
Maison >Périphériques technologiques >IA >L'intégration de mots représente-t-elle une proportion trop importante de paramètres ? Méthode MorphTE 20 fois l'effet de compression sans perte
L'intégration de mots représente-t-elle une proportion trop importante de paramètres ? Méthode MorphTE 20 fois l'effet de compression sans perte

- 王林avant
- 2023-05-17 16:01:061346parcourir
Introduction
La représentation d'intégration de mots est la base de diverses tâches de traitement du langage naturel telles que la traduction automatique, la réponse aux questions, la classification de texte, etc. Elle représente généralement 20 à 90 % du total des paramètres du modèle. Le stockage et l'accès à ces intégrations nécessitent une grande quantité d'espace, ce qui n'est pas propice au déploiement et à l'application de modèles sur des appareils aux ressources limitées. Pour résoudre ce problème, cet article propose la Méthode de compression d'intégration de mots MorphTE. MorphTE combine les puissantes capacités de compression des opérations de produits tensoriels avec une connaissance préalable de la morphologie du langage pour obtenir une compression élevée des paramètres d'incorporation de mots (plus de 20 fois) tout en conservant les performances du modèle.

- Lien papier : https://arxiv.org/abs/2210.15379
- Code source ouvert : https://github.com/bigganbing/Fairseq_MorphTE
Modèle
La méthode de compression d'intégration de mots MorphTE proposée dans cet article divise d'abord les mots en les plus petites unités ayant une signification sémantique - les morphèmes, et entraîne une représentation vectorielle de basse dimension pour chaque morphème, puis utilise des produits tensoriels pour réaliser le quantum de faible dimension. vecteurs de morphèmes dimensionnels L'état intriqué est représenté mathématiquement pour obtenir une représentation de mots de grande dimension.
01 La composition morphémique d'un mot
En linguistique, un morphème est la plus petite unité ayant des fonctions sémantiques ou grammaticales spécifiques. Pour des langues comme l'anglais, un mot peut être divisé en unités plus petites de morphèmes telles que des racines et des affixes. Par exemple, « méchamment » peut être divisé en « un » pour la négation, « gentil » pour quelque chose comme « amical » et « ly » pour un adverbe. Pour le chinois, un caractère chinois peut également être divisé en unités plus petites telles que des radicaux. Par exemple, « MU » peut être divisé en « 氵 » et « 木 » qui représentent l'eau.

Bien que les morphèmes contiennent de la sémantique, ils peuvent également être partagés entre des mots pour relier différents mots. De plus, un nombre limité de morphèmes peuvent être combinés pour former un plus grand nombre de mots.
02 Représentation compressée d'incorporations de mots sous la forme de tenseurs intriqués
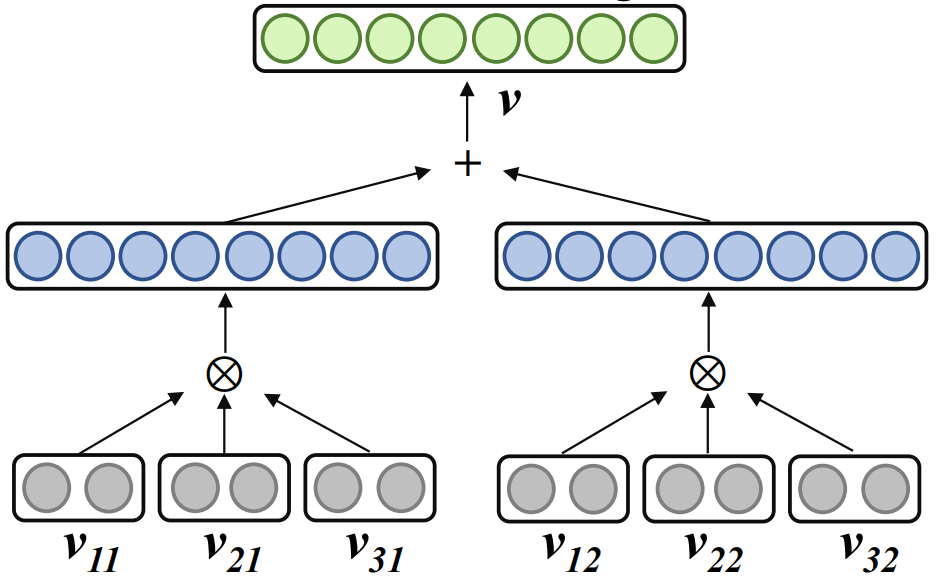
Travail connexe Word2ket utilise un produit tensoriel pour représenter un seul mot incorporé sous la forme d'une forme tensorielle intriquée de plusieurs vecteurs de faible dimension. La formule est la suivante. :
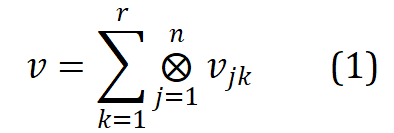
où , r est le rang, n est l'ordre, représente le produit tensoriel. Word2ket n'a besoin que de stocker et d'utiliser ces vecteurs de faible dimension pour créer des vecteurs de mots de haute dimension, obtenant ainsi une réduction efficace des paramètres. Par exemple, lorsque r = 2 et n = 3, un vecteur de mots d'une dimension de 512 peut être obtenu par deux groupes de trois produits tensoriels vectoriels de basse dimension d'une dimension de 8 dans chaque groupe. de paramètres est réduit de 512 à 48 .
03 Représentation de compression intégrant des mots tenseurs améliorés par la morphologie
Grâce au produit tenseur, Word2ket peut obtenir une compression de paramètres évidente. Cependant, il est généralement difficile d'obtenir des performances de pré-compression dans des tâches plus complexes telles que la compression haute puissance et la machine. traduction. Étant donné que les vecteurs de basse dimension sont les unités de base qui composent les tenseurs d'intrication, et que les morphèmes sont les unités de base qui composent les mots. Cette étude considère l'introduction des connaissances linguistiques et propose MorphTE, qui entraîne des vecteurs morphèmes de basse dimension et utilise le produit tensoriel des vecteurs morphèmes contenus dans le mot pour construire la représentation d'intégration de mot correspondante.
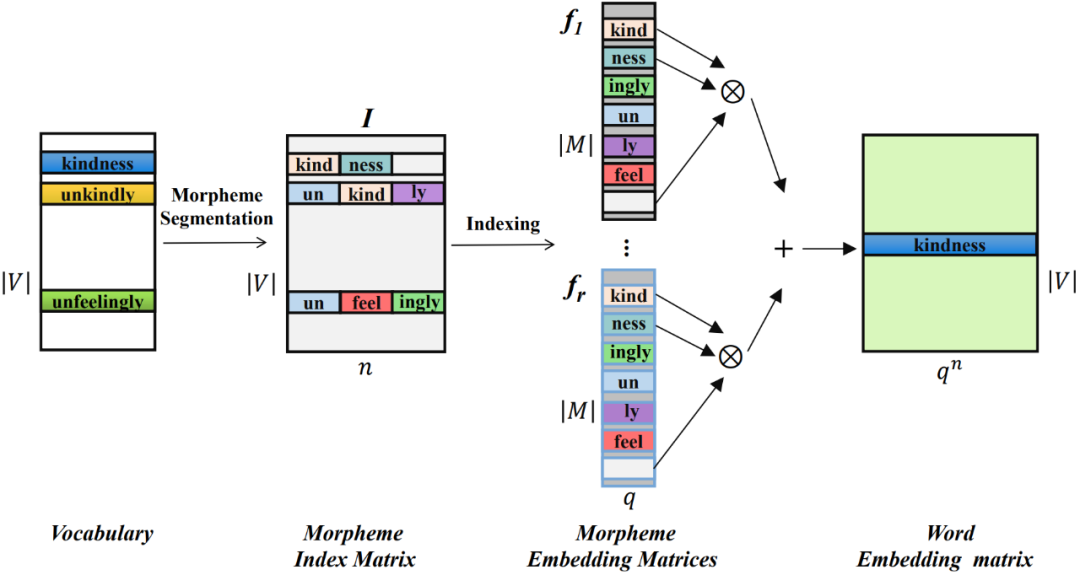
Plus précisément, utilisez d'abord l'outil de segmentation de morphèmes pour segmenter les mots de la liste de vocabulaire V. Les morphèmes de tous les mots formeront une liste de morphèmes M, et le nombre de morphèmes sera nettement inférieur au nombre de mots ( ).
Pour chaque mot, construisez son vecteur d'index de morphème, qui pointe vers la position du morphème contenu dans chaque mot dans la table des morphèmes. Les vecteurs d'index morphème de tous les mots forment une matrice d'index morphème de 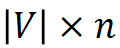 , où n est l'ordre de MorphTE.
, où n est l'ordre de MorphTE.
Pour le jème mot 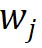 dans le vocabulaire, utilisez son vecteur d'index de morphème #🎜🎜 ## 🎜🎜# Indexez le vecteur de morphème correspondant à partir de r groupes de matrices d'incorporation de morphèmes paramétrées et effectuez une représentation tensorielle intriquée via un produit tensoriel pour obtenir l'incorporation de mots correspondante. Le processus est formalisé comme suit :
dans le vocabulaire, utilisez son vecteur d'index de morphème #🎜🎜 ## 🎜🎜# Indexez le vecteur de morphème correspondant à partir de r groupes de matrices d'incorporation de morphèmes paramétrées et effectuez une représentation tensorielle intriquée via un produit tensoriel pour obtenir l'incorporation de mots correspondante. Le processus est formalisé comme suit : 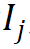 #🎜 🎜##🎜🎜. #
#🎜 🎜##🎜🎜. #
De la manière ci-dessus, MophTE peut injecter des connaissances linguistiques préalables basées sur les morphèmes dans la représentation d'incorporation de mots, tandis que les vecteurs morphèmes sont utilisés dans différents Le partage entre les mots peut explicitement établir des connexions entre les mots. De plus, le nombre et les dimensions vectorielles des morphèmes sont bien inférieurs à la taille et à la dimension du vocabulaire, et MophTE parvient à compresser les paramètres d'incorporation de mots sous les deux angles. Par conséquent, MophTE est capable d’obtenir une compression de haute qualité des représentations d’incorporation de mots. 
Expérience
Cet article mène principalement des expériences sur les tâches de traduction, de questions et réponses dans différentes langues et les intégrations de mots associées basées sur la décomposition. Méthodes de compression sont comparés.
Comme vous pouvez le voir sur le tableau, MorphTE peut s'adapter à différentes langues comme l'anglais, l'allemand, Italien, etc. Avec un taux de compression plus de 20 fois, MorphTE est capable de conserver l'effet du modèle d'origine, alors que presque toutes les autres méthodes de compression montrent une diminution de l'effet. De plus, MorphTE fonctionne mieux que les autres méthodes de compression sur différents ensembles de données avec un taux de compression plus de 40 fois. 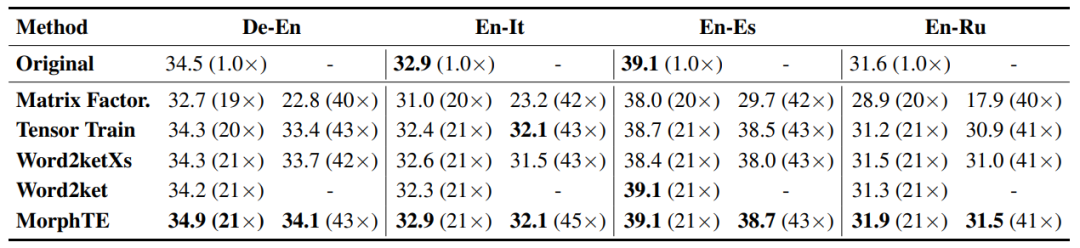
De même, sur la tâche de questions et réponses de WikiQA et la tâche de raisonnement en langage naturel de SNLI, MorphTE a réalisé respectivement 81 fois et. Taux de compression 38 fois, tout en conservant l'effet du modèle. 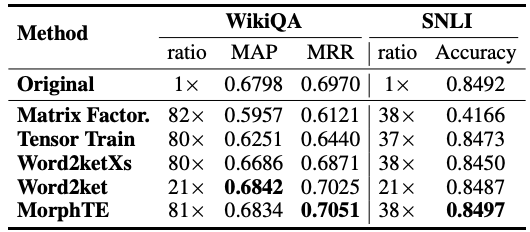
Conclusion
MorphTE combine une connaissance a priori du langage morphologique et la puissante capacité de compression des produits tensoriels pour obtenir une compression d'intégrations de mots de haute qualité. Des expériences sur différents langages et tâches montrent que MorphTE peut atteindre une compression de 20 à 80 fois les paramètres d'intégration de mots sans endommager l'effet du modèle. Cela vérifie que l'introduction de connaissances linguistiques basées sur les morphèmes peut améliorer l'apprentissage des représentations compressées des incorporations de mots. Bien que MorphTE ne modélise actuellement que les morphèmes, il peut en fait être étendu dans un cadre général d'amélioration de la compression de l'intégration de mots qui modélise explicitement des connaissances linguistiques plus a priori telles que les prototypes, les parties du discours, la capitalisation, etc., pour améliorer encore la compression express de l'intégration de mots.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI