
Maison >Périphériques technologiques >IA >L'examen d'IA et l'examen public approchent à grands pas ! L'équipe chinoise de Microsoft lance le nouveau benchmark AGIEval, spécialement conçu pour les examens humains
L'examen d'IA et l'examen public approchent à grands pas ! L'équipe chinoise de Microsoft lance le nouveau benchmark AGIEval, spécialement conçu pour les examens humains

- PHPzavant
- 2023-05-16 16:22:12998parcourir
À mesure que les modèles de langage deviennent de plus en plus puissants, les critères d'évaluation existants sont vraiment un peu enfantins, et l'exécution de certaines tâches est loin derrière les humains.
Une caractéristique importante de l'intelligence artificielle générale (AGI) est la capacité des modèles à se généraliser à des tâches au niveau humain, alors que les benchmarks traditionnels qui s'appuient sur des ensembles de données artificielles ne peuvent pas une représentation précise. des capacités humaines.
Récemment, des chercheurs de Microsoft ont publié un nouveau benchmark AGIEval, spécifiquement conçu pour évaluer le modèle de base dans « Human-centered » " Performance aux tests standardisés centrés sur l'humain , tels que les examens d'entrée à l'université, les examens de la fonction publique, les examens d'entrée à la faculté de droit, les concours de mathématiques et les examens du barreau.

Lien papier : https://arxiv.org /pdf/2304.06364.pdf
Lien de données : https://github.com/microsoft/AGIEval#🎜 🎜#
Les chercheurs ont utilisé le benchmark AGIEval pour évaluer trois modèles de base de pointe, dont GPT-4, ChatGPT et Text-Davinci-003. que GPT-4 a obtenu de meilleurs résultats au SAT Les résultats aux concours , LSAT et de mathématiques ont dépassé le niveau humain moyen. La précision du test de mathématiques SAT a atteint 95 % et la précision du test d'anglais de l'examen d'entrée au China College a atteint 92,5 %, ce qui indique que GPT-4 a obtenu de meilleurs résultats au SAT. les performances extraordinaires du modèle de base actuel.
Mais GPT-4 n'est pas très compétent dans les tâches qui nécessitent un raisonnement complexe ou des connaissances spécifiques dans un domaine. L'article est complet sur les capacités du modèle (compréhension, connaissance, raisonnement et. calcul) L’analyse révèle les forces et les limites de ces modèles.
Ensemble de données AGIEvalCes dernières années, des modèles de base à grande échelle tels que GPT-4 ont montré des capacités très puissantes dans divers domaines et peut aider les humains à gérer les événements quotidiens et même fournir des conseils de prise de décision dans des domaines professionnels tels que le droit, la médecine et la finance.
Autrement dit, les systèmes d'intelligence artificielle se rapprochent et atteignent progressivement l'intelligence générale artificielle (AGI).
Mais à mesure que l'IA s'intègre progressivement dans la vie quotidienne, comment évaluer la capacité de généralisation centrée sur l'humain des modèles, identifier les défauts potentiels et s'assurer qu'ils peuvent gérer efficacement des modèles complexes, Les tâches centrées sur l'humain, ainsi que l'évaluation des capacités de raisonnement pour garantir la fiabilité et la fiabilité dans divers contextes, sont essentielles.
Les chercheurs ont construit l'ensemble de données AGIEval principalement en suivant deux principes de conception :
# 🎜 🎜#1. L'accent est mis sur les tâches cognitives au niveau du cerveau humain
L'objectif principal du design « centré sur l'humain » est d'interagir avec la cognition humaine Concentrez-vous sur les tâches étroitement liées à la résolution de problèmes et évaluez la capacité de généralisation du modèle sous-jacent de manière plus significative et complète.Pour atteindre cet objectif, les chercheurs ont sélectionné une variété d'examens d'admission et de qualification officiels, publics et de haut niveau pour répondre aux besoins du candidat humain moyen, notamment Les examens d'entrée à l'université, les examens d'admission aux facultés de droit, les examens de mathématiques, les examens du barreau et les examens de la fonction publique de l'État, sont passés chaque année par des millions de personnes cherchant à accéder à l'enseignement supérieur ou à de nouvelles carrières.
En adhérant à ces normes officiellement reconnues pour l'évaluation des capacités au niveau humain, AGIEval garantit que les évaluations des performances des modèles sont directement liées à la prise de décision humaine et aux capacités cognitives.
2 Pertinence par rapport aux scénarios du monde réel# 🎜 🎜# En sélectionnant des tâches parmi des examens d'entrée et de qualification de haut niveau, vous vous assurez que les résultats de l'évaluation reflètent la complexité et le caractère pratique des défis que les individus rencontrent souvent dans différents domaines et contextes.
Cette méthode mesure non seulement les performances du modèle en termes de capacités cognitives humaines, mais permet également une meilleure compréhension de l'applicabilité et de l'efficacité dans la vie réelle, c'est-à-dire aide développer des systèmes d’intelligence artificielle plus fiables, plus pratiques et plus adaptés à la résolution d’un large éventail de problèmes du monde réel.
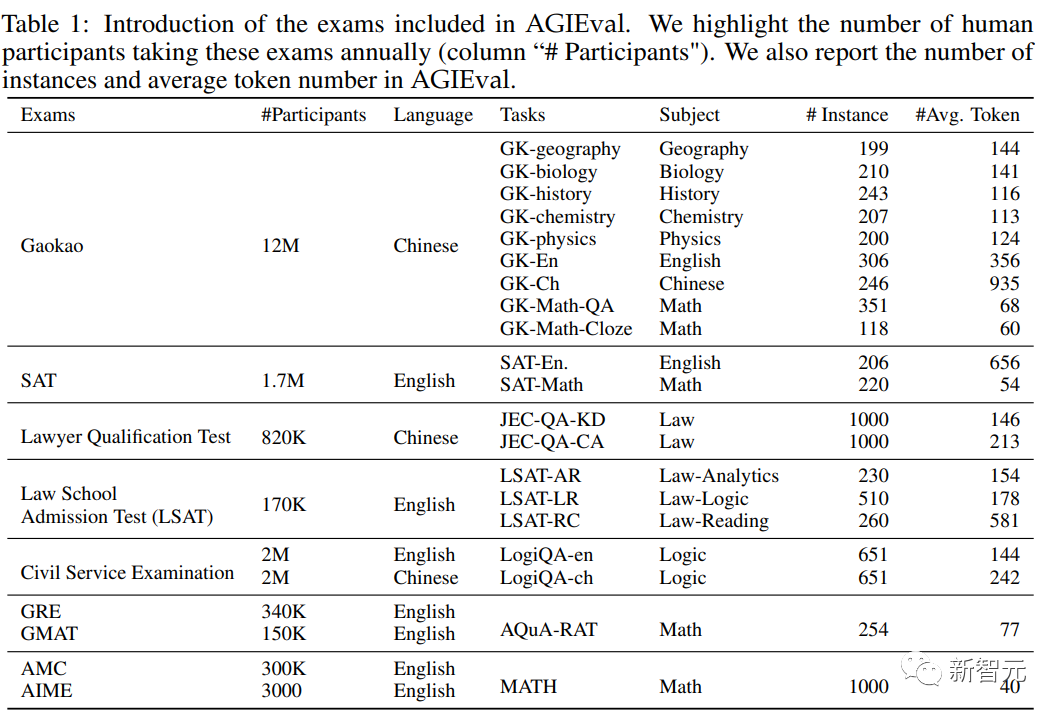
Sur la base des principes de conception ci-dessus, les chercheurs ont sélectionné une variété d'examens standardisés et de haute qualité qui mettent l'accent sur le raisonnement au niveau humain et la pertinence dans le monde réel, notamment :
1. Admissions générales à l'université EXAMEN
L'examen d'entrée à l'université couvre une variété de sujets qui nécessitent une pensée critique, des compétences en résolution de problèmes et des compétences analytiques et est idéal pour évaluer les performances de grands modèles de langage par rapport à la cognition humaine.
Comprend spécifiquement le Graduate Record Examination (GRE), le Academic Assessment Test (SAT) et le China College Entry Examination (Gaokao), qui peuvent évaluer les capacités générales et les connaissances spécifiques à une matière des étudiants souhaitant être admis dans des établissements d'enseignement supérieur.
L'ensemble de données collecte des examens correspondant à 8 matières de l'examen d'entrée à l'université chinoise : histoire, mathématiques, anglais, chinois, géographie, biologie, chimie et physique ; un ensemble de données de référence.
2. Test d'admission à la faculté de droit
Le test d'admission à la faculté de droit, tel que le LSAT, est conçu pour mesurer les compétences de raisonnement et d'analyse des futurs étudiants en droit. Le contenu du test comprend le raisonnement logique et la compréhension en lecture. et raisonnement analytique. Ces tâches évaluent la capacité des modèles de langage en matière de raisonnement et d'analyse juridiques.
3. L'examen du barreau
évalue les connaissances juridiques, les compétences analytiques et la compréhension éthique des personnes poursuivant une carrière juridique et couvre un large éventail de sujets juridiques, notamment le droit constitutionnel, le droit des contrats, le droit pénal. droit et droit de la propriété, et exige que les candidats démontrent leur capacité à appliquer efficacement les principes et le raisonnement juridiques. Les performances dans le modèle linguistique peuvent être évaluées dans le contexte de connaissances juridiques spécialisées et de jugement moral.
4. Graduate Management Admission Test (GMAT)
GMAT est un test standardisé qui évalue les compétences de raisonnement analytique, quantitatif, verbal et intégré des futurs étudiants diplômés des écoles de commerce, telles qu'évaluées par rédaction analytique. , raisonnement global, raisonnement quantitatif et raisonnement verbal, etc., pour évaluer la capacité du candidat à penser de manière critique, à analyser des données et à communiquer efficacement.
5. Concours de mathématiques au lycée
Ces concours couvrent un large éventail de sujets mathématiques, notamment la théorie des nombres, l'algèbre, la géométrie et la combinatoire, et présentent souvent des problèmes non conventionnels qui nécessitent des approches créatives pour être résolus. .
Comprend spécifiquement l'American Mathematics Competition (AMC) et l'American Invitational Mathematics Examination (AIME), qui peuvent tester les capacités mathématiques, la créativité et la capacité de résolution de problèmes des élèves, et peuvent évaluer plus en détail la capacité des modèles de langage à gérer des et les problèmes mathématiques créatifs et la capacité du modèle à générer de nouvelles solutions.
6. L'examen de la fonction publique nationale
peut évaluer les capacités et les compétences des personnes souhaitant entrer dans la fonction publique. Le contenu de l'examen comprend l'évaluation des connaissances générales, de la capacité de raisonnement, des compétences linguistiques. et divers postes de la fonction publique en Chine. Expertise spécifique à un sujet dans les rôles et responsabilités permettant de mesurer la performance des modèles linguistiques dans des contextes d'administration publique et leur potentiel pour l'élaboration de politiques, la prise de décision et les processus de prestation de services publics.
Résultats de l'évaluation
Les modèles sélectionnés incluent :
ChatGPT, un modèle d'intelligence artificielle conversationnelle développé par OpenAI qui peut participer à l'interaction utilisateur et au dialogue dynamique, formé à l'aide d'un énorme ensemble de données d'instructions et passé le renforcement L'apprentissage avec feedback humain (RLHF) l'ajuste davantage pour fournir des réponses contextuellement pertinentes et cohérentes, conformes aux attentes humaines.
GPT-4, en tant que modèle GPT de quatrième génération, contient un plus large éventail de bases de connaissances et présente des performances au niveau humain dans de nombreux scénarios d'application. GPT-4 a été modifié à plusieurs reprises à l'aide de tests contradictoires et de ChatGPT, ce qui a entraîné des améliorations significatives en termes de factualité, de démarrage et de conformité aux règles.
Text-Davinci-003 est une version intermédiaire entre GPT-3 et GPT-4, qui fonctionne mieux que GPT-3 après un réglage fin grâce aux instructions.
De plus, le score moyen et le score le plus élevé des candidats humains ont également été rapportés dans l'expérience comme limite de niveau humain pour chaque tâche, mais ils ne représentent pas pleinement l'éventail de compétences et de connaissances que les humains peuvent posséder.
Évaluation zéro tir/quelques tirs
Dans le paramètre d'échantillon zéro, le modèle évalue directement le problème dans la tâche de quelques tirs, la même tâche est entrée avant d'évaluer l'échantillon de test A ; petit nombre d’exemples (par exemple 5).
Afin de tester davantage la capacité de raisonnement du modèle, l'invite de chaîne de pensée (CoT) a également été introduite dans l'expérience, c'est-à-dire qu'il faut d'abord saisir l'invite « Pensons étape par étape » pour générer une explication pour une question donnée, puis entrez l'invite « L'explication est » selon L'explication génère la réponse finale.
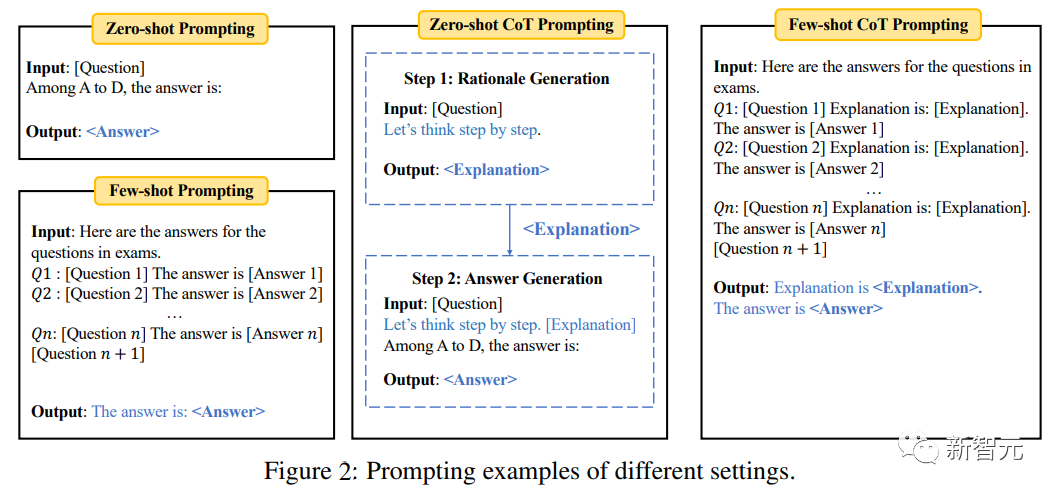
Les « questions à choix multiples » du benchmark utilisent une précision de classification standard ; les « questions à remplir » utilisent des indicateurs de correspondance exacte (EM) et F1.
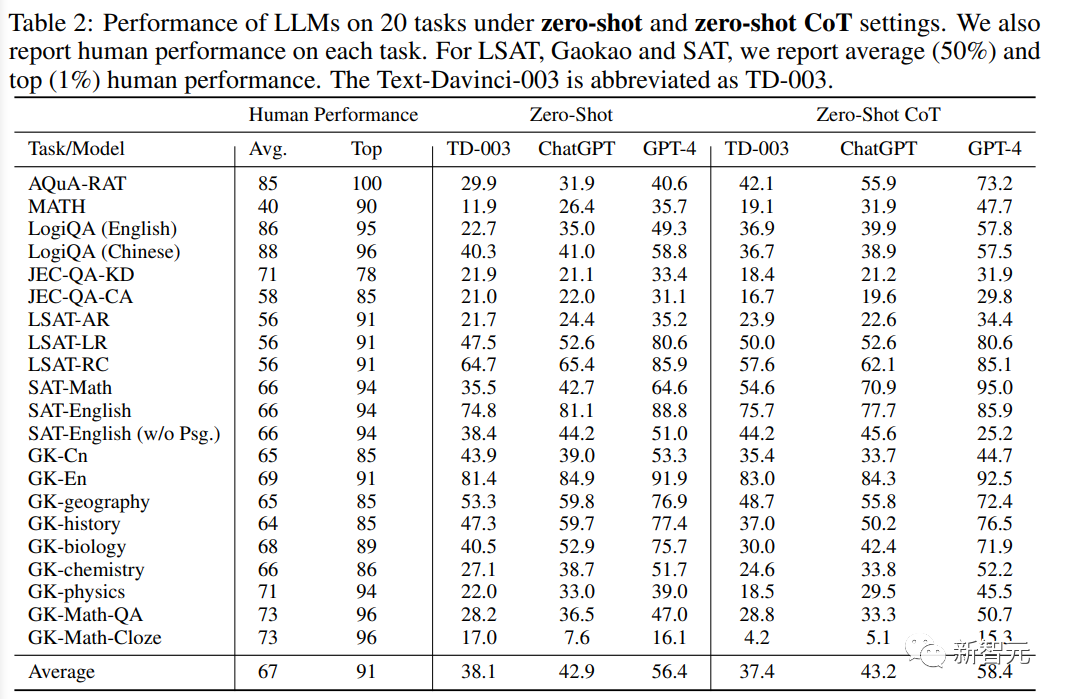
On peut le constater à partir des résultats expérimentaux :
1 GPT-4 est nettement meilleur que ses produits similaires dans tous les paramètres de tâches , en particulier sur Gaokao-English Avec une précision de. 93,8 % et une précision de 95 % sur SAT-MATH, GPT-4 possède d'excellentes capacités générales dans la gestion de tâches centrées sur l'humain.
2. ChatGPT est nettement meilleur que Text-Davinci-003 dans les tâches qui nécessitent des connaissances externes, telles que les tâches impliquant la géographie, la biologie, la chimie, la physique et les mathématiques, ce qui indique que ChatGPT possède une base de connaissances plus solide et est plus capable de bien gérer les tâches qui nécessitent une compréhension approfondie d’un domaine spécifique.
D'un autre côté, ChatGPT surpasse légèrement Text-Davinci-003, ou obtient des résultats comparables dans tous les paramètres d'évaluation, dans des tâches qui nécessitent une compréhension pure et ne s'appuient pas beaucoup sur des connaissances externes, comme les tâches d'anglais et de LSAT. Cette observation signifie que les deux modèles sont capables de gérer des tâches centrées sur la compréhension du langage et le raisonnement logique sans nécessiter de connaissances spécialisées dans un domaine.
3. Bien que les performances globales de ces modèles soient bonnes, tous les modèles de langage fonctionnent mal dans les tâches d'inférence complexes, telles que MATH, LSAT-AR, GK-physics et GK-Math, soulignant ces limitations des modèles dans gérer des tâches qui nécessitent des compétences avancées en raisonnement et en résolution de problèmes.
Les difficultés observées dans la gestion de problèmes d'inférence complexes offrent des opportunités de recherche et de développement futurs visant à améliorer les capacités générales d'inférence du modèle.
4. Par rapport à l'apprentissage sans tir, l'apprentissage en quelques coups ne peut généralement apporter qu'une amélioration limitée des performances, ce qui indique que la capacité d'apprentissage sans coup actuelle des grands modèles de langage se rapproche de la capacité d'apprentissage en quelques coups, et Il s'agit d'une grande amélioration par rapport au modèle GPT-3 d'origine, où les performances en quelques tirs étaient bien meilleures que celles en tir nul.
Une explication logique de ce développement est le réglage et l'ajustement accrus par l'homme des instructions dans les modèles de langage actuels. Ces améliorations permettent aux modèles de mieux comprendre le sens et le contexte de la tâche à l'avance, leur permettant d'effectuer des tâches même si cela est le cas. fonctionne également bien dans des conditions de tir nul, prouvant l’efficacité de l’instruction.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI