Models
C'est une bonne tentative de parler de modèles intéressants autres que LLM OpenAI qui ont enfin open source le code de leur modèle de cohérence : https://github.com/openai/consistency_models.
Le modèle de cohérence est considéré comme une alternative viable et efficace au modèle de diffusion. Vous pouvez obtenir plus d’informations dans le document sur le modèle de cohérence.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI