
Maison >Périphériques technologiques >IA >Modèle de questions et réponses vidéo « Iterative Joint Certification » de Google et du MIT : performances SOTA, utilisant 80 % de puissance de calcul en moins
Modèle de questions et réponses vidéo « Iterative Joint Certification » de Google et du MIT : performances SOTA, utilisant 80 % de puissance de calcul en moins

- PHPzavant
- 2023-05-16 18:37:061206parcourir
La vidéo est une source omniprésente de contenu médiatique qui touche de nombreux aspects de la vie quotidienne des gens. Un nombre croissant d'applications vidéo réelles, telles que le sous-titrage vidéo, l'analyse de contenu et la réponse aux questions vidéo (VideoQA), s'appuient sur des modèles capables de connecter le contenu vidéo au texte ou au langage naturel.
Parmi eux, le modèle de questions et réponses vidéo est particulièrement difficile car il doit saisir à la fois des informations sémantiques, telles que les cibles dans la scène, et des informations temporelles, telles que comment les choses bougent et interagissent. Les deux types d’informations doivent être placés dans le contexte d’une question en langage naturel avec une intention spécifique. De plus, étant donné que les vidéos comportent de nombreuses images, les traiter toutes pour apprendre des informations spatio-temporelles peut s'avérer prohibitif sur le plan informatique.

Lien papier : https://arxiv.org/pdf/2208.00934.pdf#🎜 🎜# Afin de résoudre ce problème, dans l'article « Réponse aux questions vidéo avec co-tokenisation itérative de texte vidéo », des chercheurs de Google et du MIT ont présenté une nouvelle méthode d'apprentissage de texte vidéo appelée. « co-étiquetage itératif », il peut fusionner efficacement des informations spatiales, temporelles et linguistiques pour le traitement de l'information dans les questions et réponses vidéo.

Cette méthode est multi-flux , utilisez des modèles de base indépendants pour traiter des vidéos de différentes échelles, produisant ainsi des représentations vidéo qui capturent différentes caractéristiques, telles qu'une résolution spatiale élevée ou des vidéos de longue durée. Le modèle applique le module « co-authentification » pour apprendre des représentations efficaces issues de la fusion de flux vidéo et de texte. Le modèle est très efficace sur le plan informatique, ne nécessitant que 67 GFLOP, ce qui est au moins 50 % inférieur à la méthode précédente, et offre de meilleures performances que les autres modèles SOTA.
Itération vidéo-texteL'objectif principal de ce modèle est de générer des fonctionnalités à partir de la vidéo et du texte (c'est-à-dire des questions des utilisateurs) qui permettent conjointement eux pour interagir avec l’entrée correspondante. Le deuxième objectif est de le faire de manière efficace, ce qui est très important pour les vidéos car elles contiennent des dizaines, voire des centaines d'images d'entrée.
Le modèle apprend à étiqueter l'entrée conjointe du langage vidéo en petits ensembles d'étiquettes pour représenter conjointement et efficacement les deux modalités. Lors de la tokenisation, les chercheurs utilisent les deux modes pour produire une représentation compacte commune, qui est introduite dans une couche de transformation pour produire la représentation de niveau suivant.
Un défi ici, qui est également un problème typique de l'apprentissage multimodal, est que les images vidéo ne correspondent souvent pas directement au texte associé. Les chercheurs ont résolu ce problème en ajoutant deux couches linéaires apprenables qui unifient les dimensions des caractéristiques visuelles et textuelles avant la tokenisation. Cela a permis aux chercheurs de déterminer à la fois la vidéo et le texte de la manière dont les balises vidéo ont été apprises.
De plus, une seule étape de tokenisation ne permet pas une interaction supplémentaire entre les deux modes. Pour ce faire, les chercheurs utilisent cette nouvelle représentation de fonctionnalités pour interagir avec les fonctionnalités d'entrée vidéo et produire un autre ensemble de fonctionnalités tokenisées, qui sont ensuite introduites dans la couche de transformateur suivante. Ce processus itératif crée de nouvelles caractéristiques ou marqueurs qui représentent l'amélioration continue de la représentation conjointe des deux modes. Enfin, ces fonctionnalités sont introduites dans un décodeur qui génère une sortie texte.

Conformément à la pratique de l'évaluation de la qualité vidéo, évaluation individuelle de la qualité vidéo données Avant d'affiner l'ensemble, les chercheurs ont pré-entraîné le modèle. Dans ce travail, les chercheurs ont automatiquement annoté les vidéos avec du texte basé sur la reconnaissance vocale, en utilisant l'ensemble de données HowTo100M au lieu d'une pré-formation sur le grand ensemble de données VideoQA. Ces données de pré-entraînement plus faibles ont néanmoins permis au modèle des chercheurs d'apprendre les fonctionnalités du texte vidéo.
Mise en œuvre d'une réponse vidéo efficace aux questionsLes chercheurs ont appliqué l'algorithme de co-authentification itérative du langage vidéo à trois principaux benchmarks VideoQA, MSRVTT-QA, MSVD-QA et IVQA, et démontrent que cette approche permet d'obtenir de meilleurs résultats que d'autres modèles de pointe sans rendre le modèle trop grand. De plus, l’apprentissage itératif co-labellisé nécessite également une puissance de calcul inférieure pour les tâches d’apprentissage vidéo-texte.
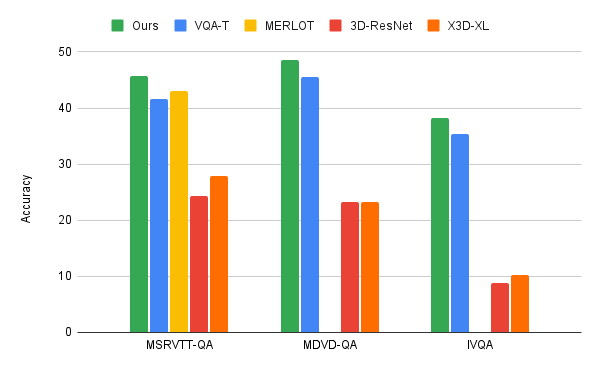
Ce modèle utilise uniquement une puissance de calcul de 67GFLOPS et est une vidéo 3D-ResNet modèle Un sixième de la puissance de calcul (360GFLOP) requise lors du traitement du texte et du texte, et plus de deux fois l'efficacité du modèle X3D. et génère des résultats très précis, dépassant les méthodes de pointe.
Entrée vidéo multi-flux
Pour VideoQA ou d'autres tâches impliquant une entrée vidéo, les chercheurs ont constaté que l'entrée multi-flux est plus précise pour Il est important de répondre aux questions sur la relation entre l’espace et le temps.
Les chercheurs ont utilisé trois flux vidéo avec des résolutions et des fréquences d'images différentes : un flux vidéo d'entrée basse résolution et à fréquence d'images élevée (32 images par seconde, spatial A résolution de 64 x 64 (notée 32 x 64 x 64) ; une vidéo haute résolution à faible fréquence d'images (8 x 224 x 224) et une vidéo intermédiaire (16 x 112 x 112).
Bien qu'il y ait évidemment plus d'informations à traiter avec trois flux de données, un modèle très efficace est obtenu grâce à la méthode de co-étiquetage itérative. Parallèlement, ces flux de données supplémentaires permettent d’extraire les informations les plus pertinentes.
Par exemple, comme le montre la figure ci-dessous, les questions liées à des activités spécifiques produiront des activations plus élevées dans les entrées vidéo avec des résolutions inférieures mais des fréquences d'images plus élevées, et les questions liées à les activités générales peuvent être répondues à partir d’entrées haute résolution avec très peu d’images. Un autre exemple de cet algorithme. La bonne nouvelle est que la tokenisation change en fonction de la question posée.
Conclusion Les chercheurs ont proposé une nouvelle méthode d'apprentissage des langues par vidéo qui se concentre sur l'apprentissage conjoint à travers les modalités vidéo-texte. Les chercheurs s’attaquent à la tâche importante et difficile de répondre aux questions par vidéo. L’approche des chercheurs est efficace et précise, surpassant les modèles de pointe actuels bien qu’elle soit plus efficace.
Les chercheurs ont proposé une nouvelle méthode d'apprentissage des langues par vidéo qui se concentre sur l'apprentissage conjoint à travers les modalités vidéo-texte. Les chercheurs s’attaquent à la tâche importante et difficile de répondre aux questions par vidéo. L’approche des chercheurs est efficace et précise, surpassant les modèles de pointe actuels bien qu’elle soit plus efficace.
L'approche des chercheurs de Google repose sur une taille de modèle modeste et pourrait améliorer encore les performances avec des modèles et des données plus volumineux. Les chercheurs espèrent que ces travaux susciteront davantage de recherches sur l’apprentissage visuel du langage afin de permettre des interactions plus fluides avec les médias visuels.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI