
Maison >Périphériques technologiques >IA >Hinton est sur la liste ! Bilan des 10 ans d'histoire de la synthèse d'images par l'IA, articles et noms à retenir
Hinton est sur la liste ! Bilan des 10 ans d'histoire de la synthèse d'images par l'IA, articles et noms à retenir

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-15 19:04:041125parcourir
Maintenant, nous sommes fin 2022.
Les performances des modèles d'apprentissage profond dans la génération d'images sont déjà très bonnes. Évidemment, cela nous réservera d’autres surprises à l’avenir.

Comment en sommes-nous arrivés là où nous en sommes aujourd'hui en dix ans ?
Dans la chronologie ci-dessous, nous retracerons quelques moments marquants, c'est-à-dire le lancement des articles, des architectures, des modèles, des ensembles de données et des expériences qui ont influencé la synthèse d'images de l'IA.
Tout commence à partir de cet été il y a dix ans.
Le début (2012-2015)
Après l'avènement des réseaux de neurones profonds, les gens ont réalisé que cela révolutionnerait la classification des images.
Dans le même temps, les chercheurs ont commencé à explorer la direction opposée : que se passerait-il si les images étaient produites à l'aide de techniques très efficaces pour la classification, comme les couches convolutives ?
C'est le début de « l'été de l'intelligence artificielle ».
Décembre 2012
C'est là que tout a commencé.
Cette année, l'article "Classification ImageNet des réseaux de neurones à convolution profonde" a été publié.

L'un des auteurs de l'article est Hinton, l'un des « trois grands » de l'IA.
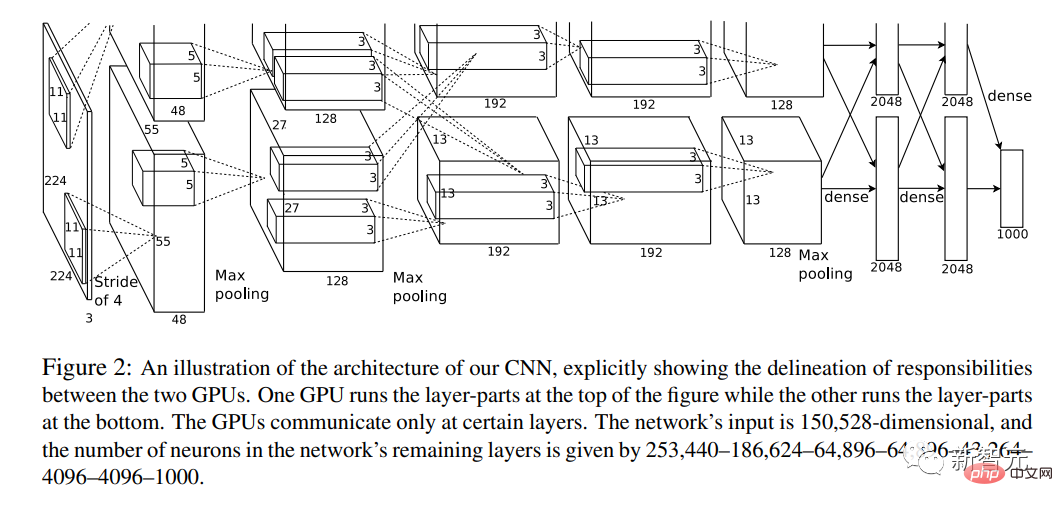
Il combine pour la première fois des réseaux de neurones convolutifs profonds (CNN), un GPU et un énorme ensemble de données provenant d'Internet (ImageNet).

En décembre 2014
Ian Goodfellow et d'autres géants de l'IA ont publié l'article épique "Generative Adversarial Networks".
GAN est la première architecture de réseau neuronal moderne dédiée à la synthèse d'images plutôt qu'à l'analyse (la définition de « moderne » est postérieure à 2012).
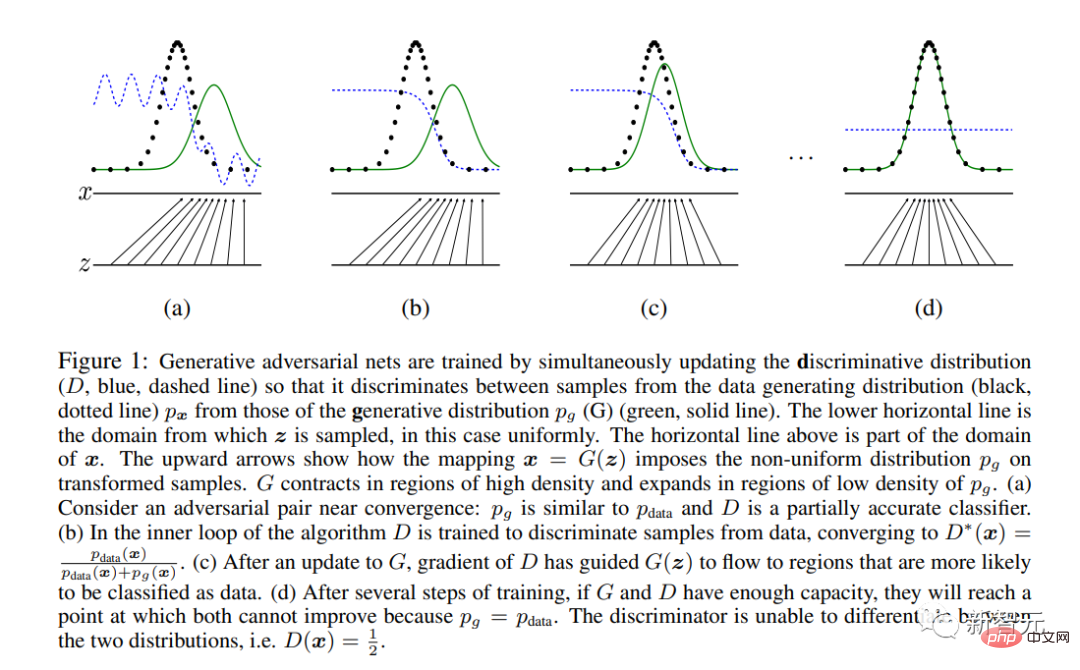
Il introduit une méthode d'apprentissage unique basée sur la théorie des jeux, avec deux sous-réseaux « Générateur » et « Discriminateur » en compétition.
Au final, seul le "générateur" est conservé en dehors du système et sert à la synthèse d'images.
Bonjour tout le monde ! GAN a généré des échantillons de visage à partir de l'article de Goodfellow et al. de 2014. Le modèle a été formé sur l'ensemble de données Toronto Faces, qui a été supprimé du Web
Novembre 2015
L'article fondateur "Using Deep Convolutional Generative Adversarial Networks" Unsupervised Representative Learning" a été publié.

Dans cet article, les auteurs décrivent la première architecture GAN pratiquement utilisable (DCGAN).
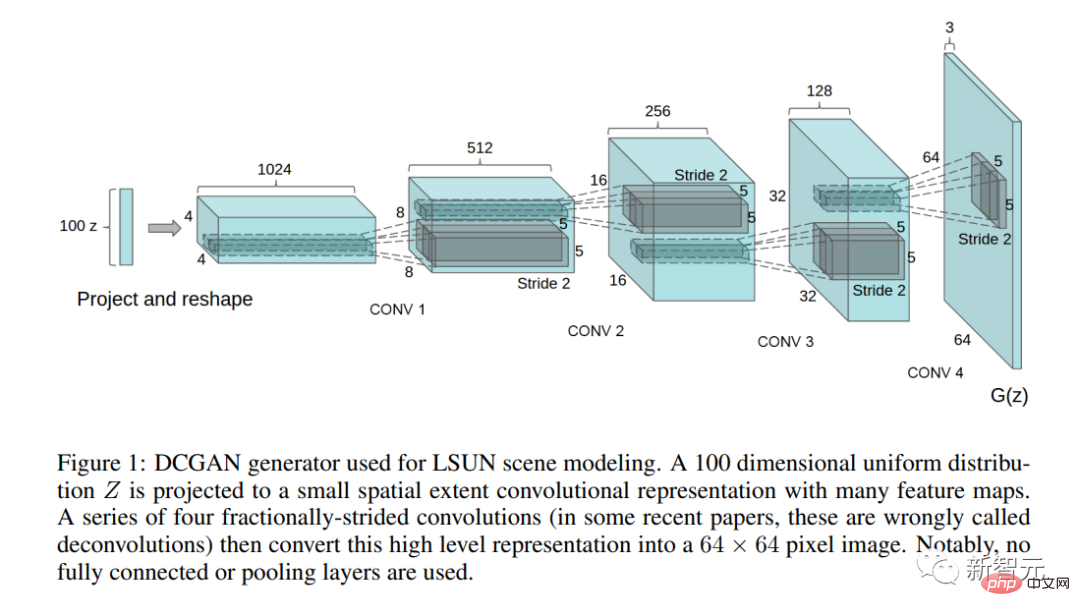
Cet article soulève également pour la première fois la question de la manipulation de l'espace latent : les concepts correspondent-ils aux directions de l'espace latent ?
Cinq années de GAN (2015-2020)
Au cours de ces cinq années, GAN a été appliqué à diverses tâches de traitement d'image, telles que le transfert de style, la restauration, le débruitage et la super-résolution. Durant
, les articles sur l'architecture GAN ont commencé à exploser.

Adresse du projet : https://github.com/nightrome/really-awesome-gan
Dans le même temps, les expérimentations artistiques de GAN ont commencé à prendre de l'ampleur, Mike Tyka, Mario Klingenmann, Anna Ridler, Helena Sarin et d'autres sont apparus.
Le premier scandale de « l’art de l’IA » a eu lieu en 2018. Trois étudiants français ont utilisé du code « emprunté » pour générer un portrait IA, qui est devenu le premier portrait IA vendu aux enchères chez Christie's.

Dans le même temps, l'architecture des transformateurs a révolutionné la PNL.
Cette chose aura un grand impact sur la synthèse d'images dans un avenir proche.
Juin 2017
Publication du document "L'attention est tout ce dont vous avez besoin".

Il y a également une explication détaillée dans « Transformers, expliqués : comprendre le modèle derrière GPT-3, BERT et T5 ».
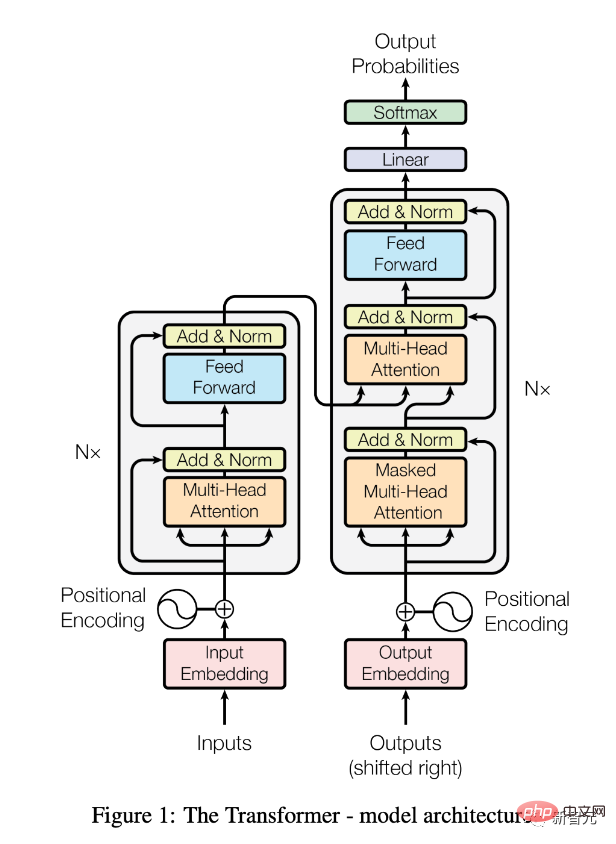
Depuis, l'architecture Transformer (sous forme de modèles pré-entraînés comme BERT) a révolutionné le domaine du traitement du langage naturel (NLP).

Juillet 2018

L'article "Annotation conceptuelle : nettoyage, superposition et ensemble de données de texte alternatif d'image pour le sous-titrage automatique d'images" a été publié.
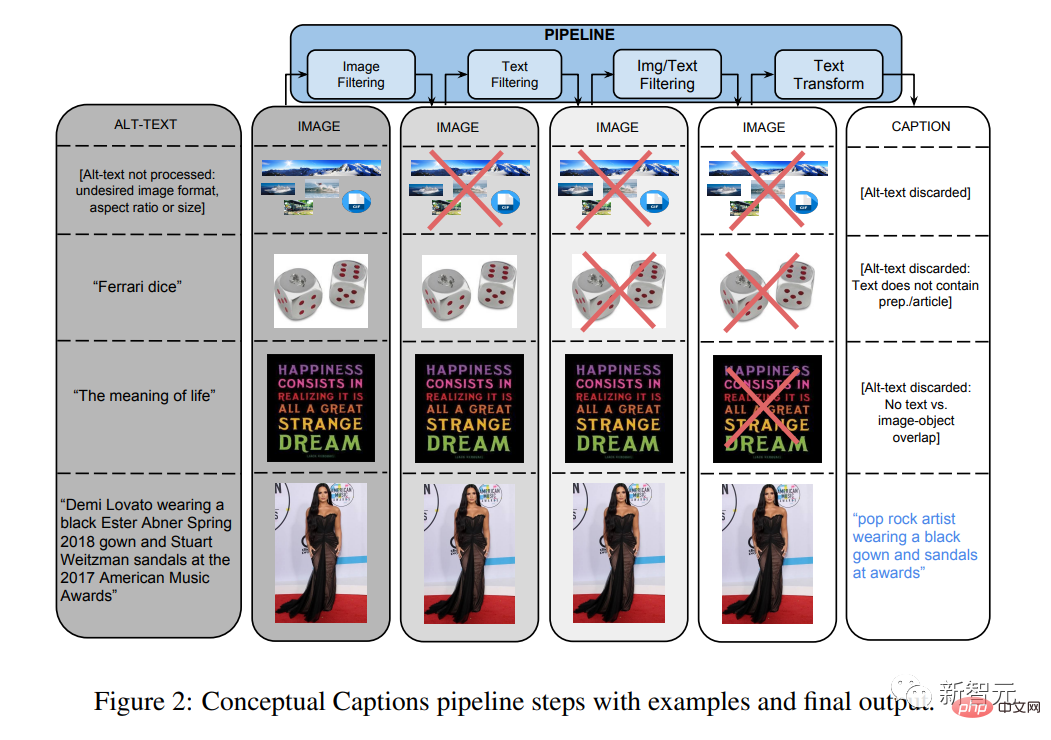
Cet ensemble de données multimodales et d'autres deviendront extrêmement importants pour des modèles comme CLIP et DALL-E.
En 2018-20
Les chercheurs de NVIDIA ont apporté une série d'améliorations approfondies à l'architecture GAN.
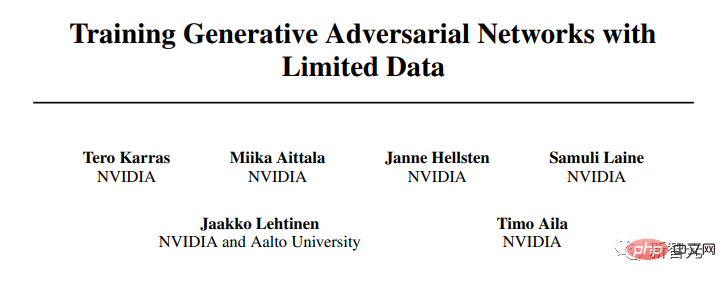
Dans l'article "Training Generative Adversarial Networks Using Limited Data", le dernier StyleGAN2-ada est présenté.
Pour la première fois, les images générées par
GAN deviennent impossibles à distinguer des images naturelles, du moins pour les ensembles de données hautement optimisés comme Flickr-Faces-HQ (FFHQ).

Mario Klingenmann, Memories of Passerby I, 2018. Les visages baconesques sont typiques de l'art de l'IA dans la région, où le non-réalisme des modèles génératifs est au centre de l'exploration artistique
2020 5 mois
L'article "Language Model is a Small Sample Learner" a été publié.
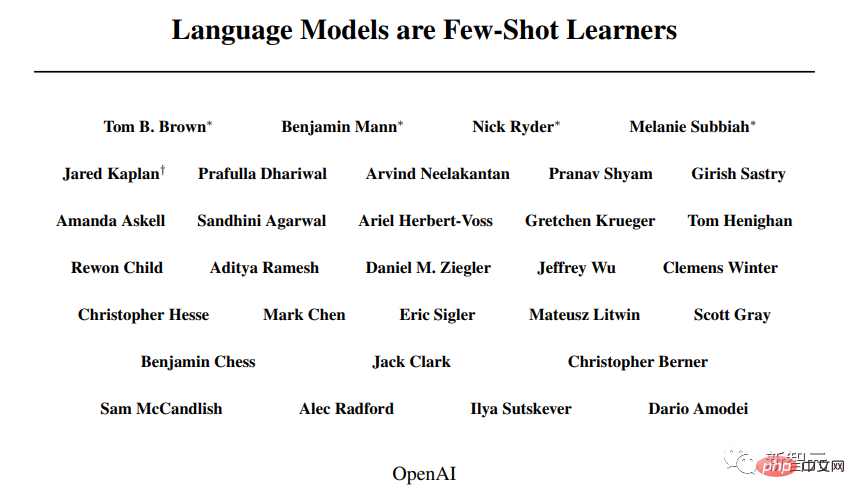
Le transformateur pré-entraîné génératif LLM 3 (GPT-3) d'OpenAI démontre la puissance de l'architecture du transformateur.
Décembre 2020
L'article "Apprivoiser les transformateurs pour la synthèse d'images à haute résolution" a été publié.

ViT montre que l'architecture Transformer peut être utilisée pour les images.
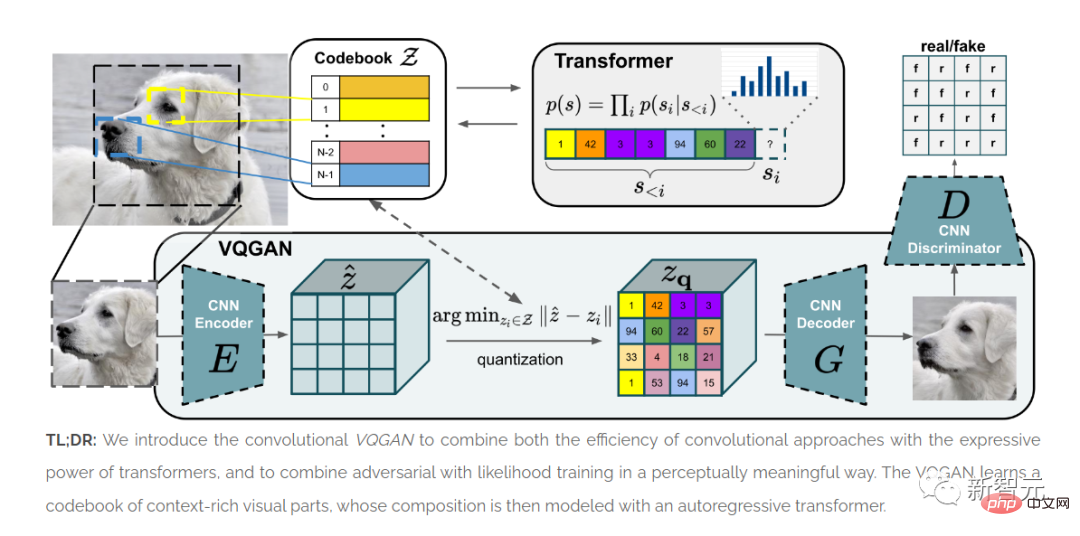
La méthode VQGAN présentée dans cet article a produit des résultats SOTA dans des tests de référence.
La qualité des architectures GAN de la fin des années 2010 a été principalement évaluée sur la base d'images faciales alignées, avec des résultats limités pour des ensembles de données plus hétérogènes.
Le visage humain reste donc une référence importante dans les expérimentations académiques/industrielles et artistiques.
L'ère Transformer (2020-2022)
L'émergence de l'architecture Transformer a complètement réécrit l'histoire de la synthèse d'images.
Depuis lors, le domaine de la synthèse d'images a commencé à laisser derrière lui le GAN.
L'apprentissage profond « multimodal » intègre les technologies de PNL et de vision par ordinateur. L'« ingénierie juste-à-temps » remplace la formation et l'ajustement des modèles et devient une méthode artistique de synthèse d'images.
Dans l'article "Apprendre des modèles visuels transférables à partir de la supervision du langage naturel", l'architecture CLIP est proposée.

On peut dire que l'engouement actuel pour la synthèse d'images est motivé par la fonction multimodale introduite pour la première fois par CLIP.
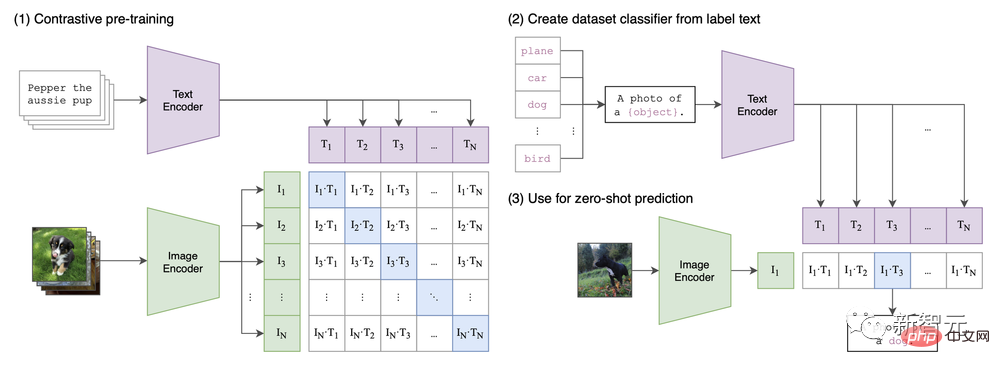
CLIP Architecture en Papier
Janvier 2021

L'article "Zero-Sample Text to Image Generation" a été publié (voir aussi le billet de blog d'OpenAI), qui présente la première version de DALL-E qui est sur le point de sortir dans le monde.
Cette version fonctionne en combinant du texte et des images (compressées par VAE en "TOKEN") dans un seul flux de données.
Ce modèle "continue" simplement la "phrase".
Les données (250 millions d'images) comprennent des paires texte-image de Wikipédia, des descriptions de concepts et un sous-ensemble filtré de YFCM100M.
CLIP pose les bases de l'approche « multimodale » de la synthèse d'images.
Janvier 2021
L'article « Apprendre des modèles de vision transférables à partir de la supervision du langage naturel » a été publié.

L'article présente CLIP, un modèle multimodal qui combine ViT et Transformer ordinaire.
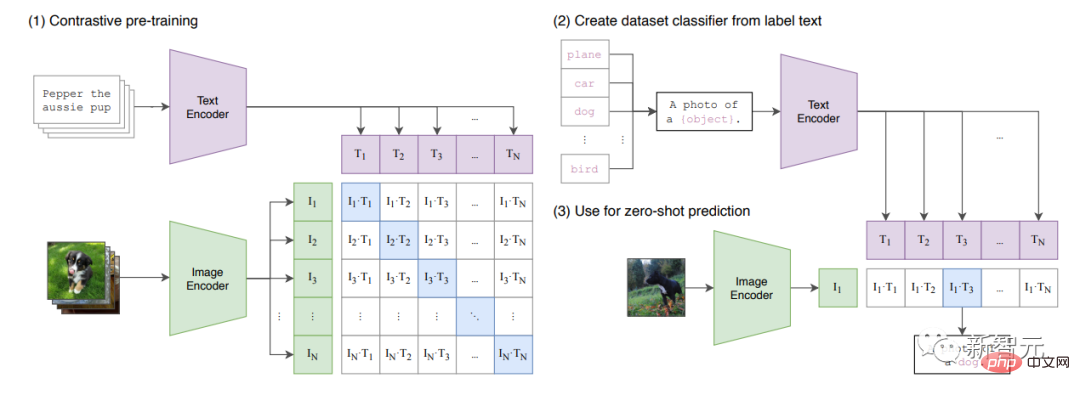
CLIP apprendra "l'espace latent partagé" des images et des légendes, afin de pouvoir étiqueter les images.
Le modèle est formé sur un grand ensemble de données répertorié à l'annexe A.1 de l'article.
Juin 2021
L'article "Le modèle de diffusion bat le GAN en synthèse d'images" a été publié.

Le modèle de diffusion introduit une méthode de synthèse d'images différente de la méthode GAN.

Les chercheurs apprennent en reconstruisant des images à partir de bruit ajouté artificiellement.
Ils sont liés aux auto-encodeurs variationnels (VAE).
Juillet 2021
Sortie du mini DALL-E.
C'est une copie de DALL-E (plus petite, avec peu d'ajustements sur l'architecture et les données).
Les données incluent Conceptual 12M, Conceptual Captions et le même sous-ensemble filtré de YFCM100M utilisé par OpenAI pour le modèle DALL-E d'origine.
Sans filtres de contenu ni restrictions d'API, DALL-E mini offre un énorme potentiel d'exploration créative et a conduit à une explosion d'images « bizarres DALL-E » sur Twitter.
2021-2022
Katherine Crowson a publié une série de notes CoLab explorant les méthodes de création de modèles génératifs guidés par CLIP.
Par exemple, diffusion guidée 512x512CLIP et VQGAN-CLIP (génération et édition d'images en domaine ouvert avec guidage en langage naturel, publiée uniquement en préimpression en 2022 mais des expériences publiques sont apparues dès la sortie de VQGAN).
Tout comme au début de l'ère GAN, artistes et développeurs ont apporté des améliorations significatives aux architectures existantes avec des moyens très limités, qui ont ensuite été simplifiées par des entreprises et finalement commercialisées par des « startups » comme wombo.ai.
Avril 2022
L'article "Génération d'images conditionnelles de texte hiérarchique avec potentiel CLIP" a été publié.

Cet article présente DALL-E 2.

Il s'appuie sur l'article GLIDE ("GLIDE : Realistic Image Generation and Editing Using Text-Guided Diffusion Models") publié il y a quelques semaines à peine

. Pendant ce temps, il y a un regain d'intérêt pour le DALL-E mini en raison de l'accès limité et des limitations intentionnelles du DALL-E 2
Selon la fiche modèle, les données comprennent "une combinaison de ressources accessibles au public et de nos ressources sous licence ." Et les ensembles de données CLIP et DALL-E complets selon le journal.

"Photo portrait de blonde, prise avec un appareil photo reflex numérique, fond neutre, haute résolution", générée à l'aide de DALL-E 2 . Les modèles génératifs basés sur des transformateurs correspondent au réalisme des architectures GAN ultérieures telles que StyleGAN 2, mais permettent la création d'une grande variété de thèmes et de modèles
Mai-juin 2022
En mai, le L'article "Realistic Text-to-Image Diffusion Model with Deep Language Understanding" a été publié

En juin, l'article "Scaling Autoregressive Model for Rich Text-to-Image Generation" a été publié.
Dans ces deux articles, Imagegen et Parti sont présentés

AI Photoshop (2022-présent)

Les utilisateurs ont continué à essayer des modèles plus petits tels que le DALL-E mini
Par la suite, tout a changé avec la sortie révolutionnaire de Stable Diffusion. On peut dire que Stable Diffusion marque le début de « l'ère Photoshop » de la synthèse d'images. "Nature morte avec quatre grappes de raisin, essayant de créer des raisins aussi réalistes que ceux du peintre antique Zeuxis Juan El Labrador Fernandez, 1636, Prado, Madrid" Six variations réalisées par Stable Diffusion Août 2022 Stability.ai publie le modèle Stable Diffusion. Dans l'article "Synthèse d'images haute résolution avec modèle de diffusion latente", Stability.ai présente fièrement la diffusion stable. Ce modèle peut atteindre le même photoréalisme que DALL-E 2. En plus du DALL-E 2, les modèles sont disponibles au public presque immédiatement et peuvent être exécutés sur les plateformes CoLab et Huggingface. En août 2022 Google a publié l'article "DreamBooth : Fine-tuning text-to-image diffusion model for topic-driven Generation". DreamBooth permet un contrôle de plus en plus fin du modèle de diffusion. Cependant, même sans une telle intervention technique supplémentaire, il devient possible d'utiliser des modèles génératifs comme Photoshop, à partir d'un croquis et en ajoutant des modifications génératives couche par couche. Octobre 2022 Shutterstock, l'une des plus grandes sociétés de photos, a annoncé un partenariat avec OpenAI pour fournir/licencer des images générées. sérieusement affecté par les modèles génératifs tels que Stable Diffusion. 




Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI